You might also like
- Retail Analysis With Walmart DataDocument2 pagesRetail Analysis With Walmart DataSriram100% (9)
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- Project Movielense SolutionDocument4 pagesProject Movielense SolutionSanjib Ganguly29% (7)
- Mercedes-Benz Greener Manufacturing AiDocument16 pagesMercedes-Benz Greener Manufacturing AiPuji0% (1)
- Project MovieLens 17082019 by Monalisa GangulyDocument28 pagesProject MovieLens 17082019 by Monalisa GangulySanjib GangulyNo ratings yet
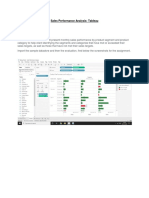
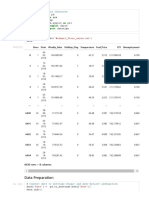
- Sales Performance AnalysisDocument3 pagesSales Performance AnalysisAnshu BaidyaNo ratings yet
- Machine Learning - Home - Coursera Quiz PDFDocument5 pagesMachine Learning - Home - Coursera Quiz PDFMary Peace100% (1)
- Comcast consumer complaint trendsDocument1 pageComcast consumer complaint trendsNavinNo ratings yet
- Deep Learning - Project Scope DocumentDocument2 pagesDeep Learning - Project Scope Documentaditya jainNo ratings yet
- BRD School Lunch OrderingDocument10 pagesBRD School Lunch OrderingNhung LêNo ratings yet
- WEBI Report ErrorsDocument4 pagesWEBI Report ErrorsYogeeswar ReddyNo ratings yet
- Tableau Desktop Fundamentals: Connect to Data & Create VisualizationsDocument3 pagesTableau Desktop Fundamentals: Connect to Data & Create VisualizationsSelvakumar ArunasalamNo ratings yet
- Analyzing Stock Market Data with PandasDocument16 pagesAnalyzing Stock Market Data with PandasAbhisek KeshariNo ratings yet
- Vehicle Registration Statistics of Private Vehicle Goods Vehicle and Others by YearDocument2 pagesVehicle Registration Statistics of Private Vehicle Goods Vehicle and Others by YearAnjan ToliaNo ratings yet
- Concept Based Practice Questions for Tableau Desktop Specialist Certification Latest Edition 2023From EverandConcept Based Practice Questions for Tableau Desktop Specialist Certification Latest Edition 2023No ratings yet
- Costa Rican Household Poverty Prediction ModelDocument19 pagesCosta Rican Household Poverty Prediction ModelSrustijit Sahoo50% (2)
- MSBIDocument30 pagesMSBISuresh MupparajuNo ratings yet
- Python Classes Objects PDFDocument8 pagesPython Classes Objects PDFAbhiram Have Drifted FarNo ratings yet
- DATA MINING LAB MANUALDocument74 pagesDATA MINING LAB MANUALAakashNo ratings yet
- Python Comcast Telecom Consumer Complaints Final ProjectDocument44 pagesPython Comcast Telecom Consumer Complaints Final ProjectNiladri Sekhar Sardar100% (2)
- Dbms Lab ManualDocument104 pagesDbms Lab ManualsureshNo ratings yet
- Tableau Introduction v01Document19 pagesTableau Introduction v01Linus HarriNo ratings yet
- Customer Service Requests Analysis - Vivek - ProjectDocument10 pagesCustomer Service Requests Analysis - Vivek - ProjectVivek Singh0% (1)
- Database Management Systems Course Guide Book PDFDocument4 pagesDatabase Management Systems Course Guide Book PDFYohanes KassuNo ratings yet
- Data Scientist Course For EvaluationDocument12 pagesData Scientist Course For EvaluationSubhadip GhoshNo ratings yet
- Advanced Excel Functions for Data AnalysisDocument7 pagesAdvanced Excel Functions for Data AnalysisCatherine VenturaNo ratings yet
- Uber HYD COE Business Analyst JD - Analytics & Data Science-1 PDFDocument3 pagesUber HYD COE Business Analyst JD - Analytics & Data Science-1 PDFcherukuNo ratings yet
- Solution - Data Analysis With Python-Project-2 - v1.0Document14 pagesSolution - Data Analysis With Python-Project-2 - v1.0Amit KumarNo ratings yet
- Fast Four S&C - Datasheet Architecture and Data Security PDFDocument5 pagesFast Four S&C - Datasheet Architecture and Data Security PDFAnurag SinghNo ratings yet
- Chapter 5 - Classification ProblemsDocument25 pagesChapter 5 - Classification Problemsanshita100% (1)
- Differences between supervised and unsupervised learningDocument22 pagesDifferences between supervised and unsupervised learningsahil kumarNo ratings yet
- SQL Cheat Sheet: Click HereDocument48 pagesSQL Cheat Sheet: Click HereSaurabh Gupta100% (2)
- Tableau DesktopDocument3,545 pagesTableau DesktopJorge Raphael Rodriguez MamaniNo ratings yet
