You might also like
- FOM Pr. 9Document3 pagesFOM Pr. 9Shreyash BhoiteNo ratings yet
- Full Stack Softwear DevelopmentDocument3 pagesFull Stack Softwear DevelopmentVIkas SharmaNo ratings yet
- पाठ ११ कबीर के दोहे WbDocument4 pagesपाठ ११ कबीर के दोहे Wbsatvikdeshmukh06No ratings yet
- Simone Mola - Fundamentals of Vehicle DynamicsDocument353 pagesSimone Mola - Fundamentals of Vehicle DynamicsWagner AbreuNo ratings yet
- l/1AIR34 Real Analysis and Partial Differential Equations Class Test One MaximumDocument6 pagesl/1AIR34 Real Analysis and Partial Differential Equations Class Test One MaximumprathikNo ratings yet
- Exam "Evolution Migration 5G Indp2, Sirt A B, C: E Le Ie S Communications de TunisDocument2 pagesExam "Evolution Migration 5G Indp2, Sirt A B, C: E Le Ie S Communications de TunisOumayma MhamdiNo ratings yet
- Sequencer in CM NotesDocument3 pagesSequencer in CM NotessaigptuseNo ratings yet
- Advanced Machine Tools Final ExamsDocument11 pagesAdvanced Machine Tools Final ExamsAhmed MohamedNo ratings yet
- FOM Pr. 10Document4 pagesFOM Pr. 10Shreyash BhoiteNo ratings yet
- Arthritis FormulaDocument1 pageArthritis FormulaSteve WilliamsonNo ratings yet
- M32 Maintenance Manual A2794-30Document122 pagesM32 Maintenance Manual A2794-30drkorneyNo ratings yet
- VivaDocument8 pagesVivaPoojitha NaikNo ratings yet
- Observer Based Detection and Recognition of External Disturbances For Large TurbogeneratorsDocument7 pagesObserver Based Detection and Recognition of External Disturbances For Large TurbogeneratorsKarthik KamuniNo ratings yet
- MT/MS/M : and Ptrmltt9d Havtns Address As Mentioned DocumentsDocument2 pagesMT/MS/M : and Ptrmltt9d Havtns Address As Mentioned DocumentsDebasis BagNo ratings yet
- No. 13 & Windows Application Validation Various Controls.: Pra Tical 14 Impl Ment A To Perform OnDocument7 pagesNo. 13 & Windows Application Validation Various Controls.: Pra Tical 14 Impl Ment A To Perform OnRootNo ratings yet
- Nilai Dan NormaDocument2 pagesNilai Dan NormaIvyNo ratings yet
- The University O THE: F West IndiesDocument3 pagesThe University O THE: F West IndiesDom PowellNo ratings yet
- P Cl&/6.Uqn: Facilllf 1Tnd Co Appllcant 2") From Iidft My Lrelltt Umhlp) 2 MyDocument1 pageP Cl&/6.Uqn: Facilllf 1Tnd Co Appllcant 2") From Iidft My Lrelltt Umhlp) 2 MyDebasis BagNo ratings yet
- M Thebehae Ass1Document5 pagesM Thebehae Ass1MalefaneNo ratings yet
- Arkray HA-8180 BrochureDocument2 pagesArkray HA-8180 BrochureOo Kenx OoNo ratings yet
- Internal Temp Rolling TireDocument15 pagesInternal Temp Rolling TiresiritapeNo ratings yet
- Pullman Elongation 19FDocument4 pagesPullman Elongation 19FCường Nguyễn MạnhNo ratings yet
- 3rd Year Past Papers 2021Document77 pages3rd Year Past Papers 2021duncan ochamiNo ratings yet
- Electronic Switching SystemDocument40 pagesElectronic Switching SystemDeepansh SharmaNo ratings yet
- Modern Power Transformer Practice - R. Feinberg PDFDocument360 pagesModern Power Transformer Practice - R. Feinberg PDFAlberto Ortiz100% (1)
- Paper 2Document16 pagesPaper 2Ali ElmaihyNo ratings yet
- MOST An Advance Prof S S PatilDocument7 pagesMOST An Advance Prof S S PatilSudhir KumarNo ratings yet
- Sanket Subhas MaliDocument13 pagesSanket Subhas MaliRADHA MALINo ratings yet
- Operation Manual TPL69-A PDFDocument65 pagesOperation Manual TPL69-A PDFмоно конечноNo ratings yet
- LRTR .... : Integrated Science 2003 P1Document8 pagesLRTR .... : Integrated Science 2003 P1KIMBERLEY MILLERNo ratings yet
