You might also like
- R Programming SlidesDocument73 pagesR Programming SlidesYan Jun HoNo ratings yet
- R Lecture#2Document56 pagesR Lecture#2Muhammad HamdanNo ratings yet
- Analitical ReseachDocument15 pagesAnalitical Reseachemir taşçıNo ratings yet
- PCA Explained: A Guide to Principal Component AnalysisDocument22 pagesPCA Explained: A Guide to Principal Component AnalysisVALMICK GUHANo ratings yet
- Sort Pandas DataFrameDocument37 pagesSort Pandas DataFrameB. Jennifer100% (1)
- Fds AnswersDocument53 pagesFds AnswerssaranyatvcetNo ratings yet
- R ProgDocument27 pagesR ProgSrinivasan KrishnanNo ratings yet
- CS229 Section: Python Tutorial: Maya SrikanthDocument39 pagesCS229 Section: Python Tutorial: Maya SrikanthTrần Thành LongNo ratings yet
- 1 IP 12 NOTES PythonPandas 2022 PDFDocument66 pages1 IP 12 NOTES PythonPandas 2022 PDFKrrish Kumar100% (3)
- B22CS014 ReportDocument11 pagesB22CS014 Reportb22cs014No ratings yet
- Statistics - A.Y. 2018-2019: BIEF - Class 22Document22 pagesStatistics - A.Y. 2018-2019: BIEF - Class 22emaNo ratings yet
- 3rd UnitDocument75 pages3rd UnitDharma Teja Sunkara100% (1)
- NumPy BasicsDocument23 pagesNumPy BasicsRohith VKaNo ratings yet
- EDA Lab ManualDocument93 pagesEDA Lab ManualYash Rox100% (2)
- Data Mining Schemas and Clustering TechniquesDocument22 pagesData Mining Schemas and Clustering TechniquesNIRAV SHAHNo ratings yet
- 832ec6c0 1602239712292Document46 pages832ec6c0 1602239712292Sandeep SinghNo ratings yet
- 1 - Introduction To Programming With RDocument13 pages1 - Introduction To Programming With Rpaseg78960No ratings yet
- MY R REPORTDocument52 pagesMY R REPORTFaguni guhaNo ratings yet
- CS229 Python & Numpy: Jingbo Yang, Zhihan XiongDocument40 pagesCS229 Python & Numpy: Jingbo Yang, Zhihan Xiongsid s100% (1)
- DAV PracticalsDocument26 pagesDAV Practicals108 AnirbanNo ratings yet
- 2 Python Data ProcessingDocument66 pages2 Python Data ProcessingShaifali Jain100% (2)
- Bdo Co1 Session 4Document43 pagesBdo Co1 Session 4s.m.pasha0709No ratings yet
- Python AbstractDocument7 pagesPython AbstractShambhavi BiradarNo ratings yet
- Basic R TutorialDocument56 pagesBasic R TutorialnelsonmbaNo ratings yet
- M2 - FDSDocument20 pagesM2 - FDS1NH20CS182 Rakshith M PNo ratings yet
- Unit 2 MLDocument93 pagesUnit 2 MLSiti Hariksa AmaliaNo ratings yet
- Week 4: 2D Arrays and PlottingDocument25 pagesWeek 4: 2D Arrays and PlottingKaleab TekleNo ratings yet
- R Programming: © 2016 SMART Training Resources Pvt. LTDDocument28 pagesR Programming: © 2016 SMART Training Resources Pvt. LTDSrinivasan KrishnanNo ratings yet
- 2. R Programming 101 Part 1Document53 pages2. R Programming 101 Part 1PavaniPaladuguNo ratings yet
- Is5312 Week10-V2Document51 pagesIs5312 Week10-V2lengbiao111No ratings yet
- Working With NumpyDocument18 pagesWorking With NumpyJay PriyaNo ratings yet
- Data Structure Chapter 2Document37 pagesData Structure Chapter 2affan ashfaqNo ratings yet
- NumPy & PandasDocument27 pagesNumPy & PandasPavan DevaNo ratings yet
- MohitDocument19 pagesMohitAyush GuptaNo ratings yet
- RbasicsDocument96 pagesRbasicsApurva HagawaneNo ratings yet
- Data Structures & Its ApplicationDocument138 pagesData Structures & Its ApplicationPushpeshNo ratings yet
- Data Structures & Its Application-2Document356 pagesData Structures & Its Application-2ankithavv13No ratings yet
- Planar Data Classification With One Hidden Layer v5Document19 pagesPlanar Data Classification With One Hidden Layer v5sn3fruNo ratings yet
