You might also like
- Software Testing Is A Process of Verifying and Validating That ADocument61 pagesSoftware Testing Is A Process of Verifying and Validating That Asv0093066No ratings yet
- Automated Software Testing Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandAutomated Software Testing Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Overview of Software TestingDocument12 pagesOverview of Software TestingBhagyashree SahooNo ratings yet
- Empower 3 EU Annex 11 Compliance Assessment Rev1 November 2019Document12 pagesEmpower 3 EU Annex 11 Compliance Assessment Rev1 November 2019Nur AcarNo ratings yet
- CSV SopDocument1 pageCSV SopjeetNo ratings yet
- Aplicabilidad 21CFR11Document6 pagesAplicabilidad 21CFR11Aydee RojasNo ratings yet
- MedTech Europe Clinical Evidence Requirements For CE Certification Ebook 2020Document84 pagesMedTech Europe Clinical Evidence Requirements For CE Certification Ebook 2020Ankara GücüNo ratings yet
- VAL 135 Risk Assessment For Computer Validation Systems Sample - SandraDocument3 pagesVAL 135 Risk Assessment For Computer Validation Systems Sample - SandraSandra Silva100% (1)
- Software Testing 061510-001Document76 pagesSoftware Testing 061510-001DkvkarmaNo ratings yet
- Computer System ValidationDocument10 pagesComputer System ValidationRudra RahmanNo ratings yet
- Unit Test PlanDocument2 pagesUnit Test Planprabhakar9114239No ratings yet
- Software Testing Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandSoftware Testing Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Computerised System ValidationDocument41 pagesComputerised System Validationmonsepack100% (2)
- Software Development Maintenance PlanDocument5 pagesSoftware Development Maintenance PlanAlexNo ratings yet
- Excel Spreadsheet Validation SpecificationDocument8 pagesExcel Spreadsheet Validation Specificationjohn DevinsNo ratings yet
- IEC 62304 Medical Device Software Life CycleDocument75 pagesIEC 62304 Medical Device Software Life Cyclesukeerthi bmeNo ratings yet
- Understanding CSV User RequirementsDocument27 pagesUnderstanding CSV User RequirementsSivaramakrishna Markandeya Gupta0% (1)
- A Study of Computerized System ValidationDocument12 pagesA Study of Computerized System ValidationTenzin Tashi100% (1)
- NASA: Software Quality Assurance PlanDocument27 pagesNASA: Software Quality Assurance PlanNASAdocumentsNo ratings yet
- 5991-8176EN Demystifying Software Validation WhitepaperDocument7 pages5991-8176EN Demystifying Software Validation WhitepaperMykolaNo ratings yet
- Comparison of FDA Part 11 and EU Annex 11Document5 pagesComparison of FDA Part 11 and EU Annex 11marco_fmNo ratings yet
- Computer System Validation (CSV) : Comparisons Between (GMP VS CGMP, GLP VS GCP, 21 CFR PART 11 VS EU 11)Document4 pagesComputer System Validation (CSV) : Comparisons Between (GMP VS CGMP, GLP VS GCP, 21 CFR PART 11 VS EU 11)T 1No ratings yet
- Data and Database Integrity TestingDocument3 pagesData and Database Integrity TestingMounir Ben MohamedNo ratings yet
- 5 GAMP5 PharmOut 2008-07-11Document43 pages5 GAMP5 PharmOut 2008-07-11Rajiv Bhala100% (1)
