You might also like
- Polyethylene Plastic Production ProcessDocument8 pagesPolyethylene Plastic Production Processkiki haikalNo ratings yet
- Essential Safety GuideDocument112 pagesEssential Safety GuideKVD100% (1)
- The Detection of Earnings Manipulation Messod D. BeneishDocument27 pagesThe Detection of Earnings Manipulation Messod D. BeneishOld School Value100% (13)
- Long Short-Term Memory Survey PaperDocument6 pagesLong Short-Term Memory Survey PaperHimanshu GaurNo ratings yet
- Design and Implementation of A SHARC Digital Signal Processor Core in Verilog HDLDocument6 pagesDesign and Implementation of A SHARC Digital Signal Processor Core in Verilog HDLAhmed HamoudaNo ratings yet
- Improving latency and throughput in wireless signal processing on Epiphany manycoreDocument6 pagesImproving latency and throughput in wireless signal processing on Epiphany manycoretresaNo ratings yet
- CS 601 Machine Learning Unit 4Document14 pagesCS 601 Machine Learning Unit 4Priyanka BhateleNo ratings yet
- A 64-Tile 2.4-Mb in-Memory-Computing CNN Accelerator Employing Charge-Domain ComputeDocument5 pagesA 64-Tile 2.4-Mb in-Memory-Computing CNN Accelerator Employing Charge-Domain ComputeHelloNo ratings yet
- Addition Multiplication RNNDocument7 pagesAddition Multiplication RNNrobinNo ratings yet
- Sense AmplifiersDocument6 pagesSense AmplifierskeerthiNo ratings yet
- An Advanced and Area Optimized L.U.T Design Using A.P.C. and O.M.SDocument5 pagesAn Advanced and Area Optimized L.U.T Design Using A.P.C. and O.M.Ssreelakshmi.ece eceNo ratings yet
- FPGA Based Efficient Implementation of Viterbi Decoder: Anubhuti KhareDocument6 pagesFPGA Based Efficient Implementation of Viterbi Decoder: Anubhuti KhareKrishnateja YarrapatruniNo ratings yet
- Low_power_and_high_speed_8x8_bit_multiplier_using_non-clocked_pass_transistor_logicDocument5 pagesLow_power_and_high_speed_8x8_bit_multiplier_using_non-clocked_pass_transistor_logicDai LewisNo ratings yet
- Inherently Lower-Power High-Performance Superscalar ArchitecturesDocument21 pagesInherently Lower-Power High-Performance Superscalar ArchitecturesMamta BorleNo ratings yet
- LS 3Document11 pagesLS 3RohanthNo ratings yet
- IEEE International Multi Topic Conference Paper Publication: E1 Stream Analyzer Capturing CSS-7Document6 pagesIEEE International Multi Topic Conference Paper Publication: E1 Stream Analyzer Capturing CSS-7Ali AzharNo ratings yet
- 35.IJAEST Vol No 5 Issue No 2 Design Analysis of FFT Blocks For Pulsed OFDM UWB Systems Using FPGA 339 342Document4 pages35.IJAEST Vol No 5 Issue No 2 Design Analysis of FFT Blocks For Pulsed OFDM UWB Systems Using FPGA 339 342iserpNo ratings yet
- Thesis VHDL PDFDocument6 pagesThesis VHDL PDFmarybrownarlington100% (2)
- Development of A Fully Implantable Recording System For Ecog SignalsDocument6 pagesDevelopment of A Fully Implantable Recording System For Ecog SignalsGeneration GenerationNo ratings yet
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document7 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationNo ratings yet
- Machine Learning Hardware AccelerationDocument26 pagesMachine Learning Hardware AccelerationSai SumanthNo ratings yet
- LUT Optimization Using Combined APC-OMS Technique For Memory-Based ComputationDocument9 pagesLUT Optimization Using Combined APC-OMS Technique For Memory-Based ComputationRaj PrabhasNo ratings yet
