You might also like
- CSCP 2022 Module 7 - ApicsDocument70 pagesCSCP 2022 Module 7 - Apicssaifeddine100% (3)
- 294 Lab ReportDocument10 pages294 Lab ReportDhanush Mahendran100% (1)
- Rsa Archer Information Security Management Systems (ISMS) Ds LetterDocument4 pagesRsa Archer Information Security Management Systems (ISMS) Ds LetterSteep BesoinNo ratings yet
- SRS - BodyDocument19 pagesSRS - BodyjohnrasquinhaNo ratings yet
- The Towers PerrinDocument11 pagesThe Towers PerrinGM19690% (1)
- 2 ADA Cluster AnalysisDocument12 pages2 ADA Cluster AnalysisAshNo ratings yet
- Advanced Topics in Environmental Health and Air Pollution Case Studies PDFDocument482 pagesAdvanced Topics in Environmental Health and Air Pollution Case Studies PDFLeandro FeitosaNo ratings yet
- Online Collective Action - Dynamics of The Crowd in Social Media-Springer-Verlag PDFDocument243 pagesOnline Collective Action - Dynamics of The Crowd in Social Media-Springer-Verlag PDFRashid Bensiamar100% (1)
- Research ParadigmsDocument25 pagesResearch ParadigmsRavika Hafizi100% (1)
- BSBINS603 - Assessment Task 2Document18 pagesBSBINS603 - Assessment Task 2Skylar Stella83% (6)
- Kuliah 1 - Struktur Data SpasialDocument40 pagesKuliah 1 - Struktur Data SpasialIksal YanuarsyahNo ratings yet
- Using R For Basic Spatial AnalysisDocument48 pagesUsing R For Basic Spatial AnalysisSteep BesoinNo ratings yet
- 2 Pengenalan GeostatistikDocument59 pages2 Pengenalan GeostatistikSAEF MAULANA DZIKRINo ratings yet
- Bio 160 - Exercise No 1 - StatisticsDocument9 pagesBio 160 - Exercise No 1 - StatisticsJunica MarcosNo ratings yet
- Noise Reduction in Hyperspectral Imagery: Overview and ApplicationDocument28 pagesNoise Reduction in Hyperspectral Imagery: Overview and Applicationjavad saadatNo ratings yet
- Scale Invariant Feature Transform: Tony LindebergDocument18 pagesScale Invariant Feature Transform: Tony LindebergVeronica NitaNo ratings yet
- 11 Upper Bound Resonances Anosov FlowsDocument40 pages11 Upper Bound Resonances Anosov FlowsFrédéric FaureNo ratings yet
- Fuzzy Proximity SearchsDocument9 pagesFuzzy Proximity SearchsSimon WistowNo ratings yet
- An Improved Edge Detection in SAR Color ImagesDocument5 pagesAn Improved Edge Detection in SAR Color ImagesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Scholar Pedia SiftDocument18 pagesScholar Pedia SiftHarsh TagotraNo ratings yet
- Acknowledgement: Sift:Scale Invariant Feature TransformDocument25 pagesAcknowledgement: Sift:Scale Invariant Feature TransformSawan Singh MaharaNo ratings yet
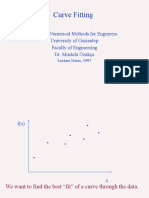
- Curve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaDocument171 pagesCurve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaAbdullah Emirhan AydınNo ratings yet
- Sampling & Sampling DistributionsDocument26 pagesSampling & Sampling DistributionsVarsha PeriwalNo ratings yet
- Remote Sensing Mapping Techniques: Magaly Koch, PHDDocument34 pagesRemote Sensing Mapping Techniques: Magaly Koch, PHDArdhia EvaNo ratings yet
- EGN 3060c: Introduction To Robotics: Background To Planning Planning As SearchDocument47 pagesEGN 3060c: Introduction To Robotics: Background To Planning Planning As SearchManny HdezNo ratings yet
- MTH-263 Probability Theory and Random VariablesDocument18 pagesMTH-263 Probability Theory and Random VariablesShakoor UllahNo ratings yet
- Sift PreprintDocument28 pagesSift PreprintRicardo Gómez GómezNo ratings yet
- MorphoTools2 TutorialDocument42 pagesMorphoTools2 Tutorialjhonny sarmientoNo ratings yet
- Survey LoujiayiDocument57 pagesSurvey LoujiayiHikari AoiNo ratings yet