- Clinical Evaluation Report for Compressor NebulizersDocument55 pagesClinical Evaluation Report for Compressor Nebulizersdon aNo ratings yet
- Computer System Validation Risk Assessment ToolDocument3 pagesComputer System Validation Risk Assessment Toolcpkakope100% (1)
- USDE - Software Verification and Validation Proc - PNNL-17772Document28 pagesUSDE - Software Verification and Validation Proc - PNNL-17772thu2miNo ratings yet
- Software Quality Assurance Testing Software’s and ToolsDocument12 pagesSoftware Quality Assurance Testing Software’s and Toolsعلی احمدNo ratings yet
- LIMS For Lasers 2015 User ManualDocument188 pagesLIMS For Lasers 2015 User Manualcharles_0814No ratings yet
- Computerized System Validation Master Plan TemplateDocument11 pagesComputerized System Validation Master Plan Templateعبدالعزيز بدرNo ratings yet
- Validate SAP S/4 HANA SystemDocument5 pagesValidate SAP S/4 HANA SystemSourav Ghosh DastidarNo ratings yet
- GAMP 5 Categories, V Model, 21 CFR Part 11, EU Annex 11 - AmpleLogicDocument7 pagesGAMP 5 Categories, V Model, 21 CFR Part 11, EU Annex 11 - AmpleLogicArjun TalwakarNo ratings yet
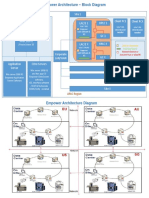
- Empower ArchitectureDocument2 pagesEmpower ArchitecturePinaki ChakrabortyNo ratings yet
- Software Testing FundamentalsDocument8 pagesSoftware Testing FundamentalsSumit RajputNo ratings yet
- Caliber Ilims Features Flipbook PDF - CompressDocument34 pagesCaliber Ilims Features Flipbook PDF - CompressTanaspohorn KaokaewNo ratings yet
- Smoke Vs SanityDocument7 pagesSmoke Vs SanityAmodNo ratings yet
- Sample - VAL004 Req For Val Plans Protocols 7 Mar 06Document3 pagesSample - VAL004 Req For Val Plans Protocols 7 Mar 06nagarajs50No ratings yet
- Electronic Data Backup SOPDocument8 pagesElectronic Data Backup SOPMLastTryNo ratings yet
- Test Environment Setup and ExecutionDocument5 pagesTest Environment Setup and ExecutionAli RazaNo ratings yet
- GS002-T02 Computer System Validation Checklist v4.0Document2 pagesGS002-T02 Computer System Validation Checklist v4.0prakashNo ratings yet
- Empower 3 21 CFR Part 11 Compliance Assessment RevA November 2019Document14 pagesEmpower 3 21 CFR Part 11 Compliance Assessment RevA November 2019Nur AcarNo ratings yet
- CSV Gamp 5Document37 pagesCSV Gamp 5Abdou SoudakiNo ratings yet
- Empower 3Document4 pagesEmpower 3amgranadosvNo ratings yet
- Minitab-2003-Software ValidationDocument11 pagesMinitab-2003-Software ValidationGonzalo_Rojas_VerenzNo ratings yet
- ECA Computerised System Validation GAMP 5 ApproachDocument6 pagesECA Computerised System Validation GAMP 5 ApproachHanan NoussaNo ratings yet
- IEC 62304:2006 Amd 1:2015: Primary Lifecycle ProcesessDocument4 pagesIEC 62304:2006 Amd 1:2015: Primary Lifecycle ProcesessBhavana KrishnapriyaNo ratings yet
- Software Assessment FormDocument4 pagesSoftware Assessment FormCathleen Ancheta NavarroNo ratings yet
- Data Integrity ChecklistDocument12 pagesData Integrity ChecklistprakashNo ratings yet
- Best Practices in Software IV&V - Pradeep OakDocument27 pagesBest Practices in Software IV&V - Pradeep OakPradeep OakNo ratings yet
- V&V White PaperDocument12 pagesV&V White PaperRichard CarsonNo ratings yet
