You might also like
- E-Mail Spam Detection Using Machine Learning and Deep LearningDocument7 pagesE-Mail Spam Detection Using Machine Learning and Deep LearningIJRASETPublicationsNo ratings yet
- Power System Protection and SwitchgearDocument96 pagesPower System Protection and SwitchgearjonatasNo ratings yet
- Learn Penetration Testing with Python 3.x: Perform Offensive Pentesting and Prepare Red Teaming to Prevent Network Attacks and Web Vulnerabilities (English Edition)From EverandLearn Penetration Testing with Python 3.x: Perform Offensive Pentesting and Prepare Red Teaming to Prevent Network Attacks and Web Vulnerabilities (English Edition)Rating: 5 out of 5 stars5/5 (1)
- Sentiment Analysis On TwitterDocument8 pagesSentiment Analysis On TwitterIJRISE Journal100% (2)
- Sentiment Analysis On Covid-19 Using Deep LearningDocument9 pagesSentiment Analysis On Covid-19 Using Deep LearningIJRASETPublicationsNo ratings yet
- Michael Walker - Data Cleaning and Exploration With Machine Learning - Get To Grips With Machine Learning Techniques To Achieve Sparkling-Clean Data Quickly-Packt Publishing (2022)Document542 pagesMichael Walker - Data Cleaning and Exploration With Machine Learning - Get To Grips With Machine Learning Techniques To Achieve Sparkling-Clean Data Quickly-Packt Publishing (2022)Shankaranarayanan GopalanNo ratings yet
- Semi-Supervised Spam Detection in Twitter StreamDocument7 pagesSemi-Supervised Spam Detection in Twitter Streamkaran kallaNo ratings yet
- Statistical Twitter Spam Detection Demystified: Performance, Stability and ScalabilityDocument13 pagesStatistical Twitter Spam Detection Demystified: Performance, Stability and ScalabilityAakash GargNo ratings yet
- Twitter Data Preprocessing For Spam Detection: Myungsook KlassenDocument6 pagesTwitter Data Preprocessing For Spam Detection: Myungsook KlassenSupportGameNo ratings yet
- Spammer Detect Project DocumentDocument45 pagesSpammer Detect Project Documentsainadh upputhollaNo ratings yet
- Spammer Detection and Fake User Identification On Social NetworksDocument9 pagesSpammer Detection and Fake User Identification On Social NetworksTech NestNo ratings yet
- 1.1 Over ViewDocument6 pages1.1 Over ViewVirupaksha BMNo ratings yet
- Survey On Spam Filtering in Text Analysis: Saksham Sharma, Rabi Raj YadavDocument7 pagesSurvey On Spam Filtering in Text Analysis: Saksham Sharma, Rabi Raj YadavAnonymous TpYSenLO8aNo ratings yet
- An Integrated Approach For Malicious Tweets Detection Using NLPDocument4 pagesAn Integrated Approach For Malicious Tweets Detection Using NLPTech NestNo ratings yet
- A Comprehensive Review On Twitter Spam DetectionDocument13 pagesA Comprehensive Review On Twitter Spam DetectionHamza MunirNo ratings yet
- (IJCST-V10I5P20) :MR D.Purushothaman, K PavanDocument9 pages(IJCST-V10I5P20) :MR D.Purushothaman, K PavanEighthSenseGroupNo ratings yet
- E-Mail Spam Detection and Classification Using SVM and Feature ExtractionDocument5 pagesE-Mail Spam Detection and Classification Using SVM and Feature ExtractionUthra RamanNo ratings yet
- Monitoring Suspicious Discussions On Online Forums Using Data MiningDocument3 pagesMonitoring Suspicious Discussions On Online Forums Using Data MiningSANDYA DUMPANo ratings yet
- Multi-Purpose Chat Bot: Team Formation Team MembersDocument15 pagesMulti-Purpose Chat Bot: Team Formation Team MembersShubham ChaudharyNo ratings yet
- mln2018 PDFDocument11 pagesmln2018 PDFKheir eddine DaouadiNo ratings yet
- Opinion Mining On Social Media Data: 2013 IEEE 14th International Conference On Mobile Data ManagementDocument6 pagesOpinion Mining On Social Media Data: 2013 IEEE 14th International Conference On Mobile Data ManagementsenthilnathanNo ratings yet
- Twitter Spam Detection Based On Deep Learning: Tingmin Wu, Shigang Liu, Jun Zhang and Yang XiangDocument8 pagesTwitter Spam Detection Based On Deep Learning: Tingmin Wu, Shigang Liu, Jun Zhang and Yang XiangR SNo ratings yet
- 5 - Real Time Spam TwitterDocument1 page5 - Real Time Spam Twitterrajeshkumar32itNo ratings yet
