You might also like
- Famous NetworksDocument6 pagesFamous Networksmavoho1719No ratings yet
- Khin Than Nyunt PHD (Ce-It) 7: Presented byDocument15 pagesKhin Than Nyunt PHD (Ce-It) 7: Presented byKhin Than NyuntNo ratings yet
- Res NetDocument8 pagesRes Netjaffar bikatNo ratings yet
- CNN Case Studies Unit 4Document13 pagesCNN Case Studies Unit 4Anushka JanotiNo ratings yet
- Report Dsa FinalDocument12 pagesReport Dsa FinalMihir OberoiNo ratings yet
- Summary Lecture 14Document1 pageSummary Lecture 14Darkos134No ratings yet
- EfficientNet TutorialDocument20 pagesEfficientNet TutorialTsigabuNo ratings yet
- Technical Report On DenseNet Architecture (Deep Learning Network Model)Document9 pagesTechnical Report On DenseNet Architecture (Deep Learning Network Model)Oluwaseun AdekolaNo ratings yet
- Xuesong Wang Et Al - 2021 - Multipath Ensemble Convolutional Neural NetworkDocument9 pagesXuesong Wang Et Al - 2021 - Multipath Ensemble Convolutional Neural Networkbigliang98No ratings yet
- Explaining How Resnet-50 Works and Why It Is So PopularDocument15 pagesExplaining How Resnet-50 Works and Why It Is So PopularAbhishek SanapNo ratings yet
- Data Science Interview Preparation (30 Days of Interview Preparation)Document15 pagesData Science Interview Preparation (30 Days of Interview Preparation)qtdaivuongNo ratings yet
- Data Science Interview Preparation (# DAY 22)Document16 pagesData Science Interview Preparation (# DAY 22)ARPAN MAITYNo ratings yet
- Data Science Interview Preparation (# DAY 22)Document16 pagesData Science Interview Preparation (# DAY 22)ThànhĐạt NgôNo ratings yet
- Data Science Interview Preparation 22Document16 pagesData Science Interview Preparation 22Julian TolosaNo ratings yet
- Chapter 3Document7 pagesChapter 3pavithrNo ratings yet
- Components of Artificial Neural NetworksDocument27 pagesComponents of Artificial Neural NetworksEmy MuhamedNo ratings yet
- Imagenet ClassificationDocument9 pagesImagenet Classificationice117No ratings yet
- CS 601 Machine Learning Unit 3Document37 pagesCS 601 Machine Learning Unit 3Priyanka BhateleNo ratings yet
- IBM Question & AnswersDocument3 pagesIBM Question & AnswersMr SKammerNo ratings yet
- Depth DropoutDocument7 pagesDepth DropoutheavywaterNo ratings yet
- Layer-Wise Training Rectified Linear Activation Function: Kick-Start Your Project With My New BookDocument3 pagesLayer-Wise Training Rectified Linear Activation Function: Kick-Start Your Project With My New BookAbhishek SanapNo ratings yet
- Imagify Reconstruction of High - Resolution Images From Degraded ImagesDocument5 pagesImagify Reconstruction of High - Resolution Images From Degraded ImagesIJRASETPublicationsNo ratings yet
- Age and Gender ClassificationDocument26 pagesAge and Gender ClassificationMohammed ZubairNo ratings yet
- Bài 9 Các Kiến Trúc CNN Đơn GiảnDocument11 pagesBài 9 Các Kiến Trúc CNN Đơn GiảnTai Nguyen AnhNo ratings yet
- Structured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong SungDocument11 pagesStructured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong Sungali shaarawyNo ratings yet
- Understanding of A Convolutional Neural NetworkDocument6 pagesUnderstanding of A Convolutional Neural NetworkJavier BushNo ratings yet
- CS231n - Convolutional-Networks 1Document3 pagesCS231n - Convolutional-Networks 1olia.92No ratings yet
- Deep Cascade LearningDocument11 pagesDeep Cascade Learningcoelho.alv4544No ratings yet
- Difference Between AlexNet, VGGNet, ResNet, and Inception - by Aqeel Anwar - Towards Data ScienceDocument14 pagesDifference Between AlexNet, VGGNet, ResNet, and Inception - by Aqeel Anwar - Towards Data ScienceShrivathsatv ShriNo ratings yet
- Types of Convolutional Neural Networks - LeNet, AlexNet, VGG-16 Net, ResNet and Inception Net - by Bhavesh Singh Bisht - Analytics Vidhya - MediumDocument6 pagesTypes of Convolutional Neural Networks - LeNet, AlexNet, VGG-16 Net, ResNet and Inception Net - by Bhavesh Singh Bisht - Analytics Vidhya - Mediumtarunbandari4504No ratings yet
- Gap Method For Keyword Spotting: Varsha Thakur, HimanisikarwarDocument7 pagesGap Method For Keyword Spotting: Varsha Thakur, HimanisikarwarSunil ChaluvaiahNo ratings yet
- Zeiler Ec CV 2014Document16 pagesZeiler Ec CV 2014Vaibhav JainNo ratings yet
