You might also like
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Simplex Method for Operations Research ProblemDocument28 pagesSimplex Method for Operations Research ProblemAbinaya J.sNo ratings yet
- Efficient Parallel Non-Negative Least Squares On Multi-Core ArchitecturesDocument16 pagesEfficient Parallel Non-Negative Least Squares On Multi-Core ArchitecturesJason StanleyNo ratings yet
- Lyapunov StabilityDocument9 pagesLyapunov StabilitylvrevathiNo ratings yet
- Chapter 4. Instrumental VariablesDocument19 pagesChapter 4. Instrumental VariablesazertyNo ratings yet
- PCA Analysis GuideDocument24 pagesPCA Analysis GuidePrabin SilwalNo ratings yet
- Pca SlidesDocument33 pagesPca Slidesforscribd1981No ratings yet
- 4 Chapter 21 Non Linear ProgrammingDocument37 pages4 Chapter 21 Non Linear ProgrammingMir Md Mofachel HossainNo ratings yet
- QFT BoccioDocument63 pagesQFT Bocciounima3610No ratings yet
- 2002 Austin 1aDocument27 pages2002 Austin 1aValério da Silva AlmeidaNo ratings yet
- Pca PDFDocument33 pagesPca PDFAparajito SenguptaNo ratings yet
- The Bayesian Elastic NetDocument20 pagesThe Bayesian Elastic Netgerald372901No ratings yet
- Simplex Method 2022Document14 pagesSimplex Method 2022Ishika ParasrampuriaNo ratings yet
- ESANN 2015 proceedings on neural networks and machine learningDocument6 pagesESANN 2015 proceedings on neural networks and machine learningRaja Ben CharradaNo ratings yet
- Oxford Notes On Limits and ContDocument72 pagesOxford Notes On Limits and ContTse WallyNo ratings yet
- Quadratic ProgrammingDocument19 pagesQuadratic Programmingjabir sulaimanNo ratings yet
- The Kuhn-Tucker Conditions: Minimize Such That 0 1,..., H 0 1,...Document11 pagesThe Kuhn-Tucker Conditions: Minimize Such That 0 1,..., H 0 1,...Michał GromiszNo ratings yet
- LP NotesDocument7 pagesLP NotesSumit VermaNo ratings yet
- Newton Raphson MetodDocument27 pagesNewton Raphson MetodAnonymous fBjdRyyNo ratings yet
- 1 Banach SpacesDocument41 pages1 Banach Spacesnuriyesan0% (1)
- CP 2Document2 pagesCP 2Ankita MishraNo ratings yet
- Implementing the Simplex AlgorithmDocument7 pagesImplementing the Simplex AlgorithmdaselknamNo ratings yet
- 4115 Troyou06Document20 pages4115 Troyou06dibekayaNo ratings yet
- Solutions To The 69th William Lowell Putnam Mathematical Competition Saturday, December 6, 2008Document7 pagesSolutions To The 69th William Lowell Putnam Mathematical Competition Saturday, December 6, 2008Ganesh KumarNo ratings yet
- Linear Programming Fundamental Theorem ExplainedDocument4 pagesLinear Programming Fundamental Theorem ExplainedMithun HaridasNo ratings yet
- Gauss Quad LPDocument19 pagesGauss Quad LPThiago NobreNo ratings yet
- Report On Newton Raphson Method PDFDocument7 pagesReport On Newton Raphson Method PDFSilviuGCNo ratings yet
- Regularized Compression of A Noisy Blurred ImageDocument13 pagesRegularized Compression of A Noisy Blurred ImageAnonymous lVQ83F8mCNo ratings yet
- Constrained OptimizationDocument10 pagesConstrained OptimizationCourtney WilliamsNo ratings yet
- Tut8-Lyapunov FunctionsDocument4 pagesTut8-Lyapunov Functionszhugc.univNo ratings yet
- Efficient Monte Carlo Simulations For Stochastic ProgrammingDocument24 pagesEfficient Monte Carlo Simulations For Stochastic ProgrammingArmin ArdekaniNo ratings yet
