You might also like
- L2 Lexical AnalysisDocument22 pagesL2 Lexical AnalysisIQRA Talim ClassNo ratings yet
- Compiler Design Chapter 2Document14 pagesCompiler Design Chapter 2Vuggam VenkateshNo ratings yet
- Lexical AnalyzerDocument17 pagesLexical AnalyzerNeoaz MahfuzNo ratings yet
- Unit - 2 Lexical AnalysisDocument11 pagesUnit - 2 Lexical Analysismdumar umarNo ratings yet
- Compiler Design 1Document30 pagesCompiler Design 1Laptop StorageNo ratings yet
- Unit 01 - PART 2Document25 pagesUnit 01 - PART 2harishkarnan004No ratings yet
- Compiler Design - Lexical AnalysisDocument2 pagesCompiler Design - Lexical Analysisswarna_793238588No ratings yet
- Lexical AnalysisDocument38 pagesLexical Analysissaeed khanNo ratings yet
- Lecture 4Document11 pagesLecture 4Chuks ValentineNo ratings yet
- rkCD-Chapter 2 - LEXICAL ANALYSISDocument9 pagesrkCD-Chapter 2 - LEXICAL ANALYSISsale msgNo ratings yet
- M.Suhaib Khalid PDFDocument10 pagesM.Suhaib Khalid PDFMohammad SuhaibNo ratings yet
- CD Unit-2Document64 pagesCD Unit-2dartionjpNo ratings yet
- Compiler Design Unit-1 - 4Document4 pagesCompiler Design Unit-1 - 4sreethu7856No ratings yet
- CD Unit 1Document35 pagesCD Unit 1Gomathi Aashika GeorgeNo ratings yet
- VMKV Engineering College Department of Computer Science & Engineering Principles of Compiler Design Unit I Part-ADocument80 pagesVMKV Engineering College Department of Computer Science & Engineering Principles of Compiler Design Unit I Part-ADular ChandranNo ratings yet
- 2-Lexical AnalysisDocument52 pages2-Lexical AnalysisHASNAIN JANNo ratings yet
- Lexical Analysis: Risul Islam RaselDocument148 pagesLexical Analysis: Risul Islam RaselRisul Islam RaselNo ratings yet
- Department of Computer Science: Subject Code: 18Kp2Cs05Document24 pagesDepartment of Computer Science: Subject Code: 18Kp2Cs05IT130 Fenil RanganiNo ratings yet
- Compiler Design - Lexical Analysis: University of Salford, UKDocument1 pageCompiler Design - Lexical Analysis: University of Salford, UKAmmar MehmoodNo ratings yet
- Certificate Declaration: Topic NameDocument16 pagesCertificate Declaration: Topic NameManish ChauhanNo ratings yet
- Compiler ConstructionDocument14 pagesCompiler ConstructionMa¡RNo ratings yet
- Compiler Construction CS-4207: Lecture 4-5 Instructor Name: Atif IshaqDocument37 pagesCompiler Construction CS-4207: Lecture 4-5 Instructor Name: Atif IshaqFaisal ShehzadNo ratings yet
- Mozart-Oz NotationDocument39 pagesMozart-Oz NotationDave20000No ratings yet
- CSC 318 Class NotesDocument21 pagesCSC 318 Class NotesYerumoh DanielNo ratings yet
- Parsing and Parsing Techniques in Compiler ConstructionDocument12 pagesParsing and Parsing Techniques in Compiler ConstructionFranklin okoloNo ratings yet
- Week 2 Lec 4 CCDocument28 pagesWeek 2 Lec 4 CCSohaib KashmiriNo ratings yet
- Lecture3 - Lexical AnalysisDocument153 pagesLecture3 - Lexical AnalysisMilon SheikhNo ratings yet
- What Is Syntax Analysis?: Syntax Analysis Is A Second Phase of The Compiler Design Process inDocument8 pagesWhat Is Syntax Analysis?: Syntax Analysis Is A Second Phase of The Compiler Design Process inRamna SatarNo ratings yet
- Implementing A Japanese Semantic Parser Based On Glue ApproachDocument8 pagesImplementing A Japanese Semantic Parser Based On Glue ApproachLam Sin WingNo ratings yet
