You might also like
- Biochemistry Applied to Beer Brewing - General Chemistry of the Raw Materials of Malting and BrewingFrom EverandBiochemistry Applied to Beer Brewing - General Chemistry of the Raw Materials of Malting and BrewingRating: 4 out of 5 stars4/5 (1)
- BIOMOLECULES Plustwo Chemistry HssliveDocument5 pagesBIOMOLECULES Plustwo Chemistry HssliveKunal Goel100% (3)
- Biomolecules GRADE 12Document26 pagesBiomolecules GRADE 12Jericho Anthiel de GuzmanNo ratings yet
- BiomoleculesDocument32 pagesBiomoleculesspandhan reddyNo ratings yet
- Org Unit 5Document115 pagesOrg Unit 5lijyohannesmekonnen7No ratings yet
- Carbohydrate: CarbonDocument6 pagesCarbohydrate: CarbonTrexie JaymeNo ratings yet
- BCH 202 First LectureDocument9 pagesBCH 202 First Lecturemetasynthronos748No ratings yet
- Carbohydrates Materials ReviewDocument8 pagesCarbohydrates Materials ReviewIrvandar NurviandyNo ratings yet
- Biochemistry (3 Class) : Chapter Two Carbohydrates DR: Zeyan A. AliDocument37 pagesBiochemistry (3 Class) : Chapter Two Carbohydrates DR: Zeyan A. AlizeyanNo ratings yet
- BiomoleculesDocument8 pagesBiomoleculesOM SableNo ratings yet
- Chapter 6: Carbohydrates: 6.1. General Information About CarbohydratesDocument12 pagesChapter 6: Carbohydrates: 6.1. General Information About CarbohydratesMD. SAJID GHUFRANNo ratings yet
- BIOMOLECULESDocument72 pagesBIOMOLECULESPavanNo ratings yet
- Biomolecules: CarbohydratesDocument11 pagesBiomolecules: CarbohydratesDUHA GORASHINo ratings yet
- Chapter-Iii:Biomolecules: CarbohydratesDocument12 pagesChapter-Iii:Biomolecules: Carbohydratesbereket gashuNo ratings yet
- BIOMOLECULESDocument92 pagesBIOMOLECULESAVC TECH AND GAMING :GOVINDNo ratings yet
- BiomoleculesDocument85 pagesBiomoleculesYashveer RaiNo ratings yet
- Structures and Functions of Biomolecules PDFDocument23 pagesStructures and Functions of Biomolecules PDFMark Bryan TolentinoNo ratings yet
- Carbohydrates (Monosaccharides)Document56 pagesCarbohydrates (Monosaccharides)khadija100% (2)
- Chemistry Notes For Class 12 Chapter 14 BiomoleculesDocument13 pagesChemistry Notes For Class 12 Chapter 14 Biomoleculesrathi rupaNo ratings yet
- Carbohydrate Chemistry HandoutDocument8 pagesCarbohydrate Chemistry HandoutPIH SHTNo ratings yet
- carbohydrate chemistryDocument76 pagescarbohydrate chemistryShivanand MaliNo ratings yet
- Biochemistry-Module 43Document14 pagesBiochemistry-Module 43Ago General Hospital LaboratoryNo ratings yet
- 6-Carbohydrate ChemistryDocument59 pages6-Carbohydrate Chemistrygodara28pNo ratings yet
- Biochem SummaryDocument20 pagesBiochem SummaryJAREL ALBERT PASCASIONo ratings yet
- Biomolecules 231224 101920Document10 pagesBiomolecules 231224 101920Mariam HussainiNo ratings yet
- Chemistry Notes For Class 12 Chapter 14 Biomolecules: CarbohydratesDocument20 pagesChemistry Notes For Class 12 Chapter 14 Biomolecules: CarbohydratesSOUMYODEEP NAYAKNo ratings yet
- Class Xii Bio MoleculesDocument22 pagesClass Xii Bio MoleculesSiddharth GuptaNo ratings yet
- Class - Xii Subject - ChemistryDocument70 pagesClass - Xii Subject - ChemistryYash TandonNo ratings yet
- Carbohydrate Chemistry 2020-1Document99 pagesCarbohydrate Chemistry 2020-1WixHal MalikNo ratings yet
- Biomolecules PDFDocument5 pagesBiomolecules PDFTr Mazhar PunjabiNo ratings yet
- 9 BiomoleculesDocument17 pages9 BiomoleculesRajnish KumarNo ratings yet
- Genetics and Evolution: CarbohydratesDocument5 pagesGenetics and Evolution: Carbohydratesmahreen akramNo ratings yet
- CHE 461 Module 1Document20 pagesCHE 461 Module 1Danladi VictoriaNo ratings yet
- Macromolecules and Living ThingsDocument33 pagesMacromolecules and Living ThingsDana AhmadNo ratings yet
- biomolecules_0Document6 pagesbiomolecules_0HYBROS GAMINGNo ratings yet