- Types of Testing: Presented byDocument27 pagesTypes of Testing: Presented bykishorenagaNo ratings yet
- Test Strategy for <Product/Project name> v<VersionDocument11 pagesTest Strategy for <Product/Project name> v<VersionshygokNo ratings yet
- Overview of Validation Documents and ProjectsDocument5 pagesOverview of Validation Documents and ProjectsMD Fahad MiajiNo ratings yet
- 1 - Introduction To Computerized Systems Validation - For ReviewDocument41 pages1 - Introduction To Computerized Systems Validation - For Reviewpate malabananNo ratings yet
- Statistical Methods for Evaluating Safety in Medical Product DevelopmentFrom EverandStatistical Methods for Evaluating Safety in Medical Product DevelopmentA. Lawrence GouldNo ratings yet
- Testing: Software Verification and Validation Swhat Is Verification?Document24 pagesTesting: Software Verification and Validation Swhat Is Verification?EDSYL JHON SARAGANo ratings yet
- NET101 Week 12 Wireless Technology2Document22 pagesNET101 Week 12 Wireless Technology2EDSYL JHON SARAGANo ratings yet
- Art History TopicsDocument1 pageArt History TopicsEDSYL JHON SARAGANo ratings yet
- Testing: Software Verification and Validation Swhat Is Verification?Document24 pagesTesting: Software Verification and Validation Swhat Is Verification?EDSYL JHON SARAGANo ratings yet
- NET101 Week 12 Wireless Technology2Document22 pagesNET101 Week 12 Wireless Technology2EDSYL JHON SARAGANo ratings yet
- Eastern Art History The Evolution of Asian Art: RENAISSANCE (C. 1350 - 1600)Document1 pageEastern Art History The Evolution of Asian Art: RENAISSANCE (C. 1350 - 1600)EDSYL JHON SARAGANo ratings yet
- NET101 Week 12 Wireless Technology2Document22 pagesNET101 Week 12 Wireless Technology2EDSYL JHON SARAGANo ratings yet
- Art History TopicsDocument1 pageArt History TopicsEDSYL JHON SARAGANo ratings yet
- Art Subject For Elementary - 2nd Grade - Visual Arts by SlidesgoDocument56 pagesArt Subject For Elementary - 2nd Grade - Visual Arts by SlidesgonopriansyahNo ratings yet
- Art Subject For Elementary - 2nd Grade - Visual Arts by SlidesgoDocument56 pagesArt Subject For Elementary - 2nd Grade - Visual Arts by SlidesgonopriansyahNo ratings yet
- CicloviasDocument53 pagesCicloviasMari EstradaNo ratings yet
- Design A Newsletter by SlidesgoDocument48 pagesDesign A Newsletter by SlidesgoEDSYL JHON SARAGANo ratings yet
- Design A Newsletter by SlidesgoDocument48 pagesDesign A Newsletter by SlidesgoEDSYL JHON SARAGANo ratings yet
- CicloviasDocument53 pagesCicloviasMari EstradaNo ratings yet
- Design A Newsletter by SlidesgoDocument48 pagesDesign A Newsletter by SlidesgoEDSYL JHON SARAGANo ratings yet
- CicloviasDocument53 pagesCicloviasMari EstradaNo ratings yet
- Art Subject For Elementary - 2nd Grade - Visual Arts by SlidesgoDocument56 pagesArt Subject For Elementary - 2nd Grade - Visual Arts by SlidesgonopriansyahNo ratings yet
- Design A Newsletter by SlidesgoDocument48 pagesDesign A Newsletter by SlidesgoEDSYL JHON SARAGANo ratings yet
- CicloviasDocument53 pagesCicloviasMari EstradaNo ratings yet
- Pokok Bahasan 04-1 ER ModelingDocument57 pagesPokok Bahasan 04-1 ER Modelingproddevel 69No ratings yet
