You might also like
- cs229 Notes EnsembleDocument7 pagescs229 Notes EnsemblebobNo ratings yet
- Expo Norm Dist 4 FDocument21 pagesExpo Norm Dist 4 FDevil GamerNo ratings yet
- Chap 5Document35 pagesChap 5Maurice PolitisNo ratings yet
- Normal Statistics EstimationDocument8 pagesNormal Statistics EstimationIonuț Cătălin SanduNo ratings yet
- SI2018Document32 pagesSI2018m garivani75No ratings yet
- Prediction vs Forecasting Fuzzy vs ProbabilityDocument15 pagesPrediction vs Forecasting Fuzzy vs ProbabilityRajesh kumarNo ratings yet
- Unit 4 - Continuous Random VariablesDocument35 pagesUnit 4 - Continuous Random VariablesShouq AbdullahNo ratings yet
- Slides Iiml Pgp1 Qam1 Continuous Random VariablesDocument18 pagesSlides Iiml Pgp1 Qam1 Continuous Random VariablesAnuj PrajapatiNo ratings yet
- Rearranging Truth Tables for Boolean ExpressionsDocument14 pagesRearranging Truth Tables for Boolean ExpressionsChandra Kishore PaulNo ratings yet
- 1 Random Walks and Data: 1.1 Serial CorrelationDocument9 pages1 Random Walks and Data: 1.1 Serial CorrelationVeeken ChaglassianNo ratings yet
- What Is The Error ? How It Is Happened ?Document24 pagesWhat Is The Error ? How It Is Happened ?Jose D CostaNo ratings yet
- 07au MidtermDocument17 pages07au MidtermEman AsemNo ratings yet
- Bisection MethodDocument7 pagesBisection MethodKauser AhmedNo ratings yet
- MATE2A2 Introduction Fourier SeriesDocument16 pagesMATE2A2 Introduction Fourier Seriesportia733hhNo ratings yet
- LineIntegrals PDFDocument11 pagesLineIntegrals PDFJia ToorNo ratings yet
- Example 3.2: Given Probability DistributionDocument38 pagesExample 3.2: Given Probability Distributionloc1409No ratings yet
- Gam TheoryDocument24 pagesGam Theorycan dagidirNo ratings yet
- chapter1bDocument35 pageschapter1bemilyNo ratings yet
- hw01 Linear System ControlsDocument5 pageshw01 Linear System ControlsAnselm AdrianNo ratings yet
- Midterm 2019 SolDocument5 pagesMidterm 2019 Solsaadsebti01No ratings yet
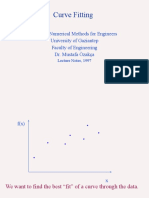
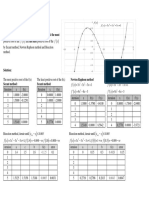
- Curve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaDocument171 pagesCurve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaAbdullah Emirhan AydınNo ratings yet
- Lecture 3 PDFDocument66 pagesLecture 3 PDFHà Anh Minh LêNo ratings yet
- Numerical Solutions of Non-Linear EquationsDocument35 pagesNumerical Solutions of Non-Linear EquationsJatinder KumarNo ratings yet
- CS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text DataDocument35 pagesCS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text Dataankit devNo ratings yet
- Normal DistributionDocument36 pagesNormal DistributionRajesh JayachandranNo ratings yet
- Approximating Functions with Tangent LinesDocument6 pagesApproximating Functions with Tangent LinesSohan MangarNo ratings yet
- Special Continuous Probability Distributions - Exponential Distribution - Weibull DistributionDocument24 pagesSpecial Continuous Probability Distributions - Exponential Distribution - Weibull DistributionPrashant SinghNo ratings yet
- Intoduction To MATLABDocument32 pagesIntoduction To MATLABDania KhattakNo ratings yet
- Chap 004Document33 pagesChap 004Evan AdrielNo ratings yet
- Chap004 - Sao ChépDocument49 pagesChap004 - Sao ChépLan PhanNo ratings yet
- Tutorial Chapter 2Document2 pagesTutorial Chapter 2noraNo ratings yet
- 6.867 Machine Learning: Mid-Term Exam October 13, 2004Document11 pages6.867 Machine Learning: Mid-Term Exam October 13, 2004Dickson SamwelNo ratings yet
- Massachusetts Institute of TechnologyDocument3 pagesMassachusetts Institute of TechnologyJohnNo ratings yet
- ApplicationsDocument84 pagesApplicationsvenkata rajuNo ratings yet
- Machine learning: Obtaining non-linear predictors using linear modelsDocument22 pagesMachine learning: Obtaining non-linear predictors using linear modelsArdiansyah Mochamad NugrahaNo ratings yet
- Lec 05 RegularizationDocument77 pagesLec 05 RegularizationMr. CoffeeNo ratings yet
- chat_openai_com_share_42b24a73_839b_4128_ade9_7d8eed9e9533Document21 pageschat_openai_com_share_42b24a73_839b_4128_ade9_7d8eed9e9533NadhiyaNo ratings yet
