You might also like
- AQA A Level Biology Paper 1 ChecklistsDocument28 pagesAQA A Level Biology Paper 1 Checklistsnutritionist1234567100% (1)
- User'S Manual: Design Program For Sizing of Heating and Cooling Hydraulic Systems Version: 5.xx - YyDocument122 pagesUser'S Manual: Design Program For Sizing of Heating and Cooling Hydraulic Systems Version: 5.xx - YyHo Dac ThanhNo ratings yet
- Fpdf2 ManualDocument136 pagesFpdf2 Manualsantiagoromo10No ratings yet
- 6754 DatasheetDocument1 page6754 DatasheetSuryakanth KattimaniNo ratings yet
- Walmart Inc PDFDocument1 pageWalmart Inc PDFWaqar AhmedNo ratings yet
- Think and HistoryDocument1 pageThink and HistoryfaizNo ratings yet
- Gonorrhea: Sexually Transmitted Disease Surveillance 2000Document12 pagesGonorrhea: Sexually Transmitted Disease Surveillance 2000Srinivas KasiNo ratings yet
- SF No 28 Kadhampadi ModelDocument1 pageSF No 28 Kadhampadi ModelmanojNo ratings yet
- SF No 28 Kadhampadi ModelDocument1 pageSF No 28 Kadhampadi ModelmanojNo ratings yet
- Tri VLDocument1 pageTri VLJ Pierre RicherNo ratings yet
- Pongalur 232,242 1NNDocument1 pagePongalur 232,242 1NNGeo Mapl InfraNo ratings yet
- CL 2000Document2 pagesCL 2000Frozen MinakoNo ratings yet
- Forecasting Stationary ModelsDocument22 pagesForecasting Stationary ModelsVINAY GUPTANo ratings yet
- CNN Features Off-the-Shelf - An Astounding Baseline For RecognitionDocument8 pagesCNN Features Off-the-Shelf - An Astounding Baseline For RecognitionhiriNo ratings yet
- Analysis and Measurements - 115-180Document66 pagesAnalysis and Measurements - 115-180김동은No ratings yet
- Tree of MoneyDocument10 pagesTree of MoneyGishan Nadeera GunadasaNo ratings yet
- Apple - Report PDFDocument1 pageApple - Report PDFUwie AndrianaNo ratings yet
- GEA - Bock - SemiHerm - Catalogue - GB 4Document1 pageGEA - Bock - SemiHerm - Catalogue - GB 4hadi mehrabiNo ratings yet
- An Introduction To The General Linear Model (GLM)Document47 pagesAn Introduction To The General Linear Model (GLM)Ibrahim JawedNo ratings yet
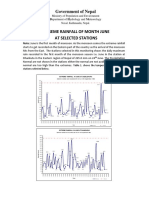
- 1437960464extreme Rainfall JuneDocument7 pages1437960464extreme Rainfall JuneSuyogya DahalNo ratings yet
- Pareto Analysis of Aircraft DefectsDocument4 pagesPareto Analysis of Aircraft Defectsnishat529No ratings yet
- Ansheet SheetDocument1 pageAnsheet SheetMarcial Jr. MilitanteNo ratings yet
- Gen 3 Ruralconnect SpecificationsDocument4 pagesGen 3 Ruralconnect SpecificationsDeriansyah Al GhurabaNo ratings yet
- Deep Learning For Scene Classification: A SurveyDocument24 pagesDeep Learning For Scene Classification: A Surveyamta1No ratings yet
- FIRM1Document1 pageFIRM1janm45.niazisolutionsNo ratings yet
- VFD HarmonicsDocument1 pageVFD HarmonicstwinvbooksNo ratings yet
- Lampiran 3 SpssDocument25 pagesLampiran 3 SpssyulianaNo ratings yet
- 1 s2.0 S022352341530180X mmc1Document80 pages1 s2.0 S022352341530180X mmc1tumtumNo ratings yet
- Bematech KC4112-3Document10 pagesBematech KC4112-3Nicolas EncisoNo ratings yet
- Book 2Document1 pageBook 2Abu TalhaNo ratings yet
- Motor Selection For VFD AplicationsDocument21 pagesMotor Selection For VFD Aplicationskrajeev2802No ratings yet
- Tabel VariabelDocument3 pagesTabel VariabelbarbieNo ratings yet
- Traffic Rep0518Document21 pagesTraffic Rep0518Yaruqh KhanNo ratings yet
- GEA - Bock - SemiHerm - Catalogue - GB 18Document1 pageGEA - Bock - SemiHerm - Catalogue - GB 18hadi mehrabiNo ratings yet
- Hatchery and Incubation Trends: Tarsicio Villalobos Technical Services Global Biodevices & AutomationDocument46 pagesHatchery and Incubation Trends: Tarsicio Villalobos Technical Services Global Biodevices & AutomationAndre FahmiNo ratings yet
