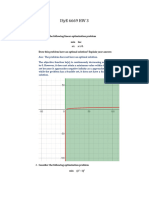
You might also like
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Calculus Tutorial 1 - Differential CalculusDocument25 pagesCalculus Tutorial 1 - Differential CalculusDr Srinivasan Nenmeli -K100% (9)
- 1.3 Piecewise FunctionsDocument68 pages1.3 Piecewise Functionskiki lovemeNo ratings yet
- Limits and Continuity PDFDocument107 pagesLimits and Continuity PDFAnonymous 0MTQ0BNo ratings yet
- Cours 2 - Training Deep Neural NetworksDocument42 pagesCours 2 - Training Deep Neural NetworksSarah BouammarNo ratings yet
- Limit RepoartDocument11 pagesLimit Repoartabdulsamadshwani67No ratings yet
- Limits: Created by Tynan Lazarus September 24, 2017Document6 pagesLimits: Created by Tynan Lazarus September 24, 2017Geetansh PancholiNo ratings yet
- Lecture 9 - SVMDocument42 pagesLecture 9 - SVMHusein YusufNo ratings yet
- Limit ReviewDocument4 pagesLimit Reviewsiekierapyo4163No ratings yet
- Basic CalculusDocument7 pagesBasic Calculusagliamraniel03No ratings yet
- Lecture 11 - Business and Economics Optimization Problems and Asymptotes PDFDocument9 pagesLecture 11 - Business and Economics Optimization Problems and Asymptotes PDFpupu_putraNo ratings yet
- Chapter 2Document95 pagesChapter 2smixers gtNo ratings yet
- Optimization 111Document29 pagesOptimization 111mohammed aliNo ratings yet
- Extrema and Average Rates of Change+Document63 pagesExtrema and Average Rates of Change+sb8239No ratings yet
- Increasing and Decreasing FunctionsDocument51 pagesIncreasing and Decreasing FunctionsNoah RyanNo ratings yet
- 1.6 Limit Laws PDFDocument3 pages1.6 Limit Laws PDFKristhel Pecolados RombaoaNo ratings yet
- A) Graphs of Functions NotesDocument10 pagesA) Graphs of Functions NotesHaoyu WangNo ratings yet
- LimitFunction PDFDocument4 pagesLimitFunction PDFNajmul IslamNo ratings yet
- Week 7Document53 pagesWeek 7Khaled TarekNo ratings yet
- Limits and Continuity of FunctionsDocument60 pagesLimits and Continuity of FunctionsAngelo ReyesNo ratings yet
- Sing Levar OptDocument29 pagesSing Levar OptDiego Isla-LópezNo ratings yet
- HW3 SolutionDocument7 pagesHW3 SolutionprakshiNo ratings yet
- Chapter 2 OptimizationDocument47 pagesChapter 2 OptimizationDHEEVIKA SURESHNo ratings yet
- 1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Document43 pages1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Tev WallaceNo ratings yet
- Multi Variable Optimization: Min F (X, X, X, - X)Document38 pagesMulti Variable Optimization: Min F (X, X, X, - X)Saheera HazarikaNo ratings yet
- AP Calculus AB Study GuideDocument63 pagesAP Calculus AB Study GuideMai Nhiên Lê NguyễnNo ratings yet
- Comp Intel Cheat SheetDocument2 pagesComp Intel Cheat SheetDanielNo ratings yet
- Lec 17 Multivariable OTDocument30 pagesLec 17 Multivariable OTMuhammad Bilal JunaidNo ratings yet
- Notes 3-6 Critical Points and ExtremaDocument15 pagesNotes 3-6 Critical Points and ExtremaNoelle CaballeraNo ratings yet
- T1 - DifferentiationDocument95 pagesT1 - DifferentiationMahmudNo ratings yet
- Interview Question What Is Gradient Descent 1679467271Document16 pagesInterview Question What Is Gradient Descent 1679467271Vani agarwalNo ratings yet
- Fb1 Stem 4 Basic Calculus Group 3Document10 pagesFb1 Stem 4 Basic Calculus Group 3Martin Federick HermanoNo ratings yet
- Max/min of A FunctionDocument5 pagesMax/min of A FunctionTrevor ChimombeNo ratings yet
- Workbook Definition+of+the+limit SolutionsDocument26 pagesWorkbook Definition+of+the+limit Solutionsalejandro aschNo ratings yet
- Section One - DerivativesDocument17 pagesSection One - Derivativestsunderes100% (2)
