You might also like
- How To Sleep BetterDocument9 pagesHow To Sleep BetterMariaNo ratings yet
- Hypnosis ScriptsDocument94 pagesHypnosis ScriptsOgist DipenNo ratings yet
- Passion Project Action PlanDocument3 pagesPassion Project Action PlanMeresa W. MartinNo ratings yet
- Pediatric Nursing CareDocument7 pagesPediatric Nursing Carearcci balinasNo ratings yet
- Ti 2 B 2023 2 Easq.1#Document2 pagesTi 2 B 2023 2 Easq.1#SAIJAS QUIROZ ENRIQUE ANTONIONo ratings yet
- ReferencesDocument3 pagesReferencesOzzyNo ratings yet
- ReferencesDocument15 pagesReferenceshiabhi2No ratings yet
- Agent Intelligence Through DMDocument135 pagesAgent Intelligence Through DMSharmila SaravananNo ratings yet
- REFERENCESDocument4 pagesREFERENCESnavaneethakim311297No ratings yet
- BIBILOGRAPHYDocument4 pagesBIBILOGRAPHYShashiNo ratings yet
- Cybersecurity ReferencesDocument2 pagesCybersecurity ReferencesPritamNo ratings yet
- Bibliography A. BooksDocument4 pagesBibliography A. BooksJay-B Salamat EnriquezNo ratings yet
- Daftar PustakaDocument3 pagesDaftar PustakaRiskaNo ratings yet
- Thesis Sample1234Document9 pagesThesis Sample1234Dr. Sabira KhatunNo ratings yet
- CH 7Document10 pagesCH 7Mohamed AhmedNo ratings yet
- SyllabusDocument5 pagesSyllabuspostscriptNo ratings yet
- 7. DAPUS-REVDocument7 pages7. DAPUS-REVGay SebastianNo ratings yet
- Sample Selected Publication Lecturer ApplDocument59 pagesSample Selected Publication Lecturer ApplCATHERINENo ratings yet
- IEEE Format Reference List for Information Systems DocumentsDocument2 pagesIEEE Format Reference List for Information Systems DocumentsNabiilah Arlita PutriyanaNo ratings yet
- Daftar Pustaka E-GovernmentDocument22 pagesDaftar Pustaka E-Governmentyopita mamaazelNo ratings yet
- Tugas 2 Feri Tri SetiawanDocument4 pagesTugas 2 Feri Tri Setiawanhumas unulampungNo ratings yet
- Proceedings of 2018 International Conference On Electrical Engineering and Computer Science, ICECOS 2018Document4 pagesProceedings of 2018 International Conference On Electrical Engineering and Computer Science, ICECOS 2018Henrique FernandesNo ratings yet
- Teme Licenta Stancu 2019 - 2020Document10 pagesTeme Licenta Stancu 2019 - 2020Laura CostacheNo ratings yet
- Thesis SampleDocument9 pagesThesis SampleDr. Sabira KhatunNo ratings yet
- Ref FinalDocument6 pagesRef FinalLayse Ribeiro MascarenhasNo ratings yet
- Cloud RefsDocument23 pagesCloud RefsAtiq jan yousafzaiNo ratings yet
- Power system stability enhancement techniques and association rule mining algorithmsDocument21 pagesPower system stability enhancement techniques and association rule mining algorithmsAnonymous TxPyX8cNo ratings yet
- Bibliography 06c9450a d20b 4a60 Bdd9 Bdfa535e6dd4Document3 pagesBibliography 06c9450a d20b 4a60 Bdd9 Bdfa535e6dd4ADNo ratings yet
- IEEE Xplore Reference Download 2024.3.23.17.56.39Document1 pageIEEE Xplore Reference Download 2024.3.23.17.56.39ismaelNo ratings yet
- Machine Learning Methods for Electricity Theft DetectionDocument4 pagesMachine Learning Methods for Electricity Theft DetectionAmmar Yousaf KharalNo ratings yet
