You might also like
- Overview Of Bayesian Approach To Statistical Methods: SoftwareFrom EverandOverview Of Bayesian Approach To Statistical Methods: SoftwareNo ratings yet
- Incidence of Anorexia Nervosa in Women: A Systematic Review and Meta-AnalysisDocument15 pagesIncidence of Anorexia Nervosa in Women: A Systematic Review and Meta-AnalysisandreaNo ratings yet
- Paper4 DarojatunDocument6 pagesPaper4 DarojatunJarot DarojatunNo ratings yet
- Art 07Document8 pagesArt 07Jorge Martinez TapiaNo ratings yet
- Handout Stat Week 9 Chi SquareDocument4 pagesHandout Stat Week 9 Chi SquareIsa IrawanNo ratings yet
- Modeling of Healthcare Systems: Past, Current and Future TrendsDocument12 pagesModeling of Healthcare Systems: Past, Current and Future TrendsMaryam ShirbanNo ratings yet
- Bertani (2018) How To Describe Bivariate DataDocument5 pagesBertani (2018) How To Describe Bivariate DataNatasya ChieCaem FunforeverNo ratings yet
- 11852-23500-1-Sm - Regresi Logistik Biner & c.45 (Adk), KlasifikasiDocument11 pages11852-23500-1-Sm - Regresi Logistik Biner & c.45 (Adk), KlasifikasivitaNo ratings yet
- Jtptunimus GDL Umilatifah 5199 3 Babiip FDocument7 pagesJtptunimus GDL Umilatifah 5199 3 Babiip Fuzlifatil jannahNo ratings yet
- Breault 2001 RoughSetsDocument11 pagesBreault 2001 RoughSetsم. سهير عبد داؤد عسىNo ratings yet
- Statistik 3 - Fadila Irsyada.21078040Document5 pagesStatistik 3 - Fadila Irsyada.21078040Claudya MailandaNo ratings yet
- Three Dimensional Model For Diagnostic Prediction: A Data Mining ApproachDocument5 pagesThree Dimensional Model For Diagnostic Prediction: A Data Mining ApproachInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Medical DatasetsDocument21 pagesMedical DatasetsAbdal LalitNo ratings yet
- Multi Variate Statistical AnalysisDocument13 pagesMulti Variate Statistical AnalysisDeepali TanejaNo ratings yet
- Penerapan Metode Statistika Dalam Analisis Kegiatan GerejaDocument9 pagesPenerapan Metode Statistika Dalam Analisis Kegiatan GerejaCahyanaEndraPurnamaNo ratings yet
- Analisis Desigualdades en SaludDocument22 pagesAnalisis Desigualdades en SaludJorge Mandl StanglNo ratings yet
- 239 241 1 SMDocument12 pages239 241 1 SMAnonymous UhM9ljnvNo ratings yet
- COURSE TOPIC-Nures2 CM - CU7Document11 pagesCOURSE TOPIC-Nures2 CM - CU7Michelle MallareNo ratings yet
- Ordinal Logistic Regression Analysis of Factors Affecting The Blood Sugar Levels of Diabetes Mellitus PatientsDocument10 pagesOrdinal Logistic Regression Analysis of Factors Affecting The Blood Sugar Levels of Diabetes Mellitus PatientsEmil MarthaNo ratings yet
- A Unification of Models For Meta-Analysis of Diagnostic Accuracy StudiesDocument13 pagesA Unification of Models For Meta-Analysis of Diagnostic Accuracy StudiesClaudiu ClementNo ratings yet
- Methodological Quality of Systematic Reviews of Animal Studies - A Survey of Reviews of Basic ResearchDocument6 pagesMethodological Quality of Systematic Reviews of Animal Studies - A Survey of Reviews of Basic Researchgabriela_mariangela5929No ratings yet
- Government Spending Discriminant AnalysisDocument58 pagesGovernment Spending Discriminant AnalysisGokhan OcakogluNo ratings yet
- Understanding of Interaction (Subgroup) Analysis in Clinical TrialsDocument21 pagesUnderstanding of Interaction (Subgroup) Analysis in Clinical TrialsAnand SurendranNo ratings yet
- Epid Klinik 6 ValiduitasDocument71 pagesEpid Klinik 6 ValiduitasHalim SyahrilNo ratings yet
- Course OutlineDocument4 pagesCourse OutlineRaunaNo ratings yet
- Metode PenelitianDocument28 pagesMetode PenelitianyeniNo ratings yet
- Business Club: Basic StatisticsDocument26 pagesBusiness Club: Basic StatisticsJustin Russo HarryNo ratings yet
- Best Practice & Research Clinical RheumatologyDocument13 pagesBest Practice & Research Clinical RheumatologydrharivadanNo ratings yet
