You might also like
- Lab 5 Work and Energy On Air Track PDFDocument27 pagesLab 5 Work and Energy On Air Track PDFMuhammad Usman Malik100% (1)
- Probability, Statistics, and Queueing TheoryFrom EverandProbability, Statistics, and Queueing TheoryRating: 5 out of 5 stars5/5 (1)
- FORECASTINGDocument37 pagesFORECASTINGRegina Jazzmim QuezadaNo ratings yet
- Assignment IC104Document7 pagesAssignment IC104Zeon tvNo ratings yet
- Case Study Assignment 2Document8 pagesCase Study Assignment 2Dang HuynhNo ratings yet
- MKF Tool HelpDocument6 pagesMKF Tool HelpRob GoetzNo ratings yet
- French Legal SystemDocument3 pagesFrench Legal SystemGauravChoudharyNo ratings yet
- Khutbah About The QuranDocument3 pagesKhutbah About The QurantakwaniaNo ratings yet
- Assignment Module 1Document30 pagesAssignment Module 1Priyanka SindhwaniNo ratings yet
- 1997 Gioncu & Petcu - Available Rotation Capacity of Wide-Flange Beams and Beam-Columns Part 2. Experimental and Numerical TestsDocument26 pages1997 Gioncu & Petcu - Available Rotation Capacity of Wide-Flange Beams and Beam-Columns Part 2. Experimental and Numerical TestsAKNo ratings yet
- Experiment: Forces in Plane Redundant TrussDocument8 pagesExperiment: Forces in Plane Redundant TrussEdmund TiewNo ratings yet
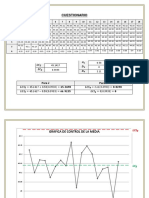
- Práctica Metrología No. 5 Gráficas de Control CuestionarioDocument3 pagesPráctica Metrología No. 5 Gráficas de Control CuestionarioReyna Escudero OctavioNo ratings yet
- Seven QC Tool and MoreDocument83 pagesSeven QC Tool and MorewllohNo ratings yet
- Lab Report Thermodynamics 222037530Document15 pagesLab Report Thermodynamics 222037530ndumisoNo ratings yet
- Oxidative Score For Prognosis in PT Operable Breast CADocument14 pagesOxidative Score For Prognosis in PT Operable Breast CANurul Fatimah MaulaNo ratings yet
- Worksheet 4Document7 pagesWorksheet 4Nona NanoNo ratings yet
- Rigidity Modulous-1Document5 pagesRigidity Modulous-1Md Tazrian TanasNo ratings yet
- Jordan University of Science Technology & Mechanical Engineering DepartmentDocument12 pagesJordan University of Science Technology & Mechanical Engineering Departmentبشير النعيمNo ratings yet
- Ass No 4Document10 pagesAss No 4Muhammad Bilal MakhdoomNo ratings yet
- Pressure Distribution Over A Circular Cylinder PDFDocument11 pagesPressure Distribution Over A Circular Cylinder PDFShiv MauryaNo ratings yet
- Measure of AssociationDocument5 pagesMeasure of AssociationAbha goyalNo ratings yet
- Given Problem:: Chart TitleDocument2 pagesGiven Problem:: Chart TitleRhea AgulayNo ratings yet
- PCP-Disso-v3: % Release (Average With Flux) )Document36 pagesPCP-Disso-v3: % Release (Average With Flux) )amitkhobragade100% (2)
- Exp 3 PhysDocument13 pagesExp 3 PhysAli Issa OthmanNo ratings yet
- Hilda Noor Farikha - 7101418106 UTS EkometDocument8 pagesHilda Noor Farikha - 7101418106 UTS EkometDhyz channelNo ratings yet
- Meanif differences μ of terms Number of terms μ= 7+18+14+9+11+2+3+7 μ= 71Document30 pagesMeanif differences μ of terms Number of terms μ= 7+18+14+9+11+2+3+7 μ= 71Hetvi PatelNo ratings yet
- QTBDocument7 pagesQTBUmarNo ratings yet
- Acknowledgement For Summer Internship Project ReportDocument23 pagesAcknowledgement For Summer Internship Project ReportBadisa NaveenNo ratings yet
- 8102 Assignment 2 - Probability DistributionDocument1 page8102 Assignment 2 - Probability DistributiontNo ratings yet
- NSGA and Optimization DocumentDocument6 pagesNSGA and Optimization DocumentAnutthara RatnayakeNo ratings yet
