You might also like
- Banking Products and Services - Course PresentationDocument171 pagesBanking Products and Services - Course Presentationnimitjain10No ratings yet
- Qur'aan Corpus (A Brief Summary On Arabic Grammar)Document74 pagesQur'aan Corpus (A Brief Summary On Arabic Grammar)Al HudaNo ratings yet
- Kuhlmann - Introduction To Computational Linguistics (Slides) (2015)Document66 pagesKuhlmann - Introduction To Computational Linguistics (Slides) (2015)JoeJune100% (1)
- AWS90 Ch04 StaticDocument54 pagesAWS90 Ch04 StaticmuruganandamdesinghNo ratings yet
- Prior Art SearchDocument1 pagePrior Art Searchinfo6656No ratings yet
- VHDL 101: Everything you Need to Know to Get StartedFrom EverandVHDL 101: Everything you Need to Know to Get StartedRating: 2.5 out of 5 stars2.5/5 (2)
- T24 Java Training Internal - 20191022Document39 pagesT24 Java Training Internal - 20191022cesar100% (10)
- Algorithmic Trading & Computational Finance Python R CourseDocument5 pagesAlgorithmic Trading & Computational Finance Python R Coursenimitjain10No ratings yet
- Artificial Intelligence: Chapter# 2: Knowledge Representation and ReasoningDocument38 pagesArtificial Intelligence: Chapter# 2: Knowledge Representation and Reasoningzabih niazaiNo ratings yet
- Freedom To Operate SearchDocument1 pageFreedom To Operate Searchinfo6656No ratings yet
- Linear Buckling Analysis: Chapter SevenDocument22 pagesLinear Buckling Analysis: Chapter Sevennimitjain10No ratings yet
- Tutorial LSIDocument64 pagesTutorial LSIrahulNo ratings yet
- Completed UNIT-III 20.9.17Document61 pagesCompleted UNIT-III 20.9.17Dr.A.R.KavithaNo ratings yet
- Statistical Natural Language ProcessingDocument31 pagesStatistical Natural Language ProcessingramlohaniNo ratings yet
- Lucene SolrDocument52 pagesLucene SolrRubila Dwi AdawiyahNo ratings yet
- NLTK: The Natural Language Toolkit: Steven Bird Edward LoperDocument4 pagesNLTK: The Natural Language Toolkit: Steven Bird Edward LoperYash GautamNo ratings yet
- Natural Language Processing TutorialDocument24 pagesNatural Language Processing TutorialAbi ZelekeNo ratings yet
- Text Mining Concepts and Techniques CS822Document45 pagesText Mining Concepts and Techniques CS822Muhammad UmairNo ratings yet
- Lecture 1Document20 pagesLecture 1AITM(FAC) Ashish Kumar SinghNo ratings yet
- IRS Unit-3Document32 pagesIRS Unit-3Nagendra MarisettiNo ratings yet
- sim(D,Q) = 1 + 1 + 1 + 1 = 4Weighted: – D = 0.5, 0.3, 0.2, 0, 0.1, 0.3, 0 – Q = 0.2, 0, 0.4, 0, 0, 0.3, 0.1Document29 pagessim(D,Q) = 1 + 1 + 1 + 1 = 4Weighted: – D = 0.5, 0.3, 0.2, 0, 0.1, 0.3, 0 – Q = 0.2, 0, 0.4, 0, 0, 0.3, 0.1Rihab BEN LAMINENo ratings yet
- Boolean Retrieval: Dr. Hosam RefaatDocument21 pagesBoolean Retrieval: Dr. Hosam RefaatHussain SaeedNo ratings yet
- CT075!3!2 DTM Topic 12 Text Data MiningDocument25 pagesCT075!3!2 DTM Topic 12 Text Data Miningkishanselvarajah80No ratings yet
- Lesson 4 Patent Search Keywrords PDFDocument68 pagesLesson 4 Patent Search Keywrords PDFjb100% (1)
- Introduction of IR ModelsDocument62 pagesIntroduction of IR ModelsMagarsa BedasaNo ratings yet
- NLP-IR (1)Document24 pagesNLP-IR (1)pawebiarxdxdNo ratings yet
- A Quick Guide To Patent Research: 7 Step Patent Search Strategy 7 Step Patent Search StrategyDocument2 pagesA Quick Guide To Patent Research: 7 Step Patent Search Strategy 7 Step Patent Search StrategyKheawed JoryNo ratings yet
- Advanced Lucene: Grant Ingersoll Center For Natural Language Processing Apachecon 2005 December 12, 2005Document37 pagesAdvanced Lucene: Grant Ingersoll Center For Natural Language Processing Apachecon 2005 December 12, 2005rajeevkri0% (1)
- Index ConstructionDocument48 pagesIndex ConstructionAhmed AlesaNo ratings yet