- Cycle Time of Stochastic Max-Plus Linear SystemsDocument17 pagesCycle Time of Stochastic Max-Plus Linear SystemsMuanalifa AnyNo ratings yet
- 32 CongressDocument18 pages32 CongressSidney LinsNo ratings yet
- Functional Analysis Lecture NotesDocument38 pagesFunctional Analysis Lecture Notesprasun pratikNo ratings yet
- Gauss-Markov TheoremDocument5 pagesGauss-Markov Theoremalanpicard2303No ratings yet
- Algoritmo Dual SimplexDocument9 pagesAlgoritmo Dual SimplexPedro Manuel Aguayo MuñozNo ratings yet
- Introduction To DiscretizationDocument10 pagesIntroduction To DiscretizationpolkafNo ratings yet
- Open MethodsDocument9 pagesOpen Methodstatodc7No ratings yet
- Optimal Lineal Quadratic ControlDocument13 pagesOptimal Lineal Quadratic ControlJeanpierreNo ratings yet
- New lower bound for quadratic assignmentDocument17 pagesNew lower bound for quadratic assignmentبن الشيخ عليNo ratings yet
- Lecture 16: Linear Algebra III: cs412: Introduction To Numerical AnalysisDocument7 pagesLecture 16: Linear Algebra III: cs412: Introduction To Numerical AnalysisZachary MarionNo ratings yet
- MULTI-OBJECTIVE Linear ProgrammingDocument37 pagesMULTI-OBJECTIVE Linear ProgrammingLuri NurlailaNo ratings yet
- Power Flow AnalysisDocument8 pagesPower Flow AnalysisMadhur MayankNo ratings yet
- Curs Tehnici de OptimizareDocument141 pagesCurs Tehnici de OptimizareAndrei BurlacuNo ratings yet
- Camacho2007 PDFDocument24 pagesCamacho2007 PDFFabianOmarValdiviaPurizacaNo ratings yet
- Spectral Theory Solutions and Operator AlgebrasDocument43 pagesSpectral Theory Solutions and Operator Algebrassticker592100% (1)
- CS 229, Public Course Problem Set #4: Unsupervised Learning and Re-Inforcement LearningDocument5 pagesCS 229, Public Course Problem Set #4: Unsupervised Learning and Re-Inforcement Learningsuhar adiNo ratings yet
- I. Introduction To Convex Optimization: Georgia Tech ECE 8823a Notes by J. Romberg. Last Updated 13:32, January 11, 2017Document20 pagesI. Introduction To Convex Optimization: Georgia Tech ECE 8823a Notes by J. Romberg. Last Updated 13:32, January 11, 2017zeldaikNo ratings yet
- Nonlinear Least Squares Optimization and Data Fitting MethodsDocument20 pagesNonlinear Least Squares Optimization and Data Fitting MethodsMeriska ApriliadaraNo ratings yet
- Multiple Shooting with YALMIP – Exercise 1: Convex Optimal Control and SCPDocument5 pagesMultiple Shooting with YALMIP – Exercise 1: Convex Optimal Control and SCPVandilberto PintoNo ratings yet
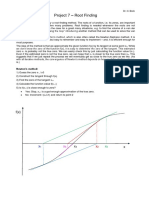
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993No ratings yet
- Chbe 553 Notes 1Document6 pagesChbe 553 Notes 1सुबेदी गौरवNo ratings yet
- Duffing Oscillator Report by Sam Needham at ANUDocument20 pagesDuffing Oscillator Report by Sam Needham at ANUNeedbeefNo ratings yet
- Approximate Solutions ParadigmsDocument17 pagesApproximate Solutions ParadigmsMouhaNo ratings yet
- ANALYSIS3: WED, SEP 11, 2013 Printed: September 12, 2013 (LEC# 3)Document11 pagesANALYSIS3: WED, SEP 11, 2013 Printed: September 12, 2013 (LEC# 3)ramboriNo ratings yet
- StokesFlowSimulation TutorialDocument20 pagesStokesFlowSimulation TutorialHridey GuptaNo ratings yet
- ManuscriptDocument9 pagesManuscriptxfliuNo ratings yet
