You might also like
- Andromeda Council About The 4th DimensionDocument11 pagesAndromeda Council About The 4th DimensionWonderlust100% (1)
- What is a Sample SizeDocument5 pagesWhat is a Sample Sizerigan100% (1)
- Determining The Sample Size (Continuous Data)Document4 pagesDetermining The Sample Size (Continuous Data)Surbhi Jain100% (1)
- Statistical Tests and Confidence Intervals in Data AnalysisDocument77 pagesStatistical Tests and Confidence Intervals in Data AnalysisAndrina Ortillano100% (2)
- Confidence IntervalsDocument12 pagesConfidence IntervalsNeko PlusNo ratings yet
- MCQs on PharmacologyDocument101 pagesMCQs on PharmacologyMohammad Rashid88% (8)
- LETTER OF AUTHORIZATION CREDO INVEST DownloadDocument1 pageLETTER OF AUTHORIZATION CREDO INVEST DownloadEsteban Enrique Posan BalcazarNo ratings yet
- MIZAT PWHT Procedure Ensures Welded Joints Meet StandardsDocument9 pagesMIZAT PWHT Procedure Ensures Welded Joints Meet StandardsM. R. Shahnawaz KhanNo ratings yet
- 7 - NIBL - G.R. No. L-15380 Wan V Kim - DigestDocument1 page7 - NIBL - G.R. No. L-15380 Wan V Kim - DigestOjie SantillanNo ratings yet
- Confidence IntervalsDocument42 pagesConfidence IntervalsBlendie V. Quiban Jr.100% (1)
- Confidence Interval Sample SizeDocument6 pagesConfidence Interval Sample SizeegcaldwellNo ratings yet
- 6 Confidence Intervals 6.03 CI For Mean With Unknown Population Standard DeviationDocument2 pages6 Confidence Intervals 6.03 CI For Mean With Unknown Population Standard Deviationedinhojr10No ratings yet
- Confidence Intervals for the Sample Mean with Known σDocument7 pagesConfidence Intervals for the Sample Mean with Known σaman_nsuNo ratings yet
- The Sampling DistributionDocument4 pagesThe Sampling DistributionNiharika SinghNo ratings yet
- ZTestDocument2 pagesZTestcoxeri8608No ratings yet
- 1 Review of Basic Concepts - Interval EstimationDocument4 pages1 Review of Basic Concepts - Interval EstimationTiffany OrNo ratings yet
- Statistics QuestionsDocument7 pagesStatistics QuestionsAakriti JainNo ratings yet
- CI For A ProportionDocument24 pagesCI For A ProportionkokleongNo ratings yet
- 6.02 CI For Mean With Known Population Standard Deviation: 6 Confidence IntervalsDocument2 pages6.02 CI For Mean With Known Population Standard Deviation: 6 Confidence Intervalsedinhojr10No ratings yet
- Chapter 5 SlidesDocument48 pagesChapter 5 SlidesParth Rajesh ShethNo ratings yet
- Lecture 4 Estimating From A Sample Sample Mean and Confidence Intervals Upload 2Document22 pagesLecture 4 Estimating From A Sample Sample Mean and Confidence Intervals Upload 2mussy001No ratings yet
- Sample SizeDocument5 pagesSample SizeChe GowthamNo ratings yet
- Skittles 2 DaneDocument3 pagesSkittles 2 Daneapi-253137548No ratings yet
- Spss Training MaterialDocument117 pagesSpss Training MaterialSteve ElroyNo ratings yet
- Chapter 5 - Research (1) NewDocument49 pagesChapter 5 - Research (1) NewkarolinNo ratings yet
- Sample Size CalculatorDocument1 pageSample Size CalculatorTania OvelinaNo ratings yet
- Introduction To GraphPad PrismDocument33 pagesIntroduction To GraphPad PrismHening Tirta KusumawardaniNo ratings yet
- BA Module 02 - 2.4 - Confidence IntervalDocument41 pagesBA Module 02 - 2.4 - Confidence IntervalScarfaceXXXNo ratings yet
- Understanding Common Misconceptions About P-ValuesDocument20 pagesUnderstanding Common Misconceptions About P-Valuesmech2007No ratings yet
- Descriptive Statistics - SPSS Annotated OutputDocument13 pagesDescriptive Statistics - SPSS Annotated OutputLAM NGUYEN VO PHINo ratings yet