- 12 ReferencesDocument12 pages12 ReferencesAbhijeet GangulyNo ratings yet
- 2007 Automated Food Ontology Construction Mechanism For Diabetic Diet CareDocument6 pages2007 Automated Food Ontology Construction Mechanism For Diabetic Diet CareDhukiDwhiRachmanNo ratings yet
- Od Data Mining & Networking, Vol. 4, No. 2, Pp. 54-57, 2014Document1 pageOd Data Mining & Networking, Vol. 4, No. 2, Pp. 54-57, 2014NinaReščičNo ratings yet
- Daftar Pustaka: en Identificación Humana., Vol. 27, No. 3, Pp. 819-825, 2009Document3 pagesDaftar Pustaka: en Identificación Humana., Vol. 27, No. 3, Pp. 819-825, 2009UmmiNo ratings yet
- Ds ResumeDocument4 pagesDs Resumedushyant kumar singhNo ratings yet
- DAFTAR PUSTAKA REFERENCES LISTDocument3 pagesDAFTAR PUSTAKA REFERENCES LISTBagas SetiawanNo ratings yet
- Copie CuprinsDocument4 pagesCopie CuprinsDany MadoffNo ratings yet
- ReferencesDocument10 pagesReferencesSatish PathakNo ratings yet
- 14 ReferenceDocument10 pages14 ReferenceHelal Ahmed AponNo ratings yet
- International JournalsDocument9 pagesInternational Journalskalyanram19858017No ratings yet
- Bibliography & AbbreviationsDocument2 pagesBibliography & AbbreviationsNaresh KumarNo ratings yet
- Radio Frequency IdentificationDocument33 pagesRadio Frequency IdentificationMary MenaNo ratings yet
- Human Brain ProjectDocument9 pagesHuman Brain ProjectAndre L'HuillierNo ratings yet
- Pemanfaatan Internet Untuk Mencari Informasi Obat dan PenyakitDocument5 pagesPemanfaatan Internet Untuk Mencari Informasi Obat dan PenyakitWidya rumaratuNo ratings yet
- Daftar PustakaDocument10 pagesDaftar Pustakabe a doctor for you Medical studentNo ratings yet
- BIBILOGRAPHYDocument6 pagesBIBILOGRAPHYHari KrishnaNo ratings yet
- Big Data ReferencesDocument4 pagesBig Data Referencessachin22221No ratings yet
- ReferencesDocument3 pagesReferencessmahadev88No ratings yet
- S2 2019 418544 BibliographyDocument5 pagesS2 2019 418544 BibliographyAnjelica RosandiNo ratings yet
- List of Research Papers Published by Our PHD ScholarsDocument19 pagesList of Research Papers Published by Our PHD ScholarsWajahat AliNo ratings yet
- Atm Minutiae ReferenceDocument3 pagesAtm Minutiae ReferenceIbrahim MakindeNo ratings yet
- Dapus TambahanDocument3 pagesDapus TambahanDevy OrshellaNo ratings yet
- Daftar Pustaka: Public Health, 16, 631Document4 pagesDaftar Pustaka: Public Health, 16, 631mustika febriliaNo ratings yet
- Health Information Systems Interoperability Maturity Toolkit ReferencesDocument9 pagesHealth Information Systems Interoperability Maturity Toolkit ReferencesAriel GerardoNo ratings yet
- Student Research References on Network and Digital ForensicsDocument4 pagesStudent Research References on Network and Digital ForensicsOnwuegbuzie Innocent U.No ratings yet
- 762 Ieee Transactions On Systems, Man, and Cybernetics-Part A: Systems and Humans, Vol. 31, No. 6, November 2001Document6 pages762 Ieee Transactions On Systems, Man, and Cybernetics-Part A: Systems and Humans, Vol. 31, No. 6, November 2001Sachin ShendeNo ratings yet