- Xii PPT CH 15 Part 1 BiomoleculesDocument17 pagesXii PPT CH 15 Part 1 BiomoleculesBhavishya VermaNo ratings yet
- Carbohydrates LecDocument8 pagesCarbohydrates LecFrancis Ryannel S. De CastroNo ratings yet
- Carbhdrts 1Document10 pagesCarbhdrts 1IshnNo ratings yet
- Lecture 2 - Carbohydrate - TaggedDocument48 pagesLecture 2 - Carbohydrate - Taggedhashm.f.alamerNo ratings yet
- Bio MoleculesDocument14 pagesBio MoleculessvjbxgjNo ratings yet
- CarbohydratesDocument50 pagesCarbohydratesKhaledNo ratings yet
- Biomolecules Complete ChapterDocument48 pagesBiomolecules Complete ChapterDeep DasNo ratings yet
- Carbohydrates: Definition, Structure, Properties and ClassificationDocument45 pagesCarbohydrates: Definition, Structure, Properties and ClassificationKiya Alemu100% (1)
- L 14 BiomoleculesDocument20 pagesL 14 Biomoleculesshahin appuNo ratings yet
- Lecture 3 Carbohydrates 1-1Document67 pagesLecture 3 Carbohydrates 1-1Nuhu SibaNo ratings yet
- Structure Function CarbohydratesDocument28 pagesStructure Function Carbohydratespriya19866No ratings yet
- BIOCHEMISTRYDocument105 pagesBIOCHEMISTRYVai SanNo ratings yet
- Bio MoleculesDocument26 pagesBio MoleculesThe RockNo ratings yet
- CarbohydratesDocument22 pagesCarbohydratesMaris JoyceNo ratings yet
- Aqsa KhotiDocument16 pagesAqsa Khotigujjar gujjarNo ratings yet
- Bio MoleculesDocument12 pagesBio MoleculesMohammed IliasNo ratings yet
- Biomolecules XiiDocument5 pagesBiomolecules Xiisinhapapu412No ratings yet
- Carbohydrate Chemistry SummaryDocument27 pagesCarbohydrate Chemistry SummaryْNo ratings yet
- Biomolecules (Hints)Document2 pagesBiomolecules (Hints)hchawla421No ratings yet
- 2 - 2021-2022 Carbohydrates Chemistry CourseDocument94 pages2 - 2021-2022 Carbohydrates Chemistry CourseMabroka El BarasiNo ratings yet
- Carbohydrates: Monosaccharide NomenclatureDocument17 pagesCarbohydrates: Monosaccharide NomenclatureEden ManggaNo ratings yet
- Lehninger Principles of Biochemistry: Fourth EditionDocument137 pagesLehninger Principles of Biochemistry: Fourth Editionruaa mhmad100% (1)
- Carbohydrates: Classification and ImportanceDocument121 pagesCarbohydrates: Classification and ImportanceRalph Ian CaingcoyNo ratings yet
- Carbohydrate IstDocument37 pagesCarbohydrate Istrabiya fayyazNo ratings yet
- 2 CarbohydratesDocument18 pages2 Carbohydratesselavathy1937No ratings yet
- Biomolecules MCQ-1Document4 pagesBiomolecules MCQ-1BikashNo ratings yet
- Unit II: Solutions: Class-Xii 2021-22 Sub-ChemistryDocument21 pagesUnit II: Solutions: Class-Xii 2021-22 Sub-ChemistryBikashNo ratings yet
- Solution ColligativeDocument4 pagesSolution ColligativeBikashNo ratings yet
- Unit II: Solutions: Class-Xii 2021-22 Sub-ChemistryDocument21 pagesUnit II: Solutions: Class-Xii 2021-22 Sub-ChemistryBikashNo ratings yet
- Solution ColligativeDocument4 pagesSolution ColligativeBikashNo ratings yet
- Solution NumericalsDocument6 pagesSolution NumericalsBikashNo ratings yet
- Osmosis & Osmotic PressureDocument4 pagesOsmosis & Osmotic PressureBikashNo ratings yet
- Reactions of Haloarenes-1Document13 pagesReactions of Haloarenes-1BikashNo ratings yet
- Nomenclature of EthersDocument8 pagesNomenclature of EthersBikashNo ratings yet
- Haloalkane&Haloarene-2 Stereochemical PrinciplesDocument3 pagesHaloalkane&Haloarene-2 Stereochemical PrinciplesBikashNo ratings yet
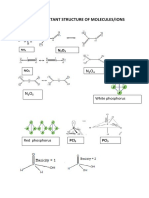
- Important Structure of MoleculesDocument4 pagesImportant Structure of MoleculesBikashNo ratings yet
- Nomenclature of EthersDocument8 pagesNomenclature of EthersBikashNo ratings yet
- Nomenclature of EthersDocument8 pagesNomenclature of EthersBikashNo ratings yet
- Jose P. Laurel Sr. High SchoolDocument8 pagesJose P. Laurel Sr. High SchoolEricha Solomon0% (1)
- Molbio HandoutDocument29 pagesMolbio HandoutHazel FlorentinoNo ratings yet
