You might also like
- 100 Excel Simulations: Using Excel to Model Risk, Investments, Genetics, Growth, Gambling and Monte Carlo AnalysisFrom Everand100 Excel Simulations: Using Excel to Model Risk, Investments, Genetics, Growth, Gambling and Monte Carlo AnalysisRating: 4.5 out of 5 stars4.5/5 (5)
- TRONZ-V2 User ManualDocument29 pagesTRONZ-V2 User ManualAjang RahmatNo ratings yet
- Orbit Steam Turbine Seal Rub - OrbitDocument14 pagesOrbit Steam Turbine Seal Rub - OrbitHatem Ali100% (3)
- Machine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonFrom EverandMachine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonNo ratings yet
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- D4762 1166550-1Document21 pagesD4762 1166550-1khudhayer1970No ratings yet
- AngularJS W3schholsDocument180 pagesAngularJS W3schholsEBookTutorials100% (2)
- PCS Ferguson Multi Stage Plunger Lift PresentationDocument16 pagesPCS Ferguson Multi Stage Plunger Lift Presentationawise118750% (2)
- Practice Problems AnsDocument16 pagesPractice Problems AnsSanskar SinghalNo ratings yet
- Data Structures: Will It Work?Document9 pagesData Structures: Will It Work?Hamed NilforoshanNo ratings yet
- Binary Tree Research PaperDocument7 pagesBinary Tree Research Paperlbiscyrif100% (1)
- DSAL Ass5 WriteupDocument10 pagesDSAL Ass5 WriteupGaurav ShindeNo ratings yet
- Heaps, Heapsort and Priority Queues: No Gaps in It. The Last Two Conditions Give A Heap A Weak Amount of OrderDocument24 pagesHeaps, Heapsort and Priority Queues: No Gaps in It. The Last Two Conditions Give A Heap A Weak Amount of Orderawadhesh.kumarNo ratings yet
- Binary Search TreesDocument39 pagesBinary Search Treesআরব বেদুঈনNo ratings yet
- 1 Preliminaries: Data Structures and AlgorithmsDocument21 pages1 Preliminaries: Data Structures and AlgorithmsPavan RsNo ratings yet
- Data Structutes Using C'Document7 pagesData Structutes Using C'Sumitavo NagNo ratings yet
- Segment Tree PDFDocument5 pagesSegment Tree PDFNeeraj SharmaNo ratings yet
- Unit 11 Dynamic Programming - 2: StructureDocument25 pagesUnit 11 Dynamic Programming - 2: StructureRaj SinghNo ratings yet
- DataStructures NotesDocument43 pagesDataStructures NotesfcmitcNo ratings yet
- TCS and InfosysDocument5 pagesTCS and InfosysAmanpreet 2003052No ratings yet
- Data Structure MaterialDocument22 pagesData Structure Materialgani525No ratings yet
- Internal Sorting:Definition: When The Entire Dataset Can FitDocument12 pagesInternal Sorting:Definition: When The Entire Dataset Can FitShubham KumarNo ratings yet
- DSA & DAA Fast StudyDocument6 pagesDSA & DAA Fast StudyrkpythonNo ratings yet
- mcs-021 3 SemDocument19 pagesmcs-021 3 Semhimanshu yadavNo ratings yet
- Swapping Variables Without Additional Space: Previous EntriesDocument13 pagesSwapping Variables Without Additional Space: Previous EntriesUtkarsh BhardwajNo ratings yet
- DS ImportentDocument17 pagesDS Importentgoswamiakshay777No ratings yet
- Fast Algorithms For Mining Association RulesDocument2 pagesFast Algorithms For Mining Association Rulesगोपाल शर्माNo ratings yet
- Online Mining of Data To Generate Association Rule Mining in Large DatabasesDocument6 pagesOnline Mining of Data To Generate Association Rule Mining in Large Databasessravya_373771414No ratings yet
- DSA and Algo For InterviewDocument15 pagesDSA and Algo For Interviewmuhammadibrarw4No ratings yet
- 1.when A Sparse Matrix Is Represented With A 2-Dimensional Array, WeDocument6 pages1.when A Sparse Matrix Is Represented With A 2-Dimensional Array, Wekhushinagar9009No ratings yet
- BINARY Search TreeDocument22 pagesBINARY Search TreeMallinath KhondeNo ratings yet
- DS Class Notes PDFDocument17 pagesDS Class Notes PDFpardeshisankalp1804No ratings yet
- DS - Unit 3 - NotesDocument13 pagesDS - Unit 3 - NotesManikyarajuNo ratings yet
- 664a040afe43076cc6040354 CSI 06Document30 pages664a040afe43076cc6040354 CSI 06dungdpt1106No ratings yet