- Chapter 1Document12 pagesChapter 1Kiahna Clare ArdaNo ratings yet
- Ecw 401 - Tutorial 4 (Chapter 2) (Hydrostatic Forces On Curved Surfaces & Pressure Diagram)Document2 pagesEcw 401 - Tutorial 4 (Chapter 2) (Hydrostatic Forces On Curved Surfaces & Pressure Diagram)Nasreq HayalNo ratings yet
- Powell, J. David - Workman, Michael L. - Franklin, Gene F. - Solutions Manual For Digital Control of Dynamic Systems-Addison-Wesley (1998)Document454 pagesPowell, J. David - Workman, Michael L. - Franklin, Gene F. - Solutions Manual For Digital Control of Dynamic Systems-Addison-Wesley (1998)Francisco GarciaNo ratings yet
- Gradiente HPLC RecomendacionesDocument3 pagesGradiente HPLC RecomendacionesTab CoastNo ratings yet
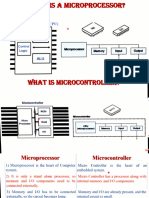
- Difference Between Microprocessor and MicroprocessorDocument10 pagesDifference Between Microprocessor and Microprocessoree210150900103No ratings yet
- KV 314 - Rampal Edition With Cadenzas PDFDocument8 pagesKV 314 - Rampal Edition With Cadenzas PDFMaurihuaanaa Navarro SantanaNo ratings yet
- Mumbat: Revised Syllabus For The Instrumentation Engineering V VI)Document20 pagesMumbat: Revised Syllabus For The Instrumentation Engineering V VI)DeeptivmNo ratings yet
- Scan Apr 1, 2019Document3 pagesScan Apr 1, 2019Navya VerukondaNo ratings yet
- Hydraulic NotesDocument62 pagesHydraulic NotesPrakashNo ratings yet
- MCE-SKMC-311-OSC-GF-MS-CI-009 Cast in Situ Concrete WorksDocument31 pagesMCE-SKMC-311-OSC-GF-MS-CI-009 Cast in Situ Concrete WorksAnonymous swFolM3gXNo ratings yet
- Adobe Scan 03 Jun 2023Document15 pagesAdobe Scan 03 Jun 2023SS PSNo ratings yet
- 03.27.2014 - FDLE Stingray Records Non-Disclosure Agreement With Harris CorpDocument4 pages03.27.2014 - FDLE Stingray Records Non-Disclosure Agreement With Harris CorpTop Gun Top GunNo ratings yet
- Phy Unit 3 Part B2 ?Document15 pagesPhy Unit 3 Part B2 ?jnarwal111No ratings yet
- Laboratory - 1 AC Circuits Phasors and Impedance TransformersDocument19 pagesLaboratory - 1 AC Circuits Phasors and Impedance TransformersAhmed SalehNo ratings yet
- Adobe Scan 21 Feb 2023Document13 pagesAdobe Scan 21 Feb 202311D-27-Aysha NoushadNo ratings yet
- Anuc Caruana Experiment 1Document6 pagesAnuc Caruana Experiment 1caruanaanuc12No ratings yet
- SequencingDocument11 pagesSequencingdivya rashmiNo ratings yet
- Chapter-4: Application of The MethodologyDocument18 pagesChapter-4: Application of The Methodology임광식No ratings yet
- Specificationc of Construcuon: Cqucncc of Chemical J.ND Opcr - Uaon.Document14 pagesSpecificationc of Construcuon: Cqucncc of Chemical J.ND Opcr - Uaon.RADHE GRAPHICSNo ratings yet
- Tjuu,,:Jml +Ii+Mlmmlml.+'" '.: 'ShiftsDocument4 pagesTjuu,,:Jml +Ii+Mlmmlml.+'" '.: 'ShiftsHassan GillNo ratings yet
- Mewar Niversity: Academic & Administrative Audit Report (Internal)Document77 pagesMewar Niversity: Academic & Administrative Audit Report (Internal)gokek80159No ratings yet
- Mech Engg Mathematics Midsem 1 October 31 2023Document2 pagesMech Engg Mathematics Midsem 1 October 31 2023vyeshwanth0621No ratings yet
- Service Manual & Part List - Casio FX 850p - 1987Document25 pagesService Manual & Part List - Casio FX 850p - 1987Iron NNo ratings yet
- Syllabus BookDocument51 pagesSyllabus BookvaibhavroysNo ratings yet
- Tugas AKL 1 P8.2 Dan P8.4 - Ghautsul Azham Saryono - C1C019114Document2 pagesTugas AKL 1 P8.2 Dan P8.4 - Ghautsul Azham Saryono - C1C019114Kenny GunawanNo ratings yet