- OracleDocument7 pagesOraclerajNo ratings yet
- ML ProjectsDocument19 pagesML ProjectsJinendra JainNo ratings yet
- Solved ProblemsDocument74 pagesSolved Problemssmitha_gururaj100% (2)
- MS SQL Server Business IntelligenceDocument6 pagesMS SQL Server Business IntelligenceJulie RobertsNo ratings yet
- Creating PDF ReportsDocument53 pagesCreating PDF Reportsアテンヂド 彩No ratings yet
- DWH Quiz2 With AnswersDocument14 pagesDWH Quiz2 With AnswersSwapnaNo ratings yet
- Oracle Cloud Platform Enterprise Analytics 2021 Specialist 1Z0-1041-21Document8 pagesOracle Cloud Platform Enterprise Analytics 2021 Specialist 1Z0-1041-21TouqeerNo ratings yet
- My SQL For BeginnersDocument3 pagesMy SQL For BeginnersPallavi SinghNo ratings yet
- Project 02 Customer Service Requests Analysis CaltechDocument19 pagesProject 02 Customer Service Requests Analysis CaltechShaila NaganurNo ratings yet
- TableauDocument5 pagesTableaudharmendardNo ratings yet
- Free 70 461 Exam Questions PDF Microsoft1Document9 pagesFree 70 461 Exam Questions PDF Microsoft1VickyNo ratings yet
- TCS BaNCS End User Report User Manual Ver 2.0Document59 pagesTCS BaNCS End User Report User Manual Ver 2.0DJ MitchNo ratings yet
- How Many Red Colored Swift Cars Are There in Delhi?Document1 pageHow Many Red Colored Swift Cars Are There in Delhi?vedNo ratings yet
- Excel Crash Course PDFDocument2 pagesExcel Crash Course PDFmanoj_yadav735No ratings yet
- Job CodesDocument17 pagesJob CodesAnil VasireddyNo ratings yet
- Software Requirements Specification Document For Urban ClapDocument26 pagesSoftware Requirements Specification Document For Urban ClapGajendra PandeyNo ratings yet
- SQL LabsheetDocument11 pagesSQL LabsheetAnonymous 0uTFeZ2cIN100% (1)
- Star SchemaDocument45 pagesStar Schemaapi-26355935100% (3)
- Oracle Functional Services Application Management Services Generating and Printing QR Code From EBSDocument10 pagesOracle Functional Services Application Management Services Generating and Printing QR Code From EBSGuru PrasadNo ratings yet
- Microsoft Dynamics AX 2012 R3 Development Cookbook - Sample ChapterDocument61 pagesMicrosoft Dynamics AX 2012 R3 Development Cookbook - Sample ChapterPackt PublishingNo ratings yet
- Busy-Accounting TutorialDocument6 pagesBusy-Accounting TutorialNaushad AnwarNo ratings yet
- DDM HW1 Akash SrivastavaDocument14 pagesDDM HW1 Akash SrivastavaAkash Srivastava100% (2)
- Tableau Desktop Introduction & FundamentalsDocument56 pagesTableau Desktop Introduction & FundamentalsVarun GuptaNo ratings yet
- 2 ASSIGNMENT 2 (Beginning Superstore)Document1 page2 ASSIGNMENT 2 (Beginning Superstore)Chaitanya Chowdary0% (1)
- Retail Analysis WalmartDocument18 pagesRetail Analysis WalmartNavin MathadNo ratings yet
- Credit Default Practice PDFDocument27 pagesCredit Default Practice PDFSravan100% (1)
- Generate Unifrom DistributionDocument11 pagesGenerate Unifrom Distributionajaykum14No ratings yet
- Comcast AnalysisDocument8 pagesComcast AnalysisRamaseshu MachepalliNo ratings yet
- Walmart Sales AnalysisDocument26 pagesWalmart Sales AnalysisRamaseshu Machepalli100% (1)
- Comcast Consumer Complaints A First ApprDocument23 pagesComcast Consumer Complaints A First ApprRamaseshu MachepalliNo ratings yet
- AndhraPradesh-01 Results C3Document79 pagesAndhraPradesh-01 Results C3Ff PlayerNo ratings yet
- Types of OsDocument12 pagesTypes of OsRamaseshu MachepalliNo ratings yet
- Economic AnalysisDocument7 pagesEconomic AnalysisRamaseshu MachepalliNo ratings yet
- Data Science With Python - Lesson 01 - Data Science OverviewDocument35 pagesData Science With Python - Lesson 01 - Data Science OverviewSwarnajyoti Mazumdar100% (2)
- Data Science With Python - Lesson 04 - Python Environment Setup and EssentialsDocument59 pagesData Science With Python - Lesson 04 - Python Environment Setup and EssentialsElie MradNo ratings yet
- Concepts and Techniques: Data MiningDocument41 pagesConcepts and Techniques: Data MiningRamaseshu MachepalliNo ratings yet
- Data Science with Python OverviewDocument54 pagesData Science with Python OverviewSwarnajyoti MazumdarNo ratings yet
- Retail Analysis With Walmart DataDocument10 pagesRetail Analysis With Walmart DataRamaseshu MachepalliNo ratings yet
