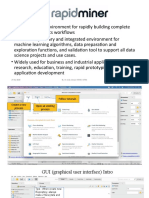
You might also like
- Wiring Diagrams STR 18 M / 28 D / 38 S / 58 U: Masterpact: ConnectionDocument21 pagesWiring Diagrams STR 18 M / 28 D / 38 S / 58 U: Masterpact: ConnectionSidali KilardjNo ratings yet
- OptistructDocument85 pagesOptistructSahithyananda ShashidharNo ratings yet
- Petrel 2013 Product Technical Update for Reservoir Engineering and GeomechanicsDocument34 pagesPetrel 2013 Product Technical Update for Reservoir Engineering and GeomechanicshaniaemanNo ratings yet
- Democratizing AI, and Surviving Titanic With Automated Machine Learning - Adnan MasoodDocument21 pagesDemocratizing AI, and Surviving Titanic With Automated Machine Learning - Adnan MasoodscottNo ratings yet
- DSE 6010-6020-ManualDocument62 pagesDSE 6010-6020-ManualVadimNo ratings yet
- Machine learning in mineral processing for abnormal event detection and soft sensor applicationsDocument24 pagesMachine learning in mineral processing for abnormal event detection and soft sensor applicationsMartin.c.figueroaNo ratings yet
- The Simulation of Mineral Processing Machinery, W.J. WhitenDocument3 pagesThe Simulation of Mineral Processing Machinery, W.J. WhitenTsakalakis G. KonstantinosNo ratings yet
- USIM PAC 3.0: New Features For A Global Approach in Mineral Processing DesignDocument13 pagesUSIM PAC 3.0: New Features For A Global Approach in Mineral Processing DesignDirceu NascimentoNo ratings yet
- L03 The Regression PipelineDocument94 pagesL03 The Regression PipelineYONG LONG KHAWNo ratings yet
- CIM UG Genval Panel SessionDocument17 pagesCIM UG Genval Panel SessionalimaghamiNo ratings yet
- 059 0058 PDFDocument10 pages059 0058 PDFzainNo ratings yet
- Time Series Anomaly Detection With DLDocument18 pagesTime Series Anomaly Detection With DLAnonymous 9tJYscsNo ratings yet
- 1994c Apcom Slovenie Opti MoinhoDocument10 pages1994c Apcom Slovenie Opti MoinhoDirceu NascimentoNo ratings yet
- UCS RM Intro-EtlDocument30 pagesUCS RM Intro-Etlnur ashfaralianaNo ratings yet
- Thesis PresentationDocument39 pagesThesis PresentationSakhaoat HossainNo ratings yet
- MLOps Asilla 20221124Document16 pagesMLOps Asilla 20221124khanh chuhuuNo ratings yet
- Modal DATASHEET: Analyze Structural DynamicsDocument12 pagesModal DATASHEET: Analyze Structural DynamicsОлег ЗахарийNo ratings yet
- Concrete Mixture Assembly Line Improvement Using ARENA Simulation - A Case StudyDocument5 pagesConcrete Mixture Assembly Line Improvement Using ARENA Simulation - A Case StudyEditor IJTSRDNo ratings yet
- Quality Prediction in A Mining ProcessDocument4 pagesQuality Prediction in A Mining ProcesspunithNo ratings yet
- Jksimmet: Steady State Processing Plant SimulatorDocument47 pagesJksimmet: Steady State Processing Plant SimulatorfabiolaNo ratings yet
- 2022 05 ISES - PresDocument25 pages2022 05 ISES - PressonnyNo ratings yet
- Week-1-Desain Sistem Kerja-CompressedDocument42 pagesWeek-1-Desain Sistem Kerja-CompressedArdy AnandaNo ratings yet
- Simulation: July 06, 2010 1 Aspen Plus For Process Design and SimulationDocument69 pagesSimulation: July 06, 2010 1 Aspen Plus For Process Design and Simulationengrabdul516No ratings yet
- Analytics 02011 Learning Path - Curriculum (6632)Document22 pagesAnalytics 02011 Learning Path - Curriculum (6632)Sheetal JNo ratings yet
- On-Line Imaging of Aggregates For Process Control: T.W. Bobo JRDocument8 pagesOn-Line Imaging of Aggregates For Process Control: T.W. Bobo JRDirceu NascimentoNo ratings yet
- HBK Operational Modal Analysis Course Oct 23Document219 pagesHBK Operational Modal Analysis Course Oct 23puriclares62No ratings yet
- Introduction To Process Design and SimulationDocument43 pagesIntroduction To Process Design and SimulationDMRINo ratings yet
- Data Mining IntroductionDocument24 pagesData Mining IntroductionkrishnakumarNo ratings yet