- React Developer with Experience in Web and Mobile AppsDocument1 pageReact Developer with Experience in Web and Mobile AppsJason StanleyNo ratings yet
- Grant Holzemer ResumeDocument1 pageGrant Holzemer ResumeJason StanleyNo ratings yet
- Bro Chemometrics 1997Document9 pagesBro Chemometrics 1997Jason StanleyNo ratings yet
- Sae ApplicationDocument2 pagesSae ApplicationJason StanleyNo ratings yet
- Topic#3.Scalars, Vectors and TensorsDocument64 pagesTopic#3.Scalars, Vectors and TensorsJason StanleyNo ratings yet
- Sejal Divekar Resume1Document2 pagesSejal Divekar Resume1Jason StanleyNo ratings yet
- Cublas LibraryDocument254 pagesCublas LibraryJason StanleyNo ratings yet
- Mahesh Bauri Jul2022Document1 pageMahesh Bauri Jul2022Jason StanleyNo ratings yet
- 1 s2.0 S1877050917307858 MainDocument10 pages1 s2.0 S1877050917307858 MainJason StanleyNo ratings yet
- Elijah Hawkins Resume PDFDocument1 pageElijah Hawkins Resume PDFJason StanleyNo ratings yet
- Social Security Numbers For Noncitizens: Does A Noncitizen Need A Social Security Number (SSN) ?Document2 pagesSocial Security Numbers For Noncitizens: Does A Noncitizen Need A Social Security Number (SSN) ?Jason StanleyNo ratings yet
- HW4 PDFDocument23 pagesHW4 PDFJason StanleyNo ratings yet
- PARAFAC. Tutorial and Applications: ElsevierDocument23 pagesPARAFAC. Tutorial and Applications: ElsevierJason StanleyNo ratings yet
- Quadratic Forms and Convexity: Eivind EriksenDocument22 pagesQuadratic Forms and Convexity: Eivind EriksenJason StanleyNo ratings yet
- QR Factorization: Triangular Matrices QR Factorization Gram-Schmidt Algorithm Householder AlgorithmDocument42 pagesQR Factorization: Triangular Matrices QR Factorization Gram-Schmidt Algorithm Householder AlgorithmALEEZA kkNo ratings yet
- Matrix Gradients ExplainedDocument1 pageMatrix Gradients ExplainedJason StanleyNo ratings yet
- Fluid Mechanics Methods GuideDocument281 pagesFluid Mechanics Methods GuideJason StanleyNo ratings yet
- Marani Et Al. 2013Document5 pagesMarani Et Al. 2013Jason StanleyNo ratings yet
- LicenseDocument1 pageLicenseRiza IskandarNo ratings yet
- Murray, Knaapen 2008Document18 pagesMurray, Knaapen 2008Jason StanleyNo ratings yet
- OE4020 Assignment - 1: Jason Stanley.S Na15b021Document1 pageOE4020 Assignment - 1: Jason Stanley.S Na15b021Jason StanleyNo ratings yet
- Marani - Et - Al 2007Document5 pagesMarani - Et - Al 2007Jason StanleyNo ratings yet
- B.Tech Curriculum Requirements by DepartmentDocument23 pagesB.Tech Curriculum Requirements by DepartmentBala SudeepNo ratings yet
- Runge KuttaDocument16 pagesRunge KuttaJason StanleyNo ratings yet
- Prediction of Warship Manoeuvring Coefficients Using CFD: C. Oldfield, M. Moradi Larmaei, A. KendrickDocument17 pagesPrediction of Warship Manoeuvring Coefficients Using CFD: C. Oldfield, M. Moradi Larmaei, A. KendrickJason StanleyNo ratings yet
- Fem Shape FunctionDocument11 pagesFem Shape FunctionJason StanleyNo ratings yet
- "List of Possible Topics For OE545 ProjectDocument1 page"List of Possible Topics For OE545 ProjectJason StanleyNo ratings yet
- OE5450: Numerical Techniques in Ocean Hydrodynamics: Implementation of FEM On A Rectangular DomainDocument15 pagesOE5450: Numerical Techniques in Ocean Hydrodynamics: Implementation of FEM On A Rectangular DomainJason StanleyNo ratings yet