- Data Science With Python - Lesson 03 - Statistical Analysis and Business ApplicationsDocument57 pagesData Science With Python - Lesson 03 - Statistical Analysis and Business ApplicationsSwarnajyoti MazumdarNo ratings yet
- Microcheck Calibration Services Presentation on Importance of Machine Tool CalibrationDocument19 pagesMicrocheck Calibration Services Presentation on Importance of Machine Tool CalibrationSunilNo ratings yet
- The Role of Protection Performance Audits in The Lifetime Management of Protection SystemsDocument10 pagesThe Role of Protection Performance Audits in The Lifetime Management of Protection Systemssno-koneNo ratings yet
- End of Chapter Assignment Jun2020 (Student)Document4 pagesEnd of Chapter Assignment Jun2020 (Student)Hidayah Dayah100% (1)
- Kharidar First Paper SyllabusDocument4 pagesKharidar First Paper SyllabusSulav KhatiwadaNo ratings yet
- PR2 Group 1Document3 pagesPR2 Group 1Deborah BandahalaNo ratings yet
- Physics - Lab Reports & RubricsDocument4 pagesPhysics - Lab Reports & Rubricsapi-464156291No ratings yet
- Sound Ratings & ARI StandardDocument4 pagesSound Ratings & ARI StandardPrasad GujarNo ratings yet
- Twitter Data Mining For Sentiment Analysis On Peoples Feedback Against Government Public PolicyDocument13 pagesTwitter Data Mining For Sentiment Analysis On Peoples Feedback Against Government Public PolicyGlobal Research and Development Services100% (2)
- D 5101 - 99 Rduxmdetotk - PDFDocument8 pagesD 5101 - 99 Rduxmdetotk - PDFdadadadNo ratings yet
- DS Levalators 14aDocument2 pagesDS Levalators 14aKim Patrick GonzalesNo ratings yet
- True Position Guide To Location TechnologiesDocument10 pagesTrue Position Guide To Location Technologiesnas2rightyNo ratings yet
- Mathematics SL - Applications and Interpretation - OXFORD 2019 (ESTIMACION)Document8 pagesMathematics SL - Applications and Interpretation - OXFORD 2019 (ESTIMACION)zaraarciniegascNo ratings yet
- Static C/cs of MeasurementsDocument3 pagesStatic C/cs of MeasurementssamadonyNo ratings yet
- MSA - StatgraphicsDocument3 pagesMSA - Statgraphicstehky63No ratings yet
- TOT PPT For HIS - M&E - Training GuidlineDocument65 pagesTOT PPT For HIS - M&E - Training Guidlinearus jundiNo ratings yet
- F 2203 - 02 RjiymdmDocument3 pagesF 2203 - 02 Rjiymdmfrostest100% (1)
- Physics Material 1Document94 pagesPhysics Material 1Mphoka SalomeNo ratings yet
- Performance Metrics (Classification) : Enrique J. de La Hoz DDocument30 pagesPerformance Metrics (Classification) : Enrique J. de La Hoz DJORGE LUIS AGUAS MEZANo ratings yet
- General Physics Week 1 4Document23 pagesGeneral Physics Week 1 4Yona SpadesNo ratings yet
- Unit 1-2 Q&ADocument35 pagesUnit 1-2 Q&APandiya Rajan100% (1)
- Evaluating Performance Characteristics of Ultrasonic Pulse-Echo Examination Instruments and Systems Without The Use of Electronic Measurement InstrumentsDocument12 pagesEvaluating Performance Characteristics of Ultrasonic Pulse-Echo Examination Instruments and Systems Without The Use of Electronic Measurement InstrumentsorlandoNo ratings yet
- Measurements Uncertainty GuideDocument13 pagesMeasurements Uncertainty GuideWaseem AhmedNo ratings yet
- Machine Learning Andrew NG Week 6Document11 pagesMachine Learning Andrew NG Week 6Hương ĐặngNo ratings yet
- SISO-REF-020-DRAFT DIS Plain and Simple-20131107Document43 pagesSISO-REF-020-DRAFT DIS Plain and Simple-20131107Neel PatelNo ratings yet
- Uncertanity Fully ExplainedDocument18 pagesUncertanity Fully Explainednoman21No ratings yet
- Comparing The Perfomance of Leica Dna03 PDFDocument48 pagesComparing The Perfomance of Leica Dna03 PDFp2342No ratings yet
- Exercise 2 Intro To Balance - 2Document3 pagesExercise 2 Intro To Balance - 2Sharlene Cecil PagoboNo ratings yet
- GR, 12 (A) Mock Exam (2022 2023) (Al Warith Bin Ka'Ab) ) Marking GuideDocument7 pagesGR, 12 (A) Mock Exam (2022 2023) (Al Warith Bin Ka'Ab) ) Marking Guideاحمد المقباليNo ratings yet
- Astm D 897 - 01 - RDG5NWDocument3 pagesAstm D 897 - 01 - RDG5NWphaindikaNo ratings yet
- Fall 2023 - CS619 - 8881Document1 pageFall 2023 - CS619 - 8881archi oo7No ratings yet