You might also like
- Classification of Bird Species Using Deep Learning TechniquesDocument5 pagesClassification of Bird Species Using Deep Learning TechniquesIJRASETPublicationsNo ratings yet
- Bird Species Classification Using Deep Learning Literature SurveyDocument27 pagesBird Species Classification Using Deep Learning Literature Surveyharshithays100% (2)
- Paper 11-Image Based Individual Cow RecognitionDocument7 pagesPaper 11-Image Based Individual Cow RecognitionCarl FeynmanNo ratings yet
- Andre Ferreira Et Al - Deep Learning Based Methods For Individual Recognition in Small BirdsDocument14 pagesAndre Ferreira Et Al - Deep Learning Based Methods For Individual Recognition in Small Birdsarie.zychlinskiNo ratings yet
- Classification and Morphological Analysis of Vector Mosquitoes Using Deep Convolutional Neural NetworksDocument13 pagesClassification and Morphological Analysis of Vector Mosquitoes Using Deep Convolutional Neural NetworkshetiNo ratings yet
- Elife 63377 v2Document39 pagesElife 63377 v2Emmanuel DahitoNo ratings yet
- Deep LearningDocument10 pagesDeep LearningAMNo ratings yet
- Biometric Animal Databases From Field Photographs: Identification of Individual Zebra in The WildDocument8 pagesBiometric Animal Databases From Field Photographs: Identification of Individual Zebra in The WildXosé PardavilaNo ratings yet
- Fnsys 13 00020Document12 pagesFnsys 13 00020Dr. Rajeev AgarwalNo ratings yet
- Study On Body Size Measurement MethodDocument22 pagesStudy On Body Size Measurement MethodMaryamZahraNo ratings yet
- 10 (2S) 368-382Document15 pages10 (2S) 368-382asmaaNo ratings yet
- Tracking Organisms: Toxtrac: A Fast and Robust Software ForDocument72 pagesTracking Organisms: Toxtrac: A Fast and Robust Software ForRogério GerbatinNo ratings yet
- Limbs Detection and Tracking of Head-Fixed Mice For Behavioral Phenotyping Using Motion Tubes and Deep LearningDocument11 pagesLimbs Detection and Tracking of Head-Fixed Mice For Behavioral Phenotyping Using Motion Tubes and Deep LearningCony GSNo ratings yet
- V4I206Document8 pagesV4I206surendar147No ratings yet
- Facial Recognition of Cattle Based On SK-ResNetDocument10 pagesFacial Recognition of Cattle Based On SK-ResNetWaleed AhmedNo ratings yet
- Perez - Mari Gayle - BS Bio 4A - CritiqueDocument7 pagesPerez - Mari Gayle - BS Bio 4A - CritiqueMari Gayle PerezNo ratings yet
- AB O D A D M: Rief Verview On Ifferent Nimal Etection EthodsDocument5 pagesAB O D A D M: Rief Verview On Ifferent Nimal Etection EthodsGowtham VNo ratings yet
- Iris Recognition With Fake IdentificationDocument12 pagesIris Recognition With Fake IdentificationiisteNo ratings yet
- 1 s2.0 S0168169922002484 MainDocument9 pages1 s2.0 S0168169922002484 MainasmaaNo ratings yet
- Iris Based Authentication ReportDocument5 pagesIris Based Authentication ReportDragan PetkanovNo ratings yet
- Gomez 2017Document29 pagesGomez 2017Aadarsh RamakrishnanNo ratings yet
- Multimodal Biometric Crypto System For Human AutheDocument11 pagesMultimodal Biometric Crypto System For Human Authetech guruNo ratings yet
- Individual Detection and Tracking of Group Housed Pigs in Their Home Pen Using Computer VisionDocument10 pagesIndividual Detection and Tracking of Group Housed Pigs in Their Home Pen Using Computer VisionViníciusNo ratings yet
