You might also like
- Sample Module OutlineDocument14 pagesSample Module OutlineGemver Baula BalbasNo ratings yet
- Review On Descriptive Statistics LESSON 2 - Measures of Central TendencyDocument4 pagesReview On Descriptive Statistics LESSON 2 - Measures of Central TendencyEllora Austria RodelNo ratings yet
- Weighted Average Formula Simplify. Multiply Each Side by 27. Subtract 1245 From Each Side. Simplify. Divide Each Side by 12Document12 pagesWeighted Average Formula Simplify. Multiply Each Side by 27. Subtract 1245 From Each Side. Simplify. Divide Each Side by 12NeoNo ratings yet
- Numerical Measures: Bf1206-Business Mathematics SEMESTER 2 - 2016/2017Document25 pagesNumerical Measures: Bf1206-Business Mathematics SEMESTER 2 - 2016/2017Muhammad AsifNo ratings yet
- Lesson Note 7Document14 pagesLesson Note 7Miftah 67No ratings yet
- Statistics Lab 10-4Document11 pagesStatistics Lab 10-4Andie CoxNo ratings yet
- STA 202 Correlation and RegressionDocument11 pagesSTA 202 Correlation and Regressionzyzzxzyzzx1No ratings yet
- Measures of Relative PositionDocument4 pagesMeasures of Relative PositionErika ValconchaNo ratings yet
- Q4 TopicsDocument7 pagesQ4 TopicsHAZEL JEAN CAMUSNo ratings yet
- Mean Median ModeDocument28 pagesMean Median ModeEs AmNo ratings yet
- Dr. K. M. Salah Uddin Associate Professor Dept. of MIS, DUDocument41 pagesDr. K. M. Salah Uddin Associate Professor Dept. of MIS, DUNuzhat MahsaNo ratings yet
- MATH 10 4th Quarter LPDocument11 pagesMATH 10 4th Quarter LPLyndon TongawanNo ratings yet
- Lecture No. 6 Measures of VariabilityDocument25 pagesLecture No. 6 Measures of VariabilityCzarina GuevarraNo ratings yet
- Measures of DispersionDocument59 pagesMeasures of DispersiontiffanyNo ratings yet
- Describing Data: Centre Mean Is The Technical Term For What Most People Call An Average. in Statistics, "Average"Document4 pagesDescribing Data: Centre Mean Is The Technical Term For What Most People Call An Average. in Statistics, "Average"Shane LambertNo ratings yet
- Hypothesis HandoutsDocument17 pagesHypothesis HandoutsReyson PlasabasNo ratings yet
- Central Tendency - Fall 20Document38 pagesCentral Tendency - Fall 20RupalNo ratings yet
- Lesson 2. Measures of Central TendencyDocument9 pagesLesson 2. Measures of Central TendencyCamille FerrerNo ratings yet
- Unit 3 Measures of Central TendencyDocument4 pagesUnit 3 Measures of Central TendencyhellokittysaranghaeNo ratings yet
- Descriptive Measures With Samples-1Document33 pagesDescriptive Measures With Samples-1Janela Venice SantosNo ratings yet
- Lecture 3Document26 pagesLecture 3lihaylihayjeanloveNo ratings yet
- Midterm Review: Chapter 1 - Descriptive StatsDocument6 pagesMidterm Review: Chapter 1 - Descriptive StatsDenish ShresthaNo ratings yet
- C4 Point MeasuresDocument36 pagesC4 Point MeasuresTeresa Mae Abuzo Vallejos-BucagNo ratings yet
- Chapter 3Document26 pagesChapter 3Shahzaib SalmanNo ratings yet
- Measure of LocationDocument7 pagesMeasure of LocationHannah ArañaNo ratings yet
- Math StatsDocument6 pagesMath StatsPein MwaNo ratings yet
- Quartiles and PercentilesDocument14 pagesQuartiles and PercentilesCeline GalvezNo ratings yet
- 10 STAT Per Comb ProbDocument34 pages10 STAT Per Comb ProbMonic RomeroNo ratings yet
- Reviewer in Statistics and Probability: Measures of Central Tendencies Constructing Probability DistributionDocument2 pagesReviewer in Statistics and Probability: Measures of Central Tendencies Constructing Probability DistributionHyana Imm MedalladaNo ratings yet
- Math PPT Module 5Document21 pagesMath PPT Module 5emmah macalNo ratings yet
- Quant NotesDocument28 pagesQuant NotesDeepak GuptaNo ratings yet
- Q3 Statistics and Probability Week 2Document8 pagesQ3 Statistics and Probability Week 2AngeleehNo ratings yet
- Chapter 3. Data Management Lesson 2.: Learning Outcomes: at The End of The Lesson The Students Will Be Able ToDocument4 pagesChapter 3. Data Management Lesson 2.: Learning Outcomes: at The End of The Lesson The Students Will Be Able ToMelissa Maravilla Ulgasan BitcoNo ratings yet