- Attachment No 2 PDFDocument10 pagesAttachment No 2 PDFTusharRoyNo ratings yet
- History of NanotechnologyDocument12 pagesHistory of NanotechnologyShubhangi RamtekeNo ratings yet
- Troubleshooting Directory for LHB Type RMPU EOG AC CoachesDocument44 pagesTroubleshooting Directory for LHB Type RMPU EOG AC Coachesdivisional electrical engg100% (6)
- The Emerald Tablets of Thoth Toth The Atlantean - Table 05Document5 pagesThe Emerald Tablets of Thoth Toth The Atlantean - Table 05Georgiana BealcuNo ratings yet
- Physical Education Week 1 ActivitiesDocument4 pagesPhysical Education Week 1 ActivitiesTummys TummieNo ratings yet
- CRRT (RVS) One Day TrainingDocument46 pagesCRRT (RVS) One Day TrainingwantoNo ratings yet
- Persian Polymath Physician Al-Rāzī's Life and WorksDocument10 pagesPersian Polymath Physician Al-Rāzī's Life and WorksAnonymous 29PN6AZTNo ratings yet
- Iso 4309 2017Document10 pagesIso 4309 2017C. de JongNo ratings yet
- Fiat Type 199 Punto Evo 3 PDFDocument9 pagesFiat Type 199 Punto Evo 3 PDFGestione SportivaNo ratings yet
- Mx81x Mx71x Service ManualDocument834 pagesMx81x Mx71x Service ManualCarlosNey0% (1)
- All Questions SLDocument50 pagesAll Questions SLRoberto Javier Vázquez MenchacaNo ratings yet
- TSC-2015-TAS Dec 10 PDFDocument8 pagesTSC-2015-TAS Dec 10 PDFvempadareddyNo ratings yet
- Sui Gas Connection FormsDocument1 pageSui Gas Connection Formsare50% (2)
- Atoms & Ions Worksheet 1 /63: Atomic Number and Mass NumberDocument4 pagesAtoms & Ions Worksheet 1 /63: Atomic Number and Mass Numbercate christineNo ratings yet
- ERT Techniques for Volunteer Fire BrigadesDocument45 pagesERT Techniques for Volunteer Fire BrigadesZionNo ratings yet
- Remote Sensing Mineral Exploration LithiumDocument16 pagesRemote Sensing Mineral Exploration LithiumGerald Darshan MogiNo ratings yet
- Ael Igniter CordsDocument1 pageAel Igniter CordsAlexander OpazoNo ratings yet
- 11 Biology Notes Ch10 Cell Cycle and Cell DevisionDocument7 pages11 Biology Notes Ch10 Cell Cycle and Cell DevisionRohit ThakranNo ratings yet
- PSPD Activity 3Document4 pagesPSPD Activity 3laurynnaNo ratings yet
- Ajuste IAC and TPSDocument17 pagesAjuste IAC and TPSLuis Ignacio SilvaNo ratings yet
- Watkins Göbekli Tepe Jerf El Ahmar PDFDocument10 pagesWatkins Göbekli Tepe Jerf El Ahmar PDFHans Martz de la VegaNo ratings yet
- Computer Education ModuleDocument22 pagesComputer Education ModuleJulia Melissa CzapNo ratings yet
- Mp1 Type 1 ManualDocument69 pagesMp1 Type 1 ManualJerryNo ratings yet
- Ship Construction IonsDocument25 pagesShip Construction Ionsanon-49038083% (6)
- Wa0001.Document1 pageWa0001.Esmael Vasco AndradeNo ratings yet
- SP18368 Automotive Radar Comparison 2018 Sample 2Document33 pagesSP18368 Automotive Radar Comparison 2018 Sample 2Chipisgood YuNo ratings yet
- Audi SSP 822703 4 2 L v8 Fsi Engine VolkswagenDocument4 pagesAudi SSP 822703 4 2 L v8 Fsi Engine Volkswagenmiriam100% (34)
- 特变电工画册(英文定稿)Document52 pages特变电工画册(英文定稿)Diego MantillaNo ratings yet
- Ymfc Al SetupDocument18 pagesYmfc Al SetupredaNo ratings yet
- Gujarat Technological University: W.E.F. AY 2018-19Document4 pagesGujarat Technological University: W.E.F. AY 2018-19Premal PatelNo ratings yet