- Is Iec 60794 1 1 2001Document18 pagesIs Iec 60794 1 1 2001Anonymous P2Kij3LjHgNo ratings yet
- @yogi NMR SpectrosDocument25 pages@yogi NMR SpectrosYogesh PingleNo ratings yet
- Adobe Scan Dec 05, 2023Document3 pagesAdobe Scan Dec 05, 2023sumaiya16skhNo ratings yet
- Cuaderno Pp.135 144Document10 pagesCuaderno Pp.135 144Ryan BlakeNo ratings yet
- 11.qurratulain Nasir PDFDocument7 pages11.qurratulain Nasir PDFOkoi OkaNo ratings yet
- Final BBMSDocument16 pagesFinal BBMSPreethu GowdaNo ratings yet
- 09.Project-Hospital Management SystemDocument50 pages09.Project-Hospital Management SystemRajeev Ranjan89% (91)
- Fastrack WatchesDocument48 pagesFastrack WatchesPreethu GowdaNo ratings yet
- ReadmeDocument1 pageReadmePreethu GowdaNo ratings yet
- Activity DiagramDocument1 pageActivity DiagramPreethu GowdaNo ratings yet
- Effects of Advertising On Sales PerformaDocument18 pagesEffects of Advertising On Sales PerformaUsman Tariq0% (1)
- 1 PB PDFDocument9 pages1 PB PDFIñnøcent ManinderNo ratings yet
- 1 PB PDFDocument9 pages1 PB PDFIñnøcent ManinderNo ratings yet
- Tata Consultancy Services Ltd. Company AnalysisDocument70 pagesTata Consultancy Services Ltd. Company AnalysisPiyush ThakarNo ratings yet
- A Synopsis of Project "Online Ngo Donation Management"Document43 pagesA Synopsis of Project "Online Ngo Donation Management"Preethu GowdaNo ratings yet
- Online Charity Management System: Language: Dotnet Backend/Database: SQL ServerDocument2 pagesOnline Charity Management System: Language: Dotnet Backend/Database: SQL ServerPreethu GowdaNo ratings yet
- HelpDocument545 pagesHelpPreethu Gowda100% (1)
- E-Music (Online Music Website) : ChaptersDocument25 pagesE-Music (Online Music Website) : ChaptersPreethu Gowda0% (1)
- SRS For iMMS (Internet Music Management System)Document20 pagesSRS For iMMS (Internet Music Management System)Imran Ahmed Hunzai100% (1)
- Asp NotesDocument224 pagesAsp Notesvivek1218No ratings yet
- The Effect of Cross-Cultural Management On The Performance of Multinational Companies in NigeriaDocument13 pagesThe Effect of Cross-Cultural Management On The Performance of Multinational Companies in NigeriaPreethu GowdaNo ratings yet
- 02 PrefaceDocument1 page02 PrefacePreethu GowdaNo ratings yet
- Sample Project - Real EstateDocument8 pagesSample Project - Real EstatePreethu GowdaNo ratings yet
- Adekoya Olusola PDFDocument38 pagesAdekoya Olusola PDFPreethu GowdaNo ratings yet
- Chapter 13 Quality Management and ReportingDocument21 pagesChapter 13 Quality Management and ReportingHSE LEARNERS SYED YOUSAFNo ratings yet
- 00 Building MGTDocument3 pages00 Building MGTPreethu GowdaNo ratings yet
- Synopsis Online AuctionDocument9 pagesSynopsis Online AuctionAshim Ranjan Bora0% (2)
- 3 Factors Affecting Customer PDFDocument19 pages3 Factors Affecting Customer PDFMd. Jahangir AlamNo ratings yet
- Srs of CharityDocument35 pagesSrs of CharityPreethu GowdaNo ratings yet
- Online Auction System PDFDocument89 pagesOnline Auction System PDFPreethu GowdaNo ratings yet
- Online Certificate VerificatonDocument76 pagesOnline Certificate VerificatonMaria DassNo ratings yet
- Zforce Touch Final ReportDocument19 pagesZforce Touch Final ReportPreethu GowdaNo ratings yet
- Acceptability of Electric Vehicles Findings From ADocument16 pagesAcceptability of Electric Vehicles Findings From APreethu GowdaNo ratings yet
