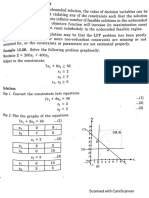
You might also like
- Heart Failure Prediction using Hybrid Machine Learning TechniquesDocument63 pagesHeart Failure Prediction using Hybrid Machine Learning Techniquesabhi spdyNo ratings yet
- Magnetic Resonance Imaging: Recording, Reconstruction and AssessmentFrom EverandMagnetic Resonance Imaging: Recording, Reconstruction and AssessmentRating: 5 out of 5 stars5/5 (1)
- Irpa SapDocument13 pagesIrpa SapDINESHNo ratings yet
- Machine Learning Techniques For Heart Disease Prediction: A. Lakshmanarao, Y.Swathi, P.Sri Sai SundareswarDocument4 pagesMachine Learning Techniques For Heart Disease Prediction: A. Lakshmanarao, Y.Swathi, P.Sri Sai SundareswarRicky ThanmaiNo ratings yet
- Heart Disease PredictionDocument9 pagesHeart Disease Predictionفضل صاهولNo ratings yet
- PPML Final ReportDocument16 pagesPPML Final Report210801059No ratings yet
- 2nd ReviewDocument21 pages2nd ReviewShivank YadavNo ratings yet
- Research ProposalDocument8 pagesResearch ProposalMUDIT CHOPRA 2020224No ratings yet
- JOCC - Volume 2 - Issue 1 - Pages 50-65Document16 pagesJOCC - Volume 2 - Issue 1 - Pages 50-65Ananya DhuriaNo ratings yet
- Comparative Study of Heart Disease Prediction Using Machine Learning AlgorithmsDocument6 pagesComparative Study of Heart Disease Prediction Using Machine Learning Algorithmsharshitvashisth76No ratings yet
- Eng p3 Heartdisease Forecasting-V7Document25 pagesEng p3 Heartdisease Forecasting-V7Cevi HerdianNo ratings yet
- Heart Disease Python Report 1st PhaseDocument33 pagesHeart Disease Python Report 1st PhaseAishwarya PNo ratings yet
- 20221031014210pmwebology 19 (5) 56Document10 pages20221031014210pmwebology 19 (5) 56harshitvashisth76No ratings yet
- SST WordDocument13 pagesSST WordRudra SharmaNo ratings yet
- ML 2020Document18 pagesML 2020Bhaskar Rao PNo ratings yet
- Data Mining Techniques: Review 1 B1+Tb1 SlotDocument10 pagesData Mining Techniques: Review 1 B1+Tb1 SlotSriGaneshNo ratings yet
- Group 19Document21 pagesGroup 19Mr. ShaikhNo ratings yet
- Research Article: Prediction of Heart Disease Using A Combination of Machine Learning and Deep LearningDocument11 pagesResearch Article: Prediction of Heart Disease Using A Combination of Machine Learning and Deep LearningTesta MestaNo ratings yet
- Developing A Hyperparameter Tuning Based Machine LDocument17 pagesDeveloping A Hyperparameter Tuning Based Machine Lshital shermaleNo ratings yet
- Using Sentiment Analysis and Machine Learning Algorithms To Determine Citizens' PerceptionsDocument6 pagesUsing Sentiment Analysis and Machine Learning Algorithms To Determine Citizens' Perceptionss.bahliNo ratings yet
- Heart Disease Detection Using Machine Learning: Chithambaram T Logesh Kannan N Gowsalya M (Gowsalya.m@vit - Ac.in)Document5 pagesHeart Disease Detection Using Machine Learning: Chithambaram T Logesh Kannan N Gowsalya M (Gowsalya.m@vit - Ac.in)Nahid HasanNo ratings yet
- Synopsis (Heart Disease Prediction)Document7 pagesSynopsis (Heart Disease Prediction)HOD CSENo ratings yet
- TSP CMC 41333Document14 pagesTSP CMC 41333KEZZIA MAE ABELLANo ratings yet
- Heart Disease rp5Document15 pagesHeart Disease rp5EkanshNo ratings yet
- Heart DiseaseDocument13 pagesHeart Diseaseفضل صاهولNo ratings yet
- Heart Disease Prediction Using Machine LearningDocument18 pagesHeart Disease Prediction Using Machine Learningsj647387No ratings yet
- Second Progres ReportDocument10 pagesSecond Progres ReportManish RajNo ratings yet
- Final Year ProjectDocument57 pagesFinal Year ProjectMuhammad FaseehNo ratings yet
- Predict Heart Failure Risk with Hybrid MLDocument17 pagesPredict Heart Failure Risk with Hybrid MLabhi spdy100% (1)
- Project 1Document17 pagesProject 1sachin chaudharyNo ratings yet
- Heart Disease Prediction Model: DissertationDocument4 pagesHeart Disease Prediction Model: DissertationGaurav MehraNo ratings yet