- How To Find Confidence IntervalDocument5 pagesHow To Find Confidence Intervalapi-126876773No ratings yet
- 6.04 CI For Proportion: 6 Confidence IntervalsDocument2 pages6.04 CI For Proportion: 6 Confidence Intervalsedinhojr10No ratings yet
- How To Calculate Confidence IntervalDocument3 pagesHow To Calculate Confidence Intervalreddy iibfNo ratings yet
- Data AnlalysisDocument6 pagesData Anlalysisرجب جبNo ratings yet
- REPORTING ReliabilityDocument5 pagesREPORTING ReliabilityCheasca AbellarNo ratings yet
- Anal Chem - 458.309A - Week 3-2Document35 pagesAnal Chem - 458.309A - Week 3-2Dark invader ytNo ratings yet
- Confidence Interval For The Mean: Point and Interval EstimatesDocument11 pagesConfidence Interval For The Mean: Point and Interval EstimatesAmarnathMaitiNo ratings yet
- Transcript (1) UpgradDocument32 pagesTranscript (1) UpgradJUSTIN THOMASNo ratings yet
- Assignment Name - Machine Learning Basics Problem StatementDocument4 pagesAssignment Name - Machine Learning Basics Problem StatementMubassir SurveNo ratings yet
- Session TranscriptDocument32 pagesSession TranscriptJUSTIN THOMASNo ratings yet
- 7.02 Test About ProportionDocument2 pages7.02 Test About ProportionBi ShengNo ratings yet
- BSCHAPTER - (Theory of Estimations)Document39 pagesBSCHAPTER - (Theory of Estimations)kunal kabraNo ratings yet
- 03 Hme 712 Week 7 Post Regression Tests For MLR Audio TranscriptDocument2 pages03 Hme 712 Week 7 Post Regression Tests For MLR Audio Transcriptjackbane69No ratings yet
- Lect 5. SMG 09312 Sample SpaceDocument16 pagesLect 5. SMG 09312 Sample Spacecalvinnelson0911No ratings yet
- Estimation and Confidence LimitsDocument6 pagesEstimation and Confidence LimitsjellylexiNo ratings yet
- DR - Arfan 3 STD Error - Estimation of CI - V1Document29 pagesDR - Arfan 3 STD Error - Estimation of CI - V1AHMED .KNo ratings yet
- Chapter 4 StatisticsDocument11 pagesChapter 4 Statisticszaheer abbasNo ratings yet
- How Do We Select A Sample Size When Sampling A Small PopulationDocument1 pageHow Do We Select A Sample Size When Sampling A Small PopulationByaruhanga EmmanuelNo ratings yet
- Student's T DistributionDocument3 pagesStudent's T DistributionboNo ratings yet
- cochran's formulaDocument10 pagescochran's formulaAmythize ChemadianNo ratings yet
- Lecture Wk08Document93 pagesLecture Wk08dana chuaNo ratings yet
- Hypothesis Testing in Machine Learning Using Python - by Yogesh Agrawal - 151413Document15 pagesHypothesis Testing in Machine Learning Using Python - by Yogesh Agrawal - 151413airplaneunderwaterNo ratings yet
- 4.1 Point and Interval EstimationDocument30 pages4.1 Point and Interval EstimationShamuel AlasNo ratings yet
- Binomial Distributions For Sample CountsDocument38 pagesBinomial Distributions For Sample CountsVishnu VenugopalNo ratings yet
- The Uncertainty of The Mean: 11.1 Using A Set'S Mean As A "Best Guess"Document0 pagesThe Uncertainty of The Mean: 11.1 Using A Set'S Mean As A "Best Guess"chuj_3210No ratings yet
- Quantitative Reasoning NotesDocument4 pagesQuantitative Reasoning NotesHéctor Flores100% (1)
- Chapter 8 Confidence IntervalDocument14 pagesChapter 8 Confidence IntervalFadli Bakhtiar AjiNo ratings yet
- 6.1 Confidence Intervals For The Mean (Large Samples)Document30 pages6.1 Confidence Intervals For The Mean (Large Samples)Vinícius BastosNo ratings yet
- Uncertainty in MeasurementsDocument5 pagesUncertainty in MeasurementsMakeedaNo ratings yet
- Error Analysis, W011Document12 pagesError Analysis, W011Evan KeastNo ratings yet
- Normal Distributions Bell Curve Definition Word ProblemsDocument14 pagesNormal Distributions Bell Curve Definition Word ProblemsCalvin YeohNo ratings yet