- Lexical Analyzer Using DFA by Ingale, Vayadande, Verma, Yeole, Zawar and JamadarDocument4 pagesLexical Analyzer Using DFA by Ingale, Vayadande, Verma, Yeole, Zawar and JamadarItiel LópezNo ratings yet
- HW 6Document28 pagesHW 6Intekhab KhanNo ratings yet
- Chapter 2 - Lexical AnalysisDocument45 pagesChapter 2 - Lexical AnalysisAschalew AyeleNo ratings yet
- L3 Syntax Analysis Part1Document35 pagesL3 Syntax Analysis Part1IQRA Talim ClassNo ratings yet
- Software Tool For Translating Pseudocode To A Programming LanguageDocument9 pagesSoftware Tool For Translating Pseudocode To A Programming LanguageJames MorenoNo ratings yet
- Programming Language Notes: February 24, 2009 Morgan Mcguire Williams CollegeDocument4 pagesProgramming Language Notes: February 24, 2009 Morgan Mcguire Williams CollegeShahzad MalikNo ratings yet
- Lexical Analyzer (Compiler Contruction)Document6 pagesLexical Analyzer (Compiler Contruction)touseefaq100% (1)
- Chapter 2 Lexical AnalysisDocument26 pagesChapter 2 Lexical AnalysisElias HirpasaNo ratings yet
- Unit 2 Lexical Analysis - Part 1: Harshita SharmaDocument55 pagesUnit 2 Lexical Analysis - Part 1: Harshita SharmaVishu AasliyaNo ratings yet
- Cs1352 Principles of Compiler DesignDocument33 pagesCs1352 Principles of Compiler DesignSathishDon01No ratings yet
- Chapter 2Document6 pagesChapter 2Antehun asefaNo ratings yet
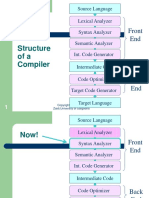
- Structure Ofa Compiler: Front EndDocument95 pagesStructure Ofa Compiler: Front EndHassan AliNo ratings yet
- 1 Principles of Compiler DesignDocument89 pages1 Principles of Compiler DesignPadmavathi BNo ratings yet
- Ss Mini ProjectDocument20 pagesSs Mini ProjectShashidhar ReddyNo ratings yet
- Compiler Design: Lexical AnalysisDocument68 pagesCompiler Design: Lexical Analysisshihab shoronNo ratings yet
- Word Sense Disambiguation Methods Applied To English and RomanianDocument8 pagesWord Sense Disambiguation Methods Applied To English and RomanianLeonNo ratings yet
- 03 Lex AnalysisDocument61 pages03 Lex Analysisaastha mallaNo ratings yet
- Chapter 2Document36 pagesChapter 2Bontu GirmaNo ratings yet
- Compiler RewindDocument52 pagesCompiler RewindneelamysrNo ratings yet
- Sri Vidya College of Engineering and Technology Question BankDocument5 pagesSri Vidya College of Engineering and Technology Question BankThiyagarajan JayasankarNo ratings yet
- Student Name: Tittle: Course: Second Stage: 2 Lecturer Name: D.wijdan Abdul AmeerDocument8 pagesStudent Name: Tittle: Course: Second Stage: 2 Lecturer Name: D.wijdan Abdul Ameerاسيا عكاب يوسف زغير صباحيNo ratings yet
- Unit 2-LEXICAL ANALYSISDocument46 pagesUnit 2-LEXICAL ANALYSISBuvana MurugaNo ratings yet
- CSC 305: Programming Paradigm: Introduction To Language, Syntax and SemanticsDocument38 pagesCSC 305: Programming Paradigm: Introduction To Language, Syntax and SemanticsDanny IshakNo ratings yet
- CConsDocument6 pagesCConsAaron RNo ratings yet
- Unit - 2Document38 pagesUnit - 2slcascs2022No ratings yet
- Compiler Overview & PhasesDocument26 pagesCompiler Overview & PhasesAadilNo ratings yet
- SE Compiler Chapter 2Document16 pagesSE Compiler Chapter 2mikiberhanu41No ratings yet
- Introduction To Compilers: Syntax AnalysisDocument35 pagesIntroduction To Compilers: Syntax AnalysisAnkit KomarNo ratings yet