- STAT - MeasureS of Central Tendency - NewDocument12 pagesSTAT - MeasureS of Central Tendency - NewRachel Jane TanNo ratings yet
- Statistics For Managers Using Microsoft Excel: 5 EditionDocument54 pagesStatistics For Managers Using Microsoft Excel: 5 EditionTsoi Yun PuiNo ratings yet
- Testing of HypothesisDocument54 pagesTesting of HypothesisKarthic SK100% (1)
- BS3. StatisticsDocument62 pagesBS3. StatisticsPhan SokkheangNo ratings yet
- Lecture 10Document44 pagesLecture 10Tú UyênNo ratings yet
- Math-Readings-4 PDFDocument24 pagesMath-Readings-4 PDFFrancis Edrian CellonaNo ratings yet
- Math Readings 4 ReviewerDocument24 pagesMath Readings 4 ReviewerCathNo ratings yet
- Compiled NotesDocument12 pagesCompiled Notescreacion impresionesNo ratings yet
- DispersionDocument27 pagesDispersionElmabeth Dela CruzNo ratings yet
- ResearchII Q3 Wk1-3 Statistical-Tools-2.CQA - GQA.LRQA PDFDocument12 pagesResearchII Q3 Wk1-3 Statistical-Tools-2.CQA - GQA.LRQA PDFSophia Claire PerezNo ratings yet
- Lecture6 - Interval Estimation PDFDocument14 pagesLecture6 - Interval Estimation PDFHiền NguyễnNo ratings yet
- Descriptive StatisticsDocument79 pagesDescriptive StatisticsYin YinNo ratings yet
- Learning Sheet No. 8Document4 pagesLearning Sheet No. 8Alex Cañizo Gabilan Jr.No ratings yet
- Basic Statistics: Quarter 3 - Module 2 FractilesDocument5 pagesBasic Statistics: Quarter 3 - Module 2 FractilesJessa Bienel Biagtas OlescoNo ratings yet
- Experimental Design I Lecture 6 070915Document17 pagesExperimental Design I Lecture 6 070915Marlvin PrimeNo ratings yet
- Las Math10 Q4 WK1Document4 pagesLas Math10 Q4 WK1Shakira MunarNo ratings yet
- Measures of Dispersion - 1Document44 pagesMeasures of Dispersion - 1muhardi jayaNo ratings yet
- Lesson 3: Measures of Central Tendency: Total Number of Scores Population N Sample NDocument12 pagesLesson 3: Measures of Central Tendency: Total Number of Scores Population N Sample NTracy Blair Napa-egNo ratings yet
- Measures of PositionDocument12 pagesMeasures of PositionMikhailNo ratings yet
- Introduction To Statistics: TeacherDocument35 pagesIntroduction To Statistics: Teachersobhy MaroufNo ratings yet
- Describing Data:: Measures of Variation or DispersionDocument31 pagesDescribing Data:: Measures of Variation or DispersionSamiul Karim SkNo ratings yet
- Summary of Midterm Lessons (20231106134417)Document9 pagesSummary of Midterm Lessons (20231106134417)Antonette LaurioNo ratings yet
- Calculating Measures of Position: Grade 10Document10 pagesCalculating Measures of Position: Grade 10jacqueline deeNo ratings yet
- Measures of Dispersion: Greg C Elvers, PH.DDocument27 pagesMeasures of Dispersion: Greg C Elvers, PH.DPalwasha KhanNo ratings yet
- Topic: Measures of Relative Position: I. Z-ScoreDocument7 pagesTopic: Measures of Relative Position: I. Z-ScoreLesterr De leonNo ratings yet
- SOLUTIONS 2022 Intro Stats Exam2Document13 pagesSOLUTIONS 2022 Intro Stats Exam2Kilana LichterfeldNo ratings yet
- 6 MANOMETER DiscussedDocument17 pages6 MANOMETER DiscussedTrixia DuazoNo ratings yet
- Cornell NotesDocument5 pagesCornell NotesDonna Claire AngusNo ratings yet
- EAPP - Statement of The ProblemDocument1 pageEAPP - Statement of The ProblemDonna Claire AngusNo ratings yet
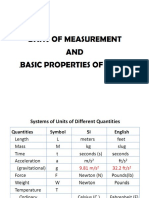
- Basic Properties of FluidsDocument11 pagesBasic Properties of FluidsDonna Claire AngusNo ratings yet
- MomentuDocument15 pagesMomentuDonna Claire AngusNo ratings yet
- NSTP - Mechanics DetailsDocument1 pageNSTP - Mechanics DetailsDonna Claire AngusNo ratings yet
- Guidelines of Final ReportDocument1 pageGuidelines of Final ReportDonna Claire AngusNo ratings yet
- Teen DepressionDocument6 pagesTeen DepressionDonna Claire AngusNo ratings yet
- Seafloor SpreadingDocument13 pagesSeafloor SpreadingDonna Claire AngusNo ratings yet
- Minerals Important To SocietyDocument20 pagesMinerals Important To SocietyDonna Claire AngusNo ratings yet
- Theology 4 NotesDocument9 pagesTheology 4 NotesDonna Claire AngusNo ratings yet
- Module 1Document12 pagesModule 1Donna Claire AngusNo ratings yet
