You might also like
- ECON 3300 Test 2 ReviewsDocument5 pagesECON 3300 Test 2 ReviewsMarcus ShumpertNo ratings yet
- Module 04 - Part1 AssignmentDocument10 pagesModule 04 - Part1 Assignmentsuresh avadutha75% (4)
- Time Series ForecastingDocument7 pagesTime Series ForecastingdarshanNo ratings yet
- Corporate Answer 13 Ledt PDFDocument11 pagesCorporate Answer 13 Ledt PDFHope KnockNo ratings yet
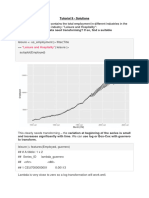
- Group 8 - Business Stats Project - Installment IDocument16 pagesGroup 8 - Business Stats Project - Installment IAbhee RajNo ratings yet
- Decision Science Answer 1Document6 pagesDecision Science Answer 1shiv panjnaniNo ratings yet
- Dar Solved AnsDocument20 pagesDar Solved AnsDevNo ratings yet
- ProblemSet9 Solutions v1Document7 pagesProblemSet9 Solutions v1s4mlauNo ratings yet
- Stat 401B Exam 2 Key F16Document10 pagesStat 401B Exam 2 Key F16juanEs2374pNo ratings yet
- Submission Group 12 Exercise 5Document42 pagesSubmission Group 12 Exercise 5Mehmet YalçınNo ratings yet
- Extra Exercises - Introductory StatisticsDocument8 pagesExtra Exercises - Introductory Statisticsworks.aliaazmiNo ratings yet
- Carrying Cost: Inventory CostsDocument31 pagesCarrying Cost: Inventory CostsVivek Kumar GuptaNo ratings yet
- Exercises For Chapter 6 of Vinod's " Hands-On Intermediate Econometrics Using R"Document25 pagesExercises For Chapter 6 of Vinod's " Hands-On Intermediate Econometrics Using R"damian camargoNo ratings yet
- Financial AccoutingDocument7 pagesFinancial Accoutingtinale1603No ratings yet
- Investment AnswersDocument22 pagesInvestment AnswerstapiwanashejakaNo ratings yet
- S19 6295 Final ExamDocument4 pagesS19 6295 Final Examzeynullah giderNo ratings yet
- 6 Solutions PDF FreeDocument12 pages6 Solutions PDF Free于富昇No ratings yet
- Analysis of ARIMA and GARCH ModelDocument14 pagesAnalysis of ARIMA and GARCH ModelSakshiNo ratings yet
- BUS 438 (Durham) - HW 8 - Capital Budgeting 3Document5 pagesBUS 438 (Durham) - HW 8 - Capital Budgeting 3sum pradhanNo ratings yet
- FINN3222 - Final Exam Review SolutionsDocument5 pagesFINN3222 - Final Exam Review Solutionsangelbear2577No ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionParth MehtaNo ratings yet
- Stats For Data Science Assignment-2: NAME: Rakesh Choudhary ROLL NO.-167 BATCH-Big Data B3Document9 pagesStats For Data Science Assignment-2: NAME: Rakesh Choudhary ROLL NO.-167 BATCH-Big Data B3Rakesh ChoudharyNo ratings yet
- Solution Assignment 3 Chapter 6Document14 pagesSolution Assignment 3 Chapter 6Huynh Ng Quynh NhuNo ratings yet
- Krajewski 11e SM Ch08 Krajewski 11e SM Ch08: Operations management (경희대학교) Operations management (경희대학교)Document67 pagesKrajewski 11e SM Ch08 Krajewski 11e SM Ch08: Operations management (경희대학교) Operations management (경희대학교)natalos100% (1)
- Lin Regr and ArimaDocument6 pagesLin Regr and Arimaapi-223061586No ratings yet
- Ballou Logistics Solved Problems Chapter 14Document25 pagesBallou Logistics Solved Problems Chapter 14RenTahL100% (1)
- Department of Statistics: Course Stats 330Document5 pagesDepartment of Statistics: Course Stats 330PETERNo ratings yet
- Exercise Sem 2 20162017 - Past YearDocument5 pagesExercise Sem 2 20162017 - Past Yearsyakirah-mustaphaNo ratings yet
- Statistics and ProbabilityDocument8 pagesStatistics and ProbabilityAlesya alesyaNo ratings yet
- Business Moments Graphic AssignmebtDocument11 pagesBusiness Moments Graphic AssignmebtAnakha PrasadNo ratings yet
