You might also like
- Bid No Bid WorksheetDocument5 pagesBid No Bid WorksheetBobbyNicholsNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- HDL-BUS Pro Programming ManualDocument121 pagesHDL-BUS Pro Programming ManualSebastian LagosNo ratings yet
- Cognitive Task AnalysisDocument3 pagesCognitive Task AnalysisCraig MawsonNo ratings yet
- 02 Industrial Waste ManagementDocument458 pages02 Industrial Waste ManagementJose Luis MarcovichNo ratings yet
- The Influence of Consciousness in The Physical World: A Psychologist's ViewDocument12 pagesThe Influence of Consciousness in The Physical World: A Psychologist's ViewEnshinNo ratings yet
- Stanford University CS 229, Autumn 2014 Midterm ExaminationDocument23 pagesStanford University CS 229, Autumn 2014 Midterm ExaminationErico ArchetiNo ratings yet
- Waltke Crux Genre GenesisDocument9 pagesWaltke Crux Genre GenesisJosé BarajasNo ratings yet
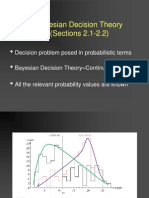
- Bayesian Decision TheoryDocument63 pagesBayesian Decision TheoryBindu Narayanan NampoothiriNo ratings yet
- Bayesian Decision Theory: CS479/679 Pattern Recognition Dr. George BebisDocument64 pagesBayesian Decision Theory: CS479/679 Pattern Recognition Dr. George Bebisএ.এস. সাকিবNo ratings yet
- Lecture 5Document16 pagesLecture 5Alireza MovahedianNo ratings yet
- Bayesian Decision Theory: Prof. Richard ZanibbiDocument47 pagesBayesian Decision Theory: Prof. Richard Zanibbishivani_himaniNo ratings yet
- Bayes&Voice RecognitionDocument76 pagesBayes&Voice RecognitionEdgar ArroyoNo ratings yet
- Machine Learning - Unit 2Document104 pagesMachine Learning - Unit 2sandtNo ratings yet
- CS 563 Advanced Topics in Computer Graphics Monte Carlo Integration: Basic ConceptsDocument38 pagesCS 563 Advanced Topics in Computer Graphics Monte Carlo Integration: Basic ConceptsNeha SameerNo ratings yet
- Bayes Sample QuestionsDocument2 pagesBayes Sample QuestionsRekha RaniNo ratings yet
- DHSCH 2Document88 pagesDHSCH 2obsidian555No ratings yet
- Pattern Classification PDFDocument39 pagesPattern Classification PDFandrey90No ratings yet
- Pattern ClassificationDocument39 pagesPattern ClassificationemanfatNo ratings yet
- Pattern ClassificationDocument39 pagesPattern ClassificationHARDIK ANANDNo ratings yet
- Bayesian TheoryDocument66 pagesBayesian TheoryPaul WalkerNo ratings yet
- Pattern ClassificationDocument39 pagesPattern ClassificationimjoshuarobertNo ratings yet
- Random Variables and Probability DistributionDocument73 pagesRandom Variables and Probability Distributionkelihe8947No ratings yet
- Statistics 202C Study Guide: Part I: Sampling Basic Unstructured Distributions and Monte Carlo BasicsDocument14 pagesStatistics 202C Study Guide: Part I: Sampling Basic Unstructured Distributions and Monte Carlo Basicsmr_joshuagordonNo ratings yet
- BayesDocument10 pagesBayesRao SaifullahNo ratings yet
- Revised Lecture Notes 2Document16 pagesRevised Lecture Notes 2engshaimaaelsayedNo ratings yet
- Risk Minimization Bayes ClassifierDocument13 pagesRisk Minimization Bayes Classifiersuman DasNo ratings yet
- HW 1 SolDocument6 pagesHW 1 SolSekharNaikNo ratings yet
- MCIntroDocument14 pagesMCIntroNguyễn Mai PhươngNo ratings yet
- Bayesian Decision Theory: Intro ToDocument56 pagesBayesian Decision Theory: Intro ToDevil DeluxeNo ratings yet