- 1.molecules of Life PDFDocument47 pages1.molecules of Life PDFaeylynnNo ratings yet
- Biological Chemistry (Concept To Remember)Document8 pagesBiological Chemistry (Concept To Remember)Kecilyn AmbrocioNo ratings yet
- Q4 Science 10 Module 2Document26 pagesQ4 Science 10 Module 2Francine Alburo75% (4)
- BIOMOLECULES POGIL (Ch. 2-3, Pgs. 44-48) : Ratio of ElementsDocument8 pagesBIOMOLECULES POGIL (Ch. 2-3, Pgs. 44-48) : Ratio of Elementsmadhavi goswami100% (1)
- Science 9 - Q2 - Mod4 - CARBON ATOM A UNIQUE ONE - VerFinalDocument24 pagesScience 9 - Q2 - Mod4 - CARBON ATOM A UNIQUE ONE - VerFinalAbel Emmanuel Solitario CabralesNo ratings yet
- Key Terms and DefinitionsDocument257 pagesKey Terms and DefinitionslaurafultanoNo ratings yet
- Gizmo - RNA Protein Synthesis BIO WORKSHEETDocument7 pagesGizmo - RNA Protein Synthesis BIO WORKSHEEThenry bhoneNo ratings yet
- TransfectionDocument60 pagesTransfectionJuan Luis Barrientos FritzNo ratings yet
- Biomolecules Quiz ReviewADocument2 pagesBiomolecules Quiz ReviewAJonaid AmpatuaNo ratings yet
- Chapter 20 Gene Technology & ApplicationsDocument6 pagesChapter 20 Gene Technology & ApplicationsIrish Jem BantolinoNo ratings yet
- Basic Medical Sciences For MRCP Part 1Document441 pagesBasic Medical Sciences For MRCP Part 1shanyiar96% (25)
- Biology ProjectDocument19 pagesBiology ProjectHussain Zohar0% (3)
- Inorg Biochem RandomnotesDocument20 pagesInorg Biochem RandomnotesDianne VillanuevaNo ratings yet
- Physical Science M4Document20 pagesPhysical Science M4Aeron GallardoNo ratings yet
- Human CellDocument22 pagesHuman Cellsen_subhasis_58No ratings yet
- Genetics Analysis and Principles 5th Edition Brooker Solutions ManualDocument6 pagesGenetics Analysis and Principles 5th Edition Brooker Solutions Manualariadneamelindasx7e100% (25)
- Nucleotides and nucleic acids: the building blocks of lifeDocument17 pagesNucleotides and nucleic acids: the building blocks of lifeFatma AdelNo ratings yet
- BiomoleculesDocument28 pagesBiomoleculesprincessmagpatocNo ratings yet
- BIO20 - The Biomolecules (Handouts) PDFDocument13 pagesBIO20 - The Biomolecules (Handouts) PDFKeith Ryan LapizarNo ratings yet
- DNA Structure and OrganizationDocument47 pagesDNA Structure and Organizationhjklknnm jhoiolkNo ratings yet
- Science 10 Q4 Module 2Document18 pagesScience 10 Q4 Module 2Carla Mae GeneseNo ratings yet
- Biological MoleculesDocument38 pagesBiological MoleculesmuzammalNo ratings yet
- w200 Science Lesson PlanDocument6 pagesw200 Science Lesson Planapi-385538681No ratings yet
- BiomoleculesDocument27 pagesBiomoleculesEreeNo ratings yet
- Water, Biomolecules & Their FunctionsDocument15 pagesWater, Biomolecules & Their FunctionsIshie De GuzmanNo ratings yet
- Biology - Grade 1 Secondary - Student's BookDocument161 pagesBiology - Grade 1 Secondary - Student's Bookhakkooma100% (1)
- Nucleic Acid PDFDocument32 pagesNucleic Acid PDFRachelle Anne LuisNo ratings yet
- Being Asked in Each of The Boxes. (Note: You Can Insert A Textbox Where You Can Insert Your Answer.)Document4 pagesBeing Asked in Each of The Boxes. (Note: You Can Insert A Textbox Where You Can Insert Your Answer.)Reign PedrosaNo ratings yet
- Periodic Tales: A Cultural History of the Elements, from Arsenic to ZincFrom EverandPeriodic Tales: A Cultural History of the Elements, from Arsenic to ZincRating: 3.5 out of 5 stars3.5/5 (137)
- Is That a Fact?: Frauds, Quacks, and the Real Science of Everyday LifeFrom EverandIs That a Fact?: Frauds, Quacks, and the Real Science of Everyday LifeRating: 4.5 out of 5 stars4.5/5 (3)
- The Disappearing Spoon: And Other True Tales of Madness, Love, and the History of the World from the Periodic Table of the ElementsFrom EverandThe Disappearing Spoon: And Other True Tales of Madness, Love, and the History of the World from the Periodic Table of the ElementsRating: 4 out of 5 stars4/5 (146)