- Business Statistics Canadian 3rd Edition Sharpe Solutions Manual DownloadDocument41 pagesBusiness Statistics Canadian 3rd Edition Sharpe Solutions Manual DownloadCharles Brickner100% (30)
- ML4T 2017fall Exam1 Version BDocument8 pagesML4T 2017fall Exam1 Version BDavid LiNo ratings yet
- ISOM4520 Sample Midterm Examination SolutionDocument10 pagesISOM4520 Sample Midterm Examination SolutionAlessia YangNo ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- MGS3100: Exercises - ForecastingDocument8 pagesMGS3100: Exercises - ForecastingJabir ArifNo ratings yet
- Problem Set 6Document6 pagesProblem Set 6Sila KapsataNo ratings yet
- EC2066 - Microeconomics - 2007 Examiners - Zone-ADocument16 pagesEC2066 - Microeconomics - 2007 Examiners - Zone-AAishwarya PotdarNo ratings yet
- Assig 2Document7 pagesAssig 2Katie CookNo ratings yet
- Business Maths ScopeDocument9 pagesBusiness Maths ScopeAbdul Razzaq KhanNo ratings yet
- Homework 2Document14 pagesHomework 2Juan Pablo Madrigal Cianci100% (1)
- Correlation RegressionDocument7 pagesCorrelation RegressionNikhil TandukarNo ratings yet
- Example 2Document7 pagesExample 2Thái TranNo ratings yet
- Business Statistics 2021Document3 pagesBusiness Statistics 2021Danesh PatilNo ratings yet
- Chapter 24: Portfolio Performance Evaluation: Problem SetsDocument13 pagesChapter 24: Portfolio Performance Evaluation: Problem SetsminibodNo ratings yet
- Section 3.4 PDFDocument8 pagesSection 3.4 PDFChristine JoyNo ratings yet
- Final Practrice (Unit 4 and 5)Document9 pagesFinal Practrice (Unit 4 and 5)mjlNo ratings yet
- Demand ForecastingDocument30 pagesDemand ForecastingBipin TiwariNo ratings yet
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Tutorial 02 PASDocument4 pagesTutorial 02 PASWinnie NguyễnNo ratings yet
- Tutorial 9 - SolutionsDocument21 pagesTutorial 9 - SolutionsPhạm Thanh Hương CaoNo ratings yet
- Ch24 AnswersDocument23 pagesCh24 Answersamisha2562585No ratings yet
- Statistics - AssignmentDocument14 pagesStatistics - AssignmentRavinderpal S Wasu100% (1)
- Coporate FinanceDocument6 pagesCoporate Financeplayjake18No ratings yet
- H-311 Linear Regression Analysis With RDocument71 pagesH-311 Linear Regression Analysis With RNat Boltu100% (1)
- FINM2003 - Mid Semester Exam Sem 1 2015 (Suggested Solutions)Document6 pagesFINM2003 - Mid Semester Exam Sem 1 2015 (Suggested Solutions)JasonNo ratings yet
- Allama Iqbal Open University, Islamabad Warning: Department of StatisticsDocument3 pagesAllama Iqbal Open University, Islamabad Warning: Department of StatisticsSHAH RUKH KHANNo ratings yet
- Alpha Factors NorthfieldDocument28 pagesAlpha Factors NorthfieldstepchoinyNo ratings yet
- Prob 14Document6 pagesProb 14LaxminarayanaMurthyNo ratings yet
- Solutions Manual to accompany Introduction to Linear Regression AnalysisFrom EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisRating: 1 out of 5 stars1/5 (1)
- Data Interpretation Guide For All Competitive and Admission ExamsFrom EverandData Interpretation Guide For All Competitive and Admission ExamsRating: 2.5 out of 5 stars2.5/5 (6)
- Chi-Squared Test Worked ExampleDocument2 pagesChi-Squared Test Worked ExampleAbhijit MandalNo ratings yet
- Makalah Pengaruh Safety LeadershipDocument26 pagesMakalah Pengaruh Safety LeadershipIntan AyuNo ratings yet
- Econ205 Final AnsDocument7 pagesEcon205 Final Anseya KhamassiNo ratings yet
- Chapter 3 Slides #4 BoxplotsDocument10 pagesChapter 3 Slides #4 BoxplotsMinh NgọcNo ratings yet
- Analisis PengaruhDocument14 pagesAnalisis Pengaruhabbydzar al ghiffaryNo ratings yet