- Credibility Analysis For Tweets Written in Turkish by A Hybrid MethodDocument8 pagesCredibility Analysis For Tweets Written in Turkish by A Hybrid MethodliezelleannNo ratings yet
- Evolving Intelligent System For Classification Twitter Data: Dr. Yossra Hussain AliDocument16 pagesEvolving Intelligent System For Classification Twitter Data: Dr. Yossra Hussain Aliحيدر محمدNo ratings yet
- Sentiment Analysis On Twitter Data Using Machine Learning Algorithms in PythonDocument15 pagesSentiment Analysis On Twitter Data Using Machine Learning Algorithms in PythonSuresh MutyalaNo ratings yet
- Detection of Social Network Spam Based On Improved Extreme Learning MachineDocument23 pagesDetection of Social Network Spam Based On Improved Extreme Learning MachineKalyan Reddy AnuguNo ratings yet
- Improving Cyberbullying Detection With User ContextDocument4 pagesImproving Cyberbullying Detection With User ContextAshish SinghNo ratings yet
- LPKM 2018 PDFDocument9 pagesLPKM 2018 PDFKheir eddine DaouadiNo ratings yet
- Spam Detection in Social Media Using Machine Learning AlgorithmDocument10 pagesSpam Detection in Social Media Using Machine Learning AlgorithmIJRASETPublicationsNo ratings yet
- Paper 26-A Topic Based Approach For Sentiment AnalysisDocument5 pagesPaper 26-A Topic Based Approach For Sentiment Analysisjorge quilumbaNo ratings yet
- S U R J S S: Indh Niversity Esearch Ournal (Cience Eries)Document6 pagesS U R J S S: Indh Niversity Esearch Ournal (Cience Eries)adsNo ratings yet
- Paper 0229Document10 pagesPaper 0229RwothomioNo ratings yet
- 9 Ijcse 02139Document9 pages9 Ijcse 02139CHILUKA PREETHINo ratings yet
- Cyberspace News Prediction of Text and ImageDocument53 pagesCyberspace News Prediction of Text and ImagecityNo ratings yet
- Cyberbullying IPRDocument25 pagesCyberbullying IPRSajid MdNo ratings yet
- Social Network Shaming Text: Identification, Inspection, ReductionDocument12 pagesSocial Network Shaming Text: Identification, Inspection, ReductionHetNo ratings yet
- Project ReportDocument10 pagesProject ReportAnurag PandeyNo ratings yet
- Detecting Spammers in Youtube: A Study To Find Spam Content in A Video PlatformDocument5 pagesDetecting Spammers in Youtube: A Study To Find Spam Content in A Video PlatformIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- Mathematical JournalDocument18 pagesMathematical JournalkriithigaNo ratings yet
- Fake Accounts Detection On Social Media (Instagram and Twitter)Document8 pagesFake Accounts Detection On Social Media (Instagram and Twitter)jasdeep jassNo ratings yet
- Rathore2018 - Epidemic Model-Based Visibility Estimation in Online Social NetworksDocument8 pagesRathore2018 - Epidemic Model-Based Visibility Estimation in Online Social NetworksNemi rathoreNo ratings yet
- Irjet Fake News Prediction Using MachineDocument5 pagesIrjet Fake News Prediction Using Machinealperen.unal89No ratings yet
- Sentiment Analysis On TwitterDocument7 pagesSentiment Analysis On TwitterarmanghouriNo ratings yet
- 12 Chapter 5 PSO-GA-DTDocument24 pages12 Chapter 5 PSO-GA-DTgomathiNo ratings yet
- Segregating Tweets Using Machine LearningDocument4 pagesSegregating Tweets Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Detection Hate OffensiveDocument6 pagesDetection Hate Offensivexiaoanw17No ratings yet
- Multilingual Cyberbullying Detection System-2019Document6 pagesMultilingual Cyberbullying Detection System-2019mubeen naeemNo ratings yet
- A Hybrid Approach For Detecting Automated Spammers in TwitterDocument6 pagesA Hybrid Approach For Detecting Automated Spammers in TwittergestNo ratings yet
- Sentiment Analysis in Airline Tweets Using Mutual Information For Feature SelectionDocument6 pagesSentiment Analysis in Airline Tweets Using Mutual Information For Feature SelectionArpan SoniNo ratings yet
- Monitoring of Suspicious Discussions On Online Forums Using Data MiningDocument7 pagesMonitoring of Suspicious Discussions On Online Forums Using Data MiningSANDYA DUMPANo ratings yet
