You might also like
- Population Growth Prediction Using Machine LearningDocument10 pagesPopulation Growth Prediction Using Machine LearningUddhav ChaliseNo ratings yet
- Prediction of Medical Costs Using Regression Algorithms: A. Lakshmanarao, Chandra Sekhar Koppireddy, G.Vijay KumarDocument7 pagesPrediction of Medical Costs Using Regression Algorithms: A. Lakshmanarao, Chandra Sekhar Koppireddy, G.Vijay KumarGr Ranjere0% (1)
- Análisis de DatosDocument36 pagesAnálisis de DatosrusoNo ratings yet
- Research Paper Multiple Regression AnalysisDocument8 pagesResearch Paper Multiple Regression Analysisc9rz4vrm100% (1)
- Estimation Strategies For The Regression Coefficient Parameter Matrix in Multivariate Multiple RegressionDocument20 pagesEstimation Strategies For The Regression Coefficient Parameter Matrix in Multivariate Multiple RegressionRonaldo SantosNo ratings yet
- Koo Che Mesh Kian 2020Document26 pagesKoo Che Mesh Kian 2020Mahdi KarimiNo ratings yet
- Using Sentiment Analysis and Machine Learning Algorithms To Determine Citizens' PerceptionsDocument6 pagesUsing Sentiment Analysis and Machine Learning Algorithms To Determine Citizens' Perceptionss.bahliNo ratings yet
- Predictive - Modelling - Project - PDF 1Document31 pagesPredictive - Modelling - Project - PDF 1Shiva KumarNo ratings yet
- How To Prepare Data For Predictive AnalysisDocument5 pagesHow To Prepare Data For Predictive AnalysisMahak KathuriaNo ratings yet
- Project 2021Document12 pagesProject 2021Melvin EstolanoNo ratings yet
- Comparison of Imputation Techniques After Classifying The Dataset Using KNN Classifier For The Imputation of Missing DataDocument4 pagesComparison of Imputation Techniques After Classifying The Dataset Using KNN Classifier For The Imputation of Missing DataInternational Journal of computational Engineering research (IJCER)No ratings yet
- BootstrapDocument33 pagesBootstrapRajshree DaulatabadNo ratings yet
- Prediction of Diabetes Using Artificial Neural Networks: A ReviewDocument6 pagesPrediction of Diabetes Using Artificial Neural Networks: A ReviewOumaima El GhafikiNo ratings yet
- Identification of Parameter Correlations For Parameter Estimation in Dynamic Biological ModelsDocument12 pagesIdentification of Parameter Correlations For Parameter Estimation in Dynamic Biological ModelsQuốc Đông VũNo ratings yet
- Dissertation Using Logistic RegressionDocument6 pagesDissertation Using Logistic RegressionBuyCheapPapersSingapore100% (1)
- Predicting job success with machine learningDocument14 pagesPredicting job success with machine learningGurucharan ReddyNo ratings yet
- Thesis Using Multiple RegressionDocument5 pagesThesis Using Multiple Regressionrwzhdtief100% (2)
- Machine Learning Models: by Mayuri BhandariDocument48 pagesMachine Learning Models: by Mayuri BhandarimayuriNo ratings yet
- COSC2753_A1_MCDocument8 pagesCOSC2753_A1_MCHuy NguyenNo ratings yet
- 1 s2.0 S0895435619308753 MainDocument13 pages1 s2.0 S0895435619308753 MainWildan AttariqNo ratings yet
- Img 19116Document3 pagesImg 19116pavithraNo ratings yet
- Thesis With Multiple Regression AnalysisDocument6 pagesThesis With Multiple Regression Analysiszehlobifg100% (2)
- Summer of Science-Final ReportDocument7 pagesSummer of Science-Final ReportManan SharmaNo ratings yet
- Bayesian Multi-Model Linear Regression in JASPDocument30 pagesBayesian Multi-Model Linear Regression in JASPLuis LuengoNo ratings yet
- 2016 Springer HandbookDocument38 pages2016 Springer HandbookssgantayatNo ratings yet
- Unit 3 DSDocument16 pagesUnit 3 DSromeesh jainNo ratings yet
- Model Selection Using Correlation in Comparison With Qq-PlotDocument5 pagesModel Selection Using Correlation in Comparison With Qq-PlotSowmya KoneruNo ratings yet
