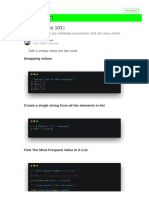
You might also like
- 147 Jicr June 2889Document8 pages147 Jicr June 2889Jay BoradeNo ratings yet
- The CodeDocument4 pagesThe CodemaenmrihansNo ratings yet
- Image AIDocument37 pagesImage AIFlat MateNo ratings yet
- 1 People - Counting - ProjectDocument4 pages1 People - Counting - Project4NM20IS003 ABHISHEK ANo ratings yet
- Object Detection and Image Recognition: KeywordsDocument11 pagesObject Detection and Image Recognition: KeywordsParas DograNo ratings yet
- Engineering Analysis and Design - ECN 206 Matlab Project TitleDocument19 pagesEngineering Analysis and Design - ECN 206 Matlab Project TitleApoorva SuriNo ratings yet
- Image Recognition and Melody CreationDocument28 pagesImage Recognition and Melody CreationAdarsh SinghNo ratings yet
- His Is A Dataset For Binary Sentiment Classification Containing Substantially More Data Than Previous Benchmark DatasetsDocument2 pagesHis Is A Dataset For Binary Sentiment Classification Containing Substantially More Data Than Previous Benchmark DatasetsMohammadali ShaikhNo ratings yet
- 2D CLASSIFICATION AND RECOGNITION SYSTEMSDocument4 pages2D CLASSIFICATION AND RECOGNITION SYSTEMSABDUL AZIZNo ratings yet
- How To Train An Object Detection Model With Mmdetection - DLologyDocument7 pagesHow To Train An Object Detection Model With Mmdetection - DLologyHuthaifa AbderahmanNo ratings yet
- An Application of A Deep Learning Algorithm For Automatic Detection of UnexpectedDocument7 pagesAn Application of A Deep Learning Algorithm For Automatic Detection of UnexpectedNATIONAL ATTENDENCENo ratings yet
- Deeplab Implementation For Object DetectionDocument4 pagesDeeplab Implementation For Object DetectionTatangwa BillyNo ratings yet
- Automatic Detection of Bike Riders Without Helmet: Under The Guidance of Mrs - Shanthi.E Submitted byDocument31 pagesAutomatic Detection of Bike Riders Without Helmet: Under The Guidance of Mrs - Shanthi.E Submitted byShanthiNo ratings yet
- Realtime Object Detection Using SSDDocument8 pagesRealtime Object Detection Using SSDAdil KhanNo ratings yet
- Automatic Video Surveillance SystemDocument16 pagesAutomatic Video Surveillance Systempratikgavale123No ratings yet
- Meghna Raj Saxena, Akarsh Pathak, Aditya Pratap Singh, Ishika ShuklaDocument4 pagesMeghna Raj Saxena, Akarsh Pathak, Aditya Pratap Singh, Ishika ShuklaGAIKWAD MAYURNo ratings yet
- Hrithik Tanwar 2K18/EE/085 Ishan Budhiraja 2K18/EE/087Document12 pagesHrithik Tanwar 2K18/EE/085 Ishan Budhiraja 2K18/EE/0872K18/EE/087 ISHAN BUDHIRAJANo ratings yet
- Chapter ThreeDocument19 pagesChapter Threeraymond wellNo ratings yet
- 19BCS2201 Progress ReportDocument15 pages19BCS2201 Progress ReportNIKHIL SHARMANo ratings yet
- Automatic Image Detection and Censoring On Web PagesDocument4 pagesAutomatic Image Detection and Censoring On Web PagesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Driver Drowsiness Detection SystemDocument17 pagesDriver Drowsiness Detection SystemNeeraj KumarNo ratings yet
- Region proposal object detection with OpenCV, Keras and TensorFlowDocument20 pagesRegion proposal object detection with OpenCV, Keras and TensorFlow超揚林No ratings yet
- Contour Based TrackingDocument20 pagesContour Based TrackingSahil SinghNo ratings yet
- Object Detection ReportDocument48 pagesObject Detection ReportAnonymous 1aqlkZNo ratings yet
- Deep Learning Weapon DetectionDocument5 pagesDeep Learning Weapon Detectionabhishek kajlaNo ratings yet
- Object Detection using YOLO algorithm ExplainedDocument10 pagesObject Detection using YOLO algorithm Explainedashmita deyNo ratings yet
- Real-Time Face Recognition Using OpenCVDocument3 pagesReal-Time Face Recognition Using OpenCVDurgesh KumarNo ratings yet