- Homework1 SolutionsDocument5 pagesHomework1 SolutionsMohan VirkhareNo ratings yet
- Tutorial Problems Day 1Document3 pagesTutorial Problems Day 1Tejas DusejaNo ratings yet
- Learning-DemoDocument7 pagesLearning-DemoHome Workout PlanNo ratings yet
- Classification L12Document20 pagesClassification L12nsephus3No ratings yet
- PR January20 04 PDFDocument40 pagesPR January20 04 PDFNadia AnjumNo ratings yet
- 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010: Aarti Singh Carnegie Mellon UniversityDocument16 pages10-701/15-781 Machine Learning - Midterm Exam, Fall 2010: Aarti Singh Carnegie Mellon UniversityMahi SNo ratings yet
- CH 8Document48 pagesCH 8marcoteran007No ratings yet
- Unit 4 - Logistic RegressionDocument26 pagesUnit 4 - Logistic RegressionshinjoNo ratings yet
- Bayes Decision Theory: How To Make Decisions in The Presence of Uncertainty?Document16 pagesBayes Decision Theory: How To Make Decisions in The Presence of Uncertainty?Derick MendozaNo ratings yet
- EC744 Lecture Note 8 Applications of Stochastic DP: Prof. Jianjun MiaoDocument31 pagesEC744 Lecture Note 8 Applications of Stochastic DP: Prof. Jianjun MiaobinicleNo ratings yet
- MCMC BriefDocument69 pagesMCMC Briefjakub_gramolNo ratings yet
- Pattern Classification: All Materials in These Slides Were Taken FromDocument44 pagesPattern Classification: All Materials in These Slides Were Taken FromShahriar StudentNo ratings yet
- 1 Stat Superv ParametricDocument4 pages1 Stat Superv ParametricAshishAmitavNo ratings yet
- Kuliah 3 Teori Keputusan Bayes Bag 2Document30 pagesKuliah 3 Teori Keputusan Bayes Bag 2Teddy EkatamtoNo ratings yet
- AMS526: Numerical Analysis I (Numerical Linear Algebra) : Lecture 08: Floating Point Arithmetic Condition NumbersDocument14 pagesAMS526: Numerical Analysis I (Numerical Linear Algebra) : Lecture 08: Floating Point Arithmetic Condition NumbersNikhilSharmaNo ratings yet
- Adaboost MatasDocument136 pagesAdaboost MatasSơn Nguyễn QuýNo ratings yet
- Cramer RaoDocument11 pagesCramer Raoshahilshah1919No ratings yet
- Lecture01 Uppsala EQG 12Document39 pagesLecture01 Uppsala EQG 12Henz RabinoNo ratings yet
- Derivative RulesDocument8 pagesDerivative RuleslukeNo ratings yet
- Math 111Document163 pagesMath 111John Fritz SinghNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- FIT5197 2021 S1 Formula SheetDocument20 pagesFIT5197 2021 S1 Formula Sheetrenu.tamsekarNo ratings yet
- Probability DistributionsDocument7 pagesProbability DistributionsJiteshNo ratings yet
- Lecture 1Document48 pagesLecture 1GauravNo ratings yet
- 2x2 Contingency Tables: Handy Reference Sheet - Hrp/Stats 261, Discrete DataDocument6 pages2x2 Contingency Tables: Handy Reference Sheet - Hrp/Stats 261, Discrete DataKristine How Sta CruzNo ratings yet
- Advanced StatisticsDocument75 pagesAdvanced StatisticsMoamen AhmedNo ratings yet
- Chapter 2.4Document11 pagesChapter 2.4Foyshel RahmanNo ratings yet
- Chapter 2.4Document11 pagesChapter 2.4Atique FaisalNo ratings yet
- Unit-Ii Bayesian Decision TheoryDocument22 pagesUnit-Ii Bayesian Decision TheoryJoyce GeorgeNo ratings yet
- Probability DistributionsDocument85 pagesProbability DistributionsEduardo JfoxmixNo ratings yet
- Sergios Theodoridis Konstantinos KoutroumbasDocument80 pagesSergios Theodoridis Konstantinos KoutroumbasKumarNo ratings yet
- Estimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelDocument19 pagesEstimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelAboubacrène Ag AhmadNo ratings yet
- Estimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelDocument19 pagesEstimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelAboubacrène Ag AhmadNo ratings yet
- BU255 - All Formulas 2022fallDocument9 pagesBU255 - All Formulas 2022fallTony TheodoropoulosNo ratings yet
- FM200 - Co2 Clac.Document4 pagesFM200 - Co2 Clac.Anas TubailNo ratings yet
- Fire Fighting 1Document117 pagesFire Fighting 1Anas TubailNo ratings yet
- HMM HW SolutionsDocument13 pagesHMM HW SolutionsAnas TubailNo ratings yet
- Hvac FinalDocument34 pagesHvac FinalAnas TubailNo ratings yet
- Work Experience: Embedded System DesignerDocument1 pageWork Experience: Embedded System DesignerAnas TubailNo ratings yet
- hw3 SolutionDocument7 pageshw3 SolutionAnas TubailNo ratings yet
- CH 5 Review Failures Resulting From Static Loading 2015Document18 pagesCH 5 Review Failures Resulting From Static Loading 2015Anas TubailNo ratings yet
- CH 4 Review Delection and Stiffness1Document12 pagesCH 4 Review Delection and Stiffness1Anas TubailNo ratings yet
- CH 3 Review Load and Stress AnalysisDocument33 pagesCH 3 Review Load and Stress AnalysisAnas TubailNo ratings yet
- CH8 Screws Fasteners and The Design of Nonpermanent Joints 2015Document129 pagesCH8 Screws Fasteners and The Design of Nonpermanent Joints 2015Anas TubailNo ratings yet
- HVAC Chapter 6Document63 pagesHVAC Chapter 6Anas TubailNo ratings yet
- CH 10 - Mechanical SpringsDocument89 pagesCH 10 - Mechanical SpringsAnas TubailNo ratings yet
- Kalpakjian 6e iCARE Ch00 OnlineDocument47 pagesKalpakjian 6e iCARE Ch00 OnlineAnas TubailNo ratings yet
- QuizDocument2 pagesQuizAnas TubailNo ratings yet
- CNC HW3: Warning: Any Student Makes A Copy From Another Student, Both Will Take Zero MarkDocument1 pageCNC HW3: Warning: Any Student Makes A Copy From Another Student, Both Will Take Zero MarkAnas TubailNo ratings yet
- Chapter 1 Questions: 1) What Are The Most Things Should You Concern About When You Manufacture Any Product?Document4 pagesChapter 1 Questions: 1) What Are The Most Things Should You Concern About When You Manufacture Any Product?Anas TubailNo ratings yet
- Experiment Ii Introduction To Computer Numerical Control IiDocument5 pagesExperiment Ii Introduction To Computer Numerical Control IiAnas TubailNo ratings yet
- General IntroductionDocument16 pagesGeneral IntroductionAnas TubailNo ratings yet
- Chapter (10) Discussion QuestionsDocument9 pagesChapter (10) Discussion QuestionsAnas TubailNo ratings yet
- Computer Numerical Control CNC Homework 1: Write The Suitable G-Code Using 1-Absolute Mode 2 - Incremental ModeDocument1 pageComputer Numerical Control CNC Homework 1: Write The Suitable G-Code Using 1-Absolute Mode 2 - Incremental ModeAnas TubailNo ratings yet
- Experiment I Introduction To Computer Numerical Control I: PageDocument2 pagesExperiment I Introduction To Computer Numerical Control I: PageAnas TubailNo ratings yet
- Computer Numerical Control CNC Homework 1: Write The Suitable G-Code Using 1-Absolute Mode 2 - Incremental ModeDocument1 pageComputer Numerical Control CNC Homework 1: Write The Suitable G-Code Using 1-Absolute Mode 2 - Incremental ModeAnas TubailNo ratings yet