- Mme 8201-4-Linear Regression ModelsDocument24 pagesMme 8201-4-Linear Regression ModelsJosephat KalanziNo ratings yet
- Medical Insurance Cost Prediction SystemDocument18 pagesMedical Insurance Cost Prediction SystemBrij MaheshwariNo ratings yet
- Solved With ChatGPTDocument3 pagesSolved With ChatGPTMd. Mahbubur RahmanNo ratings yet
- 4823 DsejournalDocument129 pages4823 DsejournalHey BuddyNo ratings yet
- Evaluating A Machine Learning ModelDocument14 pagesEvaluating A Machine Learning ModelJeanNo ratings yet
- Machine Learning Methods Predict Psychology PhenomenaDocument37 pagesMachine Learning Methods Predict Psychology Phenomenaaparna gattimiNo ratings yet
- BRM Unit 4 ExtraDocument10 pagesBRM Unit 4 Extraprem nathNo ratings yet
- Building Better Nurse Scheduling Algorithms Using Statistical Comparison MethodsDocument18 pagesBuilding Better Nurse Scheduling Algorithms Using Statistical Comparison MethodsDavidNo ratings yet
- Dissertation Using Multiple RegressionDocument8 pagesDissertation Using Multiple RegressionWriteMyPapersDiscountCodeCanada100% (2)
- Application of Big Mining On Health Care IndustryDocument6 pagesApplication of Big Mining On Health Care IndustryTanishq BhatiaNo ratings yet
- Machine Learning To Analyze Single-Case Data: A Proof of ConceptDocument18 pagesMachine Learning To Analyze Single-Case Data: A Proof of ConceptSamuel FonsecaNo ratings yet
- Structural Equation Modeling ThesisDocument6 pagesStructural Equation Modeling ThesisOrderPapersOnlineWorcester100% (3)
- Improving Econometric Prediction by Machine Learning: Applied Economics LettersDocument8 pagesImproving Econometric Prediction by Machine Learning: Applied Economics LettersDio TimaNo ratings yet
- Multi-Disease Prediction With Machine LearningDocument7 pagesMulti-Disease Prediction With Machine LearningUmar KhanNo ratings yet
- MAS5302 - I.D.C.M.Premachandra 1.abstract: Case Study (Linear Models) 2020APST24Document5 pagesMAS5302 - I.D.C.M.Premachandra 1.abstract: Case Study (Linear Models) 2020APST24Nuwan ChathurangaNo ratings yet
- The Problem of Overfitting: PerspectiveDocument12 pagesThe Problem of Overfitting: PerspectiveManoj SharmaNo ratings yet
- Final Year ProjectDocument57 pagesFinal Year ProjectMuhammad FaseehNo ratings yet
- Great Learning Predictive modelling projectDocument12 pagesGreat Learning Predictive modelling projectrameshj16708No ratings yet
- DSR Notes 3 To 5Document70 pagesDSR Notes 3 To 5lila puchariNo ratings yet
- C Ovid-19 Forecast - Final Report: Mechanical Engineering 101/221 To Lean Manufacturing Sara Mcmains May 5, 2021Document34 pagesC Ovid-19 Forecast - Final Report: Mechanical Engineering 101/221 To Lean Manufacturing Sara Mcmains May 5, 2021Matthew NelsonNo ratings yet
- CSCI 4525 Project IVDocument139 pagesCSCI 4525 Project IVPRABHUDEV G ENo ratings yet
- Exer8-Indigo-1Document2 pagesExer8-Indigo-1Karl SorianoNo ratings yet
- Machine Learning For Health Services ResearchersDocument8 pagesMachine Learning For Health Services ResearchersFaraz KhanNo ratings yet
- ETRCS-101Document7 pagesETRCS-101Abdul Jalil NiazaiNo ratings yet
- Top 100 Machine Learning Questions With Answers For Interview PDFDocument48 pagesTop 100 Machine Learning Questions With Answers For Interview PDFPiyush Saraf100% (2)
- Thesis Multiple Linear RegressionDocument5 pagesThesis Multiple Linear Regressionlesliesanchezanchorage100% (1)
- Sample Thesis Using Regression AnalysisDocument6 pagesSample Thesis Using Regression Analysisgj4m3b5b100% (2)
- Data Exploration & VisualizationDocument23 pagesData Exploration & Visualizationdivya kolluriNo ratings yet
- Second Progres ReportDocument10 pagesSecond Progres ReportManish RajNo ratings yet
- Patient Sickness Prediction SystemDocument8 pagesPatient Sickness Prediction Systemvkanishka1999No ratings yet