- Maxbox - Starter75 Object DetectionDocument7 pagesMaxbox - Starter75 Object DetectionMax KleinerNo ratings yet
- Color Based Object Tracking With OpenCV A SurveyDocument5 pagesColor Based Object Tracking With OpenCV A SurveyEditor IJTSRDNo ratings yet
- Safety For Drivers Using OpenCV in PythonDocument8 pagesSafety For Drivers Using OpenCV in PythonIJRASETPublicationsNo ratings yet
- Activity 1.4.2 Objects and Methods: 1. Form Pairs As Directed by Your Teacher. Meet or Greet Each Other To PracticeDocument15 pagesActivity 1.4.2 Objects and Methods: 1. Form Pairs As Directed by Your Teacher. Meet or Greet Each Other To PracticeWowNo ratings yet
- Report Image ProcessingDocument19 pagesReport Image Processingnahim islamNo ratings yet
- Image Processing - Using Machine Learning: Software Requirement SpecificationDocument19 pagesImage Processing - Using Machine Learning: Software Requirement Specification9609762955No ratings yet
- Image Proccessing Using PythonDocument7 pagesImage Proccessing Using PythonMayank GoyalNo ratings yet
- Object Tracking For Autonomous Vehicles: Project ReportDocument12 pagesObject Tracking For Autonomous Vehicles: Project ReportFIRE OC GAMINGNo ratings yet
- Sem V Project DocumentationDocument14 pagesSem V Project DocumentationRohan SalunkheNo ratings yet
- Smart Security Camera Using Raspberry PIDocument16 pagesSmart Security Camera Using Raspberry PIFahad KhanNo ratings yet
- Methodology: Source CodeDocument2 pagesMethodology: Source CodeChethan Reddy D RNo ratings yet
- Object Detection Using Stacked Yolov3: Ingénierie Des Systèmes D Information November 2020Document8 pagesObject Detection Using Stacked Yolov3: Ingénierie Des Systèmes D Information November 2020lamine karousNo ratings yet
- Interesting Python Project of Gender and Age Detection With OpenCVDocument8 pagesInteresting Python Project of Gender and Age Detection With OpenCVammarNo ratings yet
- Experiment:3.2: Relevance of The ExperimentDocument8 pagesExperiment:3.2: Relevance of The Experimentnishant singhNo ratings yet
- Smart Surveillance Using Computer VisionDocument4 pagesSmart Surveillance Using Computer VisionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- HandoverDocument13 pagesHandovertripletlossNo ratings yet
- Social Distancing Detection Using TensorflowDocument4 pagesSocial Distancing Detection Using TensorflowIRJMETS JOURNALNo ratings yet
- A Facial Recognition SystemDocument4 pagesA Facial Recognition SystemIJRASETPublicationsNo ratings yet
- Information Security Analysis and Audit: Team MembersDocument11 pagesInformation Security Analysis and Audit: Team MembersSaahil SmsNo ratings yet
- Python Project Final ReportDocument3 pagesPython Project Final ReportAyusha JagtapNo ratings yet
- Learn Opencv by Implementing A Face Mask Detector.: A Brief Introduction To Facial Detection With OpencvDocument10 pagesLearn Opencv by Implementing A Face Mask Detector.: A Brief Introduction To Facial Detection With OpencvChala GetaNo ratings yet
- Real-Time_Object_Detection_Using_SSD_MobileNet_ModDocument6 pagesReal-Time_Object_Detection_Using_SSD_MobileNet_Modkhalilkhalilb9No ratings yet
- OpenCV With Python Blueprints - Sample ChapterDocument30 pagesOpenCV With Python Blueprints - Sample ChapterPackt PublishingNo ratings yet
- ch1Document8 pagesch1aditya mishraNo ratings yet
- Badal Raj Tca1957010 Tmu Project SynopsisDocument20 pagesBadal Raj Tca1957010 Tmu Project SynopsisBadal RajNo ratings yet
- Aaquib Capstone Project EditedDocument2 pagesAaquib Capstone Project Editedshivam5singh-25No ratings yet
- ML Lab 3Document23 pagesML Lab 3Irfan KhanNo ratings yet
- Lab3 - Introduction To Machine Learning Algorithms With A Focus On Robotics ApplicationsDocument12 pagesLab3 - Introduction To Machine Learning Algorithms With A Focus On Robotics Applicationsnijanthan.roboticsNo ratings yet