- Why Is It Important?": Effective CommunicatiomDocument17 pagesWhy Is It Important?": Effective CommunicatiomQurat-ul-ain abroNo ratings yet
- FP - A.1 - Consequential Damage and Inspection Techniques From Lack of Lubrication, Steam Turbine CaseDocument14 pagesFP - A.1 - Consequential Damage and Inspection Techniques From Lack of Lubrication, Steam Turbine Casemhdsoleh100% (1)
- Calibration of GlasswareDocument6 pagesCalibration of GlasswareRoyale PjyNo ratings yet
- The Nectar of InstructionDocument88 pagesThe Nectar of InstructionKrishnaRam100% (1)
- Darwin's Journey Scoresheet (x3) v1.1Document1 pageDarwin's Journey Scoresheet (x3) v1.1karl san her0% (1)
- Clock Dividers Made EasyDocument25 pagesClock Dividers Made Easyanubhaw2004No ratings yet
- Cu ComplexesDocument8 pagesCu ComplexesvicianmNo ratings yet
- APCC Aps 12.1 SCPH Analytical-Framework-ParametersDocument26 pagesAPCC Aps 12.1 SCPH Analytical-Framework-ParametersJose LaraNo ratings yet
- Jhs Competencies Highest Lowest ScoresDocument55 pagesJhs Competencies Highest Lowest ScoresAileen Bongat DimituiNo ratings yet
- Network Models 05Document9 pagesNetwork Models 05api-3814100No ratings yet
- Participatory Irrigation Sector Project (Pisp)Document35 pagesParticipatory Irrigation Sector Project (Pisp)Maman Rustaman100% (1)
- Formulación de Insecticida A Base de Oleato de Nicotina Por Caseinato de Sodione OilDocument6 pagesFormulación de Insecticida A Base de Oleato de Nicotina Por Caseinato de Sodione OiljesiNo ratings yet
- Linux Command Line BasicsDocument7 pagesLinux Command Line BasicsMeow SoftwareNo ratings yet
- Aktu Result PDFDocument2 pagesAktu Result PDFDeepak KumarNo ratings yet
- Probability and Statistics: Khusnun Widiyati, PHD Department of Mechanical EngineeringDocument38 pagesProbability and Statistics: Khusnun Widiyati, PHD Department of Mechanical EngineeringiqbalNo ratings yet
- Dumitriu 2018 IOP Conf. Ser. Mater. Sci. Eng. 400 042020 PDFDocument10 pagesDumitriu 2018 IOP Conf. Ser. Mater. Sci. Eng. 400 042020 PDFFabiano OliveiraNo ratings yet
- Multiple Choice Test Bank Questions No Feedback - Chapter 3Document5 pagesMultiple Choice Test Bank Questions No Feedback - Chapter 3Đức Nghĩa100% (1)
- Error MessagesDocument1,742 pagesError Messagesabhifocus100% (3)
- Market Research - MBA Lecture Notes Presentation - 4Document28 pagesMarket Research - MBA Lecture Notes Presentation - 4Alper Orhun KilicNo ratings yet
- Could Copper Pillar Change The OSAT EcosystemDocument4 pagesCould Copper Pillar Change The OSAT EcosystemrhaudiogeekNo ratings yet
- Structural Design of High-Rise Buildings With Passive Control DevicesDocument47 pagesStructural Design of High-Rise Buildings With Passive Control DevicesProduksi Regional Rusunawa0% (1)
- Mario Andrade Internal Controls and Risk Management EnglishDocument30 pagesMario Andrade Internal Controls and Risk Management EnglishInternational Consortium on Governmental Financial ManagementNo ratings yet
- Data ControlDocument12 pagesData Controlapi-3742735No ratings yet
- SB516A Inspection and Removal of TCM and Bendix S-20 and S-1200 Series Impulse Coupling Magnetos +++ PDFDocument2 pagesSB516A Inspection and Removal of TCM and Bendix S-20 and S-1200 Series Impulse Coupling Magnetos +++ PDFNickNo ratings yet