- Survey of Machine Learning Algorithms For COVIDDocument7 pagesSurvey of Machine Learning Algorithms For COVIDwael El-BegearmiNo ratings yet
- Fi LZ Moser 2020Document18 pagesFi LZ Moser 2020Danna Lizeth Cardona HernandezNo ratings yet
- Fallsem2021-22 Eee3999 Eth VL2021220101419 Assessment Rubrics Eee3999 Assessment Rubrics TB1Document5 pagesFallsem2021-22 Eee3999 Eth VL2021220101419 Assessment Rubrics Eee3999 Assessment Rubrics TB1Abhishek RajNo ratings yet
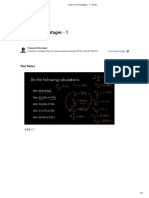
- Class On Percentages - 1 - NotesDocument2 pagesClass On Percentages - 1 - NotesAbhishek RajNo ratings yet
- Class On Carbon and It's Compounds - NotesDocument2 pagesClass On Carbon and It's Compounds - NotesAbhishek RajNo ratings yet
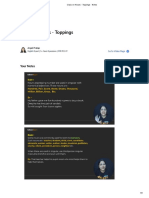
- Class On Nouns - Toppings - NotesDocument3 pagesClass On Nouns - Toppings - NotesAbhishek RajNo ratings yet
- CAPF 2018 ReportsDocument11 pagesCAPF 2018 ReportsAbhishek RajNo ratings yet
- 18BEE0342Document9 pages18BEE0342Abhishek RajNo ratings yet
- EEE3999 Technical Answers For Real World Problems (TARP) Project Description ReportDocument2 pagesEEE3999 Technical Answers For Real World Problems (TARP) Project Description ReportAbhishek RajNo ratings yet
- Eee4028 Vlsi-Design Eth 2.0 39 Eee4028Document3 pagesEee4028 Vlsi-Design Eth 2.0 39 Eee4028Abhishek RajNo ratings yet
- 18BEE0342Document9 pages18BEE0342Abhishek RajNo ratings yet
- Vulnerability AssessmentDocument12 pagesVulnerability AssessmentTabish BeighNo ratings yet
- Towards Technology With A Global Heart Through Compassionate EngineeringDocument5 pagesTowards Technology With A Global Heart Through Compassionate EngineeringAbhishek RajNo ratings yet
- EEE1011-Automated Test Engineering Lab Digital Assignement-2Document4 pagesEEE1011-Automated Test Engineering Lab Digital Assignement-2Kanav BhasinNo ratings yet
- EEE1011-Automated Test Engineering Lab Digital Assignement-2Document4 pagesEEE1011-Automated Test Engineering Lab Digital Assignement-2Kanav BhasinNo ratings yet
- 18BEE0342Document9 pages18BEE0342Abhishek RajNo ratings yet
- Date Gender Incident Type Plant Report Type Injury Location Age Group Days LostDocument24 pagesDate Gender Incident Type Plant Report Type Injury Location Age Group Days LostAbhishek RajNo ratings yet
- Biomedical and Instumentation Project: Review-3Document10 pagesBiomedical and Instumentation Project: Review-3Abhishek RajNo ratings yet
- Untitled DocumentDocument7 pagesUntitled DocumentAbhishek RajNo ratings yet
- Tarp FormDocument2 pagesTarp FormAbhishek RajNo ratings yet
- 18BEE0342Document9 pages18BEE0342Abhishek RajNo ratings yet
- Comprehensive Question PreviewDocument151 pagesComprehensive Question PreviewAbhishek RajNo ratings yet
- ARR - REG - WINTER21 - June2021Document1 pageARR - REG - WINTER21 - June2021Abhishek RajNo ratings yet
- A Sample Filled Form Is Given in The Next Page For Your ReferenceDocument6 pagesA Sample Filled Form Is Given in The Next Page For Your ReferenceAbhishek RajNo ratings yet
- Tarp (18bee0342)Document2 pagesTarp (18bee0342)Abhishek RajNo ratings yet
- Fallsem2021-22 Eee3999 Eth VL2021220101419 Assessment Rubrics Eee3999 Assessment Rubrics TB1Document5 pagesFallsem2021-22 Eee3999 Eth VL2021220101419 Assessment Rubrics Eee3999 Assessment Rubrics TB1Abhishek RajNo ratings yet
- New Doc Jul 15, 2021 16.25Document7 pagesNew Doc Jul 15, 2021 16.25Abhishek RajNo ratings yet
- EXP2: Cluster Test of A Basic Logic Gate (NOT) Using QE-49 Trainer KitDocument1 pageEXP2: Cluster Test of A Basic Logic Gate (NOT) Using QE-49 Trainer KitAbhishek RajNo ratings yet
- Tarp (18bee0342)Document2 pagesTarp (18bee0342)Abhishek RajNo ratings yet
- 18bee0342 VL2019201001033 Da02Document5 pages18bee0342 VL2019201001033 Da02Abhishek RajNo ratings yet
