You might also like
- LEARN MPLS FROM SCRATCH PART-B: A Beginners guide to next level of networkingFrom EverandLEARN MPLS FROM SCRATCH PART-B: A Beginners guide to next level of networkingNo ratings yet
- Conceptual Programming: Conceptual Programming: Learn Programming the old way!From EverandConceptual Programming: Conceptual Programming: Learn Programming the old way!No ratings yet
- Parallel Execution With Data-Driven Multithreading: Kyriakos Stavrou, Paraskevas Evripidou, and Pedro TrancosoDocument4 pagesParallel Execution With Data-Driven Multithreading: Kyriakos Stavrou, Paraskevas Evripidou, and Pedro TrancosoPaulo MeloNo ratings yet
- Lab 1Document2 pagesLab 1imsNo ratings yet
- 19 7960 07 NotesDocument17 pages19 7960 07 NotesMuhammad Fahmi PamungkasNo ratings yet
- Mid Sem QP&SolutionDocument7 pagesMid Sem QP&Solutionyadavsnair000No ratings yet
- Package Parallel': R-Core October 19, 2013Document13 pagesPackage Parallel': R-Core October 19, 2013Freeman JacksonNo ratings yet
- Day 2 1 Advanced-OpenmpDocument52 pagesDay 2 1 Advanced-OpenmpJAMEEL AHMADNo ratings yet
- Cache-Oblivious VAT AlgorithmsDocument6 pagesCache-Oblivious VAT AlgorithmszaptheimpalerNo ratings yet
- Report - Viber StringDocument26 pagesReport - Viber StringLopUiNo ratings yet
- CS 162 Computer Architecture Lecture 3: Pipelining Contd.: Instructor: L.N. BhuyanDocument21 pagesCS 162 Computer Architecture Lecture 3: Pipelining Contd.: Instructor: L.N. Bhuyanعلي سعدهاشمNo ratings yet
- LEC6 parallelAlg-BroadcastingDocument15 pagesLEC6 parallelAlg-BroadcastingSAINo ratings yet
- Parallel Databases: Solutions To Practice ExercisesDocument3 pagesParallel Databases: Solutions To Practice ExercisesNUBG GamerNo ratings yet
- Lammps OverdriveDocument28 pagesLammps OverdrivepranavNo ratings yet
- Factorisation MemoireDocument21 pagesFactorisation MemoireivanarcilaNo ratings yet
- Solution 2-DDDocument70 pagesSolution 2-DDKugaRamananNo ratings yet
- Optimal Streamed Linear PermutationsDocument2 pagesOptimal Streamed Linear PermutationsAnkit ParasharNo ratings yet
- 04 CPD OpenMP Sync TasksDocument49 pages04 CPD OpenMP Sync TasksSebastian ChimalNo ratings yet
- Lec NotesDocument50 pagesLec Noteshvs1910No ratings yet
- Dual-Field Multiplier Architecture For Cryptographic ApplicationsDocument5 pagesDual-Field Multiplier Architecture For Cryptographic ApplicationsAkshansh DwivediNo ratings yet
- ECE 313 Computer Organization Name Solution Final Exam December 14, 2002Document9 pagesECE 313 Computer Organization Name Solution Final Exam December 14, 2002Minh Hà QuangNo ratings yet
- ParallelDocument14 pagesParallelHAMDANI IbrahimNo ratings yet
- Contest Task 1.9Document16 pagesContest Task 1.9MarkNo ratings yet
- L7 Multicore 2Document22 pagesL7 Multicore 2AsHraf G. ElrawEiNo ratings yet
- 2005 Spring Exam2 SolDocument6 pages2005 Spring Exam2 SolNipun HarshaNo ratings yet
- 12.revision ParallelizationDocument30 pages12.revision ParallelizationspareyashNo ratings yet
- Introduction To Cmos Vlsi Design: Logical EffortDocument47 pagesIntroduction To Cmos Vlsi Design: Logical EffortSam Xin MinNo ratings yet
- Fdi 2008 Lecture6Document39 pagesFdi 2008 Lecture6api-27351105100% (1)
- Image Processing On The MPP (Massively Parallel Processor)Document10 pagesImage Processing On The MPP (Massively Parallel Processor)edgy-baud.00No ratings yet
- IntroductionDocument46 pagesIntroductionAli HassanNo ratings yet
- Thinning Algorithms Arabic OCR: Two Parallel Thinning AlDocument4 pagesThinning Algorithms Arabic OCR: Two Parallel Thinning Alapi-3754855No ratings yet
- Hardware Multiplier Accumulator For SIDH ProtocolDocument4 pagesHardware Multiplier Accumulator For SIDH ProtocolMircea PetrescuNo ratings yet
- qt6j57h5zw NosplashDocument2 pagesqt6j57h5zw Nosplashtab.abc.xyz.1No ratings yet