- Range-Free Localization Using Expected Hop Progress in Wireless Sensor Networks"Document31 pagesRange-Free Localization Using Expected Hop Progress in Wireless Sensor Networks"pradnyuNo ratings yet
- Automated System For Criminal Identification Using Fingerprint Clue Found at Crime SceneDocument10 pagesAutomated System For Criminal Identification Using Fingerprint Clue Found at Crime SceneInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Optimal Placement of Sensors For Trilateration: Regular Lattices Vs Metaheuristic SolutionsDocument9 pagesOptimal Placement of Sensors For Trilateration: Regular Lattices Vs Metaheuristic SolutionsEfren Diaz ChiasNo ratings yet
- Chapter7 ModelsDocument83 pagesChapter7 ModelsYashimera Laid MaapeNo ratings yet
- Ziou 1998Document42 pagesZiou 1998Sharmin SathiNo ratings yet
- Week 11 Probability and StatisticsDocument27 pagesWeek 11 Probability and StatisticsRamenKing12No ratings yet
- Parallel Computing Communication Operations SlidesDocument71 pagesParallel Computing Communication Operations SlidesgamagamaNo ratings yet
- AE Basic StatDocument31 pagesAE Basic StatJamelah AbigailNo ratings yet
- Spatial Analysis Using Grids: Learning ObjectivesDocument59 pagesSpatial Analysis Using Grids: Learning ObjectivesKaushal GhimireNo ratings yet
- Clausi - Gabor Parameters - Pattern Recognition 2000Document15 pagesClausi - Gabor Parameters - Pattern Recognition 2000GuillermoEatonNo ratings yet
- Sequential Data and Markov Models: Sargur N. Srihari Machine Learning CourseDocument21 pagesSequential Data and Markov Models: Sargur N. Srihari Machine Learning CourseasdfasdffdsaNo ratings yet
- Fingerprint Matching Using Gabor FilterDocument5 pagesFingerprint Matching Using Gabor Filterapi-3858504100% (1)
- Lecture 2Document54 pagesLecture 2Qateel JuttNo ratings yet
- CS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text DataDocument35 pagesCS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text Dataankit devNo ratings yet
- Binary Image AnalysisDocument33 pagesBinary Image Analysismehari kirosNo ratings yet
- OSE801 Engineering System Identification: Spring 2010Document29 pagesOSE801 Engineering System Identification: Spring 2010samNo ratings yet
- Constructing Multivariate Probability Distribution For Soil Properties Based On Site-Specific DataDocument6 pagesConstructing Multivariate Probability Distribution For Soil Properties Based On Site-Specific Datachin_kbNo ratings yet
- Realtime Scanmatching and Localization Using A Spinning Laser Rangefinder Tudor AchimDocument5 pagesRealtime Scanmatching and Localization Using A Spinning Laser Rangefinder Tudor AchimTudor AchimNo ratings yet
- Students T-TestDocument3 pagesStudents T-Test이승빈No ratings yet
- A Novel 3D Skeleton Algorithm Based On Neutrosophic Cost FunctionDocument8 pagesA Novel 3D Skeleton Algorithm Based On Neutrosophic Cost FunctionMia AmaliaNo ratings yet
- InterferometryDocument5 pagesInterferometryJesoJNo ratings yet
- COMP 482: Design and Analysis of Algorithms: Spring 2013Document34 pagesCOMP 482: Design and Analysis of Algorithms: Spring 2013shiv kumarNo ratings yet
- Application of Numerical Methods To Truss Bridge Using Finite Element AnalysisDocument12 pagesApplication of Numerical Methods To Truss Bridge Using Finite Element AnalysisBenmark JabayNo ratings yet
- Sensors: A Multiscale Region-Based Motion Detection and Background Subtraction AlgorithmDocument21 pagesSensors: A Multiscale Region-Based Motion Detection and Background Subtraction AlgorithmBaris YeltekinNo ratings yet