- POPESDocument38 pagesPOPESDonna Claire Angus100% (1)
- IoT Is The Interconnection of Computing DevicesDocument1 pageIoT Is The Interconnection of Computing DevicesDonna Claire AngusNo ratings yet
- HISTORY OF THE-WPS OfficeDocument2 pagesHISTORY OF THE-WPS OfficeDonna Claire AngusNo ratings yet
- EAPP - Review of Related LiteratureDocument3 pagesEAPP - Review of Related LiteratureDonna Claire AngusNo ratings yet
- Contemporary DanceDocument1 pageContemporary DanceDonna Claire AngusNo ratings yet
- Analysis and ResultsDocument3 pagesAnalysis and ResultsDonna Claire AngusNo ratings yet
- Herbal MedsDocument12 pagesHerbal MedsDonna Claire AngusNo ratings yet
- Call Center in The PhilippinesDocument4 pagesCall Center in The PhilippinesDonna Claire AngusNo ratings yet
- EAPP - RationaleDocument1 pageEAPP - RationaleDonna Claire AngusNo ratings yet
- EApp - Notes LectureDocument1 pageEApp - Notes LectureDonna Claire AngusNo ratings yet
- Notes ssp032Document3 pagesNotes ssp032Donna Claire AngusNo ratings yet
- EAPP - BibliographyDocument2 pagesEAPP - BibliographyDonna Claire AngusNo ratings yet
- ssp032 Lesson 1,2Document28 pagesssp032 Lesson 1,2Donna Claire AngusNo ratings yet
- Ebook Elementary Statistics 3Rd Edition Navidi Solutions Manual Full Chapter PDFDocument52 pagesEbook Elementary Statistics 3Rd Edition Navidi Solutions Manual Full Chapter PDFDouglasRileycnji100% (11)
- Quantitative Techniques - EPGP-15 - Course OutlineDocument4 pagesQuantitative Techniques - EPGP-15 - Course OutlinegeorgeavadakkelNo ratings yet
- Research MethodologyDocument7 pagesResearch Methodologysteven280893No ratings yet
- Lecture - 8-Statistical Inference - Single PopulationDocument25 pagesLecture - 8-Statistical Inference - Single PopulationTushar SohaleNo ratings yet
- Test Bank For Statistics For People Who Think They Hate Statistics Fifth EditionDocument18 pagesTest Bank For Statistics For People Who Think They Hate Statistics Fifth Editionbrianmcgeeprkscgnjiw100% (15)
- Pengaruh Kompensasi Dan Motivasi Kerja Terhadap Kinerja Karyawan Pada Pt. Devina SurabayaDocument15 pagesPengaruh Kompensasi Dan Motivasi Kerja Terhadap Kinerja Karyawan Pada Pt. Devina SurabayaGerry YusmanNo ratings yet
- D11 - D12-0525-MAT3017 - Statistical Inferences and Series of FunctionDocument2 pagesD11 - D12-0525-MAT3017 - Statistical Inferences and Series of FunctionVÉÑÔMNo ratings yet
- Negative Binomial Control Limits For Count Data With Extra-Poisson VariationDocument6 pagesNegative Binomial Control Limits For Count Data With Extra-Poisson VariationKraken UrNo ratings yet
- Data Analysis RoughDocument3 pagesData Analysis RoughbilalNo ratings yet
- Pearson Correlation Coefficient and Interpretation in SPSSDocument8 pagesPearson Correlation Coefficient and Interpretation in SPSSStacey TewesNo ratings yet
- Chapter 4 Measures of Central TendencyDocument7 pagesChapter 4 Measures of Central TendencyMitchie FaustinoNo ratings yet
- Plotting Decision Regions - MlxtendDocument5 pagesPlotting Decision Regions - Mlxtendakhi016733No ratings yet
- Ie106 Module 3Document257 pagesIe106 Module 3Mayden PabalanNo ratings yet
- StatisticsDocument32 pagesStatisticsLhizaNo ratings yet
- Class 1 Mathematical Basis For Managerial Decision - Chapter1 - GauravDocument42 pagesClass 1 Mathematical Basis For Managerial Decision - Chapter1 - Gauravlakshay187No ratings yet
- 15 Unit Wise QuestionsDocument2 pages15 Unit Wise QuestionsNikita MandhanNo ratings yet
- Solutions Odd For CategoricalDocument28 pagesSolutions Odd For CategoricalShi LijiaNo ratings yet
- PSYC3010 Tutorial 8: Moderated Multiple Regression (MMR) Activity 6: Exercises 4, 5 & 6Document42 pagesPSYC3010 Tutorial 8: Moderated Multiple Regression (MMR) Activity 6: Exercises 4, 5 & 6gfsgfsdNo ratings yet
- Essentials of Behavioral ResearchDocument848 pagesEssentials of Behavioral ResearchFlorencia Andrade100% (1)
- Midterm1 Spring2023 AnswerkeysDocument12 pagesMidterm1 Spring2023 AnswerkeysSwaraj AgarwalNo ratings yet
- (Ogunnaike) Random PhenomenaDocument1