- Important Concepts DocDocument40 pagesImportant Concepts DocemranalshaibaniNo ratings yet
- Citation:: Critical Appraisal of A Case-Control Study Case-Control WorksheetDocument4 pagesCitation:: Critical Appraisal of A Case-Control Study Case-Control WorksheetThai CheNo ratings yet
- Chapter 3Document2 pagesChapter 3Ustaad KaahiyeNo ratings yet
- Analisis RCT Continuous Outcome - Google SearchDocument13 pagesAnalisis RCT Continuous Outcome - Google SearchRaudhatulAisyFachrudinNo ratings yet
- Data Screening ChecklistDocument57 pagesData Screening ChecklistSugan PragasamNo ratings yet
- Ajams 8 2 1Document5 pagesAjams 8 2 1Ruth GetahunNo ratings yet
- (Sici) 1097-0258 (19990915 30) 18 17 18 2331 Aid-Sim259 3.0.co 2-lDocument11 pages(Sici) 1097-0258 (19990915 30) 18 17 18 2331 Aid-Sim259 3.0.co 2-lBenaoNo ratings yet
- 2022-09-12 - Psych - Research Methods 1 & 2Document8 pages2022-09-12 - Psych - Research Methods 1 & 2mahamahmed365No ratings yet
- Research Methodology - Multi Variate Analysis 13 10 23Document17 pagesResearch Methodology - Multi Variate Analysis 13 10 23Muthu KumarNo ratings yet
- Cheong Lieng - Gender and Ethnic Differences in DiabetesDocument10 pagesCheong Lieng - Gender and Ethnic Differences in DiabetesUmmi AzmiraNo ratings yet
- Patient Centred Variables With Univariateassociations With Unplanned ICU Admissiona Systematic ReviewDocument9 pagesPatient Centred Variables With Univariateassociations With Unplanned ICU Admissiona Systematic ReviewsarintiNo ratings yet
- LISDA RAMADHANI 1307015041 - EditDocument10 pagesLISDA RAMADHANI 1307015041 - EditSeptyNo ratings yet
- 491-Article Text-2225-1-10-20230328Document7 pages491-Article Text-2225-1-10-20230328Atik TriyanaNo ratings yet
- Bursac (2008) Purposeful Selection of Variables in Logistic Regression PDFDocument8 pagesBursac (2008) Purposeful Selection of Variables in Logistic Regression PDFLyly MagnanNo ratings yet
- Exam Pa 06 19 Model SolutionDocument17 pagesExam Pa 06 19 Model SolutionHông HoaNo ratings yet
- Inter-Rater Reliability of Case-Note Audit: A Systematic ReviewDocument8 pagesInter-Rater Reliability of Case-Note Audit: A Systematic ReviewAlex EdwardsNo ratings yet
- Engle Top K AnalysisDocument9 pagesEngle Top K AnalysisStezar PriansyaNo ratings yet
- Lecture1 S3RI 2013Document26 pagesLecture1 S3RI 2013hubik38No ratings yet
- Multivariate AnalysisDocument7 pagesMultivariate AnalysisGOMATHI ANo ratings yet
- Maths Folio BiqDocument21 pagesMaths Folio Biqapi-349814923No ratings yet
- Critical AppraisalDocument9 pagesCritical Appraisalapi-402918352No ratings yet
- Mbe - Interpreting and Understanding Meta-Analysis GraphsDocument4 pagesMbe - Interpreting and Understanding Meta-Analysis GraphsRaymundoLauroTijerinaGarciaNo ratings yet
- International Conference On Emerging Trends in Engineering, Science and Technology (ICETEST - 2015)Document10 pagesInternational Conference On Emerging Trends in Engineering, Science and Technology (ICETEST - 2015)Rista RiaNo ratings yet
- Chi Square in Bio ResearchDocument7 pagesChi Square in Bio ResearchparthajiNo ratings yet
- Insomnia Type QuestionnaireDocument61 pagesInsomnia Type QuestionnaireMondlTNo ratings yet
- Chi SquareDocument14 pagesChi SquareNOYON KUMAR DANo ratings yet
- A Comparison of The Mahalanobis-Taguchi System To A Standard Statistical Method For Defect DetectionDocument9 pagesA Comparison of The Mahalanobis-Taguchi System To A Standard Statistical Method For Defect Detection김형진No ratings yet
- Innovative Statistical Methods For Public Health DataDocument354 pagesInnovative Statistical Methods For Public Health DatasuyatnofkmundipNo ratings yet
- Missing Value TreatmentDocument22 pagesMissing Value TreatmentrphmiNo ratings yet
- Assignment: Muhammad Kamran Khan Dr. Inam UllahDocument12 pagesAssignment: Muhammad Kamran Khan Dr. Inam UllahMuhammad kamran khanNo ratings yet