- 3D Object Recognition: Koç UniversityDocument10 pages3D Object Recognition: Koç UniversityAlfan RizaldyNo ratings yet
- Skala - Resolusi - Tobler 1987Document6 pagesSkala - Resolusi - Tobler 1987Zie DNo ratings yet
- Special Problems Summer 2018 Planar Robot Localization With The Extended Kalman FilterDocument36 pagesSpecial Problems Summer 2018 Planar Robot Localization With The Extended Kalman FilterAnonymous ujfkWS8No ratings yet
- An Implementation of SIFT Detector and Descriptor: Andrea Vedaldi University of California at Los AngelesDocument7 pagesAn Implementation of SIFT Detector and Descriptor: Andrea Vedaldi University of California at Los AngelesParis BoubNo ratings yet
- TRAVERSEANALYSISDocument12 pagesTRAVERSEANALYSISSOLO INSANITYNo ratings yet
- HATRNet Human Activity Transition RecognDocument6 pagesHATRNet Human Activity Transition RecognariasalvaroNo ratings yet
- Module5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Document21 pagesModule5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Rohith RohNo ratings yet
- Imet131 e Chapitre 1Document28 pagesImet131 e Chapitre 1Nicholas SheaNo ratings yet
- Answer To Question GISDocument6 pagesAnswer To Question GISAbebawNo ratings yet
- PHY321@TD1 Quantum StatesV2310Document2 pagesPHY321@TD1 Quantum StatesV2310wokgadebanaNo ratings yet
- (Geographic Information Systems) : Applications in MarketingDocument50 pages(Geographic Information Systems) : Applications in MarketingSeif TalalNo ratings yet
- Bio 3 ApointquarterlabDocument6 pagesBio 3 ApointquarterlabArief Rahman ariefNo ratings yet
- Hidden Variables, The EM Algorithm, and Mixtures of GaussiansDocument58 pagesHidden Variables, The EM Algorithm, and Mixtures of GaussiansDUDEKULA VIDYASAGARNo ratings yet
- Introductory Statistics (3-4) : Display & Explore Using R & R CommanderDocument26 pagesIntroductory Statistics (3-4) : Display & Explore Using R & R Commanderv lNo ratings yet
- Introductory Statistics (3-4) : Display & Explore Using R & R CommanderDocument26 pagesIntroductory Statistics (3-4) : Display & Explore Using R & R Commanderv lNo ratings yet
- Scale Invariant Feature Transform: Unveiling the Power of Scale Invariant Feature Transform in Computer VisionFrom EverandScale Invariant Feature Transform: Unveiling the Power of Scale Invariant Feature Transform in Computer VisionNo ratings yet
- Tracking with Particle Filter for High-dimensional Observation and State SpacesFrom EverandTracking with Particle Filter for High-dimensional Observation and State SpacesNo ratings yet
- Spatial Structure Analysis Using Planar IndicesDocument25 pagesSpatial Structure Analysis Using Planar IndicesSteep BesoinNo ratings yet
- Advanced Spatial Analysis Training Program For Population Scientists-Research ProposalDocument48 pagesAdvanced Spatial Analysis Training Program For Population Scientists-Research ProposalSteep BesoinNo ratings yet
- Geospatial Data Repositories and ArchivesDocument24 pagesGeospatial Data Repositories and ArchivesSteep BesoinNo ratings yet
- Managed File Transfer Solutions: Get Instant Visibility Into The State of Your Organization's File TransfersDocument12 pagesManaged File Transfer Solutions: Get Instant Visibility Into The State of Your Organization's File TransfersSteep BesoinNo ratings yet
- Why Automation Is Critical To Delivering Scalable and Reliable Big Data SolutionsDocument8 pagesWhy Automation Is Critical To Delivering Scalable and Reliable Big Data SolutionsSteep BesoinNo ratings yet
- Computer Forensics Digital Forensic Computer-Forensics-digital-Forensic-Analysis-methodologyDocument9 pagesComputer Forensics Digital Forensic Computer-Forensics-digital-Forensic-Analysis-methodologySteep BesoinNo ratings yet
