You might also like
- Texture Image Segmentation Using A Nity Propagation and Spectral ClusteringDocument20 pagesTexture Image Segmentation Using A Nity Propagation and Spectral ClusteringBudi Utami FahnunNo ratings yet
- Deep Radon Prior: A Fully Unsupervised Framework For Sparse-View CT ReconstructionDocument11 pagesDeep Radon Prior: A Fully Unsupervised Framework For Sparse-View CT ReconstructionDIGANTO ROYNo ratings yet
- CSPN: A N B E L C CNN: ET EW Ackbone That Can Nhance Earning Apability ofDocument14 pagesCSPN: A N B E L C CNN: ET EW Ackbone That Can Nhance Earning Apability ofdocjagNo ratings yet
- WOA PPT 26-03-24[] (1)Document23 pagesWOA PPT 26-03-24[] (1)venur239No ratings yet
- A Fast Hybrid Level Set Model For Image Segmentation Using Lattice Boltzmann Method and Sparse Field ConstraintDocument24 pagesA Fast Hybrid Level Set Model For Image Segmentation Using Lattice Boltzmann Method and Sparse Field ConstraintAzis SubanNo ratings yet
- Danupon Chansong_Siriporn Supratid_2021_Impacts of Kernel Size on Different Resized Images in Object Recognition BasedDocument4 pagesDanupon Chansong_Siriporn Supratid_2021_Impacts of Kernel Size on Different Resized Images in Object Recognition Basedbigliang98No ratings yet
- AdvancedAIDocument184 pagesAdvancedAIKRamakrishnaNo ratings yet
- Remote SensingDocument20 pagesRemote Sensingvrp bkpNo ratings yet
- A Deep-Neural-Network-Based Relay Selection Scheme in Wireless-Powered Cognitive Iot NetworksDocument14 pagesA Deep-Neural-Network-Based Relay Selection Scheme in Wireless-Powered Cognitive Iot NetworksprazetyoNo ratings yet
- Image Denoising Network Based On Subband Information Sharing Using Dual-Tree Complex WaveletDocument17 pagesImage Denoising Network Based On Subband Information Sharing Using Dual-Tree Complex WaveletMay Thet TunNo ratings yet
- WOA_PPT_29-03-24[1]Document36 pagesWOA_PPT_29-03-24[1]venur239No ratings yet
- Modeling and Signal Integrity Analysis of RRAM-Based Neuromorphic Chip Crossbar Array Using Partial Equivalent Element Circuit (PEEC) MethodDocument11 pagesModeling and Signal Integrity Analysis of RRAM-Based Neuromorphic Chip Crossbar Array Using Partial Equivalent Element Circuit (PEEC) MethodツギハギスタッカートNo ratings yet
- UTNet A Hybrid Transformer Architecture For Medical Image Segmentation PDFDocument11 pagesUTNet A Hybrid Transformer Architecture For Medical Image Segmentation PDFdaisyNo ratings yet
- Model Transferability From ImageNet To Lithography HotspotDocument9 pagesModel Transferability From ImageNet To Lithography Hotspotameed shahNo ratings yet
- Machine learning designs 1D photonic crystals for visible light spectraDocument18 pagesMachine learning designs 1D photonic crystals for visible light spectrayassinebouazziNo ratings yet
- 2022-Learning Discriminative Features by Covering Local Geometric Space For Point Cloud AnalysisDocument16 pages2022-Learning Discriminative Features by Covering Local Geometric Space For Point Cloud AnalysisHarshil NaikNo ratings yet
- Micro NetDocument14 pagesMicro NetAshish SinghNo ratings yet
- HybridCNN Based Hyperspectral Image Classification Using Multiscalespatiospectral FeaturesDocument10 pagesHybridCNN Based Hyperspectral Image Classification Using Multiscalespatiospectral FeaturesAlkha JayakrishnanNo ratings yet
- Jurnal PCDDocument14 pagesJurnal PCDwhyuachmd shfrdnNo ratings yet