- DC Inverter VRF System Service MANUAL (R410A)Document173 pagesDC Inverter VRF System Service MANUAL (R410A)James RichardsonNo ratings yet
- A-008550-1624688646968-80386-Unit 34 - System Analysis and Design.Document103 pagesA-008550-1624688646968-80386-Unit 34 - System Analysis and Design.Hansi Ranasinghe100% (1)
- System RequirementsDocument195 pagesSystem RequirementsMahesh MaeeNo ratings yet
- Google Certifications and Coursera Specialization Courses by InfosysDocument5 pagesGoogle Certifications and Coursera Specialization Courses by InfosysSong Covers By DTNo ratings yet
- Aao GK 2022Document14 pagesAao GK 2022achikauhkauh15No ratings yet
- 3D Video and Free Viewpoint Video - Technologies, Applications and Mpeg StandardsDocument4 pages3D Video and Free Viewpoint Video - Technologies, Applications and Mpeg StandardsKorneychuk AnnaNo ratings yet
- SEW Eurodrive EMS Systems PDFDocument15 pagesSEW Eurodrive EMS Systems PDFRikardo AlexisNo ratings yet
- 3-Chapter - 10 - RTOS - Task CommunicationDocument9 pages3-Chapter - 10 - RTOS - Task CommunicationBhuvana GowdaNo ratings yet
- GNSS-Implementation AppNote (UBX-13001849)Document78 pagesGNSS-Implementation AppNote (UBX-13001849)aj4fall086050No ratings yet
- Week 9 Lecture Material PDFDocument97 pagesWeek 9 Lecture Material PDFMerugu spoorthiNo ratings yet
- Mohammed Seba e I CVDocument5 pagesMohammed Seba e I CVMohammed El SebaeiNo ratings yet
- Xiao Han Zeng ProfileDocument3 pagesXiao Han Zeng ProfilesefdeniNo ratings yet
- MacOs Scan To SMB On Konica MinoltaDocument4 pagesMacOs Scan To SMB On Konica Minoltabitt69No ratings yet
- VKIT-LFM2 HPLC Flowmeter - Datasheet - v1Document2 pagesVKIT-LFM2 HPLC Flowmeter - Datasheet - v1Cotizacion CisaNo ratings yet
- SQLiteDocument8 pagesSQLiteAmitNo ratings yet
- Malware Detection Using Statistical Analysys Byte Level File ContentDocument9 pagesMalware Detection Using Statistical Analysys Byte Level File Contentricksant2003No ratings yet
- South Galaxy G1 Datasheet 1Document2 pagesSouth Galaxy G1 Datasheet 1Teguh Firman HadiNo ratings yet
- Two Day GCC WorkshopDocument2 pagesTwo Day GCC WorkshopNagappan GovindarajanNo ratings yet
- TMV Trading PricelistDocument8 pagesTMV Trading Pricelistronald s. rodrigoNo ratings yet
- Alcohol Detection ThesisDocument34 pagesAlcohol Detection ThesisrNo ratings yet
- 26 February-4 March 2011Document24 pages26 February-4 March 2011pratidinNo ratings yet
- Intro q2 AlteraDocument196 pagesIntro q2 AlterahvillafuertebNo ratings yet
- DLCC Legacy SW Catalog CommercialDocument66 pagesDLCC Legacy SW Catalog CommercialnoychoHNo ratings yet
- Error DetailsDocument3 pagesError Detailsnaresh kumarNo ratings yet
- Test Questions | Recruitment Test | AFGT02Document26 pagesTest Questions | Recruitment Test | AFGT02Ammar Farooq Khan80% (5)
- NIELIT Jammu Industrial Training on PythonDocument24 pagesNIELIT Jammu Industrial Training on PythonAmrit MehtaNo ratings yet
- Universiti Teknologi Malaysia: Joei Ong Suk MeiDocument19 pagesUniversiti Teknologi Malaysia: Joei Ong Suk MeiJoey OngNo ratings yet
- Bad Debt ConfigrationDocument4 pagesBad Debt Configrationsudershan9No ratings yet
- AWS Course OutlineDocument5 pagesAWS Course Outlineshahebaz sayedNo ratings yet