- Gr-Iv-Paper-I - Final KeyDocument4 pagesGr-Iv-Paper-I - Final Key17-306 VivekNo ratings yet
- SmartPTT Enterprise Radioserver Configurator GuideDocument246 pagesSmartPTT Enterprise Radioserver Configurator GuideSmartPTTNo ratings yet
- A Osman Akan Open Channel Hydraulics-225-238Document14 pagesA Osman Akan Open Channel Hydraulics-225-238Juan Esteban Romero ArrietaNo ratings yet
- Arcadis QCPFeb18Document6 pagesArcadis QCPFeb18Alyanna Hipe - EsponillaNo ratings yet
- B7 Logistic Curve c3t9Document9 pagesB7 Logistic Curve c3t9ammi890No ratings yet
- Feb2023 Air TrafficDocument20 pagesFeb2023 Air TrafficSubash NehruNo ratings yet
- Hasil SpssDocument4 pagesHasil SpssHanif Al AzisNo ratings yet
- Sensair Manual 1.0 en PDFDocument104 pagesSensair Manual 1.0 en PDFPaul KinsellaNo ratings yet
- Oecd - Edu.imep, DSD Eag Uoe Fin@Df Uoe Fin Source GV PR Ndom, 1.0, Filtered, 2024!01!04 11-38-55Document158 pagesOecd - Edu.imep, DSD Eag Uoe Fin@Df Uoe Fin Source GV PR Ndom, 1.0, Filtered, 2024!01!04 11-38-55Emilia InfanteNo ratings yet
- Laporan BulananDocument7 pagesLaporan Bulananmuhammad syaifuddin ihsanNo ratings yet
- Plano ApartamentoDocument1 pagePlano Apartamentorobinson doradoNo ratings yet
- Schedule Performance Index - Ujang SonjayaDocument2 pagesSchedule Performance Index - Ujang SonjayaUjang BOP EngineerNo ratings yet
- Chuyên đề 3a - Biểu thuế XNK Việt NamDocument48 pagesChuyên đề 3a - Biểu thuế XNK Việt NamThao BuiNo ratings yet
- Upper Floor UpdateDocument1 pageUpper Floor UpdatejamellaNo ratings yet
- Intergrowth21 Postnatal Growth Standards For Preterm Infants (Boys)Document2 pagesIntergrowth21 Postnatal Growth Standards For Preterm Infants (Boys)Anonymous MWd5UOUuiyNo ratings yet
- Rotron Regenerative Blowers CatalogDocument2 pagesRotron Regenerative Blowers CatalogEnrique ArmandoNo ratings yet
- Preliminary Design Considerations For Variable Geometry Radial Turbines With Multi-Points SpecificationsDocument13 pagesPreliminary Design Considerations For Variable Geometry Radial Turbines With Multi-Points SpecificationsSyed Jiaul HoqueNo ratings yet
- Link Net Company Presentation - Investor UpdateDocument47 pagesLink Net Company Presentation - Investor UpdateumarhidayatNo ratings yet
- AnswerKey UttarPradesh NTSE Stg1 2018-19 SAT-MAT PDFDocument2 pagesAnswerKey UttarPradesh NTSE Stg1 2018-19 SAT-MAT PDFFalguni SahaNo ratings yet
- MotiveWave Volume Analysis Version 6Document89 pagesMotiveWave Volume Analysis Version 6SudheerNaiduNo ratings yet
- SPSS Individu JegrekDocument7 pagesSPSS Individu Jegrekbiill biellNo ratings yet
- FoodDocument1 pageFoodDaily FreemanNo ratings yet
- Sample Vs CuDocument1 pageSample Vs CuRevathiNo ratings yet
- Lampiran 6 Output Karakteristik RespondenDocument8 pagesLampiran 6 Output Karakteristik Respondenferi ferNo ratings yet
- Data - Sheet - MSP1-80.0-6 - VORTEX - 1+MA1.1A - 2,5 (2.5 - HP) - COS 11lps at 2m TDHDocument3 pagesData - Sheet - MSP1-80.0-6 - VORTEX - 1+MA1.1A - 2,5 (2.5 - HP) - COS 11lps at 2m TDHpaachangaNo ratings yet
- Limited Permission To Copy or Distribute Sequence InformationDocument17 pagesLimited Permission To Copy or Distribute Sequence InformationhellowinstonNo ratings yet
- Contributory Cause: Unnecessary and Insufficient: Postgraduate MedicineDocument4 pagesContributory Cause: Unnecessary and Insufficient: Postgraduate MedicinehellowinstonNo ratings yet
- Sequencing Library QPCR Quantification: GuideDocument28 pagesSequencing Library QPCR Quantification: GuidehellowinstonNo ratings yet
- 2011 Varshavsky Ubr1 MutationsDocument10 pages2011 Varshavsky Ubr1 MutationshellowinstonNo ratings yet
- NEB Gibson Master ManualDocument26 pagesNEB Gibson Master ManualhellowinstonNo ratings yet