- Automatic Cattle Identification Using YOLOv5 and MDocument8 pagesAutomatic Cattle Identification Using YOLOv5 and MDenis CardosoNo ratings yet
- An Effective CNN Based Feature Extraction Approach For Iris Recognition SystemDocument10 pagesAn Effective CNN Based Feature Extraction Approach For Iris Recognition SystemNomula SowmyareddyNo ratings yet
- Fpls 12 716784Document13 pagesFpls 12 716784Masela BambangNo ratings yet
- Dual Integration of Iris and Palmprint For RealizationDocument6 pagesDual Integration of Iris and Palmprint For Realizationeditor_ijarcsseNo ratings yet
- A Computer Vision For Animal EcologyDocument32 pagesA Computer Vision For Animal Ecologyjcle609No ratings yet
- BiometricDocument15 pagesBiometricВячеслав ГолубничныйNo ratings yet
- An Enhanced Iris Recognition and Authentication System Using Energy MeasureDocument7 pagesAn Enhanced Iris Recognition and Authentication System Using Energy MeasureNomula SowmyareddyNo ratings yet
- Bird Species Identifier Using Convolutional Neural NetworkDocument9 pagesBird Species Identifier Using Convolutional Neural NetworkIJRASETPublicationsNo ratings yet
- Computers and Electronics in Agriculture: Yu Jiang, Zhenbo Li, Jingjing Fang, Jun Yue, Daoliang LiDocument9 pagesComputers and Electronics in Agriculture: Yu Jiang, Zhenbo Li, Jingjing Fang, Jun Yue, Daoliang LiayakashimajorinNo ratings yet
- ZooscanDocument19 pagesZooscankpmanikandaanNo ratings yet
- Detecting Self-Stimulatory Behaviours For Autism Diagnosis: January 2015Document6 pagesDetecting Self-Stimulatory Behaviours For Autism Diagnosis: January 2015Ainna AldayNo ratings yet
- Deep Learning From Limited Training Data Novel Segmentation and Ensemble Algorithms Applied To Automatic Melanoma DiagnosisDocument16 pagesDeep Learning From Limited Training Data Novel Segmentation and Ensemble Algorithms Applied To Automatic Melanoma DiagnosisMuhammad Awais QureshiNo ratings yet
- Eerdekens LQ PDFDocument127 pagesEerdekens LQ PDFmisgana etichaNo ratings yet
- Tracking with Particle Filter for High-dimensional Observation and State SpacesFrom EverandTracking with Particle Filter for High-dimensional Observation and State SpacesNo ratings yet
- Pig Face Recognition Based On Trapezoid Normalized Pixel Difference Feature and Trimmed Mean Attention MechanismDocument13 pagesPig Face Recognition Based On Trapezoid Normalized Pixel Difference Feature and Trimmed Mean Attention Mechanismjonathan3700No ratings yet
- Automatic Stomata Recognition and Measurement Based On Improved YOLO Deep Learning Model and Entropy Rate Superpixel AlgorithmDocument13 pagesAutomatic Stomata Recognition and Measurement Based On Improved YOLO Deep Learning Model and Entropy Rate Superpixel AlgorithmMusabbir Ahmed ArrafiNo ratings yet
- Fetal Brain Ultrasound Image Classification Using Deep LearningDocument5 pagesFetal Brain Ultrasound Image Classification Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Detection of Stored-Grain Insects Using Deep LearningDocument7 pagesDetection of Stored-Grain Insects Using Deep LearningtrevNo ratings yet
- Pig Face Recognition Based On Metric Learning by Combining A Residual Network and Attention MechanismDocument17 pagesPig Face Recognition Based On Metric Learning by Combining A Residual Network and Attention Mechanismjonathan3700No ratings yet