- Assignment 3 InstructionsDocument10 pagesAssignment 3 InstructionsAshutosh KushwahaNo ratings yet
- Week 8 AnalyzingQualitativeData 2011 PDFDocument35 pagesWeek 8 AnalyzingQualitativeData 2011 PDFAndrei MaglacasNo ratings yet
- FFT ThesisDocument4 pagesFFT Thesiss0kuzej0byn2100% (1)
- ImplementationDocument16 pagesImplementationRihab BEN LAMINENo ratings yet
- Unit 1: Introduction and Data Pre-ProcessingDocument71 pagesUnit 1: Introduction and Data Pre-Processingmanju kakkarNo ratings yet
- Question AnsweringDocument29 pagesQuestion AnsweringSV PRNo ratings yet
- IT Dept Linux Programming SyllabusDocument25 pagesIT Dept Linux Programming Syllabusscet 315No ratings yet
- A Survey On Deep Learning For Patent AnalysisDocument13 pagesA Survey On Deep Learning For Patent AnalysisAlex ENo ratings yet
- IS707: Applications of Intelligent Technologies: Spring 2022Document41 pagesIS707: Applications of Intelligent Technologies: Spring 2022karthik ChavaliNo ratings yet
- AI6122 Text Data Management & Analysis: TFIDF and Vector Space ModelDocument27 pagesAI6122 Text Data Management & Analysis: TFIDF and Vector Space ModelYujia TianNo ratings yet
- Introduction of IR ModelsDocument67 pagesIntroduction of IR ModelsMagarsa BedasaNo ratings yet
- IPlytics - Methodology For Current Similarity & Alpha ScoresDocument13 pagesIPlytics - Methodology For Current Similarity & Alpha ScoresAnonymous qyExl9dUQu100% (1)
- Introduction To Information Retrieval: Jian-Yun Nie University of Montreal CanadaDocument61 pagesIntroduction To Information Retrieval: Jian-Yun Nie University of Montreal CanadaRicha MayankNo ratings yet
- Introduction - Major Mile Stones of TKDL - Present Status - Impact and Recognition of TKDLDocument21 pagesIntroduction - Major Mile Stones of TKDL - Present Status - Impact and Recognition of TKDLSreedhar RaoNo ratings yet
- IR-Course-Introduction-Part-1Document249 pagesIR-Course-Introduction-Part-1Gaurav MahajanNo ratings yet
- RipperDocument33 pagesRipperSaurabh BaghelNo ratings yet
- IR Models: - Why IR Models? - Boolean IR Model - Vector Space IR Model - Probabilistic IR ModelDocument46 pagesIR Models: - Why IR Models? - Boolean IR Model - Vector Space IR Model - Probabilistic IR Modelkerya ibrahimNo ratings yet
- Lecture 11 PPT (OOPs-Introduction)Document24 pagesLecture 11 PPT (OOPs-Introduction)Rachit KhuranaNo ratings yet
- Improve Search Results with Query OperationsDocument28 pagesImprove Search Results with Query Operationsbiniam teshomeNo ratings yet
- 7 B_Query LanguagesDocument33 pages7 B_Query Languagesamankinde4No ratings yet
- Slide 2 - Basic Language ElementsDocument63 pagesSlide 2 - Basic Language ElementsMihir JainNo ratings yet
- Information Retrieval Models: Vector Space Models: Chengxiang ZhaiDocument30 pagesInformation Retrieval Models: Vector Space Models: Chengxiang ZhaictadventuresinghNo ratings yet
- MSC IR 2021Document188 pagesMSC IR 2021Bini Teflon Ankh100% (1)
- Python With Data Science - SyllabusDocument6 pagesPython With Data Science - SyllabusZORO GAMING PIRATESNo ratings yet
- Introduction to Information Retrieval ProcessesDocument61 pagesIntroduction to Information Retrieval ProcessesTamizharasi ANo ratings yet
- Chapter Three Term Weighting and Similarity MeasuresDocument33 pagesChapter Three Term Weighting and Similarity MeasuresAlemayehu GetachewNo ratings yet
- CSE 1203 01 Class ObjectsDocument37 pagesCSE 1203 01 Class ObjectsWalkMan AnonymusNo ratings yet
- B.Sc. (IT) (Bachelor of Science in Information Technology) : Syllabus 2011 (Term 2)Document6 pagesB.Sc. (IT) (Bachelor of Science in Information Technology) : Syllabus 2011 (Term 2)Manish ShresthaNo ratings yet