- Computer Vision Assign-1Document1 pageComputer Vision Assign-1abdulsultanraza786No ratings yet
- Object Recognition ROS-KINECTDocument9 pagesObject Recognition ROS-KINECTyogeshkarna100% (1)
- Vehicle Detection in Videos Using OpenCV and PythonDocument1 pageVehicle Detection in Videos Using OpenCV and PythonEden AzranNo ratings yet
- Major SynopsisDocument11 pagesMajor SynopsisAnshu ChauhanNo ratings yet
- My Secret Sauce To Be in Top 2% of A Kaggle CompetitionDocument10 pagesMy Secret Sauce To Be in Top 2% of A Kaggle CompetitionmohitNo ratings yet
- Overview of AI AlgorithmsDocument31 pagesOverview of AI AlgorithmsmohitNo ratings yet
- Permutation and Combination - The Difference Explained With Formula ExamplesDocument13 pagesPermutation and Combination - The Difference Explained With Formula ExamplesmohitNo ratings yet
- P Value Explained Simply For Data Scientists 4c0cd7044f14Document12 pagesP Value Explained Simply For Data Scientists 4c0cd7044f14mohitNo ratings yet
- Python Tricks 101?Document7 pagesPython Tricks 101?mohitNo ratings yet
- OOPS Interview Questions With Answers For Freshers - Dot Net Tutorial - MediumDocument5 pagesOOPS Interview Questions With Answers For Freshers - Dot Net Tutorial - MediummohitNo ratings yet
- Python Generators: What Is A Generator?Document18 pagesPython Generators: What Is A Generator?mohitNo ratings yet
- Recursion DemystifiedDocument26 pagesRecursion DemystifiedmohitNo ratings yet
- Practical Functional ProgrammingDocument7 pagesPractical Functional ProgrammingmohitNo ratings yet
- ML Performance Improvement CheatsheetDocument11 pagesML Performance Improvement Cheatsheetrahulsukhija100% (1)
- Never Start With A HypothesisDocument7 pagesNever Start With A HypothesismohitNo ratings yet
- Object-Oriented Analysis and DesignDocument5 pagesObject-Oriented Analysis and DesignmohitNo ratings yet
- My Self-Created Artificial Intelligence Masters DegreeDocument10 pagesMy Self-Created Artificial Intelligence Masters Degreemohit100% (1)
- Multi-Class Text Classification With Scikit-LearnDocument20 pagesMulti-Class Text Classification With Scikit-LearnmohitNo ratings yet
- Nd002 Syllabus 2018 June v9Document5 pagesNd002 Syllabus 2018 June v9fsfewNo ratings yet
- Oop in Python Best ResourcesDocument1 pageOop in Python Best ResourcesSamuel ForknerNo ratings yet
- Medium ComDocument6 pagesMedium CommohitNo ratings yet
- How To Explain Object-Oriented Programming Concepts To A 6-Year-OldDocument7 pagesHow To Explain Object-Oriented Programming Concepts To A 6-Year-OldmohitNo ratings yet
- 10 Coding Prompts For Your PortfolioDocument13 pages10 Coding Prompts For Your PortfoliomohitNo ratings yet
- Todo Tutorials Can Be Fun - But Here's How To Build Your Own Projects From ScratchDocument6 pagesTodo Tutorials Can Be Fun - But Here's How To Build Your Own Projects From ScratchmohitNo ratings yet
- Floating Point RepresentationDocument5 pagesFloating Point RepresentationmohitNo ratings yet
- The Easy Way To Work With CSV, JSON, and XML in PythonDocument5 pagesThe Easy Way To Work With CSV, JSON, and XML in PythonmohitNo ratings yet
- Where To Use Object-Oriented Programming PDFDocument3 pagesWhere To Use Object-Oriented Programming PDFvikramiitkNo ratings yet
- How To Explain Object-Oriented Programming Concepts To A 6-Year-OldDocument7 pagesHow To Explain Object-Oriented Programming Concepts To A 6-Year-OldmohitNo ratings yet
- STRDocument2 pagesSTRmohitNo ratings yet
- Where To Use Object-Oriented Programming PDFDocument3 pagesWhere To Use Object-Oriented Programming PDFvikramiitkNo ratings yet
- Powerrouter Application Guideline: Technical Information About A Self-Use InstallationDocument31 pagesPowerrouter Application Guideline: Technical Information About A Self-Use InstallationluigigerulaNo ratings yet