- Autoclaving Glassware CorningDocument2 pagesAutoclaving Glassware CorninghellowinstonNo ratings yet
- As A Result of Numerous Consumer Complaints of Dizziness and NauseaDocument1 pageAs A Result of Numerous Consumer Complaints of Dizziness and NauseahellowinstonNo ratings yet
- Perceived Toddler Sleep Problems, Co Sleeping, And.99340Document8 pagesPerceived Toddler Sleep Problems, Co Sleeping, And.99340Circa NewsNo ratings yet
- AGR 32 Exer 7 - IPMDocument4 pagesAGR 32 Exer 7 - IPMAngelo HernandezNo ratings yet
- BSC 100 Midterm Questions For Oral ExamDocument20 pagesBSC 100 Midterm Questions For Oral ExamNovochino CastilloNo ratings yet
- 26 185080600111030 Muhammad Farhan AnshoryDocument7 pages26 185080600111030 Muhammad Farhan AnshoryEka WidyaNo ratings yet
- Pedigree WorksheetDocument3 pagesPedigree WorksheetAbed ZaghalNo ratings yet
- Clinical Manifestations and Diagnosis of HHT (Osler-Weber-Rendu Syndrome) - UpToDateDocument14 pagesClinical Manifestations and Diagnosis of HHT (Osler-Weber-Rendu Syndrome) - UpToDateArturoNo ratings yet
- DDFAO Baze Stiintifice Si Interpret AreDocument54 pagesDDFAO Baze Stiintifice Si Interpret Arecaneoalex578100% (2)
- Collection, Char. and Seed Multiplication PDFDocument1 pageCollection, Char. and Seed Multiplication PDFADSRNo ratings yet
- LightMix Influenza A enDocument5 pagesLightMix Influenza A envijayNo ratings yet
- Alat Pelindung Diri (APD) /PPEDocument11 pagesAlat Pelindung Diri (APD) /PPERizky ArifNo ratings yet
- The Ultimate Guide To Methylene Blue Remarkable Hope For Depression, COVID, AIDS Other Viruses, Alzheimer's, Autism, Cancer,... (Mark Sloan) (Z-Library)Document171 pagesThe Ultimate Guide To Methylene Blue Remarkable Hope For Depression, COVID, AIDS Other Viruses, Alzheimer's, Autism, Cancer,... (Mark Sloan) (Z-Library)pieterNo ratings yet
- Human EmbriologyDocument67 pagesHuman EmbriologyGalang Perdamaian0% (1)
- LA PREDICTION (8th April To 14th April 2022)Document331 pagesLA PREDICTION (8th April To 14th April 2022)Meftahul JannatNo ratings yet
- Van Es 2017 New Definition of Soil CSANEWSDocument2 pagesVan Es 2017 New Definition of Soil CSANEWSKarthii6No ratings yet
- Bayesian Estimation of Concordance Among Gene TreesDocument15 pagesBayesian Estimation of Concordance Among Gene TreesJames McInerneyNo ratings yet
- The - MD2 - Super - Sweet Pineapple Ananas Comosu29 PDFDocument2 pagesThe - MD2 - Super - Sweet Pineapple Ananas Comosu29 PDFchin100% (1)
- The Cannacea - Exclusive Beta Excerpt-CANCERDocument10 pagesThe Cannacea - Exclusive Beta Excerpt-CANCERBrian SumnerNo ratings yet
- Viruses & Bacteria: Biology 11Document28 pagesViruses & Bacteria: Biology 11Adnan Bhisma RizaldyNo ratings yet
- Journal Pre-Proof: BioprintingDocument51 pagesJournal Pre-Proof: BioprintingWalter Ricardo BritoNo ratings yet
- BSC 1010C Unit 2 Test - The CellDocument4 pagesBSC 1010C Unit 2 Test - The CellAmalee CarrascoNo ratings yet
- Henderson 2009Document25 pagesHenderson 2009Karla MorenoNo ratings yet
- Chapt08 (BIO150)Document29 pagesChapt08 (BIO150)Valecia LeachNo ratings yet
- PBL NMR 1Document5 pagesPBL NMR 1andiNo ratings yet
- Central Dogma of LifeDocument17 pagesCentral Dogma of LifeSathish KumarNo ratings yet
- Stromatolyser 3WP SR 22 SRP 200A - 10 2006Document2 pagesStromatolyser 3WP SR 22 SRP 200A - 10 2006ItaNo ratings yet
- Cerebraal Spinal FluidDocument34 pagesCerebraal Spinal FluidElisa NNo ratings yet
- Mishkin 1983 PDFDocument4 pagesMishkin 1983 PDFamandaNo ratings yet
- Nitrogen Cycle - Lecture NotesDocument2 pagesNitrogen Cycle - Lecture NotesB-Sadorra, Marls Angel Roe N.No ratings yet
- New Orbital Single Use BioreactorDocument1 pageNew Orbital Single Use BioreactorCharles LeeNo ratings yet