You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
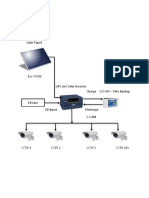
- Solar Panel 2Document2 pagesSolar Panel 2sonaiya software solutionsNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Heart Attack Prediction Full DocumentDocument28 pagesHeart Attack Prediction Full Documentsonaiya software solutionsNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Components Quantity Price: Total 7,584Document2 pagesComponents Quantity Price: Total 7,584sonaiya software solutionsNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Improving The Security of Wireless Sensor NetworksDocument108 pagesImproving The Security of Wireless Sensor Networkssonaiya software solutionsNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Fast Nearest Neighbor Search With KeywordsDocument75 pagesFast Nearest Neighbor Search With Keywordssonaiya software solutionsNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Criminal Face IdentificationDocument94 pagesCriminal Face Identificationsonaiya software solutionsNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- A Study On Customer Satisfaction On Digital Marketing in Online Advertising CompanyDocument109 pagesA Study On Customer Satisfaction On Digital Marketing in Online Advertising Companysonaiya software solutionsNo ratings yet
- Modules and DFDDocument5 pagesModules and DFDsonaiya software solutionsNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Components Price For LockerDocument8 pagesComponents Price For Lockersonaiya software solutionsNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Computer Institute: NameDocument11 pagesComputer Institute: Namesonaiya software solutionsNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Digital Marketing SyllabusDocument8 pagesDigital Marketing Syllabussonaiya software solutionsNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- New Doc AgentDocument64 pagesNew Doc Agentsonaiya software solutionsNo ratings yet
- Metrology: Bob O'Brien Dave Miller NHCTC at PeaseDocument129 pagesMetrology: Bob O'Brien Dave Miller NHCTC at PeaseOula HatahetNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Digital MarketingDocument29 pagesDigital Marketingsonaiya software solutionsNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- 1st Facilitating Document Annotation Using Content and Querying ValueDocument4 pages1st Facilitating Document Annotation Using Content and Querying Valuesonaiya software solutionsNo ratings yet
- Manage McDonald's Shop OnlineDocument21 pagesManage McDonald's Shop Onlinesonaiya software solutionsNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- School Management SystemDocument61 pagesSchool Management SystemSheela Sadanand82% (33)
- Agriculture Management SoftwareDocument10 pagesAgriculture Management Softwaresonaiya software solutionsNo ratings yet
- Souravproject3 170322074809 PDFDocument46 pagesSouravproject3 170322074809 PDFjagrutiNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Medical Equipment Calibration and Quality Assurance: March 2014Document51 pagesMedical Equipment Calibration and Quality Assurance: March 2014sonaiya software solutionsNo ratings yet
- Project Repport: Myk Laticrete India PVT - Ltd. KolkataDocument76 pagesProject Repport: Myk Laticrete India PVT - Ltd. KolkatamonishaNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Online Educational Portal With Latest TechnologiesDocument10 pagesOnline Educational Portal With Latest Technologiessonaiya software solutionsNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- CitizenshipDocument14 pagesCitizenshipsonaiya software solutionsNo ratings yet
- S. No Column Name Data Type Description Remarks: 1 Nam Number (20) Employee Name Primary Key 2 Loc Varchar (20) LocationDocument4 pagesS. No Column Name Data Type Description Remarks: 1 Nam Number (20) Employee Name Primary Key 2 Loc Varchar (20) Locationsonaiya software solutionsNo ratings yet
- On A New Paradigm For Stock Trading Via A Model Free Feedback Controller 2nd ReviewDocument23 pagesOn A New Paradigm For Stock Trading Via A Model Free Feedback Controller 2nd Reviewsonaiya software solutionsNo ratings yet
- Buy AROMA MAGIC OIL IN CHENNAIDocument1 pageBuy AROMA MAGIC OIL IN CHENNAIsonaiya software solutionsNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- College Bus TrackingDocument23 pagesCollege Bus Trackingsonaiya software solutions100% (1)
