You might also like
- Manual Caterpillar d5m d6m d6r Track Type Tractors Power Train Control System Components Diagrams PDFDocument12 pagesManual Caterpillar d5m d6m d6r Track Type Tractors Power Train Control System Components Diagrams PDFBruno Cecatto86% (21)
- Part B: User ManualDocument13 pagesPart B: User ManualtecnicoopNo ratings yet
- AI Outputs (4,5,6,7)Document16 pagesAI Outputs (4,5,6,7)avnimote121No ratings yet
- CSE3002 LAB ASSIGNMENT-5: 8 PUZZLE PROBLEM USING BFSDocument4 pagesCSE3002 LAB ASSIGNMENT-5: 8 PUZZLE PROBLEM USING BFSKSSK 9250No ratings yet
- Eight Puzzle Problem Heuristics ComparisonDocument7 pagesEight Puzzle Problem Heuristics ComparisonAayush MehtaNo ratings yet
- Py Code Example 4 1 Gradient MC EvaluationDocument4 pagesPy Code Example 4 1 Gradient MC EvaluationEmily ChengNo ratings yet
- Artificial Intelligence RecordDocument26 pagesArtificial Intelligence RecordHarishwaran V.No ratings yet
- Test-1 Answer KeyDocument23 pagesTest-1 Answer KeymuralidharNo ratings yet
- Aiml LabDocument14 pagesAiml Lab1DT19IS146TriveniNo ratings yet
- Artificial Intelligence Lab FileDocument16 pagesArtificial Intelligence Lab FileSaurabh SinghNo ratings yet
- Ass 3Document3 pagesAss 3Akash SahuNo ratings yet
- #Iteration Counter: Gradient - DescentDocument2 pages#Iteration Counter: Gradient - DescentDivyani ChavanNo ratings yet
- 8 Tile PuzzleDocument5 pages8 Tile Puzzlebrainx MagicNo ratings yet
- 8 PuzzleDocument5 pages8 PuzzleAsif KhanNo ratings yet
- Ai LabDocument15 pagesAi Lab4653Anushika PatelNo ratings yet
- Implement A* Search and AO* Search Algorithms (39Document15 pagesImplement A* Search and AO* Search Algorithms (39Shubham KumarNo ratings yet
- Assessment AIDocument4 pagesAssessment AIKIRUTHIKA V UCS20443No ratings yet
- 8 Puzzle ProblemDocument3 pages8 Puzzle ProblemhajraNo ratings yet
- Ai Week-4Document5 pagesAi Week-4sadiqali4244No ratings yet
- AI Lab Assignment Solves N-Queens ProblemDocument10 pagesAI Lab Assignment Solves N-Queens ProblemBabar AliNo ratings yet
- Machine Learning Lab Manual: Implement Backpropagation AlgorithmDocument13 pagesMachine Learning Lab Manual: Implement Backpropagation AlgorithmKumaraswamy AnnamNo ratings yet
- Implement Bot Save Princess Grid PathfindingDocument5 pagesImplement Bot Save Princess Grid PathfindingPratik RathodNo ratings yet
- Py Code Example 4 1 Policy EvaluationDocument3 pagesPy Code Example 4 1 Policy EvaluationEmily ChengNo ratings yet
- Search Algorithm Assignment !Document12 pagesSearch Algorithm Assignment !anurag.nuweshNo ratings yet
- Practical - 2Document9 pagesPractical - 2mrdevil1.2007No ratings yet
- P03 A Star Algorithm 35 Anushka ShettyDocument23 pagesP03 A Star Algorithm 35 Anushka ShettyanohanabrotherhoodcaveNo ratings yet
- AI ALL PRACTICAL 56Document25 pagesAI ALL PRACTICAL 56Kaushal ChauvhanNo ratings yet
- Ai Exp 4Document9 pagesAi Exp 4aditya bNo ratings yet
- Lab Programs.Document21 pagesLab Programs.ramNo ratings yet
- ML LabDocument7 pagesML LabSharan PatilNo ratings yet
- T21-86 AI Exp6Document5 pagesT21-86 AI Exp6Gaurang PatyaneNo ratings yet
- Ai 5 11Document13 pagesAi 5 11Devangi PatelNo ratings yet
- DAA MaualDocument24 pagesDAA MaualManoj MNo ratings yet
- 3PA07 - 11519645 - Demita Riassekar Cututri 8-Puzzles - IpynbDocument6 pages3PA07 - 11519645 - Demita Riassekar Cututri 8-Puzzles - Ipynb3PA07 Demita Riassekar CututriNo ratings yet
- Exe 1Document13 pagesExe 1jaya pandiNo ratings yet
- 8 PuzzleDocument5 pages8 Puzzlearchana palNo ratings yet
- Ai Experiment 4Document7 pagesAi Experiment 4avnimote121No ratings yet
- algoDocument10 pagesalgoManikandan KNo ratings yet
- Py Code Example 3 5 Policy EvaluationDocument3 pagesPy Code Example 3 5 Policy EvaluationEmily ChengNo ratings yet
- Ai LabDocument48 pagesAi Labvignesheai22No ratings yet
- (Assignment) : Introductiontocomputer ScienceandcontemporaraylanDocument22 pages(Assignment) : Introductiontocomputer ScienceandcontemporaraylanHASHAM DESAINo ratings yet
- DadiDocument5 pagesDadiGïø KavtaradzeNo ratings yet
- DAA RecordDocument15 pagesDAA Recorddharun0704No ratings yet
- Artificial Intelligence Lab File CompressDocument19 pagesArtificial Intelligence Lab File Compresskanta deviNo ratings yet