- Parallel Computing and Openmp Tutorial: Shao-Ching HuangDocument58 pagesParallel Computing and Openmp Tutorial: Shao-Ching HuangpraphultmenonNo ratings yet
- Moshell CommandsDocument11 pagesMoshell Commandswafa wafaNo ratings yet
- Performance Comparison of FPGA, GPU and CPU in Image ProcessingDocument7 pagesPerformance Comparison of FPGA, GPU and CPU in Image ProcessingA. HNo ratings yet
- Parallel Programming Models: Sathish VadhiyarDocument32 pagesParallel Programming Models: Sathish VadhiyardhruvbhagtaniNo ratings yet
- Dungeon Session WorksheetDocument17 pagesDungeon Session WorksheetmokhtarkanNo ratings yet
- Colfax Shallow WaterDocument11 pagesColfax Shallow WaterTg DgNo ratings yet
- F-Stack - A Full User-Space Network Service With DMM: Based On DPDK, Freebsd Tcp/Ip StackDocument17 pagesF-Stack - A Full User-Space Network Service With DMM: Based On DPDK, Freebsd Tcp/Ip StackCharan MakkinaNo ratings yet
- Janitza UMG96SDocument8 pagesJanitza UMG96SElectromontaj CraiovaNo ratings yet
- Accelerating VGG16 DCNN With An FPGA: Dongjoon Park, Pranoti DhamalDocument7 pagesAccelerating VGG16 DCNN With An FPGA: Dongjoon Park, Pranoti DhamalpucalerroneNo ratings yet
- The PRAM Model and Algorithms: Advanced Topics Spring 2008Document24 pagesThe PRAM Model and Algorithms: Advanced Topics Spring 2008rajeevrajkumarNo ratings yet
- Simulating A CRCW Algorithm With An EREW Algorithm: Efficient Parallel Algorithms COMP308Document11 pagesSimulating A CRCW Algorithm With An EREW Algorithm: Efficient Parallel Algorithms COMP308Adhita D SelvarajNo ratings yet
- Pram Algorithms: Parallel and Distributed Algorithms BY Debdeep Mukhopadhyay AND Abhishek SomaniDocument17 pagesPram Algorithms: Parallel and Distributed Algorithms BY Debdeep Mukhopadhyay AND Abhishek SomaniPariti ShastriNo ratings yet
- Aiet MPDocument64 pagesAiet MPkmpshastryNo ratings yet
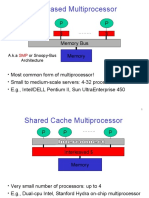
- Bus-Based Multiprocessor: A.K.A or Snoopy-Bus ArchitectureDocument54 pagesBus-Based Multiprocessor: A.K.A or Snoopy-Bus Architecturemadhu75No ratings yet
- Ejercicio 1 3Document17 pagesEjercicio 1 3SamuelNo ratings yet
- The Deadline-Based Scheduling of Divisible Real-Time Workloads On Multiprocessor PlatformsDocument16 pagesThe Deadline-Based Scheduling of Divisible Real-Time Workloads On Multiprocessor PlatformsAbd Hakim ZakariaNo ratings yet
- Operation Node B With Hyper Terminal PDFDocument29 pagesOperation Node B With Hyper Terminal PDFRAYENNE AYOUBENo ratings yet
- Lec8 MPIalgorithmDesignDocument12 pagesLec8 MPIalgorithmDesignAnirudh SethNo ratings yet
- Parallel Algorithms and Architectures 1Document22 pagesParallel Algorithms and Architectures 1Ismael Abdulkarim AliNo ratings yet
- CC LabDocument10 pagesCC LabSHASHANK .KOMMINENI (RA2111030010233)No ratings yet
- Exploiting Loop-Level Parallelism For Simd Arrays Using: OpenmpDocument12 pagesExploiting Loop-Level Parallelism For Simd Arrays Using: OpenmpSpin FotonioNo ratings yet
- Csitnepal: Unit 5 Central Processing Unit (CPU)Document13 pagesCsitnepal: Unit 5 Central Processing Unit (CPU)ishworNo ratings yet
- Assembly Directives in 8051 Microcontroller-1Document9 pagesAssembly Directives in 8051 Microcontroller-1ee210150900103No ratings yet
- This Study Resource Was: Pipelining AnalogyDocument58 pagesThis Study Resource Was: Pipelining Analogyarkaprava paulNo ratings yet
- Introduction To Assembler: Microcontroller VL Thomas Nowak TU WienDocument26 pagesIntroduction To Assembler: Microcontroller VL Thomas Nowak TU WienAli haider ZafarNo ratings yet
- Multi Gpu Programming With MpiDocument93 pagesMulti Gpu Programming With MpiOsamaNo ratings yet
- Scanned by CamscannerDocument3 pagesScanned by CamscannerKULDEEP NARAYAN MINJNo ratings yet
- Unit V 2Document16 pagesUnit V 2KULDEEP NARAYAN MINJNo ratings yet
- Multiprocessor Architectures and ProgrammingDocument89 pagesMultiprocessor Architectures and ProgrammingKULDEEP NARAYAN MINJNo ratings yet