- Lesson 2: Everything Becomes ProgrammableDocument26 pagesLesson 2: Everything Becomes ProgrammableAshley VillanuevaNo ratings yet
- Performing Effective Freedom To Operate Searches On STN: STN Patent Forum July 2005Document70 pagesPerforming Effective Freedom To Operate Searches On STN: STN Patent Forum July 2005Lalit AmbasthaNo ratings yet
- Text Mining & Question Answering: Krishna KummamuruDocument35 pagesText Mining & Question Answering: Krishna KummamuruAbhi RockyNo ratings yet
- Introduction To Automatic IndexingDocument28 pagesIntroduction To Automatic Indexing7killers4uNo ratings yet
- Query Languages: Chapter SevenDocument36 pagesQuery Languages: Chapter SevenSooraaNo ratings yet
- Patent Mining - A SurveyDocument50 pagesPatent Mining - A SurveyGerson SchafferNo ratings yet
- Introduction Review of Java and OOPDocument28 pagesIntroduction Review of Java and OOPISYAKU KABIRU ALFANo ratings yet
- Week 11 LectureDocument61 pagesWeek 11 LectureSasi DharanNo ratings yet
- ARPWConsultancy - Service OverviewDocument13 pagesARPWConsultancy - Service OverviewtrewhealNo ratings yet
- TF-ICF A New Term Weighting Scheme For ClusteringDocument7 pagesTF-ICF A New Term Weighting Scheme For ClusteringPranshu PatelNo ratings yet
- Introduction to Knowledge Representation TechniquesDocument27 pagesIntroduction to Knowledge Representation TechniquesFELICIALILIAN JNo ratings yet
- Pt. L R Group of Institutions Faridabad Delhi NCRDocument21 pagesPt. L R Group of Institutions Faridabad Delhi NCRfrodykaamNo ratings yet
- Micro EconomicsDocument6 pagesMicro Economicsnimitjain10No ratings yet
- 33 Fejc 2 G RMQ ZBLZ LOMOWDocument37 pages33 Fejc 2 G RMQ ZBLZ LOMOWnimitjain10No ratings yet
- Ethics - 20210828 - Adithya KiranDocument49 pagesEthics - 20210828 - Adithya Kirannimitjain10No ratings yet
- Futures & Forwards: Professor DroussiotisDocument12 pagesFutures & Forwards: Professor Droussiotisnimitjain10No ratings yet
- International Trade TerminologyDocument10 pagesInternational Trade Terminologynimitjain10No ratings yet
- Valuation AnalysisDocument27 pagesValuation Analysisnimitjain10No ratings yet
- DERIVATIVESDocument13 pagesDERIVATIVESnimitjain10100% (1)
- 839 - CareerPDF3 - Annexure II Challan PDFDocument1 page839 - CareerPDF3 - Annexure II Challan PDFnimitjain10No ratings yet
- Derivative Investments:: Futures, Forwards, Swaps, Swaptions, Cdas, Fras, and Other DerivativesDocument36 pagesDerivative Investments:: Futures, Forwards, Swaps, Swaptions, Cdas, Fras, and Other Derivativesnimitjain10No ratings yet
- Air India Engineering Recruitment Corrigendum - Experienced Aircraft Technicians Vacancies UpdatedDocument1 pageAir India Engineering Recruitment Corrigendum - Experienced Aircraft Technicians Vacancies Updatednimitjain10No ratings yet
- 544 1 corrigendumIIDocument1 page544 1 corrigendumIInimitjain10No ratings yet
- Corporate Finance & Valuation Lecture Series #2Document10 pagesCorporate Finance & Valuation Lecture Series #2nimitjain10No ratings yet
- Understanding Financial Statements: Chris DroussiotisDocument23 pagesUnderstanding Financial Statements: Chris Droussiotisnimitjain10No ratings yet
- Flights Operations Wings:: Page 1 of 5Document5 pagesFlights Operations Wings:: Page 1 of 5nimitjain10No ratings yet
- Notification Air India Limited SR Trainee Pilot PostsDocument4 pagesNotification Air India Limited SR Trainee Pilot PostsShreya MishraNo ratings yet
- Equity Derivatives Workbook (Version Sep-2015) PDFDocument162 pagesEquity Derivatives Workbook (Version Sep-2015) PDFjayeshcsls11100% (1)
