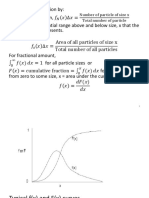
You might also like
- MOCK STATS TEST - Solutions Dec 2021Document10 pagesMOCK STATS TEST - Solutions Dec 2021Riddhi LalpuriaNo ratings yet
- How To Perform A MANOVA in SPSSDocument9 pagesHow To Perform A MANOVA in SPSSadurahulNo ratings yet
- 10 RepeatedMeasuresAndMixedANOVADocument30 pages10 RepeatedMeasuresAndMixedANOVACristina Roxana SarpeNo ratings yet
- Regression AnalysisDocument13 pagesRegression AnalysissrikanthNo ratings yet
- Timothy M. Hagle - Basic Math For Social Scientists - Concepts (Quantitative Applications in The Social Sciences) - Sage Publications, Inc (1995) PDFDocument107 pagesTimothy M. Hagle - Basic Math For Social Scientists - Concepts (Quantitative Applications in The Social Sciences) - Sage Publications, Inc (1995) PDFMizanur RahmanNo ratings yet
- Introduction To Econometrics - Stock & Watson - CH 4 SlidesDocument84 pagesIntroduction To Econometrics - Stock & Watson - CH 4 SlidesAntonio Alvino100% (2)
- One Way Anova Research Objective: Is There A Significance Difference in Preference of Travel Due To DifferentDocument7 pagesOne Way Anova Research Objective: Is There A Significance Difference in Preference of Travel Due To DifferentAkriti ShahNo ratings yet
- Two Way AnovaDocument12 pagesTwo Way AnovaDuaa ArifNo ratings yet
- PLS205 !! Lab 9 !! March 6, 2014 Topic 13: Covariance AnalysisDocument9 pagesPLS205 !! Lab 9 !! March 6, 2014 Topic 13: Covariance AnalysisPETERNo ratings yet
- HypermarketDocument6 pagesHypermarketfatin hidayahNo ratings yet
- Amos 05 Cfaefa PDFDocument50 pagesAmos 05 Cfaefa PDFAnonymous HWsv9pBUhNo ratings yet
- Kubsa Guyo Advance BiostatisticDocument30 pagesKubsa Guyo Advance BiostatistickubsaNo ratings yet
- Measures of VariabilityDocument19 pagesMeasures of VariabilityLAWAG, Angelene Mae I.No ratings yet
- Appropiate Critical Values Multivariate Outliers Mahalanobis DistanceDocument10 pagesAppropiate Critical Values Multivariate Outliers Mahalanobis DistanceAnonymous 3SfBIFNo ratings yet
- CHE 321 Wk3 Slide 4Document27 pagesCHE 321 Wk3 Slide 4Ochogu IkechukwuNo ratings yet
- Assignment Word FileDocument47 pagesAssignment Word FileTejinder SinghNo ratings yet
- Test 1Document10 pagesTest 1Brandeice BarrettNo ratings yet
- Lab 4Document5 pagesLab 4MaraweleNo ratings yet
- Gouni HW#6Document9 pagesGouni HW#6haritha vithanalaNo ratings yet
- Assignment 8 ISE 500: Groups CountDocument22 pagesAssignment 8 ISE 500: Groups CountAnanth RameshNo ratings yet
- ANOVA Unit3 BBA504ADocument9 pagesANOVA Unit3 BBA504ADr. Meghdoot GhoshNo ratings yet
- 20 Elements of Eco No Metrics Chapter1Document8 pages20 Elements of Eco No Metrics Chapter1Maria DoanNo ratings yet
- The Greatest Blessing in Life Is in Giving and Not TakingDocument30 pagesThe Greatest Blessing in Life Is in Giving and Not TakingSafi SheikhNo ratings yet
- PSYC 305 Assignment 2Document2 pagesPSYC 305 Assignment 2shaheenfakeNo ratings yet
- How To Perform A MANOVA in SPSSDocument9 pagesHow To Perform A MANOVA in SPSSsita_adhiNo ratings yet
- Chapter 13 Text PDFDocument31 pagesChapter 13 Text PDFKarthik Miduthuru100% (1)
- AQM Regression Day 3 Class WorkDocument4 pagesAQM Regression Day 3 Class Workaneeqa.shahzadNo ratings yet
- Single Factor Anova Test: Groups Count Sum Average VarianceDocument4 pagesSingle Factor Anova Test: Groups Count Sum Average VarianceShilpi ShroffNo ratings yet
- Research Notes (Chapter 3-5)Document14 pagesResearch Notes (Chapter 3-5)Joong SeoNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- 11-Anova For BRMDocument39 pages11-Anova For BRMabhdonNo ratings yet