- Enhancing Automobile Manufacturing Efficiency Using Machine Learning: Sequence Tracking and Clamping Monitoring With Machine Learning Video Analytics and Laser Light Alert SystemDocument13 pagesEnhancing Automobile Manufacturing Efficiency Using Machine Learning: Sequence Tracking and Clamping Monitoring With Machine Learning Video Analytics and Laser Light Alert SystemInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- TOPNIR Technology Features and Advantages Rev3Document7 pagesTOPNIR Technology Features and Advantages Rev3vmarchal13_57No ratings yet
- 4) Automation in Ring SpinningDocument9 pages4) Automation in Ring Spinningaladin adnanNo ratings yet
- Report Scripting - Best Practices: Version 10.0 - Service Release 12 April 2020Document37 pagesReport Scripting - Best Practices: Version 10.0 - Service Release 12 April 2020mohammedomar1974No ratings yet
- Bootcamp ContentDocument22 pagesBootcamp ContentgloNo ratings yet
- C1 - Intro To Methods Engineering - Part 2Document22 pagesC1 - Intro To Methods Engineering - Part 2bxnx joeNo ratings yet
- MEERA Reservoir Simulation Software IntroductionDocument19 pagesMEERA Reservoir Simulation Software IntroductionShahrukh SadiqNo ratings yet
- OEE Project NewDocument12 pagesOEE Project NewDeni AfrizatamaNo ratings yet
- The dimensional model is better suited for reporting as it denormalizes the data for faster querying and joins dimensions directly to fact tables. The operational model is normalized for transactionsDocument33 pagesThe dimensional model is better suited for reporting as it denormalizes the data for faster querying and joins dimensions directly to fact tables. The operational model is normalized for transactionscognosNo ratings yet
- IoT ProjectDocument16 pagesIoT ProjectSyurriya LeedangNo ratings yet
- ICOMS - Abstract - Suryajyoti NandaDocument2 pagesICOMS - Abstract - Suryajyoti NandaSuryajyoti NandaNo ratings yet
- Modeling in ADAMS of A 6R Industrial RobotDocument5 pagesModeling in ADAMS of A 6R Industrial RobotvxefjrqlanqxfimargNo ratings yet
- Design and Development of Kistler 8840 Rotational Accelerometer MountingDocument32 pagesDesign and Development of Kistler 8840 Rotational Accelerometer Mountingirfanrosli90No ratings yet
- MOA - Massive Online Analysis ManualDocument67 pagesMOA - Massive Online Analysis ManualHolisson SoaresNo ratings yet
- 1-s2.0-S2212827122013798-mainDocument6 pages1-s2.0-S2212827122013798-mainTrường Đỗ ThếNo ratings yet
- NoCA2019-ProxyML 2019nov29Document24 pagesNoCA2019-ProxyML 2019nov29Salah UddinNo ratings yet
- S1 8 - 50 Ignacio MolinaDocument18 pagesS1 8 - 50 Ignacio MolinaCesar Rodriguez GuzmanNo ratings yet
- COGNOS 8 - Framework Manager &QSDocument16 pagesCOGNOS 8 - Framework Manager &QSvisu666No ratings yet
- CH 2. ForecastingBDocument59 pagesCH 2. ForecastingBMuhammad Rizky ParamartaNo ratings yet
- dc0b1e76-7368-45d7-af1b-216749ed46daDocument294 pagesdc0b1e76-7368-45d7-af1b-216749ed46daQR JcNo ratings yet
- Session - 16 - Guest SessionDocument20 pagesSession - 16 - Guest SessionARPAN DHARNo ratings yet
- Massrearing Montool Dashboard Version 1Document373 pagesMassrearing Montool Dashboard Version 1Ahmad KhalifaNo ratings yet
- Big Data Analytics For Smart Manufacturing Systems ReportDocument9 pagesBig Data Analytics For Smart Manufacturing Systems Reportkumarveepan958No ratings yet
- Increasing Availability of Industrial Systems Through Data Stream MiningDocument11 pagesIncreasing Availability of Industrial Systems Through Data Stream Mininghind90No ratings yet
- Multiobjective Optimization of An Industrial Grinding Operation Using Elitist Nondominated Sorting Genetic AlgorithmDocument12 pagesMultiobjective Optimization of An Industrial Grinding Operation Using Elitist Nondominated Sorting Genetic AlgorithmAlejandro425No ratings yet