- A Study On Brand Positioning of Pepsi in Hyderabad: B. ChandanaDocument13 pagesA Study On Brand Positioning of Pepsi in Hyderabad: B. ChandanaPreethu GowdaNo ratings yet
- Math 4Document2 pagesMath 4Maslog Regg ReguloNo ratings yet
- Module-4 Lex YaccDocument67 pagesModule-4 Lex YaccH3ck AssassinNo ratings yet
- Abap New Syntax Examples 7.40 7.52Document5 pagesAbap New Syntax Examples 7.40 7.52Berk Can PolatNo ratings yet
- Answer Key cs6203Document6 pagesAnswer Key cs6203Mark JuarezNo ratings yet
- Stack-1680704260201 STKDocument2 pagesStack-1680704260201 STKBell DanceNo ratings yet
- DTR2023Document23 pagesDTR2023Barangay DitucalanNo ratings yet
- Coefficient of Concurrent DeviationsDocument2 pagesCoefficient of Concurrent DeviationsPolice station100% (1)
- 18CSC205J Operating Systems-Unit-5Document138 pages18CSC205J Operating Systems-Unit-5Darsh RawatNo ratings yet
- Rhyne Mixzanry Magesarey L. Rodriguez 11 - Galatians Module 1: Derivatives and Its Application Summative AssesmentDocument5 pagesRhyne Mixzanry Magesarey L. Rodriguez 11 - Galatians Module 1: Derivatives and Its Application Summative AssesmentAlex RodriguezNo ratings yet
- Lec 08 - Hill ClimbingDocument42 pagesLec 08 - Hill ClimbingMateen AhmedNo ratings yet
- There Is No LimitDocument25 pagesThere Is No LimitTony SanchezNo ratings yet
- Computer Application Examination: (Email ID:)Document1 pageComputer Application Examination: (Email ID:)SoumyadipNo ratings yet
- Caesar Cipher Method Design and ImplemenDocument10 pagesCaesar Cipher Method Design and Implemenbrian karuNo ratings yet
- RDD TDD DDD MDD BDD DBCDocument4 pagesRDD TDD DDD MDD BDD DBCdxi60431No ratings yet
- Reverse Traversal HomeworkDocument3 pagesReverse Traversal Homeworkabhi74No ratings yet
- Disk Scheduling ProblemDocument2 pagesDisk Scheduling ProblemMushira ShaikhNo ratings yet
- Laporan UAS Praktek Teknik Antarmuka MikrokontrolerDocument15 pagesLaporan UAS Praktek Teknik Antarmuka MikrokontrolerFadilla RosalinaNo ratings yet
- Lab Assignment 5Document10 pagesLab Assignment 5Samridhi JNo ratings yet
- 01 Task Performance 1/prelim Exam - ARGDocument2 pages01 Task Performance 1/prelim Exam - ARGJerome BautistaNo ratings yet
- 02 Buffer PDFDocument229 pages02 Buffer PDFCharitha ReddyNo ratings yet
- Microprocessor and Assembly Language CSC-321: Sheeza ZaheerDocument30 pagesMicroprocessor and Assembly Language CSC-321: Sheeza Zaheerali chaudaryNo ratings yet
- Mscds2022 SolutionsDocument23 pagesMscds2022 SolutionsMohammad Faiz HashmiNo ratings yet
- 2nd PUC Computer Science Super ImportantDocument16 pages2nd PUC Computer Science Super ImportantGiriraj KapaseNo ratings yet
- Algorithms and Problem Solving (15B11CI411) : EVEN 2022Document32 pagesAlgorithms and Problem Solving (15B11CI411) : EVEN 2022Vivek GargNo ratings yet
- Scaler Academy Entrance Quiz - Dipak BagadeDocument8 pagesScaler Academy Entrance Quiz - Dipak BagadeDipak Bagade100% (1)
- CIT 3102 Programming Supp TownDocument2 pagesCIT 3102 Programming Supp TownzareebrawnyNo ratings yet
- CSCI 3110 Assignment 6 Solutions: December 5, 2012Document5 pagesCSCI 3110 Assignment 6 Solutions: December 5, 2012AdamNo ratings yet
- Computer Science Application 1Document5 pagesComputer Science Application 1Izuku MedoriyaNo ratings yet
- 1Document4 pages1rajeshNo ratings yet
- Syllabus - App LabDocument1 pageSyllabus - App LabSunita MouryaNo ratings yet