- Unveiling the Power of Language: A Practical Approach to Natural Language ProcessingFrom EverandUnveiling the Power of Language: A Practical Approach to Natural Language ProcessingNo ratings yet
- CSI 411 - Compiler - Lecture 4 PDFDocument16 pagesCSI 411 - Compiler - Lecture 4 PDFMd Tasriful HoqueNo ratings yet
- CSI 411 - Compiler - Lecture 3 PDFDocument16 pagesCSI 411 - Compiler - Lecture 3 PDFMd Tasriful HoqueNo ratings yet
- CSI 411 - Compiler - Lecture 1 PDFDocument14 pagesCSI 411 - Compiler - Lecture 1 PDFMd Tasriful HoqueNo ratings yet
- Lecture 4 ERDDocument66 pagesLecture 4 ERDMd Tasriful HoqueNo ratings yet
- SurviveDocument10 pagesSurviveMi KyangNo ratings yet
- Pre Test - English 4Document5 pagesPre Test - English 4Shane Ann Basa PobleteNo ratings yet
- Hw2 2017 KeyDocument7 pagesHw2 2017 Keyprodaja47No ratings yet
- Cheat Sheets - para JumblesDocument9 pagesCheat Sheets - para JumblesMeghna ChoudharyNo ratings yet
- MA English (2008 Pattern)Document65 pagesMA English (2008 Pattern)Sanjay YadavNo ratings yet
- NarrationDocument24 pagesNarrationAdman AlifAdmanNo ratings yet
- Engleza Curs + Exam ExamplesDocument92 pagesEngleza Curs + Exam ExamplessebiNo ratings yet
- Taguchi SummaryDocument1 pageTaguchi SummaryAlita De PolloNo ratings yet
- English Grade 4Document7 pagesEnglish Grade 4محمد اكمل Kubiey0% (2)
- Chapter-1 Introduction To NLPDocument12 pagesChapter-1 Introduction To NLPSruja KoshtiNo ratings yet
- Extra - Relative PronounsDocument4 pagesExtra - Relative PronounsFrank Detchokul100% (1)
- AVANCE - PROGRAMATICO - SEP (GRUPO - INTER-sabt)Document4 pagesAVANCE - PROGRAMATICO - SEP (GRUPO - INTER-sabt)Armand MemijeNo ratings yet
- English Assignment (Present Tense) AdilaDocument5 pagesEnglish Assignment (Present Tense) AdilaAdila HidayatiNo ratings yet
- ICA WeaknessesDocument2 pagesICA WeaknessesMishal AbbasiNo ratings yet
- Long QuizDocument3 pagesLong QuizJubylyn AficialNo ratings yet
- WS BG3 M01 L17 Grammar ROOM2Document2 pagesWS BG3 M01 L17 Grammar ROOM2Paola MartínezNo ratings yet
- S LP Goals and Objectives UpdateDocument17 pagesS LP Goals and Objectives UpdateXlian Myzter YosaNo ratings yet
- VI-A English Unit 3 School Days Chapter 2 Oliver Twist (Play Script) 27.11.2020Document19 pagesVI-A English Unit 3 School Days Chapter 2 Oliver Twist (Play Script) 27.11.2020Yaseen Piyar Ali100% (1)
- RecountDocument14 pagesRecountPriti Dewi Sulistya AiniNo ratings yet
- Class Test - 01Document2 pagesClass Test - 01Md Shahbub Alam SonyNo ratings yet
- Learn MarathiDocument126 pagesLearn Marathiapi-358669406No ratings yet
- Visual Latin Sample 1 and 2 AnswersDocument7 pagesVisual Latin Sample 1 and 2 AnswerscompasscinemaNo ratings yet
- Semantics Multiple Choice QuestionsDocument20 pagesSemantics Multiple Choice QuestionsThu Huyền Trần100% (1)
- Develpoment Sequence of L2 LearningDocument8 pagesDevelpoment Sequence of L2 LearningShirin AfrozNo ratings yet
- English Syntax: by Ramda MarfalenDocument9 pagesEnglish Syntax: by Ramda MarfalenErnaaNo ratings yet
- Regular VerbsDocument2 pagesRegular VerbsAlejandra Callie Ortiz PerezNo ratings yet
- Participle ClausesDocument8 pagesParticiple ClausesTâm Anh LêNo ratings yet
- English Iv Unit 7 Lesson 2Document32 pagesEnglish Iv Unit 7 Lesson 2Ani Rous CcNo ratings yet
- KBSR English Scheme of Work, Primary 3, 2010Document15 pagesKBSR English Scheme of Work, Primary 3, 2010Cynthia C. James100% (1)