- Peran Bumdes Dalam Pengelolaan Limbah Kelapa Sawit Di Desa Talang Jerinjing Kecamatan Rengat Barat Kabupaten Indragiri Hulu Provinsi RiauDocument11 pagesPeran Bumdes Dalam Pengelolaan Limbah Kelapa Sawit Di Desa Talang Jerinjing Kecamatan Rengat Barat Kabupaten Indragiri Hulu Provinsi RiauInnaka LestariNo ratings yet
- CS121Document2 pagesCS121Ikon TrashNo ratings yet
- Critical Path MethodDocument6 pagesCritical Path Method6 4 8 3 7 JAYAASRI KNo ratings yet
- ANSYS Parametric Design Language Guide 18.2Document110 pagesANSYS Parametric Design Language Guide 18.2Panda HeroNo ratings yet
- DVD615 PDFDocument228 pagesDVD615 PDFFreddy FerrerNo ratings yet
- Courant Friedrichs LewyDocument20 pagesCourant Friedrichs LewyEv OzcanNo ratings yet
- Satelec-X Mind AC Installation and Maintainance GuideDocument50 pagesSatelec-X Mind AC Installation and Maintainance Guideagmho100% (1)
- Gaussian Filtering FpgaDocument7 pagesGaussian Filtering Fpgaakkala vikasNo ratings yet
- Emenuhan Kebutuhan Nutrisi Balita Yang Dirawat Inap Di Rumah SakitDocument7 pagesEmenuhan Kebutuhan Nutrisi Balita Yang Dirawat Inap Di Rumah SakitAnnisa Nur Majidah100% (1)
- Function X - A Universal Decentralized InternetDocument24 pagesFunction X - A Universal Decentralized InternetrahmahNo ratings yet
- Experiment No - Ripple Carry Full AdderDocument3 pagesExperiment No - Ripple Carry Full AdderNikhil PawarNo ratings yet
- Martin (2000) Interpretation of Resicence Time Distribution Data PDFDocument11 pagesMartin (2000) Interpretation of Resicence Time Distribution Data PDFJuan FelipeNo ratings yet
- E-Tutorial - Online Correction - Resolution For Overbooked Challan (Movement of Dedcutee Row)Document36 pagesE-Tutorial - Online Correction - Resolution For Overbooked Challan (Movement of Dedcutee Row)Raj Kumar MNo ratings yet
- Adams 2013 Training 740 WorkbookDocument458 pagesAdams 2013 Training 740 WorkbookAnonymous ZC1ld1CLm100% (1)
- Unit 5 Instructor Graded AssignmentDocument3 pagesUnit 5 Instructor Graded Assignmentrosalindcsr_64842985No ratings yet
- Abstract Data TypeDocument19 pagesAbstract Data TypeAnkit AgrawalNo ratings yet
- Exercise: Answer the following questionsDocument11 pagesExercise: Answer the following questionsluqyana fauzia hadi100% (1)
- Industrial Internship DiaryDocument30 pagesIndustrial Internship Diaryvineela namaNo ratings yet
- Churn Consultancy For V Case SharingDocument13 pagesChurn Consultancy For V Case SharingObeid AllahNo ratings yet
- HLAB1Document27 pagesHLAB1SenseiNo ratings yet
- EWFC 1000: "Quick-Chill and Hold" Cold ControlDocument5 pagesEWFC 1000: "Quick-Chill and Hold" Cold ControlGede KusumaNo ratings yet
- Nemo Windcatcher: Industry-Leading Drive Test Data Post-Processing and AnalysisDocument2 pagesNemo Windcatcher: Industry-Leading Drive Test Data Post-Processing and AnalysistreejumboNo ratings yet
- Rosa Maria Aguado's Top Skills as a Freelance Graphic DesignerDocument15 pagesRosa Maria Aguado's Top Skills as a Freelance Graphic Designerolivia MehedaNo ratings yet
- Curve Weighting: Effects of High - End Non - LinearityDocument3 pagesCurve Weighting: Effects of High - End Non - LinearityhF2hFhiddenFaceNo ratings yet
- Life Elementary A2 Teachers Book Resources For TeaDocument1 pageLife Elementary A2 Teachers Book Resources For TeaNguyenhuuhoiNo ratings yet
- Blockchain Systems and Their Potential Impact On Business ProcessesDocument19 pagesBlockchain Systems and Their Potential Impact On Business ProcessesHussain MoneyNo ratings yet
- Contoh CVDocument2 pagesContoh CVBetty Pasaribu100% (1)
- Fourier Series: Yi Cheng Cal Poly PomonaDocument46 pagesFourier Series: Yi Cheng Cal Poly PomonaJesusSQANo ratings yet