- Ex. No. 6 Implementation of Binary Search TreeDocument8 pagesEx. No. 6 Implementation of Binary Search TreeaddssdfaNo ratings yet
- Assignment 03Document9 pagesAssignment 03dilhaniNo ratings yet
- Case 2Document20 pagesCase 2karenNo ratings yet
- Comp 258: Assignment 2Document9 pagesComp 258: Assignment 2Hamza SheikhNo ratings yet
- Mcoo68 Smu Mca Sem2 2011Document23 pagesMcoo68 Smu Mca Sem2 2011Nitin SivachNo ratings yet
- Dsmaterials VasuDocument49 pagesDsmaterials VasuKiran All Iz Well100% (1)
- DsMahiwaya PDFDocument21 pagesDsMahiwaya PDFMahiwaymaNo ratings yet
- Abstract Data StructureDocument18 pagesAbstract Data StructureVedant PatilNo ratings yet
- Standardscaler: The Idea Behind Is That It Will Transform Your Data Such That ItsDocument6 pagesStandardscaler: The Idea Behind Is That It Will Transform Your Data Such That ItsRishikesh ThakurNo ratings yet
- CS301FinaltermMCQsbyDr TariqHanifDocument15 pagesCS301FinaltermMCQsbyDr TariqHanifRizwanIlyasNo ratings yet
- Adsa-2unit Heap ContinueDocument20 pagesAdsa-2unit Heap Continuesharmilahema33No ratings yet
- Binary Search TreesDocument19 pagesBinary Search Treessmitrajsinh1873No ratings yet
- Data Structures - CS301 Power Point Slides Lecture 01Document48 pagesData Structures - CS301 Power Point Slides Lecture 01anumNo ratings yet
- Advanced PascalDocument38 pagesAdvanced PascalMichalis IrakleousNo ratings yet
- Python For Data Science Nympy and PandasDocument4 pagesPython For Data Science Nympy and PandasStocknEarnNo ratings yet
- CS301 Lec01Document48 pagesCS301 Lec01vp97btsm9jNo ratings yet
- Machine Learning and Pattern Recognition Week 8 Neural Net IntroDocument3 pagesMachine Learning and Pattern Recognition Week 8 Neural Net IntrozeliawillscumbergNo ratings yet
- Hashing Refers To The Process of Generating A Fixed-Size Output From An Input of Variable SizeDocument10 pagesHashing Refers To The Process of Generating A Fixed-Size Output From An Input of Variable SizeManthena Narasimha RajuNo ratings yet
- Worksheet On Data StructureDocument8 pagesWorksheet On Data StructureWiki EthiopiaNo ratings yet
- AbInitio FAQsDocument14 pagesAbInitio FAQssarvesh_mishraNo ratings yet
- Trees: Binary Search (BST), Insertion and Deletion in BST: Unit VDocument26 pagesTrees: Binary Search (BST), Insertion and Deletion in BST: Unit VDheresh SoniNo ratings yet
- JNTUA Advanced Data Structures and Algorithms Lab Manual R20Document71 pagesJNTUA Advanced Data Structures and Algorithms Lab Manual R20sandeepabi25No ratings yet
- Research Paper On Binary Search TreeDocument4 pagesResearch Paper On Binary Search Treec9qw1cjs100% (1)
- Topic 5 - Abstract Data Structures HLDocument10 pagesTopic 5 - Abstract Data Structures HL6137 DenizeNo ratings yet
- Advance Data Structure ASSIGNMENTDocument13 pagesAdvance Data Structure ASSIGNMENTMudasir KhanNo ratings yet
- 21 Collections of Data: Standard "Collection Classes"Document66 pages21 Collections of Data: Standard "Collection Classes"api-3745065No ratings yet
- Data Structure1Document8 pagesData Structure1SelvaKrishnanNo ratings yet
- BDA Assignment2 BE6 20Document9 pagesBDA Assignment2 BE6 20vardhan mordhariaNo ratings yet
- Program 3Document5 pagesProgram 3api-515961562No ratings yet
- Labsheet 9Document16 pagesLabsheet 9SANJANA SANJANANo ratings yet
- TX DL 2016Document96 pagesTX DL 2016vreddy123No ratings yet
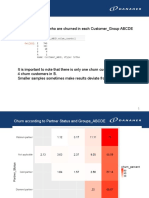
- No of Customers Who Are Churned in Each Customer - Group ABCDEDocument27 pagesNo of Customers Who Are Churned in Each Customer - Group ABCDEPallav AnandNo ratings yet
- Resume Ahmed ZaidiDocument2 pagesResume Ahmed ZaidiPallav AnandNo ratings yet
- Artofdatascience PDFDocument162 pagesArtofdatascience PDForchid21No ratings yet
- Machinelearningsalon Kit 28-12-2014Document155 pagesMachinelearningsalon Kit 28-12-2014Vladimir PodshivalovNo ratings yet
- Caltrain Fares Effective 2-28-16113161316Document1 pageCaltrain Fares Effective 2-28-16113161316Pallav AnandNo ratings yet