- Machine Learning in Process Safety PIIDocument30 pagesMachine Learning in Process Safety PIIHikmah AdiNo ratings yet
- IntroductiontoAIforbeginners IsralTankamDocument65 pagesIntroductiontoAIforbeginners IsralTankamSıla DevrimNo ratings yet
- Lecture # 06 - PerformanceDocument10 pagesLecture # 06 - PerformanceRamjan Ali SiamNo ratings yet
- S1.2 PUG2019 - ExensioPlatform - SaidAkar PDFDocument23 pagesS1.2 PUG2019 - ExensioPlatform - SaidAkar PDFDurgadevi BNo ratings yet
- Esma El 2011Document4 pagesEsma El 2011Anonymous VNu3ODGavNo ratings yet
- Manufacturing Excellence Footwear Sourcing RefreshmentDocument39 pagesManufacturing Excellence Footwear Sourcing RefreshmentAkankshaNo ratings yet
- Introduction to Machine Learning and Data Mining ConceptsDocument604 pagesIntroduction to Machine Learning and Data Mining ConceptsScion Of VirikvasNo ratings yet
- Proceedings of Symposium in Production and Quality Engineering Kasetsart University, 4-5 June 2002, pp.104-111Document8 pagesProceedings of Symposium in Production and Quality Engineering Kasetsart University, 4-5 June 2002, pp.104-111csrajmohan2924No ratings yet
- Asko S55Document1 pageAsko S55Martin.c.figueroaNo ratings yet
- Drop Ball Testing: Background and Standard ProcedureDocument6 pagesDrop Ball Testing: Background and Standard ProcedureMartin.c.figueroaNo ratings yet
- 07 Chapter7 PDFDocument22 pages07 Chapter7 PDFpollupoccuNo ratings yet
- Time AnalysisDocument5 pagesTime AnalysisMartin.c.figueroaNo ratings yet
- TasksDocument3 pagesTasksMartin.c.figueroaNo ratings yet
- Aa Sag Mill Optimization Using Model Predictive Control Data PDFDocument8 pagesAa Sag Mill Optimization Using Model Predictive Control Data PDFDlanorNo ratings yet
- 09 Chapter9 PDFDocument18 pages09 Chapter9 PDFpollupoccuNo ratings yet
- Theories of Ball Wear and The Results of A PDFDocument9 pagesTheories of Ball Wear and The Results of A PDFrobertoNo ratings yet
- Sampling-27 1Document5 pagesSampling-27 1Martin.c.figueroaNo ratings yet
- Chapter 2Document14 pagesChapter 2தர்ஷன் செல்வராஜ்No ratings yet
- Theory of SamplingDocument4 pagesTheory of SamplingMartin.c.figueroaNo ratings yet
- Chapter 5Document20 pagesChapter 5Martin.c.figueroaNo ratings yet
- A Simple Definition of MLDocument4 pagesA Simple Definition of MLMartin.c.figueroaNo ratings yet
- Minerals: Semi-Autogenous Wet Grinding Modeling With CFD-DEMDocument17 pagesMinerals: Semi-Autogenous Wet Grinding Modeling With CFD-DEMMartin.c.figueroaNo ratings yet
- MS2019 - Progress Report For LCT and Cleaner Flotation Test ResultsDocument9 pagesMS2019 - Progress Report For LCT and Cleaner Flotation Test ResultsMartin.c.figueroaNo ratings yet
- Excel For Data Analysis 1658535367Document19 pagesExcel For Data Analysis 1658535367Di Antonella G. BrunoNo ratings yet
- Label CuoxDocument781 pagesLabel CuoxMartin.c.figueroaNo ratings yet
- Optimization of The Design of AG Mill Shell Liners at The Gol-E-Gohar Concentration PlantDocument11 pagesOptimization of The Design of AG Mill Shell Liners at The Gol-E-Gohar Concentration PlantMartin.c.figueroaNo ratings yet
- Machine Learning Algorithms (Python and R Codes)Document6 pagesMachine Learning Algorithms (Python and R Codes)Martin.c.figueroaNo ratings yet
- Processes: Research On Non-Uniform Wear of Liner in SAG MillDocument11 pagesProcesses: Research On Non-Uniform Wear of Liner in SAG MillMartin.c.figueroaNo ratings yet
- Reference From MVC-40mmDocument5 pagesReference From MVC-40mmMartin.c.figueroaNo ratings yet
- Reference From MVC-40mmDocument5 pagesReference From MVC-40mmMartin.c.figueroaNo ratings yet
- Minitab Deployment Guide: Deploying Minitab On A MacDocument6 pagesMinitab Deployment Guide: Deploying Minitab On A MacJoselo_JCANo ratings yet
- Hydrocyclone BrochureDocument8 pagesHydrocyclone BrochureMartin.c.figueroaNo ratings yet