- An Object For Finding An Effective and Source Authentication Mechanism For Multicast Communication in The Hash Tree: Survey PaperDocument11 pagesAn Object For Finding An Effective and Source Authentication Mechanism For Multicast Communication in The Hash Tree: Survey PaperIJRASETPublicationsNo ratings yet
- Accepted Manuscript: Journal of Neuroscience MethodsDocument13 pagesAccepted Manuscript: Journal of Neuroscience MethodsChrisilla SNo ratings yet
- Context-Aware Attentional Graph U-Net ForDocument5 pagesContext-Aware Attentional Graph U-Net Forlin mouleNo ratings yet
- Yamashita2018 Article ConvolutionalNeuralNetworksAnODocument19 pagesYamashita2018 Article ConvolutionalNeuralNetworksAnOyihoNo ratings yet
- Optimizing Performance of Convolutional Neural Network Using Computing TechniqueDocument4 pagesOptimizing Performance of Convolutional Neural Network Using Computing TechniqueNguyen Van ToanNo ratings yet
- mid2_Wang_Decoupling-and-Aggregating_for_Image_Exposure_CorrectionDocument10 pagesmid2_Wang_Decoupling-and-Aggregating_for_Image_Exposure_Correctionperry1005No ratings yet
- Pusuluri 12020 HomoclinicDocument28 pagesPusuluri 12020 Homocliniccesar abraham torrico chavezNo ratings yet
- Exact Decomposition of Joint Low Rankness and Local Smoothness Plus Sparse Matrices PDFDocument16 pagesExact Decomposition of Joint Low Rankness and Local Smoothness Plus Sparse Matrices PDFAMISHI VIJAY VIJAYNo ratings yet
- A Review On An Efficient Multi-Focus Image Fusion Scheme Based On PCNNDocument3 pagesA Review On An Efficient Multi-Focus Image Fusion Scheme Based On PCNNJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Convolutional Neural Networks: An Overview and Application in RadiologyDocument20 pagesConvolutional Neural Networks: An Overview and Application in RadiologyAnnNo ratings yet
- 2022 RIS-Aided Mmwave MIMODocument14 pages2022 RIS-Aided Mmwave MIMOAnirban KanungoeNo ratings yet
- Biomedical Research PaperDocument7 pagesBiomedical Research PaperSathvik ShenoyNo ratings yet
- Topological Insights Into Sparse Neural NetworksDocument17 pagesTopological Insights Into Sparse Neural NetworksSanjay DasNo ratings yet
- PDE Based NNDocument13 pagesPDE Based NNAman JalanNo ratings yet
- Graph Neural Networks: A Review of Methods and ApplicationsDocument22 pagesGraph Neural Networks: A Review of Methods and ApplicationsRafael LimaNo ratings yet
- MLMIDocument9 pagesMLMIAFFAFFNo ratings yet
- Convolutional Neural Network For Image RecognitionDocument8 pagesConvolutional Neural Network For Image RecognitionIJRASETPublicationsNo ratings yet
- Improved U-Net segmentation integrates effective channel attentionDocument8 pagesImproved U-Net segmentation integrates effective channel attentionHasnain Ali ShahNo ratings yet
- 1 s2.0 S2213138822001102 MainDocument8 pages1 s2.0 S2213138822001102 MainGuru VelmathiNo ratings yet
- AVRM: Adaptive Void Recovery Mechanism To Reduce Void Nodes in Wireless Sensor NetworksDocument15 pagesAVRM: Adaptive Void Recovery Mechanism To Reduce Void Nodes in Wireless Sensor NetworksPhạm MinhNo ratings yet
- Early Warning Via Transitions in Latent Stochastic Dynamical SystemsDocument14 pagesEarly Warning Via Transitions in Latent Stochastic Dynamical Systemsliyene3869No ratings yet
- Sensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkDocument20 pagesSensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkKratika VarshneyNo ratings yet
- Analog Implementation2Document6 pagesAnalog Implementation2ANKIT KUMAR RAINo ratings yet
- Paper 2Document13 pagesPaper 2Asmi SinhaNo ratings yet