- BiblioDocument7 pagesBiblioAdelmo FilhoNo ratings yet
- Privacy Transformations For Databank SystemsDocument3 pagesPrivacy Transformations For Databank Systemsaayola99No ratings yet
- Daftar Pustaka: REZA ANDRIADY, Dr.-Ing. Awang Noor Indra Wardana, S.T., M.T., M.Sc. Nopriadi, S.T., M.SC., PH.DDocument3 pagesDaftar Pustaka: REZA ANDRIADY, Dr.-Ing. Awang Noor Indra Wardana, S.T., M.T., M.Sc. Nopriadi, S.T., M.SC., PH.DNukman TsaqibNo ratings yet
- Published Papers in Top JournalsDocument6 pagesPublished Papers in Top JournalsUrwa TNo ratings yet
- Hester RefDocument1 pageHester RefTri NugrahaNo ratings yet
- Publications by BJ Orn W. Schuller:) B Books AuthoredDocument40 pagesPublications by BJ Orn W. Schuller:) B Books AuthoredAndre MartinsNo ratings yet
- Innovative Data Integration and Conceptual Space Modeling for COVID, Cancer, and Cardiac CareFrom EverandInnovative Data Integration and Conceptual Space Modeling for COVID, Cancer, and Cardiac CareNo ratings yet
- Jan Feb 1.7.1 Acquisition 1.7.3 Subscribe: 1.7 Product Funnel Conversion Analysis (Acquisition, Activation)Document55 pagesJan Feb 1.7.1 Acquisition 1.7.3 Subscribe: 1.7 Product Funnel Conversion Analysis (Acquisition, Activation)jeremiah eliorNo ratings yet
- MGCH CRM FlowDocument1 pageMGCH CRM Flowjeremiah eliorNo ratings yet
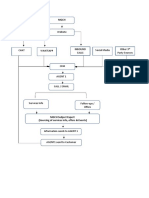
- Title: Appointment Schedule Sub-Process: Order Confirmation Code: (APR / FC - 1.1.3)Document1 pageTitle: Appointment Schedule Sub-Process: Order Confirmation Code: (APR / FC - 1.1.3)jeremiah eliorNo ratings yet
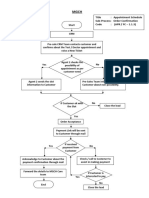
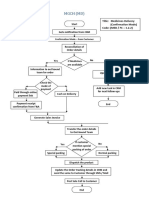
- Flowchart - Medical ServicesDocument1 pageFlowchart - Medical Servicesjeremiah eliorNo ratings yet
- Comparing SERP metrics and traffic for keyword opportunitiesDocument116 pagesComparing SERP metrics and traffic for keyword opportunitiesjeremiah eliorNo ratings yet
- Standard Operating Procedure TemplateDocument2 pagesStandard Operating Procedure Templatejeremiah eliorNo ratings yet
- Template 016 - Landing Page Creation BriefingDocument7 pagesTemplate 016 - Landing Page Creation Briefingjeremiah eliorNo ratings yet
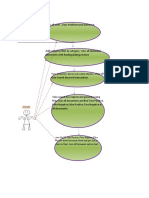
- An Iterative Use - Case - DigramDocument3 pagesAn Iterative Use - Case - Digramjeremiah eliorNo ratings yet
- Admin, User, and Data Publisher Flow ChartsDocument4 pagesAdmin, User, and Data Publisher Flow Chartsjeremiah eliorNo ratings yet
- An Iterative Classification Scheme For Sanitizing Large Scale Datasets - CONCLUSIONDocument1 pageAn Iterative Classification Scheme For Sanitizing Large Scale Datasets - CONCLUSIONjeremiah eliorNo ratings yet
- INTRODUCTIONDocument4 pagesINTRODUCTIONjeremiah eliorNo ratings yet
- Sequence Diagram: Search Documents by Keyword and Find Ratio, View DetailsDocument1 pageSequence Diagram: Search Documents by Keyword and Find Ratio, View Detailsjeremiah eliorNo ratings yet
- Class Diagram for Admin, User, Data Publisher RolesDocument1 pageClass Diagram for Admin, User, Data Publisher Rolesjeremiah eliorNo ratings yet