- Organic Chemistry for Schools: Advanced Level and Senior High SchoolFrom EverandOrganic Chemistry for Schools: Advanced Level and Senior High SchoolNo ratings yet
- Guidelines for Asset Integrity ManagementFrom EverandGuidelines for Asset Integrity ManagementRating: 5 out of 5 stars5/5 (1)
- Meltdown: Nuclear disaster and the human cost of going criticalFrom EverandMeltdown: Nuclear disaster and the human cost of going criticalRating: 5 out of 5 stars5/5 (5)
- The Periodic Table of Elements - Post-Transition Metals, Metalloids and Nonmetals | Children's Chemistry BookFrom EverandThe Periodic Table of Elements - Post-Transition Metals, Metalloids and Nonmetals | Children's Chemistry BookNo ratings yet
- Chemistry: a QuickStudy Laminated Reference GuideFrom EverandChemistry: a QuickStudy Laminated Reference GuideRating: 5 out of 5 stars5/5 (1)
- Chemistry at Home - A Collection of Experiments and Formulas for the Chemistry EnthusiastFrom EverandChemistry at Home - A Collection of Experiments and Formulas for the Chemistry EnthusiastNo ratings yet
- Essential Oil Chemistry Formulating Essential Oil Blends that Heal - Aldehyde - Ketone - Lactone: Healing with Essential OilFrom EverandEssential Oil Chemistry Formulating Essential Oil Blends that Heal - Aldehyde - Ketone - Lactone: Healing with Essential OilRating: 5 out of 5 stars5/5 (1)
- Chemistry for Breakfast: The Amazing Science of Everyday LifeFrom EverandChemistry for Breakfast: The Amazing Science of Everyday LifeRating: 4.5 out of 5 stars4.5/5 (14)
- An Introduction to the Periodic Table of Elements : Chemistry Textbook Grade 8 | Children's Chemistry BooksFrom EverandAn Introduction to the Periodic Table of Elements : Chemistry Textbook Grade 8 | Children's Chemistry BooksRating: 5 out of 5 stars5/5 (1)
- Coating and Drying Defects: Troubleshooting Operating ProblemsFrom EverandCoating and Drying Defects: Troubleshooting Operating ProblemsRating: 5 out of 5 stars5/5 (1)
- Science Goes Viral: Captivating Accounts of Science in Everyday LifeFrom EverandScience Goes Viral: Captivating Accounts of Science in Everyday LifeRating: 5 out of 5 stars5/5 (1)
- The Elements We Live By: How Iron Helps Us Breathe, Potassium Lets Us See, and Other Surprising Superpowers of the Periodic TableFrom EverandThe Elements We Live By: How Iron Helps Us Breathe, Potassium Lets Us See, and Other Surprising Superpowers of the Periodic TableRating: 3.5 out of 5 stars3.5/5 (22)
- The Regenerative Grower's Guide to Garden Amendments: Using Locally Sourced Materials to Make Mineral and Biological Extracts and FermentsFrom EverandThe Regenerative Grower's Guide to Garden Amendments: Using Locally Sourced Materials to Make Mineral and Biological Extracts and FermentsRating: 5 out of 5 stars5/5 (3)
- Gas-Liquid And Liquid-Liquid SeparatorsFrom EverandGas-Liquid And Liquid-Liquid SeparatorsRating: 3.5 out of 5 stars3.5/5 (3)
- Monkeys, Myths, and Molecules: Separating Fact from Fiction in the Science of Everyday LifeFrom EverandMonkeys, Myths, and Molecules: Separating Fact from Fiction in the Science of Everyday LifeRating: 4 out of 5 stars4/5 (9)
- Stuff Matters: Exploring the Marvelous Materials That Shape Our Man-Made WorldFrom EverandStuff Matters: Exploring the Marvelous Materials That Shape Our Man-Made WorldRating: 4 out of 5 stars4/5 (289)
- The Periodic Table: A Very Short IntroductionFrom EverandThe Periodic Table: A Very Short IntroductionRating: 4.5 out of 5 stars4.5/5 (3)
- Chemical Elements Pocket Guide: Detailed Summary of the Periodic TableFrom EverandChemical Elements Pocket Guide: Detailed Summary of the Periodic TableNo ratings yet