- Graph Neural Network Review and ApplicationsDocument20 pagesGraph Neural Network Review and ApplicationsTheStupidityOfPplNo ratings yet
- Zhang Dongxiao-Efficient Uncertainty Quantification For Dynamic Subsurface Flow With Surrogate by Theory-Guided Neural NetworkDocument27 pagesZhang Dongxiao-Efficient Uncertainty Quantification For Dynamic Subsurface Flow With Surrogate by Theory-Guided Neural NetworkJerry GreyNo ratings yet
- 1 s2.0 S0031320322003065 MainDocument10 pages1 s2.0 S0031320322003065 MainWided HechkelNo ratings yet
- 1 s2.0 S0167739X20330259 MainDocument9 pages1 s2.0 S0167739X20330259 Mainzhujin1121No ratings yet
- A Survey On Pest Detectionand Pesticide Recommendationusing CNN AlgorithmDocument5 pagesA Survey On Pest Detectionand Pesticide Recommendationusing CNN AlgorithmIJRASETPublicationsNo ratings yet
- DECT Image Decomposition With Learned Mixed Material ModelsDocument16 pagesDECT Image Decomposition With Learned Mixed Material ModelsTeo TeoNo ratings yet
- Oishi - Finite Elements Using Neural Networks and A Posteriori ErrorDocument24 pagesOishi - Finite Elements Using Neural Networks and A Posteriori ErrorbakidokiNo ratings yet
- A Study of Garbage Classification With CNNDocument6 pagesA Study of Garbage Classification With CNNRezwan AhmedNo ratings yet
- Applications of Neural Networks for Spectrum Prediction and Inverse Design in the Terahertz BandDocument10 pagesApplications of Neural Networks for Spectrum Prediction and Inverse Design in the Terahertz BandISI IndiaNo ratings yet
- Low Pass FilteringDocument6 pagesLow Pass FilteringNur RahmaNo ratings yet
- Terahertz Spatio-Temporal Deep Learning Computed TDocument13 pagesTerahertz Spatio-Temporal Deep Learning Computed Tkohli mayankNo ratings yet
- EDP An Efficient Decomposition and Pruning SchemeDocument15 pagesEDP An Efficient Decomposition and Pruning SchemeErica BalondoNo ratings yet
- A High Capacity Image Steganography Using Multi-Layer EmbeddingDocument8 pagesA High Capacity Image Steganography Using Multi-Layer EmbeddingAldo jimenezNo ratings yet
- An Introduction To Convolutional Neural NetworksDocument7 pagesAn Introduction To Convolutional Neural NetworksIJRASETPublicationsNo ratings yet
- Areviewonthedesignof Ternary Logic CircuitsDocument21 pagesAreviewonthedesignof Ternary Logic CircuitshanumeshvburliNo ratings yet
- A DOA Estimation Method of Coherent and Uncorrelated Sources Based On Nested ArraysDocument4 pagesA DOA Estimation Method of Coherent and Uncorrelated Sources Based On Nested ArraysaaNo ratings yet
- Experiment No.-1: With Continuous Supply of Fresh Gas and Removal of The Products of DiffusionDocument25 pagesExperiment No.-1: With Continuous Supply of Fresh Gas and Removal of The Products of DiffusionSohini RoyNo ratings yet
- Electronics 10 02756Document30 pagesElectronics 10 02756Sohini RoyNo ratings yet
- A Frequency Domain Neural Network For Fast Image Super-ResolutionDocument9 pagesA Frequency Domain Neural Network For Fast Image Super-ResolutionSohini RoyNo ratings yet
- Q and R VariationsDocument7 pagesQ and R VariationsSohini RoyNo ratings yet
- A Frequency Domain Approach To Registration Ofaliased Images With Application To Super-ResolutionDocument16 pagesA Frequency Domain Approach To Registration Ofaliased Images With Application To Super-ResolutionSohini RoyNo ratings yet
- Department of Chemical Engineering: List of Experiments in Mass Transfer Operations LaboratoryDocument121 pagesDepartment of Chemical Engineering: List of Experiments in Mass Transfer Operations LaboratorySohini RoyNo ratings yet
