You might also like
- Application of Soft Computing Question Paper 21 22Document3 pagesApplication of Soft Computing Question Paper 21 22Mohd Ayan BegNo ratings yet
- BCA Practical ExercisesDocument12 pagesBCA Practical Exercisesanon_355047517100% (1)
- Unit 2 FodDocument27 pagesUnit 2 Fodit hodNo ratings yet
- Web TechnologyDocument13 pagesWeb TechnologyPrabha KrishnanNo ratings yet
- Sample Exam Intake 27Document5 pagesSample Exam Intake 27Eyad El RefaieNo ratings yet
- AIML Unit Wise Question BankDocument4 pagesAIML Unit Wise Question BankNss Aissms Coe PuneNo ratings yet
- C Programming Array GuideDocument27 pagesC Programming Array GuideRadhika AjadkaNo ratings yet
- Record 2022-23Document92 pagesRecord 2022-23kawsarNo ratings yet
- "Google Driverless Car": A Technical Seminar Report OnDocument15 pages"Google Driverless Car": A Technical Seminar Report OnSumana AngelNo ratings yet
- 18 Cps 13Document3 pages18 Cps 13Suhas HanjarNo ratings yet
- Object-Oriented Programming Lab Manual RDocument63 pagesObject-Oriented Programming Lab Manual RKLR CETNo ratings yet
- Data Mining and Business Intelligence Lab ManualDocument52 pagesData Mining and Business Intelligence Lab ManualVinay JokareNo ratings yet
- Balagurusamy Programming in C#Document22 pagesBalagurusamy Programming in C#Sayan ChatterjeeNo ratings yet
- Employee table queries and PL/SQL programsDocument13 pagesEmployee table queries and PL/SQL programsKarthik Nsp50% (2)
- What Is Difference Between Backtracking and Branch and Bound MethodDocument4 pagesWhat Is Difference Between Backtracking and Branch and Bound MethodMahi On D Rockzz67% (3)
- BD Problem Solving - IDocument2 pagesBD Problem Solving - IRishab kumarNo ratings yet
- What Is GKS (The Graphical Kernel System)Document6 pagesWhat Is GKS (The Graphical Kernel System)Pram AroraNo ratings yet
- Credit Card Fraud DetectionDocument14 pagesCredit Card Fraud DetectionSnehal Jain100% (1)
- CS6611 Mobile Application Development LabDocument54 pagesCS6611 Mobile Application Development LabIndumathy MayuranathanNo ratings yet
- Structured Programming ApproachDocument1 pageStructured Programming ApproachDreamtech PressNo ratings yet
- Question PaperDocument8 pagesQuestion PaperGopi PNo ratings yet
- Visvesvaraya Technological University: Lung Cancer Segmentation and Detection Using Machine LearningDocument67 pagesVisvesvaraya Technological University: Lung Cancer Segmentation and Detection Using Machine LearningSoni TiwariNo ratings yet
- A2020 DAY 24 APPS Java 15 April 2020Document19 pagesA2020 DAY 24 APPS Java 15 April 2020lok eshNo ratings yet
- Python AssignmentDocument4 pagesPython AssignmentNITIN RAJNo ratings yet
- Tech C, C#,javaDocument471 pagesTech C, C#,javaHema MalaniNo ratings yet
- Web Technology Lab ManualDocument30 pagesWeb Technology Lab ManualTanmay MukherjeeNo ratings yet
- Study Material CS XII For High AchieversDocument124 pagesStudy Material CS XII For High AchieversAarush MahajanNo ratings yet
- Database queries and operationsDocument5 pagesDatabase queries and operationsKaushik C100% (1)
- Java EE694cDocument8 pagesJava EE694carchana100% (1)
- Data Analytics Using Python Lab ManualDocument8 pagesData Analytics Using Python Lab ManualNayana Gowda0% (1)
- Module IIDocument22 pagesModule IIjohnsonjoshal5No ratings yet
- Manual / Guidelines: Web Technology Laboratory With Mini Project-17Csl77Document31 pagesManual / Guidelines: Web Technology Laboratory With Mini Project-17Csl77Nishath HumairaNo ratings yet
- CS8261 C Programming Lab Manual With All 18 ProgramsDocument42 pagesCS8261 C Programming Lab Manual With All 18 ProgramsKousheek VinnakotiNo ratings yet