- Regression AnalysisDocument9 pagesRegression Analysisawidyas100% (1)
- Slovin and Crochans FormulaDocument4 pagesSlovin and Crochans FormulaPRETTY LYCA GAMALENo ratings yet
- DataScience Interview Master DocDocument120 pagesDataScience Interview Master DocpriyankaNo ratings yet
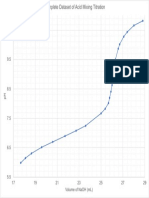
- Picture of Full GraphDocument1 pagePicture of Full Graphsamantha davidsonNo ratings yet
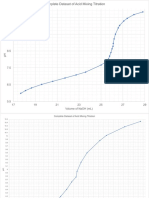
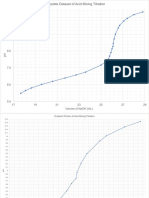
- Complete Dataset of Acid Mixing Titration Graph AnalysisDocument3 pagesComplete Dataset of Acid Mixing Titration Graph Analysissamantha davidsonNo ratings yet
- Carbonate LabDocument6 pagesCarbonate Labsamantha davidsonNo ratings yet
- HTST 200 Lecture 06 The Industrial RevolutionDocument56 pagesHTST 200 Lecture 06 The Industrial Revolutionsamantha davidsonNo ratings yet
- F21 351 L01 Lec 19 PDFDocument9 pagesF21 351 L01 Lec 19 PDFsamantha davidsonNo ratings yet
- Gender Performance Rules ExplainedDocument5 pagesGender Performance Rules Explainedsamantha davidsonNo ratings yet
- F21 351 L01 Lec 17 PDFDocument9 pagesF21 351 L01 Lec 17 PDFsamantha davidsonNo ratings yet
- F21 351 L01 Lec 26 Finish ReactionsDocument8 pagesF21 351 L01 Lec 26 Finish Reactionssamantha davidsonNo ratings yet
- Gender Chapter 2 NOTESDocument3 pagesGender Chapter 2 NOTESsamantha davidsonNo ratings yet
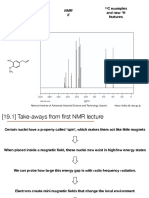
- Tour Across the Infrared SpectrumDocument9 pagesTour Across the Infrared Spectrumsamantha davidsonNo ratings yet
- Nucleophilic Substitution and Elimination Reactions GuideDocument10 pagesNucleophilic Substitution and Elimination Reactions Guidesamantha davidsonNo ratings yet
- Soci 303 Notes From PresentationsDocument30 pagesSoci 303 Notes From Presentationssamantha davidsonNo ratings yet
- Boilingpoint PDFDocument10 pagesBoilingpoint PDFAkshayNo ratings yet
- Complete Dataset of Acid Mixing Titration Endpoint AnalysisDocument3 pagesComplete Dataset of Acid Mixing Titration Endpoint Analysissamantha davidsonNo ratings yet
- Gender Textbook Key TerminologyDocument4 pagesGender Textbook Key Terminologysamantha davidsonNo ratings yet
- ExtractionDocument3 pagesExtractionsamantha davidsonNo ratings yet
- Fundamentos de Rota VaporDocument2 pagesFundamentos de Rota VaporEsau Alberto Morales TNo ratings yet
- Principles of Microeconomics: Powerpoint Presentations ForDocument48 pagesPrinciples of Microeconomics: Powerpoint Presentations Forsamantha davidsonNo ratings yet
- W2 Lect 04p-MergedDocument79 pagesW2 Lect 04p-Mergedsamantha davidsonNo ratings yet
- Formula Sheet: Olutions To A Quadratic Equation NtegralsDocument2 pagesFormula Sheet: Olutions To A Quadratic Equation Ntegralssamantha davidsonNo ratings yet
- Simbio Lab 1Document11 pagesSimbio Lab 1samantha davidsonNo ratings yet
- Tidal PoolsDocument11 pagesTidal Poolssamantha davidsonNo ratings yet
- Principles of Microeconomics: Powerpoint Presentations ForDocument51 pagesPrinciples of Microeconomics: Powerpoint Presentations Forsamantha davidsonNo ratings yet
- Econ 201 (L02) Review List - Midterm Fall 2020Document10 pagesEcon 201 (L02) Review List - Midterm Fall 2020samantha davidsonNo ratings yet
- T 10Document17 pagesT 10samantha davidsonNo ratings yet
- Bio 241 Classification QuizletDocument2 pagesBio 241 Classification Quizletsamantha davidsonNo ratings yet
- Atom Hybridization None SP SP SP SP DSP D C C C CDocument2 pagesAtom Hybridization None SP SP SP SP DSP D C C C Csamantha davidsonNo ratings yet