- Random Variable and Distribution of ProbabilityDocument54 pagesRandom Variable and Distribution of ProbabilityNatalia OronNo ratings yet
- Finite Element Primer for Solving Diffusion ProblemsDocument26 pagesFinite Element Primer for Solving Diffusion Problemsted_kordNo ratings yet
- SRDS Lecture 2 Probability DistributionsDocument35 pagesSRDS Lecture 2 Probability Distributionsprraaddeej chatelNo ratings yet
- Calculus and Differential Equations Problem Solving Task AnalysisDocument21 pagesCalculus and Differential Equations Problem Solving Task AnalysisAlex WarnerNo ratings yet
- Linear Systems: Prof. Dr. João Edgar Chaves Filho Mestrado em Eng. ElétricaDocument55 pagesLinear Systems: Prof. Dr. João Edgar Chaves Filho Mestrado em Eng. ElétricaAlipio CarvalhoNo ratings yet
- CHAPTER 7Document55 pagesCHAPTER 7mintuwondeNo ratings yet
- CS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationDocument9 pagesCS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationEman JaffriNo ratings yet
- Ma 8 Week 5 Summary Mean Value Theorem and Midterm ReviewDocument10 pagesMa 8 Week 5 Summary Mean Value Theorem and Midterm ReviewkankirajeshNo ratings yet
- MATLAB worksheet for unit root plotsDocument17 pagesMATLAB worksheet for unit root plotsAshish KatochNo ratings yet
- Newton Raphson MethodDocument16 pagesNewton Raphson MethodMinh Duy LêNo ratings yet
- NMC Handout - 3Document17 pagesNMC Handout - 3NIKHIL NIKHINo ratings yet
- Advanced Structural AnalysisDocument13 pagesAdvanced Structural AnalysisBilly JimenezNo ratings yet
- Linear Law (Worksheet 1)Document3 pagesLinear Law (Worksheet 1)deqonnesNo ratings yet
- An Introduction To Extreme Order Statistics and Actuarial ApplicationsDocument54 pagesAn Introduction To Extreme Order Statistics and Actuarial ApplicationsĐặng Minh TháiNo ratings yet
- Final 2006Document15 pagesFinal 2006Muhammad MurtazaNo ratings yet
- Ps 3Document15 pagesPs 3Bui Minh DucNo ratings yet
- Lecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022Document22 pagesLecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022rohit kumarNo ratings yet
- Block 3 2Document121 pagesBlock 3 2JaheerNo ratings yet
- Unit 1 Differential Calculus: StructureDocument35 pagesUnit 1 Differential Calculus: StructureThe FZ25 BoyNo ratings yet
- Normal Distribution With Solved ExamplesDocument70 pagesNormal Distribution With Solved ExamplesVtx MusicNo ratings yet
- Handout1a MATLAB TutorialDocument32 pagesHandout1a MATLAB TutorialHan hoNo ratings yet
- Eigen Value Detection For Spectrum Sensing inDocument5 pagesEigen Value Detection For Spectrum Sensing inhariNo ratings yet
- MITRES 6 007S11 hw10 SolDocument11 pagesMITRES 6 007S11 hw10 SolhariNo ratings yet
- PrintDocument1 pagePrinthariNo ratings yet
- Intercom System Services RFQ Final PDFDocument65 pagesIntercom System Services RFQ Final PDFhariNo ratings yet
- How To Interface LED With 8086 Lab Trainer KitDocument1 pageHow To Interface LED With 8086 Lab Trainer KithariNo ratings yet
- EmfDocument5 pagesEmfhariNo ratings yet
- 8086 MICROPROCESSOR LAB MANUALDocument14 pages8086 MICROPROCESSOR LAB MANUALhariNo ratings yet
- RL 2Document2 pagesRL 2hariNo ratings yet
- AssignmentDocument7 pagesAssignmenthari100% (1)
- ECS 50 8086 Instruction Set Opcodes Operation Operands OpcodeDocument2 pagesECS 50 8086 Instruction Set Opcodes Operation Operands OpcodehariNo ratings yet
- Ordinance 1Document7 pagesOrdinance 1hariNo ratings yet
- Digital Signal Processing Lab ManualDocument171 pagesDigital Signal Processing Lab ManualRaj Kumar ChowdaryNo ratings yet
- M Hari - Paper On ImageDocument6 pagesM Hari - Paper On ImagehariNo ratings yet
- SS IiDocument53 pagesSS IihariNo ratings yet
- Lecture1 PDFDocument4 pagesLecture1 PDFhariNo ratings yet
- NotesDocument37 pagesNoteshariNo ratings yet
- Mci Quiz 2016Document2 pagesMci Quiz 2016hariNo ratings yet
- MPMC ManualDocument93 pagesMPMC ManualsravyaNo ratings yet
- Mci Chapter 2Document10 pagesMci Chapter 2hariNo ratings yet
- MCI Course OutlineDocument9 pagesMCI Course OutlinehariNo ratings yet
- Key Words: Arduino Uno, Induction MotorDocument49 pagesKey Words: Arduino Uno, Induction Motorhari100% (1)
- Chapter 3Document19 pagesChapter 3hariNo ratings yet
- MCI Chapter 1Document6 pagesMCI Chapter 1hariNo ratings yet
