You might also like
- Scientific Graphing LabDocument13 pagesScientific Graphing LabAndreaNo ratings yet
- University of Auckland Department of Statistics Tamaki Campus Thursday November 20Document11 pagesUniversity of Auckland Department of Statistics Tamaki Campus Thursday November 20Anu PriyaNo ratings yet
- Hydrolysis ReactionDocument12 pagesHydrolysis Reactionkalyan555No ratings yet
- Classwork 1 Making Plots Using ExcelDocument8 pagesClasswork 1 Making Plots Using ExcelEnesEmreTaşNo ratings yet
- It Sol. Class 9Document6 pagesIt Sol. Class 9Hero AroraNo ratings yet
- Charges and Fields 2020Document5 pagesCharges and Fields 2020reynandcpcNo ratings yet
- Graphical Analysis of Data Using Microsoft Excel (2016 Version)Document9 pagesGraphical Analysis of Data Using Microsoft Excel (2016 Version)Técnicos QuímicosNo ratings yet
- Graphing Data and Curve FittingDocument5 pagesGraphing Data and Curve Fittinggrp38No ratings yet
- Learning Intentions:: by The End of This Chapter I Will Be Able ToDocument45 pagesLearning Intentions:: by The End of This Chapter I Will Be Able ToValeriaNo ratings yet
- Market Research and Forecasting Week 2 PracticalDocument5 pagesMarket Research and Forecasting Week 2 PracticalAsim Adnan EijazNo ratings yet
- Excel TipsDocument4 pagesExcel TipsJayson PintoNo ratings yet
- Statistical Quality Control ChartsDocument9 pagesStatistical Quality Control ChartsPramod AthiyarathuNo ratings yet
- Kinetics ExcelDocument14 pagesKinetics ExcelViviene SantiagoNo ratings yet
- Spreadsheet Workshop 2017Document21 pagesSpreadsheet Workshop 2017api-340521631No ratings yet
- Applying Theis Method in Excel & PPTDocument4 pagesApplying Theis Method in Excel & PPTShem BarroNo ratings yet
- Module XLC - Additional Information On Graphs in EXCEL Learning ObjectivesDocument13 pagesModule XLC - Additional Information On Graphs in EXCEL Learning ObjectivesM VetriselviNo ratings yet
- Using Excel To Plot Error BarsDocument3 pagesUsing Excel To Plot Error Bars09chengjp1No ratings yet
- Excel: Steps: Sample QuestionDocument2 pagesExcel: Steps: Sample QuestionourebooksNo ratings yet
- Three Methods for Finding Line of Best FitDocument2 pagesThree Methods for Finding Line of Best Fitkristi5683No ratings yet
- EXCEL Instructions For 20L Pang UCLADocument6 pagesEXCEL Instructions For 20L Pang UCLAdasomebodyNo ratings yet
- Funnel VolumesDocument6 pagesFunnel Volumeshani1986yeNo ratings yet
- MAT1033C - 2014-2015 - InstructorDocument86 pagesMAT1033C - 2014-2015 - InstructorHanzDucNguyen80% (15)
- Depth Map ManualDocument4 pagesDepth Map ManualJoost de BontNo ratings yet
- Mary Swanson Starbucks ProjectDocument5 pagesMary Swanson Starbucks Projectdinesh_as0% (1)
- Statistical Analysis Using Gnumeric: Entering Data and Calculating ValuesDocument18 pagesStatistical Analysis Using Gnumeric: Entering Data and Calculating ValuesandriuzNo ratings yet
- Regress 83 ADocument5 pagesRegress 83 AkNo ratings yet
- KMKMDocument5 pagesKMKMbertinNo ratings yet
- Brief Tutorial On Using Excel To Draw An X-Y PlotDocument10 pagesBrief Tutorial On Using Excel To Draw An X-Y Plotrahul_choubey_9No ratings yet
- POLYMATHDocument9 pagesPOLYMATHBigNo ratings yet
- Excel ExerciseDocument7 pagesExcel ExerciseadNo ratings yet
- Circumference and DiameterDocument2 pagesCircumference and Diameterapi-256464200No ratings yet
- CASIO Classpad 300 Calculator: A P P E N D I XDocument16 pagesCASIO Classpad 300 Calculator: A P P E N D I XŞükrü ErsoyNo ratings yet
- Kale Ida Graph TutorialDocument11 pagesKale Ida Graph TutorialMassimiliano SipalaNo ratings yet