- Heart Disease Detection Using Machine LearningDocument12 pagesHeart Disease Detection Using Machine LearningAbhishek DeshmukhNo ratings yet
- Models to predict cardiovascular risk- comparison of CART, Multilayer perceptron and logistic regressionDocument5 pagesModels to predict cardiovascular risk- comparison of CART, Multilayer perceptron and logistic regressionAbel DemelashNo ratings yet
- Heart Disease Prediction Using Machine Learning Techniques: AbstractDocument5 pagesHeart Disease Prediction Using Machine Learning Techniques: Abstractshital shermaleNo ratings yet
- Cardiac Disease Prediction using MLDocument17 pagesCardiac Disease Prediction using MLManoj KumarNo ratings yet
- Prediction of Heart Diseases Using Machine LearningDocument49 pagesPrediction of Heart Diseases Using Machine Learningandyy4663No ratings yet
- BalaDocument28 pagesBalaRishi rao KulakarniNo ratings yet
- 19mca1097 Heart Failure Prediction Review3Document18 pages19mca1097 Heart Failure Prediction Review3abhi spdyNo ratings yet
- Final Heart Disease PredictionDocument26 pagesFinal Heart Disease PredictionMayur ChaudhariNo ratings yet
- J Imu 2019 100203Document18 pagesJ Imu 2019 100203Basil AlsaadiNo ratings yet
- 2020 IJ Scopus IJAST Divya LalithaDocument10 pages2020 IJ Scopus IJAST Divya LalithaR.V.S.LALITHANo ratings yet
- AB Report Group 2Document14 pagesAB Report Group 2Abyan HarahapNo ratings yet
- Information: A Heart Disease Prediction Model Based On Feature Optimization and Smote-Xgboost AlgorithmDocument15 pagesInformation: A Heart Disease Prediction Model Based On Feature Optimization and Smote-Xgboost Algorithmharshitvashisth76No ratings yet
- Effective Heart Disease Prediction Using Hybrid Machine Learning TechniquesDocument13 pagesEffective Heart Disease Prediction Using Hybrid Machine Learning Techniquesसाई पालनवारNo ratings yet
- TE-MiniProject Mock 2 PresentationDocument18 pagesTE-MiniProject Mock 2 Presentationganesh.gc8747No ratings yet
- Final PPT Heart DiseaseDocument23 pagesFinal PPT Heart Diseasenithish Kumar100% (1)
- IEEE TemplateDocument4 pagesIEEE TemplateSameer HussainNo ratings yet
- 2021 IC FICTA Boosting accuracyDocument13 pages2021 IC FICTA Boosting accuracyR.V.S.LALITHANo ratings yet
- An Empirical Study On Machine Learning Algorithms For Heart Disease PredictionDocument8 pagesAn Empirical Study On Machine Learning Algorithms For Heart Disease PredictionIAES IJAINo ratings yet
- Heart Disease Prediction Using CNN, Deep Learning ModelDocument9 pagesHeart Disease Prediction Using CNN, Deep Learning ModelIJRASETPublicationsNo ratings yet
- Hybrid Classification Using Ensemble Model To Predict Cardiovascular DiseasesDocument11 pagesHybrid Classification Using Ensemble Model To Predict Cardiovascular DiseasesIJRASETPublicationsNo ratings yet
- LungcancerDocument5 pagesLungcancersubhasis mitraNo ratings yet
- Predicting Cardiovascular Disease Using Hybrid MLDocument9 pagesPredicting Cardiovascular Disease Using Hybrid MLewuiplkw phuvdjNo ratings yet
- Heart Disease Prediction Using Machine Learning Techniques: October 2020Document6 pagesHeart Disease Prediction Using Machine Learning Techniques: October 2020Nelakurthi SudheerNo ratings yet
- Prediction of Heart Disease Using Machine Learning TechniquesDocument4 pagesPrediction of Heart Disease Using Machine Learning Techniquesrahul suryawanshiNo ratings yet
- BASE PAPERDocument21 pagesBASE PAPER023-Subha KNo ratings yet
- Heart Disease Prediction Using Machine Learning Techniques: Devansh Shah Samir Patel Santosh Kumar BhartiDocument6 pagesHeart Disease Prediction Using Machine Learning Techniques: Devansh Shah Samir Patel Santosh Kumar Bhartifuck MeNo ratings yet
- Heart Disease DetectionDocument18 pagesHeart Disease Detectiondummy dummyNo ratings yet
