You might also like
- PYC3704 - 2021 - 202 - 1 - B ECP Feedback Assignment 2Document18 pagesPYC3704 - 2021 - 202 - 1 - B ECP Feedback Assignment 2meg100% (3)
- Analytics Interview QuestionsDocument64 pagesAnalytics Interview QuestionsKusuma SaddalaNo ratings yet
- CS1 R Summary SheetsDocument26 pagesCS1 R Summary SheetsPranav SharmaNo ratings yet
- Doe QuizDocument10 pagesDoe QuizManish RawatNo ratings yet
- T3 - QB - Chapter 6 - QB - SolutionDocument22 pagesT3 - QB - Chapter 6 - QB - SolutionPalak RathoreNo ratings yet
- AsimDocument27 pagesAsimMuhammad Asim Muhammad ArshadNo ratings yet
- AliDocument31 pagesAliMuhammad Asim Muhammad ArshadNo ratings yet
- Workshop 5: PDF Sampling and Statistics: Preview: Generating Random NumbersDocument10 pagesWorkshop 5: PDF Sampling and Statistics: Preview: Generating Random NumbersLevi GrantzNo ratings yet
- Binomial - Poisson - Normal - Distribution in RDocument8 pagesBinomial - Poisson - Normal - Distribution in RPratik GugliyaNo ratings yet
- Python Random Module Methods PDFDocument9 pagesPython Random Module Methods PDFBikram ChowdhuryNo ratings yet
- Introduction To Python: 1.1 Declaring VariablesDocument9 pagesIntroduction To Python: 1.1 Declaring VariablessushanthNo ratings yet
- Effect SizeDocument9 pagesEffect Sizeapi-362845526No ratings yet
- Csci Ua 02 Midterm02practice AnswersDocument8 pagesCsci Ua 02 Midterm02practice AnswersjscansinoNo ratings yet
- HurairaDocument26 pagesHurairaMuhammad Asim Muhammad ArshadNo ratings yet
- Sunali Assignment 5Document8 pagesSunali Assignment 5ssunalibe21No ratings yet
- Solutions On Python FunctionsDocument1 pageSolutions On Python FunctionsJason ShaxNo ratings yet
- B19059 Lab9 IC252 CodeDocument3 pagesB19059 Lab9 IC252 CodeSourav SehgalNo ratings yet
- Lecture Notes - Inferential StatisticsDocument9 pagesLecture Notes - Inferential StatisticsshahadNo ratings yet
- Implementing Custom Randomsearchcv: 'Red' 'Blue'Document1 pageImplementing Custom Randomsearchcv: 'Red' 'Blue'Tayub khan.ANo ratings yet
- Chapter 9 ProjectsDocument15 pagesChapter 9 ProjectsDeepakKattimaniNo ratings yet
- Experiment 4Document5 pagesExperiment 4Mahesh KadambalaNo ratings yet
- Discrete Random Variables and Their Probability DistributionsDocument71 pagesDiscrete Random Variables and Their Probability DistributionsBishal SahaNo ratings yet
- Write A Python Program That Prints All The Numbers From 0 To 6 Except 3 and 6Document6 pagesWrite A Python Program That Prints All The Numbers From 0 To 6 Except 3 and 6HARISH RAGAVENDAR S CSENo ratings yet
- UNIT 4 - Part BDocument15 pagesUNIT 4 - Part BNetaji GandiNo ratings yet
- PYTHONBOOKDocument32 pagesPYTHONBOOKJyotirmay SahuNo ratings yet
- Computational FinanceDocument19 pagesComputational FinancePrateek BhatnagarNo ratings yet
- 6PAM1052 Stats PracticalDocument25 pages6PAM1052 Stats PracticalBhuvanesh SriniNo ratings yet
- 4ann - 5Th ProgDocument15 pages4ann - 5Th Progshreyas .cNo ratings yet
- 7 - Programming With MATLABDocument22 pages7 - Programming With MATLABErtan AkçayNo ratings yet
- Computer Journal ProgramsDocument34 pagesComputer Journal ProgramsJawaan SanthNo ratings yet
- Unit 4. Probability DistributionsDocument18 pagesUnit 4. Probability DistributionszinfadelsNo ratings yet
- Computational Techniques in Statistics: Exercise 1Document5 pagesComputational Techniques in Statistics: Exercise 1وجدان الشداديNo ratings yet
- Final Pred401Document18 pagesFinal Pred401Moin Uddin SiddiqueNo ratings yet
- PTSP Lab RecordDocument27 pagesPTSP Lab RecordAnonymousNo ratings yet
- Biostatistics ProblemsDocument2 pagesBiostatistics ProblemsArmand IliescuNo ratings yet
- Algorithms - A Simple Introduction in Python: Part EightDocument4 pagesAlgorithms - A Simple Introduction in Python: Part Eightmark tranterNo ratings yet
- Ai LabDocument15 pagesAi Lab4653Anushika PatelNo ratings yet
- DVP 1Document24 pagesDVP 1rdf002740No ratings yet
- Simple Statistics Functions in RDocument41 pagesSimple Statistics Functions in RTonyNo ratings yet
- Technical Interview Questions Technical Interview QuestionsDocument13 pagesTechnical Interview Questions Technical Interview Questionsschultz jrNo ratings yet