- C# programs demonstrating command line arguments, boxing unboxing, operator overloading, arrays, exceptionsDocument75 pagesC# programs demonstrating command line arguments, boxing unboxing, operator overloading, arrays, exceptionsChandan PandaNo ratings yet
- CS3361 Data Science Lab Manual (II CYS)Document40 pagesCS3361 Data Science Lab Manual (II CYS)rajananandh72138100% (1)
- Practical-8: Create An Application in Android To Find Factorial of A Given Number Using Onclick EventDocument4 pagesPractical-8: Create An Application in Android To Find Factorial of A Given Number Using Onclick EventhdtrsNo ratings yet
- Web Technologies Lab ManualDocument97 pagesWeb Technologies Lab ManualHarsha Nihanth71% (7)
- SQL (Part 2)Document44 pagesSQL (Part 2)Tara Mecca LunaNo ratings yet
- Stack OrganizationDocument6 pagesStack OrganizationSadaf RasheedNo ratings yet
- DBMS LAB Manual Final22Document74 pagesDBMS LAB Manual Final22naveed ahmedNo ratings yet
- Question Bank ASQLDocument2 pagesQuestion Bank ASQLMeenakshi Vaylure PaulNo ratings yet
- Week 1 SolutionDocument13 pagesWeek 1 Solutionpba1 pba1No ratings yet
- Final PPTDocument39 pagesFinal PPTNitesh KumarNo ratings yet
- ADBMS Lab Manual Aug-Dec 2017 - ByMeDocument9 pagesADBMS Lab Manual Aug-Dec 2017 - ByMeDennise ShughniNo ratings yet
- Nishant Web TechDocument40 pagesNishant Web TechNishant MishraNo ratings yet
- Tricky C Questions For GATEDocument114 pagesTricky C Questions For GATEKirti KumarNo ratings yet
- Anna University: Chennai - 600 025Document6 pagesAnna University: Chennai - 600 025balaNo ratings yet
- Bank Management SystemDocument19 pagesBank Management Systemjnvbagudi32100% (2)
- DBMS Unit 3Document98 pagesDBMS Unit 3Varun GuptaNo ratings yet
- JavaDocument47 pagesJavasneha ajay nairNo ratings yet
- Practical SyllabusDocument7 pagesPractical SyllabusPooran SenNo ratings yet
- System Programming Lab Report 04Document12 pagesSystem Programming Lab Report 04Abdul RehmanNo ratings yet
- Compiler Design ProgramsDocument59 pagesCompiler Design ProgramsrajNo ratings yet
- Practical Question C#Document4 pagesPractical Question C#Vitthal Patil100% (1)
- Ai PDFDocument85 pagesAi PDFRomaldoNo ratings yet
- COMPUTER PRACTICAL FILE (Class 12)Document49 pagesCOMPUTER PRACTICAL FILE (Class 12)ishika guptaNo ratings yet
- Pincer Search AlgoDocument8 pagesPincer Search Algoaaksb123No ratings yet
- GA LAB Manual-1Document33 pagesGA LAB Manual-1Sundar Shahi ThakuriNo ratings yet
- Network Management System A Complete Guide - 2020 EditionFrom EverandNetwork Management System A Complete Guide - 2020 EditionRating: 5 out of 5 stars5/5 (1)
- Data Analytics End Term QPDocument3 pagesData Analytics End Term QPAmit PhulwaniNo ratings yet
- Schedule For Our CourseDocument7 pagesSchedule For Our CourseAmit PhulwaniNo ratings yet
- Chi-Square Test For Feature Selection in Machine LearningDocument15 pagesChi-Square Test For Feature Selection in Machine LearningAmit PhulwaniNo ratings yet
- Bank Marketing Case-Study:: Relevant Information About The DataDocument1 pageBank Marketing Case-Study:: Relevant Information About The DataAmit Phulwani100% (1)
- Data Visualization Assignment: +91-7022374614 US: 1-800-216-8930 (Toll Free)Document2 pagesData Visualization Assignment: +91-7022374614 US: 1-800-216-8930 (Toll Free)Amit PhulwaniNo ratings yet
- Prob Dist Function - ClassDocument3 pagesProb Dist Function - ClassAmit PhulwaniNo ratings yet
- Probability & Statistics Facts, Formulae and Information: Www. .Ac - UkDocument4 pagesProbability & Statistics Facts, Formulae and Information: Www. .Ac - UkAmit PhulwaniNo ratings yet
- Maths YouTube Video ListDocument39 pagesMaths YouTube Video ListAmit PhulwaniNo ratings yet