- BW1605 RB Internal Audit ENDocument7 pagesBW1605 RB Internal Audit ENSteep BesoinNo ratings yet
- IONET Change Manager For Lotus DominoDocument3 pagesIONET Change Manager For Lotus DominoSteep BesoinNo ratings yet
- SPMN RedBookDocument10 pagesSPMN RedBookSteep BesoinNo ratings yet
- 05 N002 28712Document17 pages05 N002 28712Alfian FahrosiNo ratings yet
- Sample Pages - Global Cocoa Butter Alternatives Market Research Report PDFDocument45 pagesSample Pages - Global Cocoa Butter Alternatives Market Research Report PDFAlekseyNo ratings yet
- MethodDocument19 pagesMethodLê ThùyNo ratings yet
- Job Experience Correlates of Job Performance: Michael A. McdanielDocument4 pagesJob Experience Correlates of Job Performance: Michael A. McdanielKabib AbdullahNo ratings yet
- Uganda 2021 Elections Afrobarometer PollDocument54 pagesUganda 2021 Elections Afrobarometer PolljadwongscribdNo ratings yet
- Article NewDocument9 pagesArticle NewMBA Ponjesly College of EngineeringNo ratings yet
- PMRS Chapter 9Document6 pagesPMRS Chapter 9Shubham SrivastavaNo ratings yet
- Role of Human Resource Practitioners For An Effective Change ProcessDocument19 pagesRole of Human Resource Practitioners For An Effective Change ProcessJ ANo ratings yet
- Challenges and Prospects For The Book Industry in CameroonDocument45 pagesChallenges and Prospects For The Book Industry in CameroonAcademic JournalNo ratings yet
- 7 Week5 TLE - GRADE 6 - ICT - MODULE 6Document11 pages7 Week5 TLE - GRADE 6 - ICT - MODULE 6vladryeNo ratings yet
- Lampiran 1 Perhitungan CV (Coefficient of Variation) : 1. Kategori 12 Periode: A. Abita SatinDocument117 pagesLampiran 1 Perhitungan CV (Coefficient of Variation) : 1. Kategori 12 Periode: A. Abita SatinEyrenNo ratings yet
- Research Methods in Political Science - SyllabusDocument6 pagesResearch Methods in Political Science - SyllabusMitchNo ratings yet
- EDUC 203 Curriculum Development and DesignDocument9 pagesEDUC 203 Curriculum Development and Designbenes dopitilloNo ratings yet
- Academic Writing in Second Language: An Outlook of Spanish Higher Education Practices and ChallengesDocument19 pagesAcademic Writing in Second Language: An Outlook of Spanish Higher Education Practices and ChallengesFranNo ratings yet
- Performance Evaluation of Utilization of Waste Polyethylene Terephthalate (PET) in Stone Mastic AsphaltDocument6 pagesPerformance Evaluation of Utilization of Waste Polyethylene Terephthalate (PET) in Stone Mastic AsphaltAgustina ManurungNo ratings yet
- Twelve Tips For Embedding Assessment For and As Learning Practices in A Programmatic Assessment SystemDocument8 pagesTwelve Tips For Embedding Assessment For and As Learning Practices in A Programmatic Assessment SystemClaudia HenaoNo ratings yet
- Get Published Special Report Academic WordDocument9 pagesGet Published Special Report Academic Wordgpr201No ratings yet
- EKSAKTA Authors GuidelineDocument4 pagesEKSAKTA Authors Guidelinemaisari utamiNo ratings yet
- Air Quality and Thermal Comfort in Office BuildingDocument6 pagesAir Quality and Thermal Comfort in Office BuildingnamitexNo ratings yet
- MCMC For EpidemiologistsDocument8 pagesMCMC For EpidemiologistsThiago MPNo ratings yet
- Free Food Safety VideosDocument26 pagesFree Food Safety VideosWasim ArshadNo ratings yet
- Article Review On The Relationship Between Students' Learning Styles and Their Academic AchievementDocument4 pagesArticle Review On The Relationship Between Students' Learning Styles and Their Academic AchievementDesithaNo ratings yet