- SalesforecastingDocument7 pagesSalesforecastingaayush yadavNo ratings yet
- RSM Case StudyDocument12 pagesRSM Case StudyVbaluyoNo ratings yet
- Spss Problem SolveDocument107 pagesSpss Problem SolvePalashNo ratings yet
- H 0,2m H 0,4m H 0,5m H (M) T(S) H (M) T(S) H (M) T(S) : Tabla 1Document3 pagesH 0,2m H 0,4m H 0,5m H (M) T(S) H (M) T(S) H (M) T(S) : Tabla 1Cindy Juranny Duque VanegasNo ratings yet
- This Study Resource WasDocument6 pagesThis Study Resource WasKimberly Claire AtienzaNo ratings yet
- Metode Validasi ScreeningDocument24 pagesMetode Validasi ScreeningIqbalInsaniNo ratings yet
- Scientific Paper Template.Document5 pagesScientific Paper Template.Matthew TabanaoNo ratings yet
- Binary Liquid-Vapor Phase DiagramDocument3 pagesBinary Liquid-Vapor Phase DiagramLuluaNo ratings yet
- Slovak University of Agriculture in Nitra Faculty of Economics and ManagementDocument8 pagesSlovak University of Agriculture in Nitra Faculty of Economics and ManagementdimaNo ratings yet
- Decision Science..Document6 pagesDecision Science..Hrithik GollarNo ratings yet
- LDR 640 Ind SPC Assignment 6Document5 pagesLDR 640 Ind SPC Assignment 6api-555112923No ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Exercise-No.-3 (ZANORIA, STEPHANIE)Document4 pagesExercise-No.-3 (ZANORIA, STEPHANIE)stephanie zanoriaNo ratings yet
- P15 - 178380 - Eviews GuideDocument7 pagesP15 - 178380 - Eviews Guidebobhamilton3489No ratings yet
- Homework 3 2Document7 pagesHomework 3 2Ishwar MahajanNo ratings yet
- Experiment: 2: ObjectiveDocument8 pagesExperiment: 2: ObjectiveRick JhonathonNo ratings yet
- Lampiran Size Reduction FixDocument6 pagesLampiran Size Reduction FixHabib Faisal YahyaNo ratings yet
- FN GRP 4.2 Assignment No 5Document7 pagesFN GRP 4.2 Assignment No 5Darshan sakleNo ratings yet
- Medios Semi-InfinitosDocument2 pagesMedios Semi-InfinitosLuis Enrique Sanchez Mercado :DNo ratings yet
- HW 2Document4 pagesHW 2الحمزه حبيبNo ratings yet
- Hasil Uji Eviwes 12&9Document6 pagesHasil Uji Eviwes 12&9Vivi KrisdayantiNo ratings yet
- Vapor Liquid Equilibrium and Raoults Law Solved ProblemsDocument23 pagesVapor Liquid Equilibrium and Raoults Law Solved ProblemsGenius media networkNo ratings yet
- Hypothesis Tests - Excel WorkbookDocument12 pagesHypothesis Tests - Excel WorkbookannieNo ratings yet
- Lampiran Jadi IniDocument9 pagesLampiran Jadi Inimonica zulqaNo ratings yet
- 08 Unit 4 Consolidation 3Document20 pages08 Unit 4 Consolidation 3Chun YenNo ratings yet
- Generic TST Protocol Distributed Annexes KNCVDocument14 pagesGeneric TST Protocol Distributed Annexes KNCVtheresiaNo ratings yet
- Case AnalysisDocument10 pagesCase AnalysisSami Un BashirNo ratings yet
- Am ActivityDocument12 pagesAm ActivityGrace CaritNo ratings yet
- End-Term ExaminationDocument4 pagesEnd-Term ExaminationABHISHEK BNo ratings yet
- Nama: Ersa Kusumawardani NPM: 0115103003/reg B2/C Mata Kuliah: Statistik Multivariat Tugas Eviews 1Document9 pagesNama: Ersa Kusumawardani NPM: 0115103003/reg B2/C Mata Kuliah: Statistik Multivariat Tugas Eviews 1ersa kusumawardaniNo ratings yet
- Fluid Mechanics Project Search and ExperDocument26 pagesFluid Mechanics Project Search and ExperMithileshNo ratings yet
- Principles and Applications of Thermal AnalysisFrom EverandPrinciples and Applications of Thermal AnalysisPaul GabbottRating: 4 out of 5 stars4/5 (1)
- A Unified Approach to the Finite Element Method and Error Analysis ProceduresFrom EverandA Unified Approach to the Finite Element Method and Error Analysis ProceduresNo ratings yet