- Backtracking: Consider The N Queens Problem - Discover If and How N Queens Can Be Placed On AnDocument11 pagesBacktracking: Consider The N Queens Problem - Discover If and How N Queens Can Be Placed On AnAbhijit GovekarNo ratings yet
- Neal Wu-000000000088b044Document11 pagesNeal Wu-000000000088b044mushagraNo ratings yet
- AI Lets GoDocument28 pagesAI Lets GoRushikesh BallalNo ratings yet
- PythonDocument10 pagesPythonKalim Ullah MarwatNo ratings yet
- Ai - Digital AssignmentDocument14 pagesAi - Digital AssignmentRamagopal VemuriNo ratings yet
- QMHISBSORT TimeDocument6 pagesQMHISBSORT TimeGhousia College of EngineeringNo ratings yet
- 4ann - 5Th ProgDocument15 pages4ann - 5Th Progshreyas .cNo ratings yet
- Load CSV, Normalize Features, Logistic RegressionDocument3 pagesLoad CSV, Normalize Features, Logistic RegressioncndNo ratings yet
- Ai-Ce Lab ManualDocument35 pagesAi-Ce Lab ManualMama JiNo ratings yet
- Ai Practical FileDocument14 pagesAi Practical FileSo JaNo ratings yet
- ML Course Description & Lab ExperimentsDocument48 pagesML Course Description & Lab ExperimentsRavi ShankarNo ratings yet
- Question BankDocument4 pagesQuestion BankROHAN T ANo ratings yet
- SML - Week 2Document4 pagesSML - Week 2szho68No ratings yet
- DaaDocument7 pagesDaakjhsuigajighNo ratings yet
- Ex No - 2 (B) Memory-Bounded A AlgorithmDocument5 pagesEx No - 2 (B) Memory-Bounded A Algorithmkpramya19No ratings yet
- Wa0002.Document5 pagesWa0002.sir BryanNo ratings yet
- 17 Arid 6459 TheoryDocument17 pages17 Arid 6459 TheoryLucky Asr AwaisNo ratings yet
- Convolution ExampleDocument20 pagesConvolution ExampleLucky Asr AwaisNo ratings yet
- Crime PortalDocument10 pagesCrime PortalLucky Asr AwaisNo ratings yet
- Design and Implementation of an Online Crime Reporting SystemDocument58 pagesDesign and Implementation of an Online Crime Reporting SystemShaikh Hasim AliNo ratings yet
- Online Crime Reporting System: Submitted byDocument56 pagesOnline Crime Reporting System: Submitted byLucky Asr AwaisNo ratings yet
- Documentation SampleDocument52 pagesDocumentation SampleLucky Asr AwaisNo ratings yet
- Q3) Write A Java Code For Given Question - Write A ...Document5 pagesQ3) Write A Java Code For Given Question - Write A ...Lucky Asr AwaisNo ratings yet
- Textbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkDocument4 pagesTextbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkLucky Asr AwaisNo ratings yet
- Constraint Satisfaction ProblemDocument43 pagesConstraint Satisfaction ProblemLucky Asr AwaisNo ratings yet
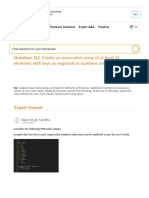
- Question: Q2: Create An Associative Array of at Least 15 Elements With Keys As Registration Numbers and Val..Document4 pagesQuestion: Q2: Create An Associative Array of at Least 15 Elements With Keys As Registration Numbers and Val..Lucky Asr AwaisNo ratings yet
- Your Question Has Been Answered: Question: Q2. Answer Following: A. Why Data Transformation Is ImportanDocument3 pagesYour Question Has Been Answered: Question: Q2. Answer Following: A. Why Data Transformation Is ImportanLucky Asr AwaisNo ratings yet
- Allama Allama Iqbal Open University Open UniversityDocument1 pageAllama Allama Iqbal Open University Open UniversityLucky Asr AwaisNo ratings yet
- 17 Arid 6459 TheoryDocument17 pages17 Arid 6459 TheoryLucky Asr AwaisNo ratings yet
- Adversary SearchDocument26 pagesAdversary SearchLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument8 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- 17 Arid 6459 TheoryDocument17 pages17 Arid 6459 TheoryLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument21 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- Allama Allama Iqbal Open University Open UniversityDocument1 pageAllama Allama Iqbal Open University Open UniversityLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument21 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument21 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument8 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- 17 Arid 6459 TheoryDocument17 pages17 Arid 6459 TheoryLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument21 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- Demoralization to enhance efficiency in data miningDocument3 pagesDemoralization to enhance efficiency in data miningLucky Asr AwaisNo ratings yet