- CT-2 Paper 2016Document12 pagesCT-2 Paper 2016KULDEEP NARAYAN MINJNo ratings yet
- Development Landscape (NON HANA)Document2 pagesDevelopment Landscape (NON HANA)Sharif RaziNo ratings yet
- Zcodesystem - High Converting Betting Offer On CBDocument6 pagesZcodesystem - High Converting Betting Offer On CBGAMING AND TECH ZONENo ratings yet
- Python Default ArgumentsDocument4 pagesPython Default ArgumentsratheeshbrNo ratings yet
- VLIW ArchitectureDocument5 pagesVLIW ArchitectureSharda Pratap Singh YadavNo ratings yet
- Source Code: Q5.Write A C Code To Implement SJF (Non-Preemptive) For 1. Arrival Time Is Not GivenDocument6 pagesSource Code: Q5.Write A C Code To Implement SJF (Non-Preemptive) For 1. Arrival Time Is Not Givenharshit ChaturvediNo ratings yet
- Lesson 1Document38 pagesLesson 1Dianne Jiecel CasimoNo ratings yet
- Change Management T QMDocument215 pagesChange Management T QMayoubNo ratings yet
- Dissertation Les Restos Du CoeurDocument5 pagesDissertation Les Restos Du CoeurPaperWritingServiceSuperiorpapersOmaha100% (1)
- An5816 How To Build stm32 Lpbam Application Using Stm32cubemx StmicroelectronicsDocument33 pagesAn5816 How To Build stm32 Lpbam Application Using Stm32cubemx StmicroelectronicsYure AlbuquerqueNo ratings yet
- Application Development and Emerging Technology All inDocument21 pagesApplication Development and Emerging Technology All inInah ValdezNo ratings yet
- AmpleTrails API Document EsslDocument8 pagesAmpleTrails API Document EsslManikandanNo ratings yet
- S52156 - A Bridge To 6G - Aerial Research and Innovation Platform - 1679440158411001f3YIDocument32 pagesS52156 - A Bridge To 6G - Aerial Research and Innovation Platform - 1679440158411001f3YIRed DragonNo ratings yet
- AHsd - Important LegalDocument6 pagesAHsd - Important LegalShrek SqueegeeNo ratings yet
- 2021 1 Eau p2 Estereotomía Programa de CursoDocument6 pages2021 1 Eau p2 Estereotomía Programa de CursoDixom Javier Monastoque RomeroNo ratings yet
- Kaspersky Internet SecurityDocument15 pagesKaspersky Internet SecurityNidhal CANo ratings yet
- WP EN Thermoforming With 3D Printed Molds Quick Start GuideDocument4 pagesWP EN Thermoforming With 3D Printed Molds Quick Start GuideZakaria BenyounessNo ratings yet
- Internship ReportDocument26 pagesInternship ReportSatyajeet RoutNo ratings yet
- Altair Licensing Quick Installation Guide PDFDocument15 pagesAltair Licensing Quick Installation Guide PDFRoni Ayan DebNo ratings yet
- .PK 274308Document24 pages.PK 274308faizanansar500No ratings yet
- ANAUDI HERNANDEZ Indictment PDFDocument64 pagesANAUDI HERNANDEZ Indictment PDFAANo ratings yet
- Data Flow Diagram (DFD)Document23 pagesData Flow Diagram (DFD)Evrich WatsonNo ratings yet
- DJI+Assistant+2+For+Phantom+Release+Notes (2 0 8)Document6 pagesDJI+Assistant+2+For+Phantom+Release+Notes (2 0 8)Novenska KlasnichovNo ratings yet
- Puppet Installation & ConfigurationDocument1,705 pagesPuppet Installation & Configurationkmk2099No ratings yet
- Intel SSD Toolbox 3.x Installation Guide 326039-004USDocument8 pagesIntel SSD Toolbox 3.x Installation Guide 326039-004USeidmubaarakNo ratings yet
- Umang Resume-2022Document2 pagesUmang Resume-2022Shivam KumarNo ratings yet
- Xbox ScriptDocument5 pagesXbox ScriptUncleGeo1No ratings yet
- OpenStack Commissioning - MSS Cloud CFP5Document142 pagesOpenStack Commissioning - MSS Cloud CFP5DavidNo ratings yet
- Library Management SystemDocument20 pagesLibrary Management Systemrithikashivani06No ratings yet
- Core Java Assignment 1: Name: Vansh Dilip Nagda Roll No: 381 Class: SyitDocument6 pagesCore Java Assignment 1: Name: Vansh Dilip Nagda Roll No: 381 Class: Syit127fyitvanshnagdaNo ratings yet
- Name:-Tanveer Ul Hasan: Topic To Be DiscussedDocument23 pagesName:-Tanveer Ul Hasan: Topic To Be Discussedtan999729No ratings yet