- A Workflow For Rapid Unbiased Quantification of Fibrillar Featu Alignment in Biological ImagesDocument16 pagesA Workflow For Rapid Unbiased Quantification of Fibrillar Featu Alignment in Biological ImagesO SNo ratings yet
- 2011 Meijering Et Al Particle Tracking MethodDocument18 pages2011 Meijering Et Al Particle Tracking Methodhansraj4u4800No ratings yet
- Iris Segmentation and Detection System For Human IdentificationDocument6 pagesIris Segmentation and Detection System For Human Identificationanil kasotNo ratings yet
- Paper 34-Birds Identification System Using Deep LearningDocument11 pagesPaper 34-Birds Identification System Using Deep LearningHui ShanNo ratings yet
- Arxiv 23Document7 pagesArxiv 23Sinan EntwistleNo ratings yet
- A Video-Based Eye Pupil Detection System For Diagnosing Bipolar DisorderDocument11 pagesA Video-Based Eye Pupil Detection System For Diagnosing Bipolar DisorderÖmer Faruk YıldızNo ratings yet
- Bird Species Identification Using Deep Fuzzy Neural NetworkDocument8 pagesBird Species Identification Using Deep Fuzzy Neural NetworkIJRASETPublicationsNo ratings yet
- 251 SubmissionDocument6 pages251 Submissionsharwari solapurNo ratings yet
- AnimaliaDocument6 pagesAnimaliaHui ShanNo ratings yet
- Person Large Area SpyDocument8 pagesPerson Large Area SpyMossad NewsNo ratings yet
- Animals 12 01976 v2Document16 pagesAnimals 12 01976 v2JPNo ratings yet
- Iris Recognition Research PapersDocument5 pagesIris Recognition Research Papersgw2cgcd9100% (1)
- A Benchmark For Comparison of Cell Tracking AlgorithmsDocument9 pagesA Benchmark For Comparison of Cell Tracking Algorithmssaujanya raoNo ratings yet
- 2263-Article Text-6723-1-10-20220430Document8 pages2263-Article Text-6723-1-10-20220430panca saputraNo ratings yet
- Human Gait Recognition and Classification Using SimilarityDocument6 pagesHuman Gait Recognition and Classification Using SimilarityUmm ShahadNo ratings yet
- A Study To Find Facts Behind Preprocessing On Deep Learning AlgorithmsDocument11 pagesA Study To Find Facts Behind Preprocessing On Deep Learning AlgorithmsEsclet PHNo ratings yet
- BowyerHollingsworthFlynnCVIU 2007 PDFDocument37 pagesBowyerHollingsworthFlynnCVIU 2007 PDFMarguerite FlowerNo ratings yet
- In-Ear EEG Biometrics For Feasible and Readily Collectable Real-World Person AuthenticationDocument14 pagesIn-Ear EEG Biometrics For Feasible and Readily Collectable Real-World Person AuthenticationTimothy AdeyemiNo ratings yet
- Questions - Homework - 10th - Science - 2021-11-24T05 - 39Document14 pagesQuestions - Homework - 10th - Science - 2021-11-24T05 - 39Saurabh BhattacharyaNo ratings yet
- Mes 038Document9 pagesMes 038MimiNo ratings yet
- Assement of Data Integrity Risk Areas in Microbiology LabDocument2 pagesAssement of Data Integrity Risk Areas in Microbiology Labfaisal abbasNo ratings yet
- Propositions: A. Learning Outcome Content StandardDocument9 pagesPropositions: A. Learning Outcome Content StandardMarc Joseph NillasNo ratings yet
- Mark Scheme (Results) : Summer 2017Document22 pagesMark Scheme (Results) : Summer 2017Khalid AhmedNo ratings yet
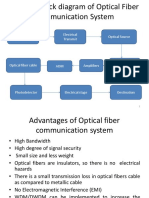
- Source of Information Electrical Transmit Optical SourceDocument37 pagesSource of Information Electrical Transmit Optical SourcesubashNo ratings yet