- Plotting Experimental Data in Graphs and Error AnalysisDocument35 pagesPlotting Experimental Data in Graphs and Error AnalysisSURESH SURAGANINo ratings yet
- Excelets Tutorial PDFDocument13 pagesExcelets Tutorial PDFtayzerozNo ratings yet
- GCD HL CH6 Example11Document4 pagesGCD HL CH6 Example11Mark ChangNo ratings yet
- Auto CAD2Document10 pagesAuto CAD2Betsy L. BatistaNo ratings yet
- Data PolyDocument4 pagesData PolyjimakosjpNo ratings yet
- A NEW REPRESENTATION FOR FAST RATIONAL ARITHMETICDocument16 pagesA NEW REPRESENTATION FOR FAST RATIONAL ARITHMETICPrecious Anne Talosig-PrudencianoNo ratings yet
- 3 Square Root SpiralDocument2 pages3 Square Root SpiralSawarSagwalNo ratings yet
- Using The TI-83 Calculator: Lesson 5: Linear Equations in Slope-Intercept FormDocument28 pagesUsing The TI-83 Calculator: Lesson 5: Linear Equations in Slope-Intercept FormJodie McComiskeyNo ratings yet
- Test Bank Chapter 3 Answers and ExercisesDocument7 pagesTest Bank Chapter 3 Answers and Exercises_84mhmNo ratings yet
- Week_7_1_Excel Charts_Advance_reading (1)Document8 pagesWeek_7_1_Excel Charts_Advance_reading (1)eynullabeyliseymurNo ratings yet
- Autocad Lecture NotesDocument9 pagesAutocad Lecture NotesalbertNo ratings yet
- Creating Charts: Components of A ChartDocument18 pagesCreating Charts: Components of A ChartOSCARTAWNNo ratings yet
- Using Excel To Create An X-Bar & R ChartDocument1 pageUsing Excel To Create An X-Bar & R Chartankur panwarNo ratings yet
- LinestDocument6 pagesLinestMayankNo ratings yet
- CHARTS" Excel Charts: Types & How to Create VisualizationsDocument14 pagesCHARTS" Excel Charts: Types & How to Create VisualizationsanamicaNo ratings yet
- Michaelis-Menten Regression in Excel 2011Document11 pagesMichaelis-Menten Regression in Excel 2011zdNo ratings yet
- 3.6 Adding Data To Charts: Expand/collapse ButtonDocument6 pages3.6 Adding Data To Charts: Expand/collapse ButtonbertinNo ratings yet
- Linear Regression with TrendlineDocument3 pagesLinear Regression with TrendlineRichard HampsonNo ratings yet
- Oripa UserManual PDFDocument7 pagesOripa UserManual PDFJ. M. S-GNo ratings yet
- 121 - Experiment 01Document18 pages121 - Experiment 01Swarnav BanikNo ratings yet
- ITOM 6212 Data Visualization and Communication: CorrelationDocument54 pagesITOM 6212 Data Visualization and Communication: CorrelationGhulamNo ratings yet
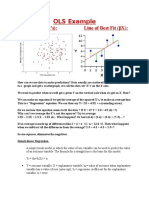
- OLS Example: Sample Data (X's) : Line of Best Fit (βX)Document3 pagesOLS Example: Sample Data (X's) : Line of Best Fit (βX)Stephen OndiekNo ratings yet
- Graphs Excel 2003Document7 pagesGraphs Excel 2003Rick ChatterjeeNo ratings yet
- Analyzing R2: Using Nmrview To Obtain R2 ValuesDocument5 pagesAnalyzing R2: Using Nmrview To Obtain R2 ValuesSam MahdiNo ratings yet
- Learn Excel Functions: Count, Countif, Sum and SumifFrom EverandLearn Excel Functions: Count, Countif, Sum and SumifRating: 5 out of 5 stars5/5 (4)
- HP Prime: Exploring IB MathsDocument42 pagesHP Prime: Exploring IB Mathsjcbp9No ratings yet
- HP DESIGNJET Poster PortfolioDocument1 pageHP DESIGNJET Poster Portfoliojcbp9No ratings yet
- HP 300s+ Scientific Calculator: Sophisticated Design Ideal For Math and Science StudentsDocument3 pagesHP 300s+ Scientific Calculator: Sophisticated Design Ideal For Math and Science StudentsgemaNo ratings yet
- Printer Datasheet PDFDocument5 pagesPrinter Datasheet PDFHope HimuyandiNo ratings yet
- Telefono Motorola D1001Document45 pagesTelefono Motorola D1001x_crowNo ratings yet
- Esoteric Osteopathy PDFDocument45 pagesEsoteric Osteopathy PDFjcbp9No ratings yet