- Distortion and LSADocument13 pagesDistortion and LSAMarian AldescuNo ratings yet
- Spam Identification On Facebook, Twitter and Email Using Machine LearningDocument9 pagesSpam Identification On Facebook, Twitter and Email Using Machine LearningHatim LakhdarNo ratings yet
- Paper 8908Document7 pagesPaper 8908IJARSCT JournalNo ratings yet
- Author Profiling Using Semantic and Syntactic FeaturesDocument12 pagesAuthor Profiling Using Semantic and Syntactic FeaturesKarthik KrishnamurthiNo ratings yet
- An Ensemble Approach For The Identification and Classification of Crime Tweets in The English LanguageDocument11 pagesAn Ensemble Approach For The Identification and Classification of Crime Tweets in The English LanguageCSIT iaesprimeNo ratings yet
- Sentiment Analysis On Twitter Hashtag DatasetsDocument6 pagesSentiment Analysis On Twitter Hashtag DatasetsIJRASETPublicationsNo ratings yet
- A Survey of Recent Techniques For Detection of Spam Profiles in Online Social NetworksDocument7 pagesA Survey of Recent Techniques For Detection of Spam Profiles in Online Social NetworkskriithigaNo ratings yet
- Sentiff Combining Textual Information and Sentimental Diffusion Patterns For Twitter Sentimental AnalysisDocument14 pagesSentiff Combining Textual Information and Sentimental Diffusion Patterns For Twitter Sentimental AnalysisAbhishek ReddyNo ratings yet
- Sentence Embedding To Improve Rumour Detection Performance ModelDocument7 pagesSentence Embedding To Improve Rumour Detection Performance ModelIAES IJAINo ratings yet
- NCSPCN 12 CRPDocument3 pagesNCSPCN 12 CRPajitharaja2003No ratings yet
- Seminar f0Document17 pagesSeminar f0Kiranmai DindigalaNo ratings yet
- Analysis of Women Safety Using Machine Learning On TweetsDocument4 pagesAnalysis of Women Safety Using Machine Learning On TweetsVinetha NekkantiNo ratings yet
- Question Paper Code: X: (10×2 20 Marks)Document3 pagesQuestion Paper Code: X: (10×2 20 Marks)Tech NestNo ratings yet
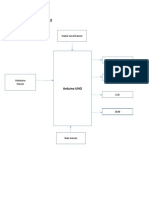
- Block Diagram: Water Level SensorDocument1 pageBlock Diagram: Water Level SensorTech NestNo ratings yet
- A Study On Brand Preference of Soft Drinks at Madurai CityDocument13 pagesA Study On Brand Preference of Soft Drinks at Madurai CityTech NestNo ratings yet
- Government Polytechnic CollegeDocument1 pageGovernment Polytechnic CollegeTech NestNo ratings yet
- GOVERNMENT POLYTECHNIC COLLEGE VeeraDocument2 pagesGOVERNMENT POLYTECHNIC COLLEGE VeeraTech NestNo ratings yet
- FFFDocument3 pagesFFFTech NestNo ratings yet
- 12th Maths Vol.2 Model Question Paper Tamil MediumDocument6 pages12th Maths Vol.2 Model Question Paper Tamil MediumTech NestNo ratings yet
- Government Polytechnic College: Bonafide CertificateDocument2 pagesGovernment Polytechnic College: Bonafide CertificateTech NestNo ratings yet
- 06 - Chapter 3Document28 pages06 - Chapter 3Tech NestNo ratings yet
- 04 - Chapter 1Document20 pages04 - Chapter 1Tech NestNo ratings yet
- Factors Influencing Branded Soft Drinks Among The People of Salem, Tamil NaduDocument6 pagesFactors Influencing Branded Soft Drinks Among The People of Salem, Tamil NaduTech NestNo ratings yet
- Profit Maximization Strategy With Spot AllocationDocument6 pagesProfit Maximization Strategy With Spot AllocationTech NestNo ratings yet
- 05 - Chapter 2Document28 pages05 - Chapter 2Tech NestNo ratings yet
- Secure Data Sharing in Cloud Computing Using Revocable StorageDocument13 pagesSecure Data Sharing in Cloud Computing Using Revocable StorageAmit PandeyNo ratings yet
- 26Document1 page26Tech NestNo ratings yet
- An Integrated Approach For Malicious Tweets Detection Using NLPDocument4 pagesAn Integrated Approach For Malicious Tweets Detection Using NLPTech NestNo ratings yet
- AGREEMENTDocument1 pageAGREEMENTTech NestNo ratings yet
- EliminationDocument2 pagesEliminationTech NestNo ratings yet
- Abstract PDFDocument1 pageAbstract PDFTech NestNo ratings yet
- Customer Perceived Value - and Risk-AwareDocument15 pagesCustomer Perceived Value - and Risk-AwareTech NestNo ratings yet