- Implementation and Analysis of An Error DetectionDocument7 pagesImplementation and Analysis of An Error DetectioninfinitywaysalwaysNo ratings yet
- Survey FPGA IEEE AccessDocument13 pagesSurvey FPGA IEEE AccessSaurabh BhangaleNo ratings yet
- Antenna DesignDocument6 pagesAntenna Designsappal73asNo ratings yet
- Low Area Fpga Implementation of Dromcsla-Qtl Architecture For Cryptographic ApplicationsDocument13 pagesLow Area Fpga Implementation of Dromcsla-Qtl Architecture For Cryptographic ApplicationsAIRCC - IJNSANo ratings yet
- Building Custom FIR Filters Using System GeneratorDocument4 pagesBuilding Custom FIR Filters Using System Generatordwivedi89No ratings yet
- छावा सरकार TAE - महाराष्ट्र राज्यDocument20 pagesछावा सरकार TAE - महाराष्ट्र राज्यfake mailNo ratings yet
- Fpga Implementation of A Multilayer Perceptron Neural Network Using VHDLDocument4 pagesFpga Implementation of A Multilayer Perceptron Neural Network Using VHDLminoramixNo ratings yet
- Yang 2018 Europa RDocument16 pagesYang 2018 Europa RShrey AgarwalNo ratings yet
- ML (Cs-601) Unit 4 CompleteDocument45 pagesML (Cs-601) Unit 4 Completeread4freeNo ratings yet
- IJETR032171Document4 pagesIJETR032171erpublicationNo ratings yet
- Neural NetworksDocument22 pagesNeural Networksdamank2402No ratings yet
- Fast Automatic Gain Control Employing Two Compensation Loop For High Throughput MIMO-OFDM ReceiversDocument4 pagesFast Automatic Gain Control Employing Two Compensation Loop For High Throughput MIMO-OFDM Receiversapi-19755952No ratings yet
- A Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"Document6 pagesA Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"svasanth007No ratings yet
- Wind Power Prediction Based On LSTM-CNN Optimization: Yang Liu, Liqun LiuDocument9 pagesWind Power Prediction Based On LSTM-CNN Optimization: Yang Liu, Liqun LiuRony Arturo Bocangel SalasNo ratings yet
- Secure Remote Protocol For Fpga ReconfigurationDocument5 pagesSecure Remote Protocol For Fpga ReconfigurationesatjournalsNo ratings yet
- Tam MetinDocument4 pagesTam MetinerkandumanNo ratings yet
- Implementation of High Speed OFDM Transceiver Using FPGADocument3 pagesImplementation of High Speed OFDM Transceiver Using FPGAiirNo ratings yet
- Project-1 Basic Architecture DesignDocument4 pagesProject-1 Basic Architecture DesignUmesh KumarNo ratings yet
- FPGA Implementations of Feed Forward Neural Network by Using Floating Point Hardware AcceleratorsDocument10 pagesFPGA Implementations of Feed Forward Neural Network by Using Floating Point Hardware AcceleratorsCarlos Torres CasasNo ratings yet
- Cascaded Multilevel InvertersDocument6 pagesCascaded Multilevel InvertersMinhaj NaimNo ratings yet
- Hardware Implementation BackpropagationDocument14 pagesHardware Implementation BackpropagationDavidThânNo ratings yet
- 5G NR PhyDocument13 pages5G NR PhyBrian HabibNo ratings yet
- REDDY K., SALIVAHANAN S. - Novel and Efficient Celular Automated Based Symmetric Key Encription Algorithm For Wireless Sensor NetworkDocument8 pagesREDDY K., SALIVAHANAN S. - Novel and Efficient Celular Automated Based Symmetric Key Encription Algorithm For Wireless Sensor NetworkLeandro TeixeiraNo ratings yet
- Delayed Branch Logic: Texas Instruments TMS320 Is A Blanket Name For A Series ofDocument13 pagesDelayed Branch Logic: Texas Instruments TMS320 Is A Blanket Name For A Series ofnomadcindrellaNo ratings yet