- Sanjay Natraj: Data Scientist/hadoop EngineerDocument2 pagesSanjay Natraj: Data Scientist/hadoop EngineerPallav AnandNo ratings yet
- Machine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Document36 pagesMachine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Pallav AnandNo ratings yet
- IsenDocument4 pagesIsenPallav AnandNo ratings yet
- Students As FormDocument2 pagesStudents As FormPallav AnandNo ratings yet
- 6 Chi SquareDocument3 pages6 Chi SquarePallav AnandNo ratings yet
- 3.1 Hypothesis Testing (Critical Value Approach) : StatisticsDocument3 pages3.1 Hypothesis Testing (Critical Value Approach) : StatisticsPallav AnandNo ratings yet
- AllDocument506 pagesAllPallav AnandNo ratings yet
- 01 IntroductionDocument60 pages01 IntroductionPallav AnandNo ratings yet
- 1SFC151003C0201 79Document1 page1SFC151003C0201 79psatyasrinivasNo ratings yet
- Lecture 2: Wavefront and Amplitude Division Class of InterferenceDocument8 pagesLecture 2: Wavefront and Amplitude Division Class of InterferenceShouvik MitraNo ratings yet
- BAM AnalysisDocument15 pagesBAM Analysispratik panchalNo ratings yet
- DsPIC30F Motor ControlDocument21 pagesDsPIC30F Motor Controlboyluca100% (3)
- An Essay Concerning Human UnderstandingDocument6 pagesAn Essay Concerning Human UnderstandingKrishnaNo ratings yet
- PSR-... - 24UC/ESA2/4X1/1X2/B: Safety Relay For Emergency Stop and Safety Door MonitoringDocument16 pagesPSR-... - 24UC/ESA2/4X1/1X2/B: Safety Relay For Emergency Stop and Safety Door MonitoringJoão BaptistaNo ratings yet
- GFG Flipkart QuestionsDocument39 pagesGFG Flipkart QuestionsRajiv Poplai100% (1)
- Summative Test 2 Unit 2 Module 2 Part 2Document2 pagesSummative Test 2 Unit 2 Module 2 Part 2sinunuc nhsNo ratings yet
- Migration ChecklistDocument19 pagesMigration ChecklistAbhishek GuptaNo ratings yet
- Perimeter Greater Than AreaDocument5 pagesPerimeter Greater Than AreaS.Srinivasan ('Chinu'); Renu KhannaNo ratings yet
- Compress To Impress by Arup Nanda: Solution: CompressionDocument9 pagesCompress To Impress by Arup Nanda: Solution: CompressionSHAHID FAROOQNo ratings yet
- 5.3. Transition ElementsDocument12 pages5.3. Transition ElementsTahmina MaryamNo ratings yet
- Chapter 3 Homework SolutionDocument23 pagesChapter 3 Homework SolutionsyarifahafizahNo ratings yet
- Experiment 4Document2 pagesExperiment 4DARREN JOHN MUUWILNo ratings yet
- Values of C For Simply Supported Beams W-Shapes: Table 3-1 Table 3-2Document31 pagesValues of C For Simply Supported Beams W-Shapes: Table 3-1 Table 3-2MarkNo ratings yet
- Dr.R.Venkatesan MatricesDocument63 pagesDr.R.Venkatesan MatricesSai Vasanth GNo ratings yet
- System Restructuring, Deregulation (MM: Point Appreciated: Exam, 30, HRS)Document10 pagesSystem Restructuring, Deregulation (MM: Point Appreciated: Exam, 30, HRS)MAHAK GARGNo ratings yet
- Coingecko Api: The World'S Most Comprehensive Cryptocurrency DataDocument13 pagesCoingecko Api: The World'S Most Comprehensive Cryptocurrency Datamas gantengNo ratings yet
- Basic Steam Pipe Sizing Charts: Technical ManualDocument4 pagesBasic Steam Pipe Sizing Charts: Technical ManualAymen KhlifiNo ratings yet
- A Preliminary Acoustical Study of Some Old Temples in Vadodara PDFDocument9 pagesA Preliminary Acoustical Study of Some Old Temples in Vadodara PDFiaetsdiaetsd100% (2)
- Ecosystems QP Edexcel IalDocument19 pagesEcosystems QP Edexcel IalAyesha TauseefNo ratings yet
- 002-00886 S29GL01GP S29GL512P S29GL256P S29GL128P 1 Gbit 512 256 128 Mbit 3 V Page Flash With 90 NM MirrorBit Process TechnologyDocument82 pages002-00886 S29GL01GP S29GL512P S29GL256P S29GL128P 1 Gbit 512 256 128 Mbit 3 V Page Flash With 90 NM MirrorBit Process TechnologymegatornadoNo ratings yet
- TE - Internship Report TanviDocument31 pagesTE - Internship Report TanviDARSHAN JADHAVNo ratings yet
- Machining 2Document19 pagesMachining 2Kah KiatNo ratings yet
- Mastermind (Animal Friends)Document2 pagesMastermind (Animal Friends)Deepshikha KhulbeNo ratings yet