- Cloud BasepaperDocument13 pagesCloud BasepaperTech NestNo ratings yet
- Table of Content PDFDocument5 pagesTable of Content PDFTech NestNo ratings yet
- AsssDocument1 pageAsssTech NestNo ratings yet
- Table of Content PDFDocument5 pagesTable of Content PDFTech NestNo ratings yet
- ReportDocument67 pagesReportTech NestNo ratings yet
- 9Document12 pages9Tech NestNo ratings yet
- Jewel LoanDocument1 pageJewel LoanTech NestNo ratings yet
- Monitoring and Detection of Agricultural Disease Using Wireless Sensor NetworkDocument5 pagesMonitoring and Detection of Agricultural Disease Using Wireless Sensor NetworkJaya VakapalliNo ratings yet
- NBA Salary Prediction PresentationDocument29 pagesNBA Salary Prediction PresentationKINN JOHN CHOWNo ratings yet
- MGNM801 Ca2Document19 pagesMGNM801 Ca2Atul KumarNo ratings yet
- Applied Machine Learning Course Schedule: TopicDocument29 pagesApplied Machine Learning Course Schedule: TopicAmarjeet KrishhnanNo ratings yet
- A Review of Multi-Class Classification AlgorithmsDocument10 pagesA Review of Multi-Class Classification AlgorithmsSamuel AsmelashNo ratings yet
- Telecom Customer Churn Prediction Assessment-Pratik ZankeDocument19 pagesTelecom Customer Churn Prediction Assessment-Pratik Zankepratik zankeNo ratings yet
- Quiz 4 - Attempt ReviewDocument3 pagesQuiz 4 - Attempt ReviewciciNo ratings yet
- Research PaperDocument13 pagesResearch PaperPrateek IngoleNo ratings yet
- Template Full PaperDocument11 pagesTemplate Full PaperHarisIlmanFiqihNo ratings yet
- Implementing Clinical Decision Support System Using Naïve Bayesian ClassifierDocument6 pagesImplementing Clinical Decision Support System Using Naïve Bayesian ClassifierEditor IJRITCCNo ratings yet
- Lecture Notes For Chapter 5 Introduction To Data Mining: by Tan, Steinbach, KumarDocument88 pagesLecture Notes For Chapter 5 Introduction To Data Mining: by Tan, Steinbach, KumarmounikaNo ratings yet
- My Final FileDocument54 pagesMy Final Fileharshit gargNo ratings yet
- Naïve Bayes Classifier: Ke ChenDocument20 pagesNaïve Bayes Classifier: Ke ChenEri ZuliarsoNo ratings yet
- Applied AI CourseDocument26 pagesApplied AI CourseSai KiranNo ratings yet
- Cs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryDocument20 pagesCs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryZeeshan Ali SayyedNo ratings yet
- Bangla Licence Plate Detection & Recognition Using ANNDocument84 pagesBangla Licence Plate Detection & Recognition Using ANNkaniz fatemaNo ratings yet
- ML Gtu QuestionsDocument4 pagesML Gtu QuestionsKunj PatelNo ratings yet
- AI Fundamentals Midterm Exam - Attempt ReviewDocument17 pagesAI Fundamentals Midterm Exam - Attempt ReviewkielmorganzapietoNo ratings yet
- Personality Prediction Using CV, Deep LearningDocument7 pagesPersonality Prediction Using CV, Deep LearningIJRASETPublicationsNo ratings yet
- Bayesian Classification: Dr. Navneet Goyal BITS, PilaniDocument35 pagesBayesian Classification: Dr. Navneet Goyal BITS, PilaniSiti OmarNo ratings yet
- 6 - Naive BayesDocument26 pages6 - Naive BayesHadiNo ratings yet
- Fake News Detection Using Machine LearniDocument13 pagesFake News Detection Using Machine LearniTefe100% (1)
- NotebookDocument10 pagesNotebookBruno PereiraNo ratings yet
- V23i9047 1694756701Document6 pagesV23i9047 1694756701cumar aadan apdiNo ratings yet
- Android Application For Crop Yield Prediction and Crop Disease DetectionDocument4 pagesAndroid Application For Crop Yield Prediction and Crop Disease DetectionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Bayessian ClassificationDocument5 pagesBayessian ClassificationManoj BalajiNo ratings yet
- Development of Faculty Qualification Analysis System Using Naive Bayes AlgorithmDocument11 pagesDevelopment of Faculty Qualification Analysis System Using Naive Bayes AlgorithmInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Automated ML Approaches To Discriminate The Autism-Categorical Spectrum DisorderDocument5 pagesAutomated ML Approaches To Discriminate The Autism-Categorical Spectrum Disorderibmlenovo2021No ratings yet