- Assignment 3: Research Reflection PaperDocument9 pagesAssignment 3: Research Reflection PaperDang HuynhNo ratings yet
- (Phase 2.2) (Submission) Team The ChasersDocument15 pages(Phase 2.2) (Submission) Team The ChasersDang HuynhNo ratings yet
- Scmission 2021: Round 2.1 - Inventory Management Business CaseDocument9 pagesScmission 2021: Round 2.1 - Inventory Management Business CaseDang HuynhNo ratings yet
- Summary of All Sequences For 4MS 2021Document8 pagesSummary of All Sequences For 4MS 2021rohanZorba100% (3)
- Final For Influence of OJTDocument39 pagesFinal For Influence of OJTAnthony B. AnocheNo ratings yet
- Speech VP SaraDocument2 pagesSpeech VP SaraStephanie Dawn MagallanesNo ratings yet
- Communist Party of India - WikipediaDocument104 pagesCommunist Party of India - WikipediaRameshwar ChandravanshiNo ratings yet
- The 5 Basic Sentence PatternsDocument6 pagesThe 5 Basic Sentence PatternsShuoNo ratings yet
- Chapter 7: Identifying and Understanding ConsumersDocument3 pagesChapter 7: Identifying and Understanding ConsumersDyla RafarNo ratings yet
- Analysis of Effectiveness of Heat Exchanger Shell and Tube Type One Shell Two Tube Pass As Cooling OilDocument6 pagesAnalysis of Effectiveness of Heat Exchanger Shell and Tube Type One Shell Two Tube Pass As Cooling OilHendrik V SihombingNo ratings yet
- Beginner Levels of EnglishDocument4 pagesBeginner Levels of EnglishEduardoDiazNo ratings yet
- Click Here For Download: (PDF) HerDocument2 pagesClick Here For Download: (PDF) HerJerahm Flancia0% (1)
- Foreign Policy During Mahathir EraDocument7 pagesForeign Policy During Mahathir EraMuhamad Efendy Jamhar0% (1)
- Selfishness EssayDocument8 pagesSelfishness Essayuiconvbaf100% (2)
- 11v.jigisha Chaptear2Document53 pages11v.jigisha Chaptear2Anirban PalNo ratings yet
- Ra 9048 Implementing RulesDocument9 pagesRa 9048 Implementing RulesToffeeNo ratings yet
- Kuo SzuYu 2014 PHD ThesisDocument261 pagesKuo SzuYu 2014 PHD ThesiskatandeNo ratings yet
- PG 19 - 20 GROUP 5Document2 pagesPG 19 - 20 GROUP 5Kevin Luis Pacheco ZarateNo ratings yet
- Clayton Parks and Recreation: Youth Soccer Coaching ManualDocument19 pagesClayton Parks and Recreation: Youth Soccer Coaching ManualFranklin Justniano VacaNo ratings yet
- Exercise and Ppismp StudentsDocument6 pagesExercise and Ppismp StudentsLiyana RoseNo ratings yet
- MCDP4, LogisticsDocument127 pagesMCDP4, Logisticsjayemcee2100% (2)
- Perception On The Impact of New Learning Tools in Humss StudentDocument6 pagesPerception On The Impact of New Learning Tools in Humss StudentElyza Marielle BiasonNo ratings yet
- Chryso CI 550Document2 pagesChryso CI 550Flavio Jose MuhaleNo ratings yet
- 2013 03 01 Maurizio Di Noia PresentationDocument80 pages2013 03 01 Maurizio Di Noia PresentationRene KotzeNo ratings yet
- G.R. No. 205307 PEOPLE Vs EDUARDO GOLIDAN y COTO-ONGDocument24 pagesG.R. No. 205307 PEOPLE Vs EDUARDO GOLIDAN y COTO-ONGRuel FernandezNo ratings yet
- Failure of Composite Materials PDFDocument2 pagesFailure of Composite Materials PDFPatrickNo ratings yet
- SakalDocument33 pagesSakalKaran AsnaniNo ratings yet
- FS 1 Activity 3.3Document6 pagesFS 1 Activity 3.3HYACINTH GALLENERONo ratings yet
- Upload Emp Photo ConfigDocument14 pagesUpload Emp Photo Configpaulantony143No ratings yet
- Accounting Volume 1 Canadian 8th Edition Horngren Solutions ManualDocument25 pagesAccounting Volume 1 Canadian 8th Edition Horngren Solutions ManualElizabethBautistadazi100% (43)