- Measuring Diffusivity of Carbon Tetrachloride Using TemperatureDocument19 pagesMeasuring Diffusivity of Carbon Tetrachloride Using TemperatureSohini RoyNo ratings yet
- An Efficient Super-Resolution Algorithm For IR TheDocument7 pagesAn Efficient Super-Resolution Algorithm For IR TheSohini RoyNo ratings yet
- Guidelines and General Instructions For Mass Transfer Laboratory (CH39006)Document2 pagesGuidelines and General Instructions For Mass Transfer Laboratory (CH39006)Sohini RoyNo ratings yet
- Microsoft Module 2 Task 2 - Model Answer PDFDocument2 pagesMicrosoft Module 2 Task 2 - Model Answer PDFsolaiman9sayemNo ratings yet
- Sample Paper 1Document5 pagesSample Paper 1Sohini RoyNo ratings yet
- Mass Transfer Assignment SolutionsDocument7 pagesMass Transfer Assignment SolutionsSohini RoyNo ratings yet
- Assignment 5 - MT1-2019Document6 pagesAssignment 5 - MT1-2019Sohini RoyNo ratings yet
- Problem Set Solutions for LTI SystemsDocument5 pagesProblem Set Solutions for LTI SystemsPankaj MishraNo ratings yet
- Model Answer Engineering: What To Expect From Your Virtual InternshipDocument7 pagesModel Answer Engineering: What To Expect From Your Virtual InternshipAshutosh TripathiNo ratings yet
- Microsoft Module 5 Task 9 - Model AnswerDocument6 pagesMicrosoft Module 5 Task 9 - Model Answerabdullah noorNo ratings yet
- Microsoft Module 2 Task 2 - Model Answer PDFDocument2 pagesMicrosoft Module 2 Task 2 - Model Answer PDFsolaiman9sayemNo ratings yet
- CH 6 Fundamental of MIcroelectronics Bahzad Razavi Chapter 6 Solution ManualDocument55 pagesCH 6 Fundamental of MIcroelectronics Bahzad Razavi Chapter 6 Solution ManualSumra MaqboolNo ratings yet
- FINAL Industry and Company AwarenessDocument98 pagesFINAL Industry and Company AwarenessSatyanarayanaNo ratings yet
- Design and Implementation of 64 Bit Multiplier Using Vedic Algorithm (Final Report)Document20 pagesDesign and Implementation of 64 Bit Multiplier Using Vedic Algorithm (Final Report)Sohini RoyNo ratings yet
- Design of Fast Dadda Multiplier Using Vedic Mathematics: Sathish@svce - Ac.inDocument8 pagesDesign of Fast Dadda Multiplier Using Vedic Mathematics: Sathish@svce - Ac.inSohini RoyNo ratings yet
- Electronics: Assessment of A Smart Sensing Shoe For Gait Phase Detection in Level WalkingDocument15 pagesElectronics: Assessment of A Smart Sensing Shoe For Gait Phase Detection in Level WalkingFinaz JamilNo ratings yet
- CH 6 Fundamental of MIcroelectronics Bahzad Razavi Chapter 6 Solution ManualDocument55 pagesCH 6 Fundamental of MIcroelectronics Bahzad Razavi Chapter 6 Solution ManualSumra MaqboolNo ratings yet
- E0801014346 PDFDocument5 pagesE0801014346 PDFRocker byNo ratings yet
- Tutorial Sheet - 06 (Transformer) : A B E N NDocument2 pagesTutorial Sheet - 06 (Transformer) : A B E N NSohini RoyNo ratings yet
- CH 7Document85 pagesCH 7Sohini RoyNo ratings yet
- ET Tut7 AUT2017-18Document2 pagesET Tut7 AUT2017-18raviNo ratings yet
- ET Tut7 AUT2017-18Document2 pagesET Tut7 AUT2017-18raviNo ratings yet
- Et Practice 2Document6 pagesEt Practice 2Sohini RoyNo ratings yet
- CAPS LESSON PLAN, KAHOOT QUIZ, PPT VIDEODocument3 pagesCAPS LESSON PLAN, KAHOOT QUIZ, PPT VIDEOMandisa MselekuNo ratings yet
- Chapter 3 Week 1 Inductive and Deductive ReasoningDocument57 pagesChapter 3 Week 1 Inductive and Deductive ReasoningDiane Agcaoili Edra50% (6)
- MF ISIN CodeDocument49 pagesMF ISIN CodeshriramNo ratings yet