- Math Project Part 2Document21 pagesMath Project Part 2harsh2006rocks -No ratings yet
- Part2 Basic MathDocument22 pagesPart2 Basic Mathzepozepo06No ratings yet
- 11 Limits of Functions of Real Variables: 11.1 The ε / δ DefinitionDocument7 pages11 Limits of Functions of Real Variables: 11.1 The ε / δ Definitiona2hasijaNo ratings yet
- Calculus 1Document57 pagesCalculus 1fayera letaNo ratings yet
- Math Review: Sequences and LimitsDocument11 pagesMath Review: Sequences and LimitsMichael GarciaNo ratings yet
- Gradient Descent Deep Learning: by T.K. Damodharan Vice President, RBS Reg - No: PC2013003013008Document37 pagesGradient Descent Deep Learning: by T.K. Damodharan Vice President, RBS Reg - No: PC2013003013008Shanmuganathan V (RC2113003011029)No ratings yet
- 2.2 Evaluate and Graph Polynomial FunctionsDocument30 pages2.2 Evaluate and Graph Polynomial FunctionsJo-Emmanuel P. PañeNo ratings yet
- MT 1112 Calculus Group ADocument7 pagesMT 1112 Calculus Group Aanime admirersNo ratings yet
- Recitation 8: Continuous Optimization: For I End ForDocument12 pagesRecitation 8: Continuous Optimization: For I End ForWenjun HouNo ratings yet
- Introduction To Optimization: Anjela Govan North Carolina State University SAMSI NDHS Undergraduate Workshop 2006Document29 pagesIntroduction To Optimization: Anjela Govan North Carolina State University SAMSI NDHS Undergraduate Workshop 2006Teferi LemmaNo ratings yet
- Introduction, Function and Limits With Derivatives: Module OutlineDocument10 pagesIntroduction, Function and Limits With Derivatives: Module OutlineErn NievaNo ratings yet
- Linear RegressionDocument29 pagesLinear RegressionSoubhav ChamanNo ratings yet
- Gradient Descent - Xiaowei HuangDocument53 pagesGradient Descent - Xiaowei HuangHuy PhamNo ratings yet
- CS 546: Module 2: Spring 2014Document73 pagesCS 546: Module 2: Spring 2014drsimrankaurNo ratings yet
- EC2104 Lecture 2Document40 pagesEC2104 Lecture 2GeekgodNo ratings yet
- Examples 1 - LimitsDocument4 pagesExamples 1 - LimitsLexNo ratings yet
- Calculus and Analytical GeometryDocument19 pagesCalculus and Analytical GeometryRizwanAliNo ratings yet
- OQM Lecture Note - Part 1 Introduction To Mathematical OptimisationDocument10 pagesOQM Lecture Note - Part 1 Introduction To Mathematical OptimisationdanNo ratings yet
- Topic 5A. DifferentiationDocument52 pagesTopic 5A. DifferentiationZEEL PATELNo ratings yet
- Topic 5A. DifferentiationDocument52 pagesTopic 5A. DifferentiationZEEL PATELNo ratings yet
- Module 3 - Critical PointsDocument19 pagesModule 3 - Critical PointsMaddyyyNo ratings yet
- 1 Limits & Continuity NotesDocument82 pages1 Limits & Continuity Notesmseconroy84No ratings yet
- JIM101 Learning Material (Lecture Note) - CHAPTER 2 (Part I)Document54 pagesJIM101 Learning Material (Lecture Note) - CHAPTER 2 (Part I)Hor KaiNo ratings yet
- Find The Local Maximum and Minimum ValuesDocument4 pagesFind The Local Maximum and Minimum Valuesapi-143521979No ratings yet
- 2.3 The Limit Laws - Calculus Volume 1 OpenStax PDFDocument1 page2.3 The Limit Laws - Calculus Volume 1 OpenStax PDFlea biscuitNo ratings yet
- Lecture 03Document4 pagesLecture 03Saikat DasNo ratings yet
- 3.1 Global-Descent-Based Error Backpropagation: W W Given byDocument28 pages3.1 Global-Descent-Based Error Backpropagation: W W Given byStefanescu AlexandruNo ratings yet
- Optimization Algorithms For Ultrasonic Array Imaging in Homogeneous Anisotropic Steel Components With Unknown PropertiesDocument14 pagesOptimization Algorithms For Ultrasonic Array Imaging in Homogeneous Anisotropic Steel Components With Unknown PropertiespjhollowNo ratings yet