- Stat Doc Pract 6,7,8Document17 pagesStat Doc Pract 6,7,8Ajay KajaniyaNo ratings yet
- Python ProgramsDocument16 pagesPython Programssrijal kunwarNo ratings yet
- Lab-6-Binomail and Poisson DistributionDocument13 pagesLab-6-Binomail and Poisson DistributionRakib Khan100% (1)
- 7probability Distributions (Binomial, Poisson and Normal)Document33 pages7probability Distributions (Binomial, Poisson and Normal)lakshita6789No ratings yet
- Assignment 2 1Document4 pagesAssignment 2 1deepakkashyaNo ratings yet
- CS 2 Ans - Introduction To PythonDocument5 pagesCS 2 Ans - Introduction To Pythonasha.py81No ratings yet
- Chi Square TutorialDocument4 pagesChi Square TutorialAlifah UlyaNo ratings yet
- Beal's Conjecture A Search For CounterexamplesDocument3 pagesBeal's Conjecture A Search For CounterexamplesAnonymous JIRIzeiJ6ONo ratings yet
- Computational Physics MCQ Final KeyDocument5 pagesComputational Physics MCQ Final KeySharoon DanielNo ratings yet
- 05 Logistic - RegressionDocument7 pages05 Logistic - RegressionadalinaNo ratings yet
- Experiment No 3 - Gredient Decent in PythonDocument20 pagesExperiment No 3 - Gredient Decent in PythonSalilNo ratings yet
- Conditional Statements AssignmentDocument6 pagesConditional Statements AssignmentMohammed Ashfaque JamalNo ratings yet
- Session Set Working Directory Choose DirectlryDocument17 pagesSession Set Working Directory Choose DirectlryAnimesh DubeyNo ratings yet
- MLR Example 2predictorsDocument5 pagesMLR Example 2predictorswangshiui2002No ratings yet
- String Functions: Extract 1st Word From String "Name"Document28 pagesString Functions: Extract 1st Word From String "Name"blakewilNo ratings yet
- PyCon India 2012 NotebookDocument10 pagesPyCon India 2012 NotebookSin JuneNo ratings yet
- P02 Introduction To Numpy AnsDocument32 pagesP02 Introduction To Numpy AnsYONG LONG KHAWNo ratings yet
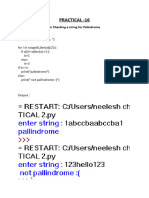
- Practical CSDocument22 pagesPractical CSneeleshchopra3459No ratings yet
- Lab3 Fitting and Plotting of Binomial Distribution & Poisson Distribution (Challenging Experiment 2 (A) and 2 (B) ) AimDocument18 pagesLab3 Fitting and Plotting of Binomial Distribution & Poisson Distribution (Challenging Experiment 2 (A) and 2 (B) ) AimAshutosh MauryaNo ratings yet
- Complete NMCP FileDocument29 pagesComplete NMCP FileMEB05 Kishyon KumarNo ratings yet
- Python S, L, F, TDocument9 pagesPython S, L, F, Tdisss8989No ratings yet
- Egg WaveDocument3 pagesEgg WaveGherasie GabrielNo ratings yet
- Random Number Generator: Comprehensive VersionDocument3 pagesRandom Number Generator: Comprehensive VersionGherasie GabrielNo ratings yet
- Vocaloid Part 4 - Fdhdef/100: Request DeleteDocument2 pagesVocaloid Part 4 - Fdhdef/100: Request DeleteGherasie GabrielNo ratings yet
- Using Namespace Int Int Int Int For For If Return: #Include N ADocument4 pagesUsing Namespace Int Int Int Int For For If Return: #Include N AGherasie GabrielNo ratings yet
- Analysis: Greg WajdaDocument11 pagesAnalysis: Greg WajdaGherasie GabrielNo ratings yet
- Real-Valued Distributions: RandomDocument5 pagesReal-Valued Distributions: RandomGherasie GabrielNo ratings yet
- Games and LotteriesDocument3 pagesGames and LotteriesGherasie GabrielNo ratings yet
- Set The File Permissions To Read and ExecuteDocument4 pagesSet The File Permissions To Read and ExecuteGherasie GabrielNo ratings yet
- Random : Random Seed Getstate Setstate GetrandbitsDocument6 pagesRandom : Random Seed Getstate Setstate GetrandbitsGherasie GabrielNo ratings yet
- Clean The PrinterDocument3 pagesClean The PrinterGherasie GabrielNo ratings yet
- #IncludeDocument5 pages#IncludeGherasie GabrielNo ratings yet
- Subiectul I: B - B D A CDocument5 pagesSubiectul I: B - B D A CGherasie GabrielNo ratings yet
- It Authenticates EvidenceDocument4 pagesIt Authenticates EvidenceGherasie GabrielNo ratings yet
- Listen To The Complaint and Then Apologize For Any Inconvenience Caused by The Lengthy Service On The ComputerDocument3 pagesListen To The Complaint and Then Apologize For Any Inconvenience Caused by The Lengthy Service On The ComputerGherasie GabrielNo ratings yet