- Res NetDocument46 pagesRes Netjaffar bikatNo ratings yet
- Data Science Interview Preparation (#DAY 14)Document11 pagesData Science Interview Preparation (#DAY 14)ARPAN MAITYNo ratings yet
- MLOA Exp 1 - C121Document18 pagesMLOA Exp 1 - C121Devanshu MaheshwariNo ratings yet
- Room Classification Using Machine LearningDocument16 pagesRoom Classification Using Machine LearningVARSHANo ratings yet
- Graph Convolutional Networks Adaptations and ApplicationsDocument6 pagesGraph Convolutional Networks Adaptations and ApplicationsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Principles of Convolutional Neural NetworksDocument9 pagesPrinciples of Convolutional Neural NetworksAsma AliNo ratings yet
- U-Net: Convolutional Networks For Biomedical Image SegmentationDocument8 pagesU-Net: Convolutional Networks For Biomedical Image SegmentationUsman SaeedNo ratings yet
- Artificial Neural Networks: 3.1) IntroductionDocument24 pagesArtificial Neural Networks: 3.1) IntroductionNmg KumarNo ratings yet
- Alex NetDocument9 pagesAlex NetMahmoudNo ratings yet
- Semantic Segmentation Via Highly Fused Convolutional Network With Multiple Soft Cost FunctionsDocument16 pagesSemantic Segmentation Via Highly Fused Convolutional Network With Multiple Soft Cost FunctionsV.R.S.MANINo ratings yet
- 5 Days InetrnshipDocument48 pages5 Days InetrnshipsowmiNo ratings yet
- DL Anonymous Question BankDocument22 pagesDL Anonymous Question BankAnuradha PiseNo ratings yet
- Convolutional Neural Networks (Cnns / Convnets)Document21 pagesConvolutional Neural Networks (Cnns / Convnets)CGNo ratings yet
- C2FS: An Algorithm For Feature Selection in Cascade Neural NetworksDocument6 pagesC2FS: An Algorithm For Feature Selection in Cascade Neural NetworksKukuh UtamaNo ratings yet
- 219 ReportDocument7 pages219 Reportjames flkjsNo ratings yet
- Eait 2018 8470438Document5 pagesEait 2018 8470438Ahmed EmadNo ratings yet
- Deep LearningUNIT-IVDocument16 pagesDeep LearningUNIT-IVnikhilsinha0099No ratings yet
- Convolutional Neural NetworkDocument61 pagesConvolutional Neural NetworkAnkit MahapatraNo ratings yet
- King-Rook Vs King With Neural NetworksDocument10 pagesKing-Rook Vs King With Neural NetworksfuzzieNo ratings yet
- Ml@ok QuestionsDocument16 pagesMl@ok QuestionsINV SHRNo ratings yet
- Deep Residual Learning For Image RecognitionDocument2 pagesDeep Residual Learning For Image RecognitionShrishti HoreNo ratings yet
- Quoc Le TutorialDocument20 pagesQuoc Le TutorialVikramJhaNo ratings yet
- PyTorch Plus Computer Vision - Aravind AriharasudhanDocument28 pagesPyTorch Plus Computer Vision - Aravind AriharasudhanAravind AriharasudhanNo ratings yet
- From: First IEE International Conference On Artificial Neural Networks. IEE Conference Publication 313Document18 pagesFrom: First IEE International Conference On Artificial Neural Networks. IEE Conference Publication 313Ahmed KhazalNo ratings yet
- CS231n Convolutional Neural Networks For Visual RecognitionDocument2 pagesCS231n Convolutional Neural Networks For Visual RecognitionFernando Robles BermejoNo ratings yet
- Pattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkDocument5 pagesPattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkEkin RafiaiNo ratings yet
- Deep Learning with Python: A Comprehensive Guide to Deep Learning with PythonFrom EverandDeep Learning with Python: A Comprehensive Guide to Deep Learning with PythonNo ratings yet
- Keras to Kubernetes: The Journey of a Machine Learning Model to ProductionFrom EverandKeras to Kubernetes: The Journey of a Machine Learning Model to ProductionNo ratings yet
- Face Recognition Documentation: Release 1.4.0Document41 pagesFace Recognition Documentation: Release 1.4.0Nhân HồNo ratings yet
- Possible, and Determine Whether Row Interchanges Are NecessaryDocument78 pagesPossible, and Determine Whether Row Interchanges Are NecessaryNhân HồNo ratings yet
- Possible, and Determine Whether Row Interchanges Are NecessaryDocument78 pagesPossible, and Determine Whether Row Interchanges Are NecessaryNhân HồNo ratings yet
- THEORIESDocument5 pagesTHEORIESNhân HồNo ratings yet
- Hand SolvingDocument1 pageHand SolvingNhân HồNo ratings yet
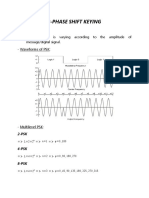