- NumpyDocument26 pagesNumpyJames PrakashNo ratings yet
- Introduction To RDocument11 pagesIntroduction To RMaddy IlNo ratings yet
- Empirical Software Engineering (Swe504) : Practical FileDocument27 pagesEmpirical Software Engineering (Swe504) : Practical Fileyankit kumarNo ratings yet
- Introduction To R PDFDocument56 pagesIntroduction To R PDFHarshana SupunNo ratings yet
- Unit 2Document81 pagesUnit 2jai geraNo ratings yet
- Lab 1Document11 pagesLab 1Clark Jan MykleNo ratings yet
- introduction-to-numpy-pandas-and-matplotlibDocument2 pagesintroduction-to-numpy-pandas-and-matplotlibrk73462002No ratings yet
- Hints and AnswersDocument13 pagesHints and Answersashishamitav123No ratings yet
- P03 Confidence RegionDocument7 pagesP03 Confidence RegionYANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- Lectur2 PANDASDocument65 pagesLectur2 PANDAShandotinashe15No ratings yet
- Basic Linear AlgebraDocument18 pagesBasic Linear AlgebraSuraj DhanaweNo ratings yet
- Dplyr Package in R: Alka VaidyaDocument22 pagesDplyr Package in R: Alka VaidyaPrabhat SinghNo ratings yet
- DataFrame StatisticsDocument41 pagesDataFrame Statisticsrohan jhaNo ratings yet
- R Session ADocument107 pagesR Session Adivya kolluriNo ratings yet
- Python LibrariesDocument29 pagesPython LibrariesSubhradeep PalNo ratings yet
- R BasicDocument16 pagesR BasicTaslima ChowdhuryNo ratings yet
- Core Python, NumPy, Pandas and SQL FunctionsDocument7 pagesCore Python, NumPy, Pandas and SQL FunctionsKuldeep GangwarNo ratings yet
- DAV PracticalDocument12 pagesDAV PracticalBHAVYA MALIK 204052No ratings yet
- PrintDocument296 pagesPrintMohammed ZameerNo ratings yet
- What Is A Data Structure?: Data Structures in Data ScienceDocument24 pagesWhat Is A Data Structure?: Data Structures in Data ScienceMeghna ChoudharyNo ratings yet
- Information PracticesDocument141 pagesInformation PracticesajNo ratings yet
- Analog ComparatorDocument11 pagesAnalog ComparatorMohamedAbdelrazekNo ratings yet
- Git & Github Basics: Gamecraft Training Radoslav Georgiev (@rado - G)Document28 pagesGit & Github Basics: Gamecraft Training Radoslav Georgiev (@rado - G)MohamedAbdelrazekNo ratings yet
- Git & Github Basics: Gamecraft Training Radoslav Georgiev (@rado - G)Document28 pagesGit & Github Basics: Gamecraft Training Radoslav Georgiev (@rado - G)MohamedAbdelrazekNo ratings yet
- Git & Github Basics: Gamecraft Training Radoslav Georgiev (@rado - G)Document28 pagesGit & Github Basics: Gamecraft Training Radoslav Georgiev (@rado - G)MohamedAbdelrazekNo ratings yet
- SC0x W3L2 CLEAN PDFDocument31 pagesSC0x W3L2 CLEAN PDFMohamedAbdelrazekNo ratings yet
- SC4x W1L2 CleanDocument45 pagesSC4x W1L2 CleanMohamedAbdelrazekNo ratings yet
- Timeseries v5 UnannotatedDocument22 pagesTimeseries v5 UnannotatedMohamedAbdelrazekNo ratings yet
- EOQExtensions v11 UnannotatedDocument27 pagesEOQExtensions v11 UnannotatedMohamedAbdelrazekNo ratings yet
- Atmega16l8au PDFDocument26 pagesAtmega16l8au PDFNelson AlmeidaNo ratings yet
- Atmega16l8au PDFDocument26 pagesAtmega16l8au PDFNelson AlmeidaNo ratings yet
- Booksstream k33 BookMH61TF PDFDocument180 pagesBooksstream k33 BookMH61TF PDFMohamedAbdelrazekNo ratings yet
- SC0x W3L2 CLEAN PDFDocument31 pagesSC0x W3L2 CLEAN PDFMohamedAbdelrazekNo ratings yet
- "Bobca T ": AMD's New Low Pow Er X 86 Cor e Ar Chit Ect Ur eDocument20 pages"Bobca T ": AMD's New Low Pow Er X 86 Cor e Ar Chit Ect Ur eMohamedAbdelrazekNo ratings yet
- Synchronous Sequential CircuitsDocument3 pagesSynchronous Sequential CircuitsMohamedAbdelrazekNo ratings yet