- Format - For - Project - Synopsis HeartDocument19 pagesFormat - For - Project - Synopsis HeartMadhuri RahangdaleNo ratings yet
- Clinical Prediction Models: A Practical Approach to Development, Validation, and UpdatingFrom EverandClinical Prediction Models: A Practical Approach to Development, Validation, and UpdatingNo ratings yet
- Clinical Decision Support System: Fundamentals and ApplicationsFrom EverandClinical Decision Support System: Fundamentals and ApplicationsNo ratings yet
- Caste and Class ConflictsDocument2 pagesCaste and Class ConflictsRicky ThanmaiNo ratings yet
- Documents Submission: (As Per SSC) (Surname) (Please Expand Your Lastname)Document3 pagesDocuments Submission: (As Per SSC) (Surname) (Please Expand Your Lastname)Ricky ThanmaiNo ratings yet
- CIA 3 - Social Issues in MaharshiDocument7 pagesCIA 3 - Social Issues in MaharshiRicky ThanmaiNo ratings yet
- Nutritional Epidemiology AssignmentDocument6 pagesNutritional Epidemiology AssignmentRicky ThanmaiNo ratings yet
- Unit 3: AnnuitiesDocument15 pagesUnit 3: AnnuitiesRicky Thanmai100% (1)
- CIA 3 - Social Issues in MaharshiDocument7 pagesCIA 3 - Social Issues in MaharshiRicky ThanmaiNo ratings yet
- BCom Business MathematicsDocument31 pagesBCom Business MathematicsRicky ThanmaiNo ratings yet
- End Sem Exams - Term 1: English Economics Add. English Economics English MathematicsDocument1 pageEnd Sem Exams - Term 1: English Economics Add. English Economics English MathematicsRicky ThanmaiNo ratings yet
- Basic Psychological Processes CIA - 3: SAI Harini Vegiraju 2120820 1 BBA HDocument6 pagesBasic Psychological Processes CIA - 3: SAI Harini Vegiraju 2120820 1 BBA HRicky ThanmaiNo ratings yet
- Note-Taking: English Asynchronous Activity Sai Harini Vegiraju 2120820Document2 pagesNote-Taking: English Asynchronous Activity Sai Harini Vegiraju 2120820Ricky ThanmaiNo ratings yet
- Parts of Speech-VerbsDocument5 pagesParts of Speech-VerbsRicky ThanmaiNo ratings yet
- MENUDocument1 pageMENURicky ThanmaiNo ratings yet
- Sec-Cia Sai Harini Vegiraju 2120820 Time Management-The Case of Missing TimeDocument2 pagesSec-Cia Sai Harini Vegiraju 2120820 Time Management-The Case of Missing TimeRicky ThanmaiNo ratings yet
- MathsDocument4 pagesMathsRicky ThanmaiNo ratings yet
- CIA 3 - Social Issues in MaharshiDocument7 pagesCIA 3 - Social Issues in MaharshiRicky ThanmaiNo ratings yet
- Caste and Class ConflictsDocument2 pagesCaste and Class ConflictsRicky ThanmaiNo ratings yet
- Sec-Cia Sai Harini Vegiraju 2120820 Time Management-The Case of Missing TimeDocument2 pagesSec-Cia Sai Harini Vegiraju 2120820 Time Management-The Case of Missing TimeRicky ThanmaiNo ratings yet
- Potential Investor in Automotive Sector in Mena'Document10 pagesPotential Investor in Automotive Sector in Mena'Ricky ThanmaiNo ratings yet
- Parts of Speech-VerbsDocument5 pagesParts of Speech-VerbsRicky ThanmaiNo ratings yet
- Business Mathematics CIA-1.2 2120820 Sai Harini Vegiraju Investment and Returns-Cramer'S RuleDocument5 pagesBusiness Mathematics CIA-1.2 2120820 Sai Harini Vegiraju Investment and Returns-Cramer'S RuleRicky ThanmaiNo ratings yet
- Caste and Class ConflictsDocument2 pagesCaste and Class ConflictsRicky ThanmaiNo ratings yet
- Asynchronous Assignment Sai Harini Vegiraju 2120820 The Babu'S of Nayanjore-KusumDocument1 pageAsynchronous Assignment Sai Harini Vegiraju 2120820 The Babu'S of Nayanjore-KusumRicky ThanmaiNo ratings yet
- VANSHIKA GUPTA 2120871 - Identify Subject, Verb and TenseDocument5 pagesVANSHIKA GUPTA 2120871 - Identify Subject, Verb and TenseRicky ThanmaiNo ratings yet
- Financial Accounting: Company Choosen: NTPC Name: Priyanka Sanjana Voonna REGISTRATION NO: 2120873Document3 pagesFinancial Accounting: Company Choosen: NTPC Name: Priyanka Sanjana Voonna REGISTRATION NO: 2120873Ricky ThanmaiNo ratings yet