- Laboratory Activity 2 StatisticsDocument17 pagesLaboratory Activity 2 StatisticsJENNEFER LEENo ratings yet
- RM Assignment 2Document9 pagesRM Assignment 27 EduNo ratings yet
- Spss Anova PDFDocument16 pagesSpss Anova PDFNovi AriantiNo ratings yet
- Ho There Is No Significant Difference Among The Means. Ha There Is A Significant Difference Among The MeansDocument3 pagesHo There Is No Significant Difference Among The Means. Ha There Is A Significant Difference Among The MeansClarissa TeodoroNo ratings yet
- Anova Satu ArahDocument69 pagesAnova Satu ArahjanitaNo ratings yet
- Anova-Pant Sir, EnglishDocument11 pagesAnova-Pant Sir, EnglishTamika LeeNo ratings yet
- Regression Analysis and Its Interpretation With SpssDocument4 pagesRegression Analysis and Its Interpretation With SpssChakraKhadkaNo ratings yet
- ANCOVA - SPSS Interpretation - DVD RatingDocument13 pagesANCOVA - SPSS Interpretation - DVD RatingAhhhhhhhNo ratings yet
- Stats SemisDocument18 pagesStats SemisMary Angelie SenarioNo ratings yet
- One-Way Analysis of Variance (ANOVA) : AssumptionsDocument9 pagesOne-Way Analysis of Variance (ANOVA) : AssumptionsShanice BurnettNo ratings yet
- Econ Last FinalsDocument31 pagesEcon Last FinalspissotytNo ratings yet
- 578 Assignment 1 F14 SolDocument15 pages578 Assignment 1 F14 Solaman_nsuNo ratings yet
- AnovaDocument46 pagesAnovasampritcNo ratings yet
- Chapter 4Document9 pagesChapter 4Rizwan RaziNo ratings yet
- Efa ManualDocument11 pagesEfa ManualJun Virador MagallonNo ratings yet
- Estepa, Edrianne M.Document8 pagesEstepa, Edrianne M.Edrianne EstepaNo ratings yet
- Model SummaryDocument2 pagesModel SummaryForza RagazziNo ratings yet
- 04 Simple AnovaDocument9 pages04 Simple AnovaShashi KapoorNo ratings yet
- Regression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inDocument16 pagesRegression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inPavan PearliNo ratings yet
- Statistics Module 11Document9 pagesStatistics Module 11Gaile YabutNo ratings yet
- AnovaDocument16 pagesAnovajakejakeNo ratings yet
- 6A-1 - ANOVA (F Test) Updated PDFDocument36 pages6A-1 - ANOVA (F Test) Updated PDFZergaia WPNo ratings yet
- FINAL EXAM IN E-WPS OfficeDocument12 pagesFINAL EXAM IN E-WPS OfficeLorwel ReyesNo ratings yet
- Descriptive Statistics: Data Analysis AssignmentDocument9 pagesDescriptive Statistics: Data Analysis AssignmentSuriya SamNo ratings yet
- Report Has Prepared by Kamran Selimli and Sahil MesimovDocument14 pagesReport Has Prepared by Kamran Selimli and Sahil MesimovsahilNo ratings yet
- Ancova - Using SpssDocument12 pagesAncova - Using SpssazzuryNo ratings yet
- (Velda Rifka Almira) Statistical AnalysisDocument13 pages(Velda Rifka Almira) Statistical Analysis22098713No ratings yet
- Statistical Inference for Models with Multivariate t-Distributed ErrorsFrom EverandStatistical Inference for Models with Multivariate t-Distributed ErrorsNo ratings yet
- Nonparametric Hypothesis Testing: Rank and Permutation Methods with Applications in RFrom EverandNonparametric Hypothesis Testing: Rank and Permutation Methods with Applications in RNo ratings yet
- An Introduction to Stochastic Modeling, Student Solutions Manual (e-only)From EverandAn Introduction to Stochastic Modeling, Student Solutions Manual (e-only)No ratings yet
- Applied Ba YesDocument13 pagesApplied Ba Yesbozzaitabob4493No ratings yet
- DOM105 Session 27Document6 pagesDOM105 Session 27DevanshiNo ratings yet