- Fulltext PDFDocument38 pagesFulltext PDFmphil.rameshNo ratings yet
- IRJES 2017 Vol. 1 Special Issue 2 English Full Paper 038Document6 pagesIRJES 2017 Vol. 1 Special Issue 2 English Full Paper 038liew wei keongNo ratings yet
- Collaborative Planning Template W CaptionDocument5 pagesCollaborative Planning Template W Captionapi-297728751No ratings yet
- Intellectual Property Rights and Hostile TakeoverDocument8 pagesIntellectual Property Rights and Hostile TakeoverDanNo ratings yet
- Henderson 1Document4 pagesHenderson 1danielNo ratings yet
- Gpcdoc Gtds Shell Gadus s3 v460xd 2 (En) TdsDocument2 pagesGpcdoc Gtds Shell Gadus s3 v460xd 2 (En) TdsRoger ObregonNo ratings yet
- Marvel Science StoriesDocument4 pagesMarvel Science StoriesPersonal trainerNo ratings yet
- A Modified Newton's Method For Solving Nonlinear Programing ProblemsDocument15 pagesA Modified Newton's Method For Solving Nonlinear Programing Problemsjhon jairo portillaNo ratings yet
- SLC 10 ScienceDocument16 pagesSLC 10 SciencePffflyers KurnawanNo ratings yet
- Capillary PressureDocument12 pagesCapillary PressureamahaminerNo ratings yet
- Penawaran AC LG - GD Checkup Laborat RS PHCDocument1 pagePenawaran AC LG - GD Checkup Laborat RS PHCaisyahbrillianaNo ratings yet
- Đề Thi Tham Khảo (Đề thi có 5 trang) : 6: The flood victims 7: Many 8Document7 pagesĐề Thi Tham Khảo (Đề thi có 5 trang) : 6: The flood victims 7: Many 8Quang Đặng HồngNo ratings yet
- Potential Application of Orange Peel (OP) As An Eco-Friendly Adsorbent For Textile Dyeing EffluentsDocument13 pagesPotential Application of Orange Peel (OP) As An Eco-Friendly Adsorbent For Textile Dyeing EffluentsAnoif Naputo AidnamNo ratings yet
- Model Village PDFDocument6 pagesModel Village PDFakshat100% (1)
- Organizational Behavior - Motivational Theories at Mcdonald's ReportDocument11 pagesOrganizational Behavior - Motivational Theories at Mcdonald's ReportvnbioNo ratings yet
- AABB Sample New Program Business PlanDocument14 pagesAABB Sample New Program Business Planbiospacecowboy100% (1)
- TRB CatalogDocument836 pagesTRB CatalogDiana LazariNo ratings yet
- BharathDocument2 pagesBharathbharath kumarNo ratings yet
- Gear Whine Prediction With CAE For AAMDocument6 pagesGear Whine Prediction With CAE For AAMSanjay DeshpandeNo ratings yet
- Fichas Slate HoneywellDocument1 pageFichas Slate HoneywellING CARLOS RAMOSNo ratings yet
- A Science Lesson Plan Analysis Instrument For Formative and Summative Program Evaluation of A Teacher Education ProgramDocument31 pagesA Science Lesson Plan Analysis Instrument For Formative and Summative Program Evaluation of A Teacher Education ProgramTiara Kurnia KhoerunnisaNo ratings yet
- DSSSSPDocument3 pagesDSSSSPChris BalmacedaNo ratings yet
- Wa0004Document8 pagesWa0004Thabo ChuchuNo ratings yet
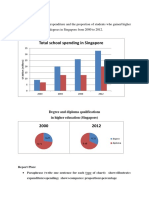
- Total School Spending in Singapore: Task 1 020219Document6 pagesTotal School Spending in Singapore: Task 1 020219viper_4554No ratings yet
- Oral Com Mods Except 6Document4 pagesOral Com Mods Except 6ninjarkNo ratings yet
- Senior Project Manager Marketing in Toronto Canada Resume Cindy KempDocument2 pagesSenior Project Manager Marketing in Toronto Canada Resume Cindy KempCindyKempNo ratings yet
- Learn C++ Programming LanguageDocument322 pagesLearn C++ Programming LanguageAli Eb100% (8)
- LearnEnglish Reading B1 A Conference ProgrammeDocument4 pagesLearnEnglish Reading B1 A Conference ProgrammeAylen DaianaNo ratings yet
- WV6 QuestionnaireDocument21 pagesWV6 QuestionnaireBea MarquezNo ratings yet
- B.tech - Non Credit Courses For 2nd Year StudentsDocument4 pagesB.tech - Non Credit Courses For 2nd Year StudentsNishant MishraNo ratings yet
- JavaScript ArraysDocument5 pagesJavaScript Arraysursu_padure_scrNo ratings yet