You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- ExpressDocument141 pagesExpressEndy Santoso100% (1)
- Machine Learning Methods in The Environm - William W. HsiehDocument365 pagesMachine Learning Methods in The Environm - William W. Hsiehmorteza hosseini100% (1)
- Audit in CBS Environment: CA. Kuntal P. Shah BackgroundDocument28 pagesAudit in CBS Environment: CA. Kuntal P. Shah BackgroundPatricia UkemNo ratings yet
- 4 2020 Big Data Analytics For Cyber-Physical System in Smart City - 663, 768Document2,049 pages4 2020 Big Data Analytics For Cyber-Physical System in Smart City - 663, 768morteza hosseiniNo ratings yet
- MS ACCESS TutorialDocument94 pagesMS ACCESS TutorialCoke Aidenry SaludoNo ratings yet
- 124-Online Attendance System - SynopsisDocument6 pages124-Online Attendance System - SynopsismcaprojectsNo ratings yet
- 2017 - Improving Link Prediction in Complex Networks by Adaptively Exploiting Multiple Structural Features of NetworksDocument8 pages2017 - Improving Link Prediction in Complex Networks by Adaptively Exploiting Multiple Structural Features of Networksmorteza hosseiniNo ratings yet
- 2013 - Data Construction For Phosphorylation Site PredictionDocument17 pages2013 - Data Construction For Phosphorylation Site Predictionmorteza hosseiniNo ratings yet
- 2012 - A Novel Sequence-Based Method For Phosphorylation Site Prediction With Feature Selection and AnalysisDocument2 pages2012 - A Novel Sequence-Based Method For Phosphorylation Site Prediction With Feature Selection and Analysismorteza hosseiniNo ratings yet
- 2012 - Prediction of Protein Phosphorylation Sites by Using The Composition of K-Spaced Amino Acid PairsDocument8 pages2012 - Prediction of Protein Phosphorylation Sites by Using The Composition of K-Spaced Amino Acid Pairsmorteza hosseiniNo ratings yet
- Deciphering Kinase-Substrate Relationships by Analysis of Domain-Specific Phosphorylation NetworkDocument9 pagesDeciphering Kinase-Substrate Relationships by Analysis of Domain-Specific Phosphorylation Networkmorteza hosseiniNo ratings yet
- Advances in Knowledge Discovery and Data - Joshua Zhexue Huang - Longbing Cao - JaideDocument583 pagesAdvances in Knowledge Discovery and Data - Joshua Zhexue Huang - Longbing Cao - Jaidemorteza hosseiniNo ratings yet
- A Novel Method For Predicting Post-Translational Modifications On Serine and Threonine Sites by Using Site-Modification Network ProfilesDocument10 pagesA Novel Method For Predicting Post-Translational Modifications On Serine and Threonine Sites by Using Site-Modification Network Profilesmorteza hosseiniNo ratings yet
- Reputation-Based Worker Filtering in CrowdsourcingDocument9 pagesReputation-Based Worker Filtering in Crowdsourcingmorteza hosseiniNo ratings yet
- Spectral Methods Meet EM A Provably Optimal Algorithm For CrowdsourcingDocument9 pagesSpectral Methods Meet EM A Provably Optimal Algorithm For Crowdsourcingmorteza hosseiniNo ratings yet
- Iterative Learning For Reliable Crowdsourcing SystemsDocument10 pagesIterative Learning For Reliable Crowdsourcing Systemsmorteza hosseiniNo ratings yet
- CrowdSourcing For NLPDocument71 pagesCrowdSourcing For NLPmorteza hosseiniNo ratings yet