- Synthesis AlDocument7 pagesSynthesis AlAgnathavasiNo ratings yet
- High-Speed Hardware-Efficient SC Polar DecoderDocument5 pagesHigh-Speed Hardware-Efficient SC Polar Decodersameer nigamNo ratings yet
- Simultaneous Multithreading: Exploiting ILP and TLP for Greater PerformanceDocument4 pagesSimultaneous Multithreading: Exploiting ILP and TLP for Greater PerformancePalanikumarNo ratings yet
- Unit I IntroductionDocument54 pagesUnit I IntroductionMerbin JoseNo ratings yet
- Project Work M.Tech PDFDocument4 pagesProject Work M.Tech PDFkailashNo ratings yet
- Implementing On-Line Sketch-Based Change Detection On A Netfpga PlatformDocument6 pagesImplementing On-Line Sketch-Based Change Detection On A Netfpga PlatformHargyo Tri NugrohoNo ratings yet
- Microprocessor Basic ProgrammingDocument132 pagesMicroprocessor Basic Programmingersimohit100% (1)
- A Reconfigurable Digital Signal Processing SystemDocument6 pagesA Reconfigurable Digital Signal Processing Systempym1506gmail.comNo ratings yet
- Tech Doc 2 (Repaired)Document22 pagesTech Doc 2 (Repaired)Anudeep AllenkiNo ratings yet
- FPGA Arquitectura BasicaDocument7 pagesFPGA Arquitectura BasicaJesus LeyvaNo ratings yet
- Performance Analysisof LEACHwith Machine Learning Algorithmsin Wireless Sensor NetworksDocument6 pagesPerformance Analysisof LEACHwith Machine Learning Algorithmsin Wireless Sensor NetworksRoneena AJNo ratings yet
- Saini 2011Document10 pagesSaini 2011Bookaholic 11No ratings yet
- Design of VLSI Architecture For A Flexible Testbed of Artificial Neural Network For Training and Testing On FPGADocument7 pagesDesign of VLSI Architecture For A Flexible Testbed of Artificial Neural Network For Training and Testing On FPGAInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Parallel Performance Study of Monte Carlo Photon Transport Code On Shared-, Distributed-, and Distributed-Shared-Memory ArchitecturesDocument7 pagesParallel Performance Study of Monte Carlo Photon Transport Code On Shared-, Distributed-, and Distributed-Shared-Memory Architecturesvermashanu89No ratings yet
- PSB-RNN: A Processing-in-Memory Systolic Array Architecture Using Block Circulant Matrices For Recurrent Neural NetworksDocument6 pagesPSB-RNN: A Processing-in-Memory Systolic Array Architecture Using Block Circulant Matrices For Recurrent Neural NetworksVidhi DesaiNo ratings yet
- Gujarat Technological University: CreditsDocument4 pagesGujarat Technological University: CreditsNiket RathodNo ratings yet
- Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipFrom EverandGain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipNo ratings yet
- 'D:/Sridhar/Reference Paper/ Data' 'Fileextensions' '.Wav' 'Includesubfolders'Document3 pages'D:/Sridhar/Reference Paper/ Data' 'Fileextensions' '.Wav' 'Includesubfolders'sridharchandrasekarNo ratings yet
- Audio Signal ProcessingDocument2 pagesAudio Signal ProcessingsridharchandrasekarNo ratings yet
- Convolutional Networks For Images, Speech, and Time-Series: January 1995Document15 pagesConvolutional Networks For Images, Speech, and Time-Series: January 1995sridharchandrasekarNo ratings yet
- LSTM CodeDocument15 pagesLSTM CodesridharchandrasekarNo ratings yet
- Intellectual Property RightsDocument11 pagesIntellectual Property RightssridharchandrasekarNo ratings yet
- HttpsDocument1 pageHttpssridharchandrasekarNo ratings yet