- ANSWER - Cost Accounting Session 2Document8 pagesANSWER - Cost Accounting Session 2Vincenttio le CloudNo ratings yet
- Tunnelling and Underground Space Technology: J. Hassanpour, J. Rostami, S. Tarigh Azali, J. ZhaoDocument10 pagesTunnelling and Underground Space Technology: J. Hassanpour, J. Rostami, S. Tarigh Azali, J. ZhaoJovanNo ratings yet
- House Price Prediction Using Machine LearningDocument6 pagesHouse Price Prediction Using Machine LearningIJRASETPublicationsNo ratings yet
- Linear Regression Models For Panel Data Using SAS, STATA, LIMDEP and SPSSDocument67 pagesLinear Regression Models For Panel Data Using SAS, STATA, LIMDEP and SPSSLuísa Martins100% (2)
- Modelling Time Series With Calender VariationDocument10 pagesModelling Time Series With Calender VariationIvani VolliNo ratings yet
- Introduction Econometrics NotesDocument7 pagesIntroduction Econometrics Notesjerry veraNo ratings yet
- 2023 Ijmfa-110014 PPVDocument22 pages2023 Ijmfa-110014 PPVRe DreamNo ratings yet
- Econometrics Lecture NotesDocument16 pagesEconometrics Lecture NotesfarmerNo ratings yet
- Tutorial Chapter 5 Bivariate Analysis - SolutionDocument5 pagesTutorial Chapter 5 Bivariate Analysis - SolutionAthira RidwanNo ratings yet
- 2 Slides TF ReviewDocument203 pages2 Slides TF ReviewZoe RossiNo ratings yet
- Homoscedasticity Assumption in Linear Regression vs. Concept of Studentized Residuals - Cross ValidaDocument1 pageHomoscedasticity Assumption in Linear Regression vs. Concept of Studentized Residuals - Cross ValidavaskoreNo ratings yet
- Lecture 15-3 Cross Section and Panel (Truncated Regression, Heckman Sample Selection)Document50 pagesLecture 15-3 Cross Section and Panel (Truncated Regression, Heckman Sample Selection)Daniel Bogiatzis GibbonsNo ratings yet
- ARDLDocument3 pagesARDLMohammed SeidNo ratings yet
- Shopping Via Instagram The Influence of Perceptions of Value, Benefits and Risks On PurchaseDocument23 pagesShopping Via Instagram The Influence of Perceptions of Value, Benefits and Risks On PurchasemarinaNo ratings yet
- Unit 2 HR Planning and Job AnalysisDocument18 pagesUnit 2 HR Planning and Job AnalysisCharlie PuthNo ratings yet
- Forecasting: Operations ManagementDocument50 pagesForecasting: Operations ManagementoumaimaNo ratings yet
- Regression AnalysisDocument22 pagesRegression AnalysisJoanna Marie SimonNo ratings yet
- Impact of Staff Turnover On The Financial Performance of Nigerian Deposit Money BanksDocument12 pagesImpact of Staff Turnover On The Financial Performance of Nigerian Deposit Money BanksEditor IJTSRDNo ratings yet
- The Impact of Interest Rate On Bank Deposits Evidence From The Nigerian Banking SectorDocument18 pagesThe Impact of Interest Rate On Bank Deposits Evidence From The Nigerian Banking SectorMelson Frengki BiafNo ratings yet
- 1 PDFDocument44 pages1 PDFAftab KhanNo ratings yet
- Complexity Metrics For Statechart DiagramsDocument17 pagesComplexity Metrics For Statechart DiagramsAnonymous rVWvjCRLGNo ratings yet
- The Implementation of Green Accounting and Its Implication On Financial Reporting Quality in IndonesiaDocument9 pagesThe Implementation of Green Accounting and Its Implication On Financial Reporting Quality in IndonesiaWindaNo ratings yet
- Gorg 2001Document17 pagesGorg 2001mariam shetemNo ratings yet
- ICA-ANN, ANN and Multiple Regression Models For Prediction of SurfaceDocument13 pagesICA-ANN, ANN and Multiple Regression Models For Prediction of SurfaceHaha ZazaNo ratings yet
- RegressionDocument6 pagesRegressionian92193No ratings yet