- Online Student Enrollment SystemDocument29 pagesOnline Student Enrollment SystemajidonsonNo ratings yet
- Elliott Wave Watching Part 2 Rev 1-2600717Document9 pagesElliott Wave Watching Part 2 Rev 1-2600717GateshNdegwahNo ratings yet
- Enr PlanDocument40 pagesEnr PlanShelai LuceroNo ratings yet
- Cellular Tower: Bayombong, Nueva VizcayaDocument17 pagesCellular Tower: Bayombong, Nueva VizcayaMonster PockyNo ratings yet
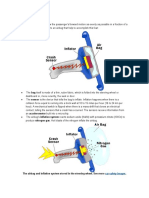
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- Appendix A - Status Messages: Armed. Bad Snubber FuseDocument9 pagesAppendix A - Status Messages: Armed. Bad Snubber Fuse이민재No ratings yet
- GC 1999 03 Minas BrethilDocument5 pagesGC 1999 03 Minas BrethilErszebethNo ratings yet
- SAP HCM - Default Wage Types - Info Type 0008Document6 pagesSAP HCM - Default Wage Types - Info Type 0008cjherrera2No ratings yet
- The Mini-Guide To Sacred Codes and SwitchwordsDocument99 pagesThe Mini-Guide To Sacred Codes and SwitchwordsJason Alex100% (9)
- Vsphere Storage PDFDocument367 pagesVsphere Storage PDFNgo Van TruongNo ratings yet
- The Essential Guide To Data in The Cloud:: A Handbook For DbasDocument20 pagesThe Essential Guide To Data in The Cloud:: A Handbook For DbasInes PlantakNo ratings yet
- Ndeb Bned Reference Texts 2019 PDFDocument11 pagesNdeb Bned Reference Texts 2019 PDFnavroop bajwaNo ratings yet
- Biokimia - DR - Maehan Hardjo M.biomed PHDDocument159 pagesBiokimia - DR - Maehan Hardjo M.biomed PHDHerryNo ratings yet
- Audiology DissertationDocument4 pagesAudiology DissertationPaperWritingHelpOnlineUK100% (1)
- Telegram Log File Details Launch Settings Fonts OpenGLDocument5 pagesTelegram Log File Details Launch Settings Fonts OpenGLThe nofrizalNo ratings yet
- (Nano and Energy) Gavin Buxton - Alternative Energy Technologies - An Introduction With Computer Simulations-CRC Press (2014) PDFDocument302 pages(Nano and Energy) Gavin Buxton - Alternative Energy Technologies - An Introduction With Computer Simulations-CRC Press (2014) PDFmarcosNo ratings yet
- Aptamers in HIV Research Diagnosis and TherapyDocument11 pagesAptamers in HIV Research Diagnosis and TherapymikiNo ratings yet
- Problem solving and decision making in nutrition postgraduate studiesDocument55 pagesProblem solving and decision making in nutrition postgraduate studiesteklayNo ratings yet
- Rectangle StabbingDocument49 pagesRectangle StabbingApurba DasNo ratings yet
- MDF 504 Investment Analysis and Portfolio Management 61017926Document3 pagesMDF 504 Investment Analysis and Portfolio Management 61017926komalkataria2003No ratings yet
- Bohemian Flower Face Mask by Maya KuzmanDocument8 pagesBohemian Flower Face Mask by Maya KuzmanDorca MoralesNo ratings yet
- Insert - Elecsys Anti-HBs II - Ms - 05894816190.V2.EnDocument4 pagesInsert - Elecsys Anti-HBs II - Ms - 05894816190.V2.EnyantuNo ratings yet
- Gen - Biology 2 Module 2Document12 pagesGen - Biology 2 Module 2Camille Castrence CaranayNo ratings yet
- 5e3 Like ApproachDocument1 page5e3 Like Approachdisse_detiNo ratings yet
- FSA&V Case StudyDocument10 pagesFSA&V Case StudyAl Qur'anNo ratings yet
- Drainage Manual: State of Florida Department of TransportationDocument78 pagesDrainage Manual: State of Florida Department of TransportationghoyarbideNo ratings yet
- Rick CobbyDocument4 pagesRick CobbyrickcobbyNo ratings yet
- Cambridge English Business Vantage Sample Paper 1 Listening v2Document5 pagesCambridge English Business Vantage Sample Paper 1 Listening v2salma23478No ratings yet
- Nad C541iDocument37 pagesNad C541iapi-3837207No ratings yet
- Topicwise Analysis For Last 10 YearsDocument20 pagesTopicwise Analysis For Last 10 YearsVAMCNo ratings yet