- 17 Arid 6459 TheoryDocument17 pages17 Arid 6459 TheoryLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument21 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- Arid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherDocument21 pagesArid Agriculture University, Rawalpindi: Final Exam / Spring 2021 (Paper Duration 12 Hours) To Be Filled by TeacherLucky Asr AwaisNo ratings yet
- 17-Arid-6382 (Muhammad Awais Riaz)Document9 pages17-Arid-6382 (Muhammad Awais Riaz)Lucky Asr AwaisNo ratings yet
- Demoralization to enhance efficiency in data miningDocument3 pagesDemoralization to enhance efficiency in data miningLucky Asr AwaisNo ratings yet
- 17 Arid 6459 TheoryDocument17 pages17 Arid 6459 TheoryLucky Asr AwaisNo ratings yet
- Introduction To Structured Query Language (SQL) - Part 1 PDFDocument14 pagesIntroduction To Structured Query Language (SQL) - Part 1 PDFbazezewNo ratings yet
- Manual Transmission and DifferentialDocument1 pageManual Transmission and DifferentialJeff PascoeNo ratings yet
- HHM Unit-1 PDFDocument66 pagesHHM Unit-1 PDFAchyutha AnilNo ratings yet
- Introduction to StatisticsDocument9 pagesIntroduction to StatisticsJudith CuevaNo ratings yet
- The Android Arsenal - Dialogs - Spots Progress DialogDocument8 pagesThe Android Arsenal - Dialogs - Spots Progress DialogRudolfNo ratings yet
- Power Team PA6 Pumps - CatalogDocument2 pagesPower Team PA6 Pumps - CatalogTitanplyNo ratings yet
- IBPS PO Study Material for Computer FundamentalsDocument30 pagesIBPS PO Study Material for Computer FundamentalsPapan SarkarNo ratings yet
- Adjusted School Reading Program of Buneg EsDocument7 pagesAdjusted School Reading Program of Buneg EsGener Taña AntonioNo ratings yet
- CNC Programming Tutorials Examples G and M Codes Programming Tutorial Example Code For Beginner To Advance Level CNC Machinist PDFDocument302 pagesCNC Programming Tutorials Examples G and M Codes Programming Tutorial Example Code For Beginner To Advance Level CNC Machinist PDFSanjai RohanNo ratings yet
- Tutorial For Processing LiDAR Datasets and Visualization (For Slovenian Lidar)Document13 pagesTutorial For Processing LiDAR Datasets and Visualization (For Slovenian Lidar)ksk upNo ratings yet
- Unit I Lesson 4 Computing The Variance of A Discrete Probability DistributionDocument23 pagesUnit I Lesson 4 Computing The Variance of A Discrete Probability DistributionKira MilestoneNo ratings yet
- Contoh InvoiceDocument2 pagesContoh InvoiceLinda RizkaNo ratings yet
- 3 Installing The Product: Downloaded From Manuals Search EngineDocument41 pages3 Installing The Product: Downloaded From Manuals Search EngineHyacinthe KOSSINo ratings yet
- Cloud Computing VXVDFVDFVDFVDFBVDFDocument12 pagesCloud Computing VXVDFVDFVDFVDFBVDFNehaNo ratings yet
- What Are Your Children Watching On Youtube?: December 2011Document11 pagesWhat Are Your Children Watching On Youtube?: December 2011Quỳnh nhiNo ratings yet
- Maharashtra State Board of Technical EducationDocument15 pagesMaharashtra State Board of Technical EducationKavir AhirNo ratings yet
- Datasheet M 900ib 700Document1 pageDatasheet M 900ib 700oscar AlvaradoNo ratings yet
- Qu Windows Driver Help V4.67.0Document2 pagesQu Windows Driver Help V4.67.0cristian ticonaNo ratings yet
- Flujometro SierraDocument52 pagesFlujometro SierraCapacitacion TodocatNo ratings yet
- Tms 5220Document2 pagesTms 5220WaldoNo ratings yet
- MessageDocument2 pagesMessageDominyka CharičevaitėNo ratings yet
- UART Implementation Using FPGA: December 2019Document50 pagesUART Implementation Using FPGA: December 2019V.ASHISH REDDYNo ratings yet
- Inte 314 ExamsDocument4 pagesInte 314 ExamsskipchirchirNo ratings yet
- 100 MCQ Questions For Operating Systems MCQ Sets PDFDocument29 pages100 MCQ Questions For Operating Systems MCQ Sets PDFghodkeshital291150% (4)
- Dell Case Study - G02Document3 pagesDell Case Study - G02Miniteca Mega Rumba0% (1)
- NXP Elec Boq - 15.04.2022 - FDocument24 pagesNXP Elec Boq - 15.04.2022 - FShreya BhattacharyaNo ratings yet
- Check SAP RESUME NALNI - 12Document7 pagesCheck SAP RESUME NALNI - 12Afsar AbdulNo ratings yet
- Page 44Document1 pagePage 44Abhishek ShatagopachariNo ratings yet