- Comparison of The PAM and BLOSUM Amino Acid Substitution MatricesDocument4 pagesComparison of The PAM and BLOSUM Amino Acid Substitution Matricesmorteza hosseiniNo ratings yet
- Byte, Kilobyte, Megabyte, GigabyteDocument3 pagesByte, Kilobyte, Megabyte, Gigabytesan nicolasNo ratings yet
- BCT - GRP 07 - 007,014,027,034,047,054,067,075Document11 pagesBCT - GRP 07 - 007,014,027,034,047,054,067,075Pranay BhandariNo ratings yet
- Google UX Design Certificate - Competitive Audit Report (Template)Document3 pagesGoogle UX Design Certificate - Competitive Audit Report (Template)Saumya VermaNo ratings yet
- Nning From Internal Flash PDFDocument45 pagesNning From Internal Flash PDFChu Minh ThắngNo ratings yet
- Equivalence Partitioning A Technique Under Black Box ApproachDocument11 pagesEquivalence Partitioning A Technique Under Black Box ApproachKSul2012No ratings yet
- Lab Manual Experiment 7Document6 pagesLab Manual Experiment 7Aman KumarNo ratings yet
- Gantt Chart For Seed Sow Machine: OperationDocument7 pagesGantt Chart For Seed Sow Machine: Operationvidyadhar GNo ratings yet
- Far Cry Config CheatDocument4 pagesFar Cry Config CheatCarlos Islas GNo ratings yet
- Esp32 Wroom 32dDocument24 pagesEsp32 Wroom 32dRazwan ali saeedNo ratings yet
- Aci 304.2R-96Document28 pagesAci 304.2R-96Eka SethianaNo ratings yet
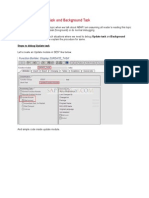
- Debugging Update Task and Background TaskDocument11 pagesDebugging Update Task and Background TaskEmilSNo ratings yet
- HWT-M2121-10-EI (8-32mm) : FeaturesDocument5 pagesHWT-M2121-10-EI (8-32mm) : FeaturesLeandro GomesNo ratings yet
- 001 List of Acrm JUNE 2012Document55 pages001 List of Acrm JUNE 2012AraNo ratings yet
- Transforming To A Cisco Intent Based Network IbntrnDocument4 pagesTransforming To A Cisco Intent Based Network IbntrnHaithamNo ratings yet
- DAA Unit1Document139 pagesDAA Unit1Wondwesen FelekeNo ratings yet
- Assignment 6 Study of Triggers - 181021004Document14 pagesAssignment 6 Study of Triggers - 181021004Shivpriya AmaleNo ratings yet
- Chapter 09 Profibus PLC ProgDocument12 pagesChapter 09 Profibus PLC ProgHammad RehmanNo ratings yet
- AGe of Empires ReadmeDocument1 pageAGe of Empires ReadmeRenzo Paolo QuintanillaNo ratings yet
- Big Data PgdcaDocument23 pagesBig Data PgdcarahulNo ratings yet
- Towel Day 2010 - UI Council Update - Terho NiemiDocument9 pagesTowel Day 2010 - UI Council Update - Terho NiemiroelofdkNo ratings yet
- Remote Access in Tally ERP 9Document16 pagesRemote Access in Tally ERP 9Brijesh KumarNo ratings yet
- Lec11 EEE13 2s1617Document42 pagesLec11 EEE13 2s1617Nikko Angelo Dela RosaNo ratings yet
- Equipment Maintenance Scheduler (EMS)Document11 pagesEquipment Maintenance Scheduler (EMS)Soro FoxNo ratings yet
- MEMORIA r5f21257sn Familia R8C25Document525 pagesMEMORIA r5f21257sn Familia R8C25Cesar GastaldiNo ratings yet
- Our Website Uses Fluid Grids: Thoroughly Decently PoorlyDocument2 pagesOur Website Uses Fluid Grids: Thoroughly Decently Poorlysantosh kumarNo ratings yet
- 2 Uml For Ooad: 2.1 What Is UML? 2.2 Classes in UML 2.3 Relations in UML 2.4 Static and Dynamic Design With UMLDocument33 pages2 Uml For Ooad: 2.1 What Is UML? 2.2 Classes in UML 2.3 Relations in UML 2.4 Static and Dynamic Design With UMLthehtNo ratings yet