- Deep Learning (All in One)Document23 pagesDeep Learning (All in One)B BasitNo ratings yet
- Self-Organizing Maps: EE4305 Introduction To Fuzzy/Neural System Part II Project IIDocument9 pagesSelf-Organizing Maps: EE4305 Introduction To Fuzzy/Neural System Part II Project IIColzi ChenNo ratings yet
- Linear RegressionDocument14 pagesLinear RegressionSyed Tariq NaqshbandiNo ratings yet
- Learning Rate Free Learning by D AdaptationDocument35 pagesLearning Rate Free Learning by D AdaptationSatish GundawarNo ratings yet
- Assignment-1: Abhishek ShringiDocument19 pagesAssignment-1: Abhishek ShringiFranklin GarysonNo ratings yet
- Mini Project Fln..Document51 pagesMini Project Fln..Umesh MauryaNo ratings yet
- Data Science Lab Assignment: Name: Vemula Yaminee Jyothsna Roll No: 20BM6JP44Document2 pagesData Science Lab Assignment: Name: Vemula Yaminee Jyothsna Roll No: 20BM6JP44Jyothsna VemulaNo ratings yet
- Adaptive FilteringDocument410 pagesAdaptive FilteringLino García MoralesNo ratings yet
- Slides-4 Optimization Extra Gradient DescentDocument67 pagesSlides-4 Optimization Extra Gradient DescentBhavana AkkirajuNo ratings yet
- Improving Generalization Performance by Switching From Adam To SGDDocument10 pagesImproving Generalization Performance by Switching From Adam To SGDDavidNo ratings yet
- 23 DeepLearning PDFDocument74 pages23 DeepLearning PDFkavinscribNo ratings yet
- MiniCPM-2B: New Compact Multimodal LLM Outperforming The GiantsDocument9 pagesMiniCPM-2B: New Compact Multimodal LLM Outperforming The GiantsMy SocialNo ratings yet
- Exercise: Train and Use An Object Detection ModelDocument15 pagesExercise: Train and Use An Object Detection ModelGeorgeKaramanoglouNo ratings yet
- Gradient Descent Algorithm in Machine Learning - Analytics VidhyaDocument11 pagesGradient Descent Algorithm in Machine Learning - Analytics VidhyaAmritaRupiniNo ratings yet
- HyperparametersDocument15 pagesHyperparametersrajaNo ratings yet
- Gradnorm: Gradient Normalization For Adaptive Loss Balancing in Deep Multitask NetworksDocument12 pagesGradnorm: Gradient Normalization For Adaptive Loss Balancing in Deep Multitask NetworksTTNo ratings yet
- Plant Disease Detection Using Deep Learning: Anjaneya Teja KalvakolanuDocument4 pagesPlant Disease Detection Using Deep Learning: Anjaneya Teja KalvakolanuCoffee pasteNo ratings yet
- Building Blocks of DNN PDFDocument21 pagesBuilding Blocks of DNN PDFAmbreen Abdul razzaqueNo ratings yet
- Building Blocks of DNN PDFDocument21 pagesBuilding Blocks of DNN PDFAmbreen Abdul razzaqueNo ratings yet
- Programming Assign Unit 7Document5 pagesProgramming Assign Unit 7Mahmoud HeretaniNo ratings yet
- Continuous OptimizationDocument51 pagesContinuous Optimizationlaphv494No ratings yet
- Deep Learning NotesDocument14 pagesDeep Learning NotesbadalrkcocNo ratings yet
- EDA Lecture Module 4Document20 pagesEDA Lecture Module 4WINORLOSENo ratings yet
- ICDAR 2021 Competition On On-Line Signature Verification: September 2021Document17 pagesICDAR 2021 Competition On On-Line Signature Verification: September 2021Hannah JanawaNo ratings yet
- Assessment: The DatasetDocument5 pagesAssessment: The DatasetPraveen SinghNo ratings yet
- Lab5 Linear RegressionDocument1 pageLab5 Linear RegressionSamratNo ratings yet
- Geoffrey Hinton With Nitish Srivastava Kevin Swersky: Neural Networks For Machine LearningDocument31 pagesGeoffrey Hinton With Nitish Srivastava Kevin Swersky: Neural Networks For Machine LearningMahapatra MilonNo ratings yet