- 10 NISM Series VII Securities OperationsDocument137 pages10 NISM Series VII Securities OperationsPrashant PatelNo ratings yet
- Other Useful Data Types PDFDocument11 pagesOther Useful Data Types PDFnimitjain10No ratings yet
- Automobile Engineering Department Project Reports 2015-2012Document4 pagesAutomobile Engineering Department Project Reports 2015-2012nimitjain10No ratings yet
- Nahar Auth PDFDocument1 pageNahar Auth PDFnimitjain10No ratings yet
- Paragraph Vector PDFDocument9 pagesParagraph Vector PDFSr. RZNo ratings yet
- Airline Allied Service Limited: (A Wholly Owned Subsidiary of Air India)Document1 pageAirline Allied Service Limited: (A Wholly Owned Subsidiary of Air India)nimitjain10No ratings yet
- GDPI PrepDocument115 pagesGDPI PrepPrajeeth NairNo ratings yet
- Yaw MomentDocument9 pagesYaw MomentewiontkoNo ratings yet
- Chapter 2 Hovering Theory 21april2012 Cor 7june2013Document32 pagesChapter 2 Hovering Theory 21april2012 Cor 7june2013nimitjain10No ratings yet
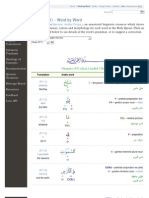
- Verse (72:1) - Word by Word: Quranic Arabic CorpusDocument39 pagesVerse (72:1) - Word by Word: Quranic Arabic CorpusaminchatNo ratings yet
- Verse (57:1) - Word by Word: Quranic Arabic CorpusDocument76 pagesVerse (57:1) - Word by Word: Quranic Arabic CorpusaminchatNo ratings yet
- 043Document115 pages043aminchatNo ratings yet
- Automatic Analysis of Syntactic Complexity in Second Language WritingDocument24 pagesAutomatic Analysis of Syntactic Complexity in Second Language WritingJoyce CheungNo ratings yet
- Aepli Noemi 1990Document62 pagesAepli Noemi 1990Uri ZilbermanNo ratings yet
- Enhancing Czech Parsing With Verb Valency Frames: March 2013Document13 pagesEnhancing Czech Parsing With Verb Valency Frames: March 2013Leonardo Santos PereiraNo ratings yet
- C10 2147Document9 pagesC10 2147zubairhussainscribdNo ratings yet
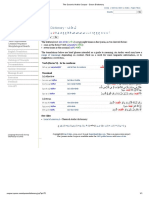
- Verse (13:1) - Word by Word: Quranic Arabic CorpusDocument110 pagesVerse (13:1) - Word by Word: Quranic Arabic CorpusaminchatNo ratings yet
- NLP Unit II NotesDocument18 pagesNLP Unit II Notesnsyadav89590% (1)
- Verse (68:1) - Word by Word: Quranic Arabic CorpusDocument43 pagesVerse (68:1) - Word by Word: Quranic Arabic CorpusaminchatNo ratings yet
- What is Corpus LinguisticsDocument24 pagesWhat is Corpus LinguisticsramlohaniNo ratings yet
- Evaluation of Discourse Relation Annotation in HindiDocument6 pagesEvaluation of Discourse Relation Annotation in HindiJawed AhmedNo ratings yet
- Verse (48:1) - Word by Word: Quranic Arabic CorpusDocument74 pagesVerse (48:1) - Word by Word: Quranic Arabic CorpusaminchatNo ratings yet
- Dukes 11 PGRDocument37 pagesDukes 11 PGRsindurationNo ratings yet
- TreebankDocument17 pagesTreebankmiskoscribdNo ratings yet
- S10 1Document477 pagesS10 1robertoNo ratings yet
- Sandiway Fong: EducationDocument10 pagesSandiway Fong: EducationЮлия БондаренкоNo ratings yet
- Urdu Dependency Parser A Data-Driven ApproachDocument7 pagesUrdu Dependency Parser A Data-Driven ApproachSafi Ud Din KhanNo ratings yet
- Beyond GrammarDocument184 pagesBeyond Grammaryazadn100% (2)
- The Quranic Arabic Corpus - Quran Dictionary PDFDocument1 pageThe Quranic Arabic Corpus - Quran Dictionary PDFmustak100% (1)
- 12Document31 pages12Saurabh GuptaNo ratings yet
- Should I Do A Masters ThesisDocument6 pagesShould I Do A Masters Thesisafkogsfea100% (2)
- NLP UNIT 2 (Ques Ans Bank)Document26 pagesNLP UNIT 2 (Ques Ans Bank)Zainab BelalNo ratings yet
- RNTN PDFDocument12 pagesRNTN PDFVikasNo ratings yet
- Conjunct Verbs in Punjabi and Across Indo-Aryan A Corpus StudyDocument7 pagesConjunct Verbs in Punjabi and Across Indo-Aryan A Corpus Studycamill chemleyNo ratings yet