- Question 2 TemplateDocument2 pagesQuestion 2 Templatesamantha davidsonNo ratings yet
- How cells convert food energy into ATP via cellular respirationDocument18 pagesHow cells convert food energy into ATP via cellular respirationsamantha davidsonNo ratings yet
- Inner Unit EstimateDocument35 pagesInner Unit EstimateMir MoNo ratings yet
- Assessmentof Safety Cultureand Maturityin Mining Environments Caseof Njuli QuarryDocument12 pagesAssessmentof Safety Cultureand Maturityin Mining Environments Caseof Njuli QuarryAbdurrohman AabNo ratings yet
- Red Lion Edict-97 - Manual PDFDocument282 pagesRed Lion Edict-97 - Manual PDFnaminalatrukNo ratings yet
- JMPRTraininga I5545e PDFDocument500 pagesJMPRTraininga I5545e PDFmvptoxNo ratings yet
- Frequently Asked Questions About Ailunce HD1: Where Can Find HD1 Software & Firmware?Document5 pagesFrequently Asked Questions About Ailunce HD1: Where Can Find HD1 Software & Firmware?Eric Contra Color0% (1)
- BSNL TrainingDocument25 pagesBSNL TrainingAditya Dandotia68% (19)
- Satisfaction ExtraDocument2 pagesSatisfaction ExtraFazir AzlanNo ratings yet
- Safety Data Sheet: 1. Identification of The Substance/preparation and of The Company/undertakingDocument4 pagesSafety Data Sheet: 1. Identification of The Substance/preparation and of The Company/undertakingBalasubramanian AnanthNo ratings yet
- St. Anthony College Calapan City Syllabus: Course DescriptionDocument6 pagesSt. Anthony College Calapan City Syllabus: Course DescriptionAce HorladorNo ratings yet
- St. Francis de Sales Sr. Sec. School, Gangapur CityDocument12 pagesSt. Francis de Sales Sr. Sec. School, Gangapur CityArtificial GammerNo ratings yet
- Contemporary Issue in StrategyDocument13 pagesContemporary Issue in Strategypatrick wafulaNo ratings yet
- Covid 19 PDFDocument117 pagesCovid 19 PDFvicky anandNo ratings yet
- What Is Robotic Process Automation?: ERP SystemDocument5 pagesWhat Is Robotic Process Automation?: ERP SystemAna BoboceaNo ratings yet
- Spare Parts List: WarningDocument5 pagesSpare Parts List: WarningÃbdøū Èqúípmeńť MédîcàlNo ratings yet
- 2 Both Texts, and Then Answer Question 1 On The Question Paper. Text A: Esports in The Olympic Games?Document2 pages2 Both Texts, and Then Answer Question 1 On The Question Paper. Text A: Esports in The Olympic Games?...No ratings yet
- Mark Wildon - Representation Theory of The Symmetric Group (Lecture Notes) (2015)Document34 pagesMark Wildon - Representation Theory of The Symmetric Group (Lecture Notes) (2015)Satyam Agrahari0% (1)
- Radio Codes and ConventionsDocument2 pagesRadio Codes and Conventionsapi-570661298No ratings yet
- The Joint Force Commander's Guide To Cyberspace Operations: by Brett T. WilliamsDocument8 pagesThe Joint Force Commander's Guide To Cyberspace Operations: by Brett T. Williamsأريزا لويسNo ratings yet
- GMS175CSDocument4 pagesGMS175CScorsini999No ratings yet
- Thesis Hakonen Petri - Detecting Insider ThreatsDocument72 pagesThesis Hakonen Petri - Detecting Insider ThreatsalexandreppinheiroNo ratings yet
- Christos A. Ioannou & Dimitrios A. Ioannou, Greece: Victim of Excessive Austerity or of Severe "Dutch Disease"? June 2013Document26 pagesChristos A. Ioannou & Dimitrios A. Ioannou, Greece: Victim of Excessive Austerity or of Severe "Dutch Disease"? June 2013Christos A IoannouNo ratings yet
- YlideDocument13 pagesYlidePharaoh talk to youNo ratings yet
- Climate Change Survivor GameDocument22 pagesClimate Change Survivor Game许凉发No ratings yet
- Neutron SourcesDocument64 pagesNeutron SourcesJenodi100% (1)
- 02 1 Cohen Sutherland PDFDocument3 pages02 1 Cohen Sutherland PDFSarra AnitaNo ratings yet