- EMEA Print Business Insights (FY16 Q2)Document12 pagesEMEA Print Business Insights (FY16 Q2)jcbp9100% (1)
- EliminationDocument55 pagesEliminationShubham TiwariNo ratings yet
- A Survey On Demand Response Programs in Smart Grids - Pricing Methods and Optimization AlgorithmsDocument27 pagesA Survey On Demand Response Programs in Smart Grids - Pricing Methods and Optimization AlgorithmsAbdulrahman AldeekNo ratings yet
- 2021-Bateria FE AdolescentesDocument23 pages2021-Bateria FE AdolescentesISABELANo ratings yet
- RLS 8000 Technical Services ManualDocument205 pagesRLS 8000 Technical Services ManualGabrielNo ratings yet
- RMiT ApendicesDocument14 pagesRMiT ApendicesSoda JuiNo ratings yet
- Hospital Management System AbstractDocument5 pagesHospital Management System AbstractManoj Kumar MohanNo ratings yet
- ComputerDocument5 pagesComputerParidhi AgrawalNo ratings yet
- Reviews Scam, Legit or Safe Check Scamadviser PDFDocument1 pageReviews Scam, Legit or Safe Check Scamadviser PDFOghenetega udiNo ratings yet
- What's Really Happning A Forensic Analysis of Android and iOSDocument8 pagesWhat's Really Happning A Forensic Analysis of Android and iOSAfrizal AjujNo ratings yet
- Hua Hua Hua WDocument5 pagesHua Hua Hua WbiedhafiNo ratings yet
- Atmega128: 16-Bit Timer/Counter (Timer/Counter 1 and Timer/Counter3)Document32 pagesAtmega128: 16-Bit Timer/Counter (Timer/Counter 1 and Timer/Counter3)Corina SoareNo ratings yet
- 19MAT301 - Mathematics For Intelligence Systems - V: Assignment - 2Document4 pages19MAT301 - Mathematics For Intelligence Systems - V: Assignment - 2Blyss BMNo ratings yet
- Chapter 3 - Strategy Information SystemsDocument20 pagesChapter 3 - Strategy Information SystemsTrí Đức NguyễnNo ratings yet
- Engr. ABDUL-REHMAN SULTAN ResumeDocument2 pagesEngr. ABDUL-REHMAN SULTAN ResumeAbdul RehmanNo ratings yet
- ASC Nionuco - Monthly Claim Report Itel-Infinix-Tecno - Sep 2022Document50 pagesASC Nionuco - Monthly Claim Report Itel-Infinix-Tecno - Sep 2022regine vinegasNo ratings yet
- JN0-363 Q&a 264Document107 pagesJN0-363 Q&a 264Vijay Kumar Reddy50% (2)
- Tutorialspoint Examples: How To Use JSON Object in Java?Document2 pagesTutorialspoint Examples: How To Use JSON Object in Java?Khaliq Dawood BuxNo ratings yet
- Database Management System KCS 501Document2 pagesDatabase Management System KCS 501Sparsh SaxenaNo ratings yet
- Naveen Resume PDFDocument6 pagesNaveen Resume PDFNaveen ONo ratings yet
- Configuring Frame-Mode MPLS On IOSDocument71 pagesConfiguring Frame-Mode MPLS On IOSRafael A Couto CabralNo ratings yet
- 6sr41 SeriesDocument202 pages6sr41 Seriesfireza husnulNo ratings yet
- Cracking Linux Passwords with John the RipperDocument3 pagesCracking Linux Passwords with John the RipperRoman HacksNo ratings yet
- Name List Correction 1Document11 pagesName List Correction 1THIRUNAVUKKARASU ENo ratings yet
- Introduction To IBISDocument9 pagesIntroduction To IBISabhishekmath123No ratings yet
- JD-OPENEDGES-Chief Architect - Rev.1 RJDocument2 pagesJD-OPENEDGES-Chief Architect - Rev.1 RJPeterNo ratings yet
- Frame Analysis OutputDocument14 pagesFrame Analysis OutputMary Joy AzonNo ratings yet
- Swami - SCM: Devops EngineerDocument3 pagesSwami - SCM: Devops EngineerAlbacore EnterprisesNo ratings yet
- Activity Guide - Unreasonable Time - Unit 6 Lesson 3Document2 pagesActivity Guide - Unreasonable Time - Unit 6 Lesson 3gabriel cruzNo ratings yet
- GIS Fundamentals 7e ContentsDocument9 pagesGIS Fundamentals 7e ContentsJose AraujoNo ratings yet
- Baixa Ae MalucoDocument7 pagesBaixa Ae MalucoSrCleaw 666No ratings yet