- PHI Ephi: Explanation: Both Protected Health Information (PHI) and Electronic ProtectedDocument3 pagesPHI Ephi: Explanation: Both Protected Health Information (PHI) and Electronic ProtectedGherasie GabrielNo ratings yet
- Power Supply WattageDocument3 pagesPower Supply WattageGherasie GabrielNo ratings yet
- Entering A Concise Description of A Customer Problem Into A Ticketing SystemDocument2 pagesEntering A Concise Description of A Customer Problem Into A Ticketing SystemGherasie GabrielNo ratings yet
- #IncludeDocument5 pages#IncludeGherasie GabrielNo ratings yet
- Get Random Documents From A Collection in Firebase Firestore With Firebase Cloud FunctionsDocument2 pagesGet Random Documents From A Collection in Firebase Firestore With Firebase Cloud FunctionsGherasie GabrielNo ratings yet
- TextDocument1 pageTextGherasie GabrielNo ratings yet
- This Study Resource Was: Practice Set 6 Demand Management and ForecastingDocument8 pagesThis Study Resource Was: Practice Set 6 Demand Management and ForecastingAbinashMahapatraNo ratings yet
- SPSS Without PainDocument179 pagesSPSS Without PainDivine ExcellenceNo ratings yet
- Analysis of Service, Price and Quality Products To Customer SatisfactionDocument6 pagesAnalysis of Service, Price and Quality Products To Customer SatisfactionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Simple Linear Regression and CorrelationDocument52 pagesSimple Linear Regression and CorrelationMajmaah_Univ_Public100% (1)
- Learning Task 3 DraftDocument12 pagesLearning Task 3 DraftRebecca UyNo ratings yet
- Correlation and Regression AnalysisDocument17 pagesCorrelation and Regression AnalysisTariq Bin AmirNo ratings yet
- SamplingDocument66 pagesSamplingMerleAngeliM.SantosNo ratings yet
- Failure Rate Analysis of Jaw Crusher Using Weibull ModelDocument14 pagesFailure Rate Analysis of Jaw Crusher Using Weibull ModelLuigi MaguiñaNo ratings yet
- Jurnal Konformitas Dengan Perilaku Konsumtif 5Document7 pagesJurnal Konformitas Dengan Perilaku Konsumtif 5Uzha Hilman HanafiNo ratings yet
- Introduction To Business Statistics - BCPC 112 PDFDocument11 pagesIntroduction To Business Statistics - BCPC 112 PDFElizabeth InsaidooNo ratings yet
- Full Download Design and Analysis of Experiments 9th Edition Ebook PDFDocument41 pagesFull Download Design and Analysis of Experiments 9th Edition Ebook PDFmary.abernathy960100% (36)
- EBE Dummy VariablesDocument9 pagesEBE Dummy VariablesHarsha DuttaNo ratings yet
- Hypothesis Testing Part 1Document53 pagesHypothesis Testing Part 1Khaye SabaytonNo ratings yet
- Assignment02 Sec17 No Submission-1Document2 pagesAssignment02 Sec17 No Submission-1Rokibul HasanNo ratings yet
- R12 Hypothesis Testing Q BankDocument12 pagesR12 Hypothesis Testing Q Bankakshay mouryaNo ratings yet
- Advance Educational Statistics: Prof. Donabelle D. MongaoDocument17 pagesAdvance Educational Statistics: Prof. Donabelle D. MongaoDorindah DalisayNo ratings yet
- 10 CH 10 Linear Regression and CorrelationDocument92 pages10 CH 10 Linear Regression and CorrelationtilahunthmNo ratings yet
- Lecture 19Document16 pagesLecture 19huey4966No ratings yet
- WWC Dreambox 121013Document13 pagesWWC Dreambox 121013api-299398831No ratings yet
- Sampling Distributions: Section 7.1Document21 pagesSampling Distributions: Section 7.1DrMohamed MansourNo ratings yet
- Cheat Sheet For Test 4 UpdatedDocument8 pagesCheat Sheet For Test 4 UpdatedKayla SheltonNo ratings yet
- FINA340 8 Single Index Model - Full VersionDocument14 pagesFINA340 8 Single Index Model - Full VersionSteven ColeyNo ratings yet
- Chap 17 Statistical Quality ControlDocument37 pagesChap 17 Statistical Quality ControlAbhishek KesarwaniNo ratings yet
- MAS202 - Homework For Chapter 11Document4 pagesMAS202 - Homework For Chapter 11Ngọc YếnNo ratings yet
- 72 - P A G e Convenience Sampling: December 2022Document7 pages72 - P A G e Convenience Sampling: December 2022Wafaa HanyNo ratings yet
- Introduction To Robustness and Robust StatiticsDocument12 pagesIntroduction To Robustness and Robust StatiticsUmesh Sai GurramNo ratings yet
- Random Sample ConsensusDocument10 pagesRandom Sample Consensussophia787No ratings yet