- Digital 01 AfterDocument13 pagesDigital 01 AfterMohamedAbdelrazekNo ratings yet
- Circle of ConfusionDocument17 pagesCircle of ConfusionArturo Forton CuñaNo ratings yet
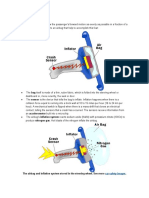
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- Epoxy HRDocument5 pagesEpoxy HRMuthuKumarNo ratings yet
- Ms. Rochelle P. Sulitas – Grade 7 SCIENCE Earth and Space Learning PlanDocument4 pagesMs. Rochelle P. Sulitas – Grade 7 SCIENCE Earth and Space Learning PlanEmelynNo ratings yet
- FLG 212 Study GuideDocument19 pagesFLG 212 Study GuidecynthiaNo ratings yet
- A Critical Review: Constructive Analysis in English and Filipino 1 SEMESTER 2021-2022Document4 pagesA Critical Review: Constructive Analysis in English and Filipino 1 SEMESTER 2021-2022roseNo ratings yet
- Nature and Purpose of CommunicationDocument17 pagesNature and Purpose of CommunicationEdmond Dantès100% (4)
- FND Global and FND Profile PDFDocument4 pagesFND Global and FND Profile PDFSaquib.MahmoodNo ratings yet
- Abbadvant 800 XaDocument9 pagesAbbadvant 800 XaAlexNo ratings yet
- Project On Honda Two WheelersDocument46 pagesProject On Honda Two WheelersC SHIVASANKARNo ratings yet
- Gas Mixtures: Seventh Edition in SI UnitsDocument13 pagesGas Mixtures: Seventh Edition in SI Unitshamed farzanehNo ratings yet
- Book Notes - The Life Changing Magic of Tidying Up PDFDocument6 pagesBook Notes - The Life Changing Magic of Tidying Up PDFAilyn Bagares AñanoNo ratings yet
- FLANSI CAP SONDA CatalogsDocument30 pagesFLANSI CAP SONDA CatalogsTeodor Ioan Ghinet Ghinet DorinaNo ratings yet
- Aruksha ResumeDocument2 pagesAruksha Resumeapi-304262732No ratings yet
- Gender Support Plan PDFDocument4 pagesGender Support Plan PDFGender SpectrumNo ratings yet
- 7 Ways of Looking at Grammar China EditDocument20 pages7 Ways of Looking at Grammar China EditAshraf MousaNo ratings yet
- Tepache Kulit Nanas Sebagai Bahan Campuran Minuman 28 37Document10 pagesTepache Kulit Nanas Sebagai Bahan Campuran Minuman 28 37nabila sukmaNo ratings yet
- Basic of Seismic RefractionDocument43 pagesBasic of Seismic Refractionfitriah wulandariNo ratings yet
- Ebooks vs Traditional Books: An AnalysisDocument10 pagesEbooks vs Traditional Books: An AnalysisLOVENo ratings yet
- Annual Reading Plan - Designed by Pavan BhattadDocument12 pagesAnnual Reading Plan - Designed by Pavan BhattadFarhan PatelNo ratings yet
- Course 4Document3 pagesCourse 4Ibrahim SalahudinNo ratings yet
- Kak MhamadDocument1 pageKak MhamadAyub Anwar M-SalihNo ratings yet
- Chapter Three 3.0 Research MethodologyDocument5 pagesChapter Three 3.0 Research MethodologyBoyi EnebinelsonNo ratings yet
- Beef & Dairy 2016Document36 pagesBeef & Dairy 2016The Standard NewspaperNo ratings yet
- TaxonomyDocument56 pagesTaxonomyKrezia Mae SolomonNo ratings yet
- DMG48480F021 01WN DataSheetDocument16 pagesDMG48480F021 01WN DataSheeteminkiranNo ratings yet
- Wave Optics - I: Created by C. Mani, Principal, K V No.1, AFS, Jalahalli West, BangaloreDocument16 pagesWave Optics - I: Created by C. Mani, Principal, K V No.1, AFS, Jalahalli West, BangaloreNitesh Gupta100% (1)
- 2010 - Caliber JEEP BOITE T355Document484 pages2010 - Caliber JEEP BOITE T355thierry.fifieldoutlook.comNo ratings yet
- Decision Flow Chart: For Suspicious PackagesDocument2 pagesDecision Flow Chart: For Suspicious PackagesHervian LanangNo ratings yet
- Raoult's law and colligative propertiesDocument27 pagesRaoult's law and colligative propertiesGøbindNo ratings yet