- Chapter 1Document6 pagesChapter 1hariNo ratings yet
- Mosfet Small SignalDocument7 pagesMosfet Small SignalTabraizShahNo ratings yet
- NotesDocument37 pagesNoteshariNo ratings yet
- EE101 Measurement Guide to OhmmetersDocument5 pagesEE101 Measurement Guide to OhmmetersIqmal Shah PutraNo ratings yet
- Errors in Measurement Theory and Statistical AnalysisDocument19 pagesErrors in Measurement Theory and Statistical AnalysishariNo ratings yet
- Measurements and Sources of Errors1Document32 pagesMeasurements and Sources of Errors1hariNo ratings yet
- HashingDocument29 pagesHashingaaryan jainNo ratings yet
- Kon407E - State Space Methods in Control Systems Homework # 3Document2 pagesKon407E - State Space Methods in Control Systems Homework # 3T KaripNo ratings yet
- NA Ch5 StudentDocument83 pagesNA Ch5 StudentAhiduzzaman AhirNo ratings yet
- Analog-to-Digital Converter (ADC)Document59 pagesAnalog-to-Digital Converter (ADC)gkkishorekumarNo ratings yet
- Edge-Picking AlgorithmDocument31 pagesEdge-Picking AlgorithmJoy Agustin67% (3)
- Audio WatermarkingDocument19 pagesAudio WatermarkingEr. Amar KumarNo ratings yet
- DE-GAN A Conditional Generative Adversarial PDFDocument12 pagesDE-GAN A Conditional Generative Adversarial PDFbroNo ratings yet
- Lecture Note 1 CE605A&CHE705BDocument5 pagesLecture Note 1 CE605A&CHE705BSamrat RouthNo ratings yet
- Interior PointDocument213 pagesInterior PointAnonymous XKlkx7cr2INo ratings yet
- Solution Manual For Introduction To Geographic Information Systems 9th Edition Kang Tsung ChangDocument4 pagesSolution Manual For Introduction To Geographic Information Systems 9th Edition Kang Tsung ChangDanielPattersonqdgb100% (42)
- Chapter 5Document10 pagesChapter 5warenda mikesNo ratings yet
- Restoring DivisionDocument5 pagesRestoring DivisionAsha DurafeNo ratings yet
- CGIP Lab-FileDocument31 pagesCGIP Lab-FileRahul KumarNo ratings yet
- Deep Learning For Signal ProcessingDocument19 pagesDeep Learning For Signal ProcessingRodrigo Esteban Alva BañuelosNo ratings yet
- Code No: 45015Document7 pagesCode No: 45015SRINIVASA RAO GANTA0% (1)
- Matlab method for speech signal silence removal and segmentationDocument3 pagesMatlab method for speech signal silence removal and segmentationJulsNo ratings yet
- Table (With Non Integer Solution) Given BelowDocument2 pagesTable (With Non Integer Solution) Given BelowJaleel ChennaiNo ratings yet
- Lecture Notes For Chapter 9 Introduction To Data Mining: by Tan, Steinbach, KumarDocument38 pagesLecture Notes For Chapter 9 Introduction To Data Mining: by Tan, Steinbach, KumarAbu KafshaNo ratings yet
- Optimization of Rasasm and Sambar Powder Ingredients Using Linear Programming TechniquesDocument1 pageOptimization of Rasasm and Sambar Powder Ingredients Using Linear Programming TechniquesGulshan KumarNo ratings yet
- Signals and Systems.60 Q.PDocument9 pagesSignals and Systems.60 Q.Prubiniravichandran100% (1)
- 5D InterpolationDocument4 pages5D InterpolationkadrawiNo ratings yet
- Exercise 11 - DiscretizationDocument9 pagesExercise 11 - DiscretizationJuan Pablo Arg RdzNo ratings yet
- Introduction To Genetic Algorithms (GA)Document46 pagesIntroduction To Genetic Algorithms (GA)Saksham RawatNo ratings yet
- Greedy Algorithms for Optimization ProblemsDocument39 pagesGreedy Algorithms for Optimization ProblemsHarsh SoniNo ratings yet
- Distance-Based Models and Clustering Algorithms ExplainedDocument19 pagesDistance-Based Models and Clustering Algorithms ExplainedNidhiNo ratings yet
- Taking Derivative by ConvolutionDocument29 pagesTaking Derivative by Convolutionhyfkyhj ;mnk,.No ratings yet
- Design and Simulation of Kalman FiltersDocument10 pagesDesign and Simulation of Kalman Filtersrktiwary256034No ratings yet
- Relaxation Methods for Solving Linear SystemsDocument13 pagesRelaxation Methods for Solving Linear Systemsعبدالرحمن المحماديNo ratings yet
- Bubble sort, insertion sort, merge sort, heap sort, and quick sort explainedDocument3 pagesBubble sort, insertion sort, merge sort, heap sort, and quick sort explainedmalli009No ratings yet
- Linear Equations With 7 UnknownsDocument4 pagesLinear Equations With 7 UnknownsmeguNo ratings yet