- 2-Phase Shift Keying: Lecturer: Prof. Lê Tiến ThườngDocument9 pages2-Phase Shift Keying: Lecturer: Prof. Lê Tiến ThườngNhân HồNo ratings yet
- Impact of The 2008-2009 Global Financial Crisis On SingaporeDocument1 pageImpact of The 2008-2009 Global Financial Crisis On SingaporeNhân HồNo ratings yet
- 2-Phase Shift Keying: - Definition of PSKDocument3 pages2-Phase Shift Keying: - Definition of PSKNhân HồNo ratings yet
- Project Report: Đại học Duy Tân Khoa Điện - Điện tửDocument22 pagesProject Report: Đại học Duy Tân Khoa Điện - Điện tửNhân HồNo ratings yet
- Multi-Phase Shift Keying Modulation Using Generalised Array CodesDocument19 pagesMulti-Phase Shift Keying Modulation Using Generalised Array CodesTasheela SujeebunNo ratings yet
- Lab 5 Report: Đại học Duy Tân Khoa Điện - Điện tửDocument22 pagesLab 5 Report: Đại học Duy Tân Khoa Điện - Điện tửNhân HồNo ratings yet
- ICS Security Solutions MapDocument2 pagesICS Security Solutions MapAni MNo ratings yet
- © The Institute of Chartered Accountants of IndiaDocument0 pages© The Institute of Chartered Accountants of IndiaP VenkatesanNo ratings yet
- Transient Master Manual EnglishDocument12 pagesTransient Master Manual EnglishIgnacioNo ratings yet
- SQIT3043 Chapter 8 - SQL (Latest)Document36 pagesSQIT3043 Chapter 8 - SQL (Latest)Naurah Baiti100% (1)
- How To: Make LyX PortableDocument2 pagesHow To: Make LyX PortableLibMonkeyNo ratings yet
- Blue Purple Futuristic Modern 3D Tech Company Business PresentationDocument10 pagesBlue Purple Futuristic Modern 3D Tech Company Business PresentationUser Not FoundNo ratings yet
- JavaDocument11 pagesJavaharshad waghNo ratings yet
- Microsoft AZ-104 ExamDocument274 pagesMicrosoft AZ-104 ExamAbrarNo ratings yet
- DPR eDocument19 pagesDPR eHải Dương CT thí nghiệm điệnNo ratings yet
- HDS DF800 Maintenance Manual IntroDocument176 pagesHDS DF800 Maintenance Manual Introulrik engellNo ratings yet
- Make Your Own Anti Virus With Batch CommandsDocument2 pagesMake Your Own Anti Virus With Batch CommandsSunday AdebiyiNo ratings yet
- ch-2 PHPDocument33 pagesch-2 PHPHirNo ratings yet
- Adh Dozon SchoolDocument41 pagesAdh Dozon Schoolapi-19663628No ratings yet
- Registering For PING ID On A Mobile PhoneDocument4 pagesRegistering For PING ID On A Mobile PhonePablo PazNo ratings yet
- Biometrics Research PaperDocument1 pageBiometrics Research PaperDhananjayKumarNo ratings yet
- Selling The Value of Google Workspace To Microsoft Customers - Y22Document36 pagesSelling The Value of Google Workspace To Microsoft Customers - Y22rupsshaNo ratings yet
- Revised - Quiz - DA Schedule - Vellore PDFDocument1 pageRevised - Quiz - DA Schedule - Vellore PDFMohamed JunaidNo ratings yet
- Routing PosterDocument1 pageRouting PosterFrederick Mensah-BurobeyNo ratings yet
- Current Awareness Service - A Contemporary Issue in Digital Era - Anil MishraDocument23 pagesCurrent Awareness Service - A Contemporary Issue in Digital Era - Anil MishraAnil Mishra100% (1)
- Sage Intelligence 100 Ms Excel Tips and TricksDocument76 pagesSage Intelligence 100 Ms Excel Tips and Trickssmartysus100% (1)
- Beamer CernDocument18 pagesBeamer CernzeusNo ratings yet
- Unique Cable Condition Assessment SystemDocument2 pagesUnique Cable Condition Assessment SystemNaseemNo ratings yet
- NSXT 24 AdminDocument606 pagesNSXT 24 Adminjei.dataNo ratings yet
- 1.GSM OverviewDocument46 pages1.GSM OverviewAmit ThakurNo ratings yet
- Programming Fundamentals Course Outline - 2022-2023Document3 pagesProgramming Fundamentals Course Outline - 2022-2023nhyirahayimNo ratings yet
- Leo Grammaticus: ChronographiaDocument573 pagesLeo Grammaticus: ChronographiaRuskiiMorganNo ratings yet
- Create A Jenkins CICD Pipeline With SonarQube Integration To Perform Static Code AnalysisDocument3 pagesCreate A Jenkins CICD Pipeline With SonarQube Integration To Perform Static Code AnalysisRidam MisraNo ratings yet
- S4600 - 3.1.1 - Configuration GuideDocument431 pagesS4600 - 3.1.1 - Configuration GuideHadrian1No ratings yet
- Using CALL TRANSACTION USING For Data Transfer: The MODE ParameterDocument13 pagesUsing CALL TRANSACTION USING For Data Transfer: The MODE ParameterashahmednNo ratings yet
- Django SetupDocument11 pagesDjango SetupSandeep Chowdary MuthineniNo ratings yet