- Mutlileyer Perseptron Ann Based Watershed Segmentation To Detect Mammogram TumorDocument9 pagesMutlileyer Perseptron Ann Based Watershed Segmentation To Detect Mammogram TumorInternational Journal of Application or Innovation in Engineering & Management100% (1)
- L5 Slides - Computing Systems - Y12Document25 pagesL5 Slides - Computing Systems - Y12Mr. Mark Joseph P.ImperioNo ratings yet
- PC Experiment - Pressure, Temperature, Flow and LevelDocument15 pagesPC Experiment - Pressure, Temperature, Flow and LevelnajihahNo ratings yet
- Hill RBF CalculatorDocument4 pagesHill RBF CalculatorHaag-Streit UK (HS-UK)No ratings yet
- Buchanan2006 - A Very Brief History of AIDocument8 pagesBuchanan2006 - A Very Brief History of AIJuan PalomoNo ratings yet
- USM EEE 350 Control Systems Exam QuestionsDocument16 pagesUSM EEE 350 Control Systems Exam QuestionsNur AfiqahNo ratings yet
- Load Frequency Control in Two Area Power System Using ANFISDocument10 pagesLoad Frequency Control in Two Area Power System Using ANFISSudhir KumarNo ratings yet
- TENET Temporal CNN With Attention For Anomaly DeteDocument6 pagesTENET Temporal CNN With Attention For Anomaly Detebran.strevNo ratings yet
- DS Unit IIIDocument34 pagesDS Unit IIIRick BombsNo ratings yet
- SQL 2Document10 pagesSQL 2Ganesh KumarNo ratings yet
- EXO HandDocument2 pagesEXO HandGaurav GuptaNo ratings yet
- Classification and Analysis of Deep Learning Applications in ConstructionDocument17 pagesClassification and Analysis of Deep Learning Applications in ConstructionMohammadreza MalekMohamadiNo ratings yet
- Predicting Article Retweets and Likes Based On The Title Using Machine LearningDocument10 pagesPredicting Article Retweets and Likes Based On The Title Using Machine LearningQiscusNewsNo ratings yet
- Tensorflow Placeholders and OptimizersDocument20 pagesTensorflow Placeholders and OptimizersDevyansh GuptaNo ratings yet
- ELL784/AIP701: Assignment 3: InstructionsDocument3 pagesELL784/AIP701: Assignment 3: Instructionslovlesh royNo ratings yet
- AdobeDocument1 pageAdobeShantam VermaNo ratings yet
- KnowledgeDocument18 pagesKnowledgeSamir SumanNo ratings yet
- Artificial Intelligence: Course Instructor: Dr. Muhammad Kamran MalikDocument15 pagesArtificial Intelligence: Course Instructor: Dr. Muhammad Kamran MalikAdeel AhmadNo ratings yet
- Project Name Spam Email Detection 1Document7 pagesProject Name Spam Email Detection 1ayeshanaseem9999No ratings yet
- Turban 02Document88 pagesTurban 02Ayu Saida ZulfaNo ratings yet
- Lecture 2 PDFDocument62 pagesLecture 2 PDFYash Sunil AhirraoNo ratings yet
- Unit 1Document36 pagesUnit 1meghanaghogareNo ratings yet
- Towards K-Means-Friendly Spaces: Simultaneous Deep Learning and ClusteringDocument12 pagesTowards K-Means-Friendly Spaces: Simultaneous Deep Learning and ClusteringTeerapat JenrungrotNo ratings yet
- Kobuki Deep Learning RobotDocument6 pagesKobuki Deep Learning Robotalvaromazuera16No ratings yet
- Robotics Club Offers Classes for 1st-10th StudentsDocument5 pagesRobotics Club Offers Classes for 1st-10th Studentsnchanchi_593984380No ratings yet
- Lecun DLHardware Isscc2019Document8 pagesLecun DLHardware Isscc2019claudiaNo ratings yet
- Survey of Explainable Artificial Intelligence Techniques For Biomedical Imaging With Deep Neural NetworksDocument29 pagesSurvey of Explainable Artificial Intelligence Techniques For Biomedical Imaging With Deep Neural Networkslenka14126No ratings yet
- Flexiv Launches New Solutions To Define The Applications of Adaptive RobotsDocument3 pagesFlexiv Launches New Solutions To Define The Applications of Adaptive RobotsPR.comNo ratings yet
- Autopilot Design Based On Robust LQR ApproachDocument5 pagesAutopilot Design Based On Robust LQR ApproachTry SusantoNo ratings yet