- Analysis of Feature Extraction Techniques For Speech Recognition SystemDocument4 pagesAnalysis of Feature Extraction Techniques For Speech Recognition SystemsridharchandrasekarNo ratings yet
- Discrete Time System PropertiesDocument24 pagesDiscrete Time System PropertiessridharchandrasekarNo ratings yet
- Computer Speech & Language: Gueorgui Pironkov, Sean UN Wood, ST Ephane DupontDocument13 pagesComputer Speech & Language: Gueorgui Pironkov, Sean UN Wood, ST Ephane DupontsridharchandrasekarNo ratings yet
- ACFrOgBcxUlZKgyHP WLwSRZiMgFjfB1lw72TFnG0OHgxh7I6NzXfPOtLvRsmRu5z faoo9Pud9-m-gooCokdBk5OQude4 g9Vb5xQLUAzL9 d7bHjzhj8ziwC4mZSvhbCzasZQCjBoXJZqQq0pRDocument42 pagesACFrOgBcxUlZKgyHP WLwSRZiMgFjfB1lw72TFnG0OHgxh7I6NzXfPOtLvRsmRu5z faoo9Pud9-m-gooCokdBk5OQude4 g9Vb5xQLUAzL9 d7bHjzhj8ziwC4mZSvhbCzasZQCjBoXJZqQq0pRsridharchandrasekarNo ratings yet
- Figure 1Document1 pageFigure 1sridharchandrasekarNo ratings yet
- Microprocessors and Microsystems: Kharibam Jilenkumari Devi, Nangbam Herojit Singh, Khelchandra ThongamDocument14 pagesMicroprocessors and Microsystems: Kharibam Jilenkumari Devi, Nangbam Herojit Singh, Khelchandra Thongamvenkat301485No ratings yet
- Binarized Neural Networks: 30th Conference On Neural Information Processing Systems (NIPS 2016), Barcelona, SpainDocument9 pagesBinarized Neural Networks: 30th Conference On Neural Information Processing Systems (NIPS 2016), Barcelona, SpainsridharchandrasekarNo ratings yet
- Efcient Binary 3D Convolutional Neural Network and HardwareDocument11 pagesEfcient Binary 3D Convolutional Neural Network and HardwaresridharchandrasekarNo ratings yet
- EC 1 - Unit 1 Class Notes PDFDocument57 pagesEC 1 - Unit 1 Class Notes PDFsridharchandrasekarNo ratings yet
- Summations: Discrete Time Linear SystemsDocument5 pagesSummations: Discrete Time Linear SystemssridharchandrasekarNo ratings yet
- B.Tech. Degree in Computer Science and EngineeringDocument171 pagesB.Tech. Degree in Computer Science and EngineeringsridharchandrasekarNo ratings yet
- Problems On Bode PlotDocument5 pagesProblems On Bode PlotAnkit Kumar AJ0% (1)
- Iv TT 2020 Odd SemDocument1 pageIv TT 2020 Odd SemsridharchandrasekarNo ratings yet
- Computer Speech & Language: Gueorgui Pironkov, Sean UN Wood, ST Ephane DupontDocument13 pagesComputer Speech & Language: Gueorgui Pironkov, Sean UN Wood, ST Ephane DupontsridharchandrasekarNo ratings yet
- Cns QPDocument2 pagesCns QPsridharchandrasekarNo ratings yet
- Final Year Project Review ReportDocument8 pagesFinal Year Project Review ReportsridharchandrasekarNo ratings yet
- Antennas and Radiation Mechanism of Various Antennas and Antenna ArraysDocument11 pagesAntennas and Radiation Mechanism of Various Antennas and Antenna ArrayssridharchandrasekarNo ratings yet
- Code Fundamentals of Semiconductor Devices L T P C: Applied OpticsDocument6 pagesCode Fundamentals of Semiconductor Devices L T P C: Applied OpticssridharchandrasekarNo ratings yet
- SEMESTER TitleDocument15 pagesSEMESTER TitlesridharchandrasekarNo ratings yet
- Professional Elective - IIdfdDocument13 pagesProfessional Elective - IIdfdsridharchandrasekarNo ratings yet
- Department of Electronics and Communication Engineering Project Batch For The Academic Year 2020 - 21 Batch: 2017-2021Document4 pagesDepartment of Electronics and Communication Engineering Project Batch For The Academic Year 2020 - 21 Batch: 2017-2021sridharchandrasekarNo ratings yet