- Slurry Pooling and Transport Issues in SAG Mills PDFDocument10 pagesSlurry Pooling and Transport Issues in SAG Mills PDFMartin.c.figueroaNo ratings yet
- Reporting JK Drop Weight and SMC Test ResultsDocument5 pagesReporting JK Drop Weight and SMC Test ResultsMartin.c.figueroaNo ratings yet
- Simulación Datos Promedio PDFDocument2 pagesSimulación Datos Promedio PDFMartin.c.figueroaNo ratings yet
- Slurry Pooling and Transport Issues in SAG Mills PDFDocument10 pagesSlurry Pooling and Transport Issues in SAG Mills PDFMartin.c.figueroaNo ratings yet
- 1.water Level Controller Using 8051 MicrocontrollerDocument4 pages1.water Level Controller Using 8051 MicrocontrolleranupamdubeyNo ratings yet
- Router CISCO c1111-4pDocument5 pagesRouter CISCO c1111-4pEdgar CastilloNo ratings yet
- Motorola Power Controller: by Sasi Kumar C Development EngineerDocument29 pagesMotorola Power Controller: by Sasi Kumar C Development EngineerVenkat RaoNo ratings yet
- Lecture 23 - Unit IV - 8255A Programmable Peripheral InterfaceDocument4 pagesLecture 23 - Unit IV - 8255A Programmable Peripheral InterfaceTarun SinghNo ratings yet
- SqlinjectablesDocument116 pagesSqlinjectablesJacob Pochin50% (2)
- Binary Division: 64-Bit Shift Register 64-Bit ALU 32-Bit Shift RegisterDocument4 pagesBinary Division: 64-Bit Shift Register 64-Bit ALU 32-Bit Shift RegisterAllan Ayala BalcenaNo ratings yet
- Venus 30 Commissioning Manual ENDocument29 pagesVenus 30 Commissioning Manual ENWaltinegojiya CadondonNo ratings yet
- Excel Obstacle Course XTimerDocument36 pagesExcel Obstacle Course XTimercryticopero69No ratings yet
- BK 2202 Ultrasound System - User ManualDocument86 pagesBK 2202 Ultrasound System - User Manualhakep112No ratings yet
- 00 F 5 Meak 320Document388 pages00 F 5 Meak 320derbalijalelNo ratings yet
- Atp Assv1 Pl72888213 LetterDocument1 pageAtp Assv1 Pl72888213 LetterNarin SangrungNo ratings yet
- DLSH101Document266 pagesDLSH101BlessingNo ratings yet
- Bubt Eee-304 Lab Manual - Edited 25-12-21 v2Document73 pagesBubt Eee-304 Lab Manual - Edited 25-12-21 v2Md. Arif Hasan MasumNo ratings yet
- 190A1E0336 - ProjectDocument67 pages190A1E0336 - ProjectSrisasthagnaneswarsaikumar KonduruNo ratings yet
- Topic Wise Bundle PDF Course 2022 - Quantitative Aptitude Time and Work & Pipes and Cistern Set-5 (Eng)Document6 pagesTopic Wise Bundle PDF Course 2022 - Quantitative Aptitude Time and Work & Pipes and Cistern Set-5 (Eng)Rohit TopeNo ratings yet
- Poly Video Os 4 1 0 382263 RNDocument30 pagesPoly Video Os 4 1 0 382263 RNBono646No ratings yet
- AFL1501Document10 pagesAFL1501Sarfaraaz SmilezNo ratings yet
- Hospital Trade ProjectDocument15 pagesHospital Trade Projectlydiahwmwangi.lwmNo ratings yet
- OFFICE MANAGEMENT-noteDocument53 pagesOFFICE MANAGEMENT-notereem mazeeNo ratings yet
- Level 3 - ICTDocument1 pageLevel 3 - ICTmirfieldfreeNo ratings yet
- High-efficiency solar inverter with dual MPP trackers and OLED displayDocument2 pagesHigh-efficiency solar inverter with dual MPP trackers and OLED displayYudha Trias RusmanaNo ratings yet
- Manual SigmaDocument2 pagesManual SigmaespartanotpmNo ratings yet
- LogDocument74 pagesLogBerry NiezaNo ratings yet
- 2019 IoT and Wi Fi Based Door Access Control System Using Mobile ApplicationDocument4 pages2019 IoT and Wi Fi Based Door Access Control System Using Mobile ApplicationKamrul HasanNo ratings yet
- Nexford University CatalogDocument127 pagesNexford University CatalogSola Adesanya-AtirokoNo ratings yet
- Firewalld Iptables (Continued)Document36 pagesFirewalld Iptables (Continued)Alex ValenciaNo ratings yet
- ERP and Related TechnologiesDocument96 pagesERP and Related Technologiessaudgazali93% (15)
- How to install Aspen HYSYS V9 and configure licensing in less than 40 stepsDocument21 pagesHow to install Aspen HYSYS V9 and configure licensing in less than 40 stepsMitzgun AjahNo ratings yet