- Catanduanes State University: Page 1 of 12Document12 pagesCatanduanes State University: Page 1 of 12Jonah reiNo ratings yet
- 01 - Narmada M PhilDocument200 pages01 - Narmada M PhilafaceanNo ratings yet
- Chemists 12-2023Document7 pagesChemists 12-2023PRC BaguioNo ratings yet
- Customer Satisfaction in Maruti SuzukiDocument31 pagesCustomer Satisfaction in Maruti Suzukirajesh laddha100% (1)
- Breaugh Starke PDFDocument30 pagesBreaugh Starke PDFRichard YeongNo ratings yet
- About WELDA Anchor PlateDocument1 pageAbout WELDA Anchor PlateFircijevi KurajberiNo ratings yet
- Recipe of Medical AirDocument13 pagesRecipe of Medical AirMd. Rokib ChowdhuryNo ratings yet
- Capacity Based On Shear Parameters As Per IS 6403: C C C C W Q Q Q Q F y y y yDocument5 pagesCapacity Based On Shear Parameters As Per IS 6403: C C C C W Q Q Q Q F y y y yKishore KumarNo ratings yet
- Gripper of FTV Invisio Panels For Horizontal FacadeDocument16 pagesGripper of FTV Invisio Panels For Horizontal FacadefghfNo ratings yet
- OTISLINE QuestionsDocument5 pagesOTISLINE QuestionsArvind Gupta100% (1)
- MIT LL. Target Radar Cross Section (RCS)Document45 pagesMIT LL. Target Radar Cross Section (RCS)darin koblickNo ratings yet
- Korean Enthusiasm and PatriotismDocument68 pagesKorean Enthusiasm and PatriotismYukino Hera100% (1)
- 337 686 1 SMDocument8 pages337 686 1 SMK61 ĐOÀN HỒ GIA HUYNo ratings yet
- Cracking The SQL InterviewDocument52 pagesCracking The SQL InterviewRedouan AFLISSNo ratings yet
- (Food Engineering Series) Gustavo V Barbosa-Cánovas - Humberto Vega-Mercado - Dehydration of Foods PDFDocument339 pages(Food Engineering Series) Gustavo V Barbosa-Cánovas - Humberto Vega-Mercado - Dehydration of Foods PDFLis FernandesNo ratings yet
- Qualitative Research On Vocabulary and Spelling Skills of A Student Chapters I IIIDocument23 pagesQualitative Research On Vocabulary and Spelling Skills of A Student Chapters I IIIarniza blazoNo ratings yet
- Historical Background of The SchoolDocument2 pagesHistorical Background of The SchoolJoel Daen50% (2)
- Repport Btech FinalDocument49 pagesRepport Btech FinalSuzelle NGOUNOU MAGANo ratings yet
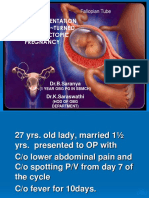
- Clinical Presentation of Ectopic Pregnancy Turned Out to Be Ectopic PregnancyDocument33 pagesClinical Presentation of Ectopic Pregnancy Turned Out to Be Ectopic PregnancyRosiNo ratings yet
- Exclusion and Lack of Accessibility in TheatreDocument12 pagesExclusion and Lack of Accessibility in TheatrebethanyslaterNo ratings yet
- Lyrics: Original Songs: - JW BroadcastingDocument56 pagesLyrics: Original Songs: - JW BroadcastingLucky MorenoNo ratings yet
- Piano: Grade 2: PiecesDocument4 pagesPiano: Grade 2: PiecesnolozeNo ratings yet
- Diosdado MacapagalDocument13 pagesDiosdado MacapagalMermie ArmentaNo ratings yet
- Certified Islamic Professional Accountant (Cipa) ProgramDocument13 pagesCertified Islamic Professional Accountant (Cipa) ProgramTijjani Ridwanulah AdewaleNo ratings yet
- Lifeboat Equipment ListDocument1 pageLifeboat Equipment Listjosua albertNo ratings yet
- Hatsun Supplier Registration RequestDocument4 pagesHatsun Supplier Registration Requestsan dipNo ratings yet
- Advantages and Disadvantages of Becoming EntrepreneurDocument2 pagesAdvantages and Disadvantages of Becoming EntrepreneurbxndNo ratings yet




![WOA PPT 26-03-24[] (1)](https://imgv2-1-f.scribdassets.com/img/document/720532113/149x198/ce9bbf1ae4/1712389058?v=1)






![WOA_PPT_29-03-24[1]](https://imgv2-1-f.scribdassets.com/img/document/720532132/149x198/f421208759/1712389047?v=1)