- An Iterative Classification Scheme For Sanitizing Large Scale Datasets - Full DocumentDocument4 pagesAn Iterative Classification Scheme For Sanitizing Large Scale Datasets - Full Documentjeremiah eliorNo ratings yet
- New Pattern QP-1Document50 pagesNew Pattern QP-1Unknown cool KidNo ratings yet
- Mom 202108003Document2 pagesMom 202108003Ckucku AranetaNo ratings yet
- JR NeuroanestesiDocument11 pagesJR Neuroanestesiliashuban29No ratings yet
- Vocab 2Document2 pagesVocab 2api-245567970No ratings yet
- Pestle Analysis On Reliance Industries: MBA Student - DBS Module International ManagementDocument15 pagesPestle Analysis On Reliance Industries: MBA Student - DBS Module International ManagementshubhamNo ratings yet
- NCMB 314 - GERIATRICS (CARE OF THE OLDER ADULT) - Physical and Physiological Changes of AgingDocument3 pagesNCMB 314 - GERIATRICS (CARE OF THE OLDER ADULT) - Physical and Physiological Changes of AgingSofia LiNo ratings yet
- Sociological Imagination EssayDocument5 pagesSociological Imagination Essayapi-402783933No ratings yet
- Jurnal Penelitian KBDocument6 pagesJurnal Penelitian KBMaya Ulfah apriliyaNo ratings yet
- Lecture 3.2.3: Erection III: Steel Construction: Fabrication and ErectionDocument4 pagesLecture 3.2.3: Erection III: Steel Construction: Fabrication and ErectionMihajloDjurdjevicNo ratings yet
- Abstract of ThesisDocument2 pagesAbstract of ThesisdrkartikeytyagiNo ratings yet
- 2 NdresearchpaperDocument5 pages2 Ndresearchpaperapi-356685046No ratings yet
- Re-Opening Plan For The 2020-2021 School YearDocument18 pagesRe-Opening Plan For The 2020-2021 School YearNews 8 WROCNo ratings yet
- Addicted To Phones - Reading AssignmentDocument4 pagesAddicted To Phones - Reading AssignmentLilith PersephoneNo ratings yet
- How To Negotiate With Nursing Authority Figures (Rough)Document2 pagesHow To Negotiate With Nursing Authority Figures (Rough)Meet DandiwalNo ratings yet
- Employee Perceptions of HR Practices & Organizational CultureDocument45 pagesEmployee Perceptions of HR Practices & Organizational CultureJatin Gupta100% (1)
- Aromasin 25 MG Coated Tablets SMPCDocument9 pagesAromasin 25 MG Coated Tablets SMPCpedjaljubaNo ratings yet
- MAPEH Daily Lesson LogDocument11 pagesMAPEH Daily Lesson LogMARTIN YUI LOPEZNo ratings yet
- Junal 1Document6 pagesJunal 1indadzi arsyNo ratings yet
- DLL Health 9 & 10Document6 pagesDLL Health 9 & 10Gladys GutierrezNo ratings yet
- Pharmacology Course IntroductionDocument2 pagesPharmacology Course IntroductionHassen ZabalaNo ratings yet
- Lec 3Document21 pagesLec 3Valerie VargasNo ratings yet
- 15 Incision AchievementsDocument15 pages15 Incision AchievementsAhmed AdelNo ratings yet
- Graduation Certificates: Speech TherapyDocument10 pagesGraduation Certificates: Speech Therapyliza khalilNo ratings yet
- OSHA Complaint FinalDocument3 pagesOSHA Complaint FinalBethanyNo ratings yet
- ORGB 5th Edition Nelson Solutions Manual 1Document44 pagesORGB 5th Edition Nelson Solutions Manual 1shirley100% (52)
- Privacy NurseDocument62 pagesPrivacy NurseGerryNo ratings yet