- Professional Elective - IDocument10 pagesProfessional Elective - IsridharchandrasekarNo ratings yet
- Professional Elective - VDocument8 pagesProfessional Elective - VsridharchandrasekarNo ratings yet
- BE Information Technology 0Document655 pagesBE Information Technology 0virendra giraseNo ratings yet
- CIVIL ENGINEERING COMPETITIVE QUESTIONSDocument58 pagesCIVIL ENGINEERING COMPETITIVE QUESTIONSpatanelakathNo ratings yet
- Srs Property Management System For ProgramersDocument16 pagesSrs Property Management System For ProgramersShah Alam100% (3)
- Model B: Thermostatic Control ValvesDocument13 pagesModel B: Thermostatic Control ValvesRei_budNo ratings yet
- Kerosene Isosiv Process For Production of Normal Paraffins: Stephen W. SohnDocument6 pagesKerosene Isosiv Process For Production of Normal Paraffins: Stephen W. SohnAshraf SeragNo ratings yet
- 3 D Via Composer Error LogDocument9 pages3 D Via Composer Error LogNilesh A. KhedekarNo ratings yet
- SPSS ImplicationsDocument3 pagesSPSS ImplicationsAnonymous MMNqiyxBUNo ratings yet
- Multidimensional SchemaDocument4 pagesMultidimensional SchemaJanmejay PantNo ratings yet
- ISO 15614 vs ASME IX welding standards comparisonDocument2 pagesISO 15614 vs ASME IX welding standards comparisontuanNo ratings yet
- Rank and Nullity TheoremDocument6 pagesRank and Nullity TheoremsdfsdfNo ratings yet
- Cisco ASR 9001 Router DatasheetDocument5 pagesCisco ASR 9001 Router DatasheetĐỗ TháiNo ratings yet
- Prokofiev NotesDocument14 pagesProkofiev NotesUlyssesm90No ratings yet
- Pes Inv As 27bDocument5 pagesPes Inv As 27bapi-336208398No ratings yet
- RRB Clerk Prelims Day - 13 e (1) 168804293277Document27 pagesRRB Clerk Prelims Day - 13 e (1) 168804293277sahilNo ratings yet
- 1 to 10 DSBDA case studyDocument17 pages1 to 10 DSBDA case studyGanesh BagulNo ratings yet
- Psd4135G2: Flash In-System-Programmable Peripherals For 16-Bit McusDocument94 pagesPsd4135G2: Flash In-System-Programmable Peripherals For 16-Bit McusSiva Manohar ReddyNo ratings yet
- Fish RespirationDocument4 pagesFish Respirationmekala17181705No ratings yet
- Surveying NotesDocument7 pagesSurveying NotesTrina SambasNo ratings yet
- Data Communication: Lecturer: Tamanna Haque NipaDocument20 pagesData Communication: Lecturer: Tamanna Haque NipaAlokTripathiNo ratings yet
- Impact of Socio-Economic Status On Academic Achievement Among The Senior Secondary School StudentsDocument7 pagesImpact of Socio-Economic Status On Academic Achievement Among The Senior Secondary School StudentsClariza PascualNo ratings yet
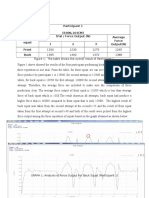
- Result: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackDocument5 pagesResult: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackpatenggNo ratings yet
- PLC Based Solar Panel With Tilting Arrangement: April 2016Document9 pagesPLC Based Solar Panel With Tilting Arrangement: April 2016Paul TodericNo ratings yet
- M. Santosh Kumar Datastructures Using C++Document7 pagesM. Santosh Kumar Datastructures Using C++Marumamula Santosh KumarNo ratings yet
- Module-4: Numerical Differentiation and IntegrationDocument22 pagesModule-4: Numerical Differentiation and Integrationvenkat sathwik kethepalliNo ratings yet
- Making A PCB: Report and PPT - PresentationDocument6 pagesMaking A PCB: Report and PPT - PresentationKaranSinghNo ratings yet
- BS Iso 12817-2013Document28 pagesBS Iso 12817-2013Ігор БадюкевичNo ratings yet