- Modeling and Detection of Camouflaging Worm 2nd ReviewDocument13 pagesModeling and Detection of Camouflaging Worm 2nd Reviewsonaiya software solutionsNo ratings yet
- Intelligent Home Monitoring and Security 1st ReviewDocument7 pagesIntelligent Home Monitoring and Security 1st Reviewsonaiya software solutionsNo ratings yet
- Monochrome Digital Production Press: TechnologyDocument8 pagesMonochrome Digital Production Press: TechnologyAlexNo ratings yet
- DFI Boards Catalog 2021 R2 - 210705 - 1028 - WebDocument32 pagesDFI Boards Catalog 2021 R2 - 210705 - 1028 - WebWai Leong WongNo ratings yet
- Build a Mining Rig Guide: Components & ProcessDocument10 pagesBuild a Mining Rig Guide: Components & ProcessMadalin Cristian ConstantinNo ratings yet
- Neelayam PrgrmingDocument125 pagesNeelayam PrgrmingAthl SNo ratings yet
- CODAC Core System Overview 34SDZ5 v4 3Document26 pagesCODAC Core System Overview 34SDZ5 v4 3jadecu11252No ratings yet
- Prinect Package Designer Illustrator Connect 2017 - Installation ENDocument16 pagesPrinect Package Designer Illustrator Connect 2017 - Installation ENOleg100% (1)
- DOC1 Overview: An Introduction For ProgrammersDocument23 pagesDOC1 Overview: An Introduction For ProgrammersartikalraNo ratings yet
- Language-Based Vectorization and Parallelization Using Intrinsics, Openmp, TBB and Cilk PlusDocument12 pagesLanguage-Based Vectorization and Parallelization Using Intrinsics, Openmp, TBB and Cilk PlusanaNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Practical-8: Create An Application in Android To Find Factorial of A Given Number Using Onclick EventDocument4 pagesPractical-8: Create An Application in Android To Find Factorial of A Given Number Using Onclick EventhdtrsNo ratings yet
- Module 11 Utilizing A Shared Object RepositoryDocument13 pagesModule 11 Utilizing A Shared Object RepositoryMashiro ShiinaNo ratings yet
- 06 Karil06 iJIM Plant Watering Maria Monika SytDocument8 pages06 Karil06 iJIM Plant Watering Maria Monika SytSuyoto UAJYNo ratings yet
- 2018 Edpm Paper 1 PDFDocument5 pages2018 Edpm Paper 1 PDFCeline DookramNo ratings yet
- It - Unit 15 - Test Plan Report TemplateDocument13 pagesIt - Unit 15 - Test Plan Report Templateapi-667853795No ratings yet
- Computer Basic 1201Document6 pagesComputer Basic 1201Doinik DorkarNo ratings yet
- What Was The Original Motivation Behind IntelDocument1 pageWhat Was The Original Motivation Behind IntelAntony LawrenceNo ratings yet
- Business Cards Logo Design Photoshop Editing Presentation Design Poster DesignDocument3 pagesBusiness Cards Logo Design Photoshop Editing Presentation Design Poster DesignAmazing K Makers (Havijithan)No ratings yet
- Implementation of The Virtual Camber Transformation Into The - 2018 - Energy PDFDocument8 pagesImplementation of The Virtual Camber Transformation Into The - 2018 - Energy PDFVikram KumarNo ratings yet
- Computer Padhanam MS ExcelDocument9 pagesComputer Padhanam MS Excelaboobacker saqafi AgathiNo ratings yet
- HP P6000 CV Kit ContentsDocument13 pagesHP P6000 CV Kit ContentsADM HOSTCoNo ratings yet
- DX DiagDocument25 pagesDX DiagLevente NagyNo ratings yet
- G11 - Module 2Document19 pagesG11 - Module 2Daniel Daryl CalingNo ratings yet
- Dell™ Latitude™ E5410 Discrete Service Manual: Notes, Cautions, and WarningsDocument81 pagesDell™ Latitude™ E5410 Discrete Service Manual: Notes, Cautions, and WarningsciphardNo ratings yet
- Design and Comparision of Low Power High Speed 4 Bit - AluDocument40 pagesDesign and Comparision of Low Power High Speed 4 Bit - AluMohammed I.BayoumeyNo ratings yet
- AVEVA White Paper Schematic Model PDFDocument12 pagesAVEVA White Paper Schematic Model PDFtsaipeterNo ratings yet
- Engineering Drawing GlossaryDocument37 pagesEngineering Drawing GlossaryJuan MaNo ratings yet
- TanagraDocument8 pagesTanagra2BL20IS038 Pooja SulakheNo ratings yet
- Top 100 Linux Interview Questions AnswersDocument33 pagesTop 100 Linux Interview Questions AnswersMansoor75% (4)
- Petrel 2020-4 Release NotesDocument19 pagesPetrel 2020-4 Release NotesAiwarikiaarNo ratings yet
- 24slides - Online Test For Graphic DesignerDocument6 pages24slides - Online Test For Graphic DesignerFarid AdrianNo ratings yet
- Excel Module 01Document35 pagesExcel Module 01jieNo ratings yet
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)From EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Rating: 5 out of 5 stars5/5 (1)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)