- Abraham Tilahun GSE 6950 15Document13 pagesAbraham Tilahun GSE 6950 15Abraham tilahun100% (1)
- Math Makes Sense Practice and Homework Book Grade 5 AnswersDocument8 pagesMath Makes Sense Practice and Homework Book Grade 5 Answerseh041zef100% (1)
- AP Geography Study Material-AP Geography Quiz Questions With AnswersDocument3 pagesAP Geography Study Material-AP Geography Quiz Questions With AnswersRaja Sekhar BatchuNo ratings yet
- China Domestic Style Test ProcessDocument2 pagesChina Domestic Style Test ProcessPopper JohnNo ratings yet
- Bloom's Taxonomy Practice MCQsDocument6 pagesBloom's Taxonomy Practice MCQsAbdul RehmanNo ratings yet
- Wiring DM 1wDocument20 pagesWiring DM 1wAnan NasutionNo ratings yet
- Book Review Doing Action Research in Your Own OrganisationDocument5 pagesBook Review Doing Action Research in Your Own OrganisationJeronimo SantosNo ratings yet
- Housekeeping Services NCII Quarter 3 PDF HousekeepingDocument1 pageHousekeeping Services NCII Quarter 3 PDF HousekeepingSalve RegineNo ratings yet
- 11.22 Elastic Settlement of Group Piles: RumusDocument1 page11.22 Elastic Settlement of Group Piles: RumusHilda MaulizaNo ratings yet
- PBL Final ReportDocument4 pagesPBL Final ReportChester Dave Bal-otNo ratings yet
- Saroj Dulal - Pest Management Practices by Commercial Farmers in Kakani Rural MuncipalityDocument123 pagesSaroj Dulal - Pest Management Practices by Commercial Farmers in Kakani Rural MuncipalitySaroj DulalNo ratings yet
- Past Simple WH Questions Word Order Exercise 2Document3 pagesPast Simple WH Questions Word Order Exercise 2karen oteroNo ratings yet
- Introducing Python Programming For Engineering Scholars: Zahid Hussain, Muhammad Siyab KhanDocument8 pagesIntroducing Python Programming For Engineering Scholars: Zahid Hussain, Muhammad Siyab KhanDavid C HouserNo ratings yet
- CHM556 - Experiment 1 - Isolation of Caffeine From A Tea BagDocument8 pagesCHM556 - Experiment 1 - Isolation of Caffeine From A Tea Bagnabilahdaud93% (45)
- Doctrine of Double EffectDocument3 pagesDoctrine of Double EffectRael VillanuevaNo ratings yet
- Astm e 337Document24 pagesAstm e 337luisafer26No ratings yet
- Đề MINH HỌA Số 11 Luyện Thi Tốt Nghiệp THPT 2023Document7 pagesĐề MINH HỌA Số 11 Luyện Thi Tốt Nghiệp THPT 2023Minh ThưNo ratings yet
- Presentation On Employee Turnover Rate-BRMDocument13 pagesPresentation On Employee Turnover Rate-BRMMir Hossain EkramNo ratings yet
- Mathematics, Science, and Technology - Module 1Document6 pagesMathematics, Science, and Technology - Module 1Dale CalicaNo ratings yet
- Critically Discuss About Major Features of Water Resource Act, 2049 B.SDocument12 pagesCritically Discuss About Major Features of Water Resource Act, 2049 B.SPurple DreamNo ratings yet
- Trackless Mining at Thabazimbi MineDocument7 pagesTrackless Mining at Thabazimbi MineYojan Ccoa CcopaNo ratings yet
- 3.2.5.applying The Normal Curve Concepts in Problem Solving PDFDocument3 pages3.2.5.applying The Normal Curve Concepts in Problem Solving PDFJhasmin Jane LagamayoNo ratings yet
- 28-11-21 - JR - Iit - Star Co-Sc (Model-A) - Jee Adv - 2015 (P-I) - Wat-29 - Key & SolDocument8 pages28-11-21 - JR - Iit - Star Co-Sc (Model-A) - Jee Adv - 2015 (P-I) - Wat-29 - Key & SolasdfNo ratings yet
- List of Academic Design ProjectsDocument4 pagesList of Academic Design ProjectsAnurag SinghNo ratings yet