- Eee1004 Engineering-Electromagnetics Eth 1.1 39 Eee1004Document4 pagesEee1004 Engineering-Electromagnetics Eth 1.1 39 Eee1004Abhishek RajNo ratings yet
- Chapter 04: Patient Records, Medication Orders, and Medication Labels Mulholland: The Nurse, The Math, The Meds, 3rd EditionDocument5 pagesChapter 04: Patient Records, Medication Orders, and Medication Labels Mulholland: The Nurse, The Math, The Meds, 3rd EditionadenNo ratings yet
- Metabolic Solutions Report: Should You Get A Biopsy of That Lump?Document11 pagesMetabolic Solutions Report: Should You Get A Biopsy of That Lump?Ilona Gunawan100% (1)
- Psychiatric Interview (Autosaved)Document22 pagesPsychiatric Interview (Autosaved)Jana Victor100% (1)
- Trial Sem 3 2017 SMK THREE RIVERSDocument10 pagesTrial Sem 3 2017 SMK THREE RIVERSKeertana SubramaniamNo ratings yet
- Malnutrition e BD 12Document51 pagesMalnutrition e BD 12dr.vichiayorinaNo ratings yet
- Halitosis Augost 20 2015Document52 pagesHalitosis Augost 20 2015HairunnisaNo ratings yet
- Fayara Aretha Kunaefi Pathophysiology QBD1 FG2Document25 pagesFayara Aretha Kunaefi Pathophysiology QBD1 FG2fayaNo ratings yet
- Acute Paracetamol Poisoning Case Studies ReviewDocument5 pagesAcute Paracetamol Poisoning Case Studies Reviewbiya ao0No ratings yet
- Colic Essay OutlineDocument2 pagesColic Essay OutlineSyaie SyaiedaNo ratings yet
- Master Drug ChartDocument22 pagesMaster Drug ChartMahadhir AkmalNo ratings yet
- Emma Sarbit, EPSE405 WILK, Assignment 1 Watching A MovieDocument5 pagesEmma Sarbit, EPSE405 WILK, Assignment 1 Watching A Movieesarbit1No ratings yet
- 1.urogen Well D-One Eng. Rev. 6Document9 pages1.urogen Well D-One Eng. Rev. 6nmakrygNo ratings yet
- Mesenteric Venous Thrombosis NejmDocument6 pagesMesenteric Venous Thrombosis NejmJUAN LUIS PASAPERANo ratings yet
- Dispensing DrugsDocument1 pageDispensing DrugsIan CalalangNo ratings yet
- Gender Sensitivity in the PhilippinesDocument46 pagesGender Sensitivity in the PhilippinesMedardo BombitaNo ratings yet
- Cardiogenic Shock and Septic Shock: Perioperative ManagementDocument21 pagesCardiogenic Shock and Septic Shock: Perioperative ManagementachyutsharmaNo ratings yet
- 2015 Khairallah Et AlDocument9 pages2015 Khairallah Et AlAnifo Jose AntonioNo ratings yet
- Session 5 - Performing Cardiovascular System ExaminationDocument22 pagesSession 5 - Performing Cardiovascular System ExaminationOtsward OwdenNo ratings yet
- Community As Partner - Chapter 2Document2 pagesCommunity As Partner - Chapter 2KTNo ratings yet
- Genetics Problem Key Biol 121Document13 pagesGenetics Problem Key Biol 121S0% (1)
- GMAT Crititcal Reasoning (Practice)Document11 pagesGMAT Crititcal Reasoning (Practice)Hương HuỳnhNo ratings yet
- Bio 12 Zoology Lab ReviewerDocument12 pagesBio 12 Zoology Lab ReviewerFrettyDavidNo ratings yet
- 23011214560126@70 - Pichay, Loren Sta - Teresa - L230000355933 - 2300013461Document2 pages23011214560126@70 - Pichay, Loren Sta - Teresa - L230000355933 - 2300013461maxor4242No ratings yet
- Cinnamon Contact Stomatitis: A Case Report and ReviewDocument2 pagesCinnamon Contact Stomatitis: A Case Report and ReviewDwiNo ratings yet
- Thyroid Gland Resection Causes Appetite LossDocument14 pagesThyroid Gland Resection Causes Appetite LossRodriguez Vivanco Kevin DanielNo ratings yet
- 7-day recurrent feversDocument88 pages7-day recurrent feversCristobal Andres Fernandez Coentrao100% (2)
- Construction Manpower SafetyDocument25 pagesConstruction Manpower SafetyFritz BalasabasNo ratings yet
- Low Vision IntroductionDocument14 pagesLow Vision IntroductionSutrishna PramanikNo ratings yet
- Radionics - Lowe Chronically IllDocument6 pagesRadionics - Lowe Chronically IllE Paty VázquezNo ratings yet