- SHS Fundamentals of Statistics PDFDocument210 pagesSHS Fundamentals of Statistics PDFRose Anne CaringalNo ratings yet
- Tutorial 5Document2 pagesTutorial 5Ainaasyahirah RosidanNo ratings yet
- Chapter 16. Simultaneous Equations ModelsDocument23 pagesChapter 16. Simultaneous Equations ModelsValeria Silva VeasNo ratings yet
- DBA-5102 Statistics - For - Management AssignmentDocument12 pagesDBA-5102 Statistics - For - Management AssignmentPrasanth K SNo ratings yet
- 13 SBE11e PPT Ch10bDocument20 pages13 SBE11e PPT Ch10bGlen JoshuaNo ratings yet
- Pengaruh Clay Therapy Terhadap Kecemasan Anak Usia Prasekolah Yang Menjalani Prosedur Invasif Di Rsud Al-IhsanDocument15 pagesPengaruh Clay Therapy Terhadap Kecemasan Anak Usia Prasekolah Yang Menjalani Prosedur Invasif Di Rsud Al-IhsanAnisa KusumaNo ratings yet
- Regression: Nama:Chaidir Trisakti Nim:1571041012 Kelas:IICDocument2 pagesRegression: Nama:Chaidir Trisakti Nim:1571041012 Kelas:IICChaidir Tri SaktiNo ratings yet
- Beale Et Al 2010 Regression Analysis of Spatial DataDocument19 pagesBeale Et Al 2010 Regression Analysis of Spatial DataValdemir SousaNo ratings yet
- Repeated Measures ANOVADocument22 pagesRepeated Measures ANOVAanderaltunaNo ratings yet
- Statistics and Probability USLeM Q3 Week 8Document8 pagesStatistics and Probability USLeM Q3 Week 8RICARDO RAQUIONNo ratings yet
- A New Criterion For Assesing Discriminant Validity - HenselerDocument21 pagesA New Criterion For Assesing Discriminant Validity - HenselerCUCUTA JUAN DIEGO HERNANDEZ LALINDENo ratings yet
- λ β β η η Mtbf Mttf Mtbf R2 R2 R2 R2 g g: Swing Bearing Normal Exponencial Weibull 2P Weibull 3P (t)Document17 pagesλ β β η η Mtbf Mttf Mtbf R2 R2 R2 R2 g g: Swing Bearing Normal Exponencial Weibull 2P Weibull 3P (t)Jose Carlos Quispe RanillaNo ratings yet
- Demand Estimation and Forecasting: Managerial Economics, 2eDocument13 pagesDemand Estimation and Forecasting: Managerial Economics, 2eMandira PrakashNo ratings yet
- BS INdiDocument8 pagesBS INdiAkanksha ChaudharyNo ratings yet
- SM025 - Topic 6 Data DescriptiveDocument15 pagesSM025 - Topic 6 Data DescriptiveJade Ng100% (1)
- Data Analyst Certification Study GuideDocument5 pagesData Analyst Certification Study GuideALEX ANDRe ARQUE MU�OZNo ratings yet
- ISO 3534 Statistical TerminologyDocument10 pagesISO 3534 Statistical TerminologyLeo TsaoNo ratings yet
- Question 1. (12 Marks) : Module #3: Sampling Distributions, Estimates, and Hypothesis TestingDocument11 pagesQuestion 1. (12 Marks) : Module #3: Sampling Distributions, Estimates, and Hypothesis TestingSagar AggarwalNo ratings yet
- Edit - Randomized Block Design Baru Banget 7.41Document43 pagesEdit - Randomized Block Design Baru Banget 7.41erninda suputriNo ratings yet
- Metlit-02 Populasi, Sampel & Variabel - Prof. Dr. Sudigdo S, SpA (K)Document55 pagesMetlit-02 Populasi, Sampel & Variabel - Prof. Dr. Sudigdo S, SpA (K)Laurencia LenyNo ratings yet
- Jurnal Pengaruh Prestasi Kerja, Pendidikan, Dan Masa Kerja Terhadap Promosi JabatanDocument19 pagesJurnal Pengaruh Prestasi Kerja, Pendidikan, Dan Masa Kerja Terhadap Promosi JabatanSiza MosaNo ratings yet
- Week 6-MCQ in EBP-1Document36 pagesWeek 6-MCQ in EBP-1Geeta SureshNo ratings yet
- Applying The Concepts: Assignment 2Document2 pagesApplying The Concepts: Assignment 2ahmed tarekNo ratings yet
- Northern - Southeast Case StudyDocument8 pagesNorthern - Southeast Case StudyYogeshLuhar100% (3)
- MSC 1st Physics Mathaematical PhysicsDocument51 pagesMSC 1st Physics Mathaematical PhysicsNaresh GulatiNo ratings yet