You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Different Approaches For Digestion, Performance Assessment and Measurement Uncertainty For The Analysis of Cadmium and Lead in FeedsDocument13 pagesDifferent Approaches For Digestion, Performance Assessment and Measurement Uncertainty For The Analysis of Cadmium and Lead in FeedsChuckPeter MartinorrisNo ratings yet
- Incertidumbre Kacker 2003 BayesianaDocument15 pagesIncertidumbre Kacker 2003 BayesianaChuckPeter MartinorrisNo ratings yet
- Incertidumbre Synek 2006 SesgoDocument11 pagesIncertidumbre Synek 2006 SesgoChuckPeter MartinorrisNo ratings yet
- Simultaneous Analysis and Uncertainty of Measurement For Pymetrozine, Ethoxyquin, and Cycloxydim in Sweet Pepper Using Lc-Ms/MsDocument10 pagesSimultaneous Analysis and Uncertainty of Measurement For Pymetrozine, Ethoxyquin, and Cycloxydim in Sweet Pepper Using Lc-Ms/MsChuckPeter MartinorrisNo ratings yet
- The Use of Reference Materials in Internal Quality Control: Marina PatriarcaDocument35 pagesThe Use of Reference Materials in Internal Quality Control: Marina PatriarcaChuckPeter MartinorrisNo ratings yet
- MRC CRM Keilbasa 2016 PDFDocument13 pagesMRC CRM Keilbasa 2016 PDFChuckPeter MartinorrisNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Mathematics ExcerciseDocument74 pagesMathematics Excerciseserge129100% (1)
- 01CDT00330 - Lakeshore - 330 - ManualDocument104 pages01CDT00330 - Lakeshore - 330 - ManualSPMS_MELECNo ratings yet
- Network Management Systems 10CS834 PDFDocument113 pagesNetwork Management Systems 10CS834 PDFSarfraz AhmedNo ratings yet
- 2.2 Lesson Notes FA12Document24 pages2.2 Lesson Notes FA12JAPNo ratings yet
- Corrosion of Iron Lab Writeup Julia GillespieDocument4 pagesCorrosion of Iron Lab Writeup Julia Gillespieapi-344957036No ratings yet
- Đề Đề Nghị Gởi SởDocument13 pagesĐề Đề Nghị Gởi SởPhú TôNo ratings yet
- Wifi HackDocument20 pagesWifi HackVAJIR ABDURNo ratings yet
- Control Panel Manual 1v4Document52 pagesControl Panel Manual 1v4Gustavo HidalgoNo ratings yet
- Gpcdoc Gtds Shell Gadus s3 v460xd 2 (En) TdsDocument2 pagesGpcdoc Gtds Shell Gadus s3 v460xd 2 (En) TdsRoger ObregonNo ratings yet
- Limitations of The Study - Docx EMDocument1 pageLimitations of The Study - Docx EMthreeNo ratings yet
- A Modified Newton's Method For Solving Nonlinear Programing ProblemsDocument15 pagesA Modified Newton's Method For Solving Nonlinear Programing Problemsjhon jairo portillaNo ratings yet
- Sample Test Paper 2012 NucleusDocument14 pagesSample Test Paper 2012 NucleusVikramNo ratings yet
- Cee 2005 - 06Document129 pagesCee 2005 - 06iloveeggxPNo ratings yet
- Brandi Jones-5e-Lesson-Plan 2Document3 pagesBrandi Jones-5e-Lesson-Plan 2api-491136095No ratings yet
- 02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxDocument1 page02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxMichel van WordragenNo ratings yet
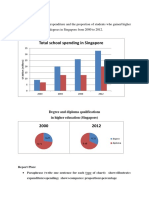
- Total School Spending in Singapore: Task 1 020219Document6 pagesTotal School Spending in Singapore: Task 1 020219viper_4554No ratings yet
- IBRO News 2004Document8 pagesIBRO News 2004International Brain Research Organization100% (1)
- HowToCreate DataDriven HorizonCube OpendTectv4.4 PDFDocument49 pagesHowToCreate DataDriven HorizonCube OpendTectv4.4 PDFKrisna Hanjar PrastawaNo ratings yet
- Protein Dot BlottingDocument4 pagesProtein Dot BlottingstcosmoNo ratings yet
- Tcps 2 Final WebDocument218 pagesTcps 2 Final WebBornaGhannadiNo ratings yet
- LG 55lw5600 Chassis La12c SMDocument29 pagesLG 55lw5600 Chassis La12c SMwandag2010No ratings yet
- LearnEnglish Reading B1 A Conference ProgrammeDocument4 pagesLearnEnglish Reading B1 A Conference ProgrammeAylen DaianaNo ratings yet
- Solarbotics Wheel Watcher Encoder ManualDocument10 pagesSolarbotics Wheel Watcher Encoder ManualYash SharmaNo ratings yet
- JAIM InstructionsDocument11 pagesJAIM InstructionsAlphaRaj Mekapogu100% (1)
- CBSE Class 10 Science Sample Paper-08 (For 2013)Document11 pagesCBSE Class 10 Science Sample Paper-08 (For 2013)cbsesamplepaperNo ratings yet
- Unification of Euler and Werner Deconvolution in Three Dimensions Via The Generalized Hilbert TransformDocument6 pagesUnification of Euler and Werner Deconvolution in Three Dimensions Via The Generalized Hilbert TransformMithunNo ratings yet
- SLC 10 ScienceDocument16 pagesSLC 10 SciencePffflyers KurnawanNo ratings yet
- The Iron Warrior: Volume 25, Issue 11Document8 pagesThe Iron Warrior: Volume 25, Issue 11The Iron WarriorNo ratings yet
- Curriculum Vitae: Name: Father S Name: Cell No: Email: Date of Birth: Nationality: Cnic No: Passport No: AddressDocument2 pagesCurriculum Vitae: Name: Father S Name: Cell No: Email: Date of Birth: Nationality: Cnic No: Passport No: AddressJahanzeb JojiNo ratings yet
- Report Swtich Cisco Pass DNSDocument91 pagesReport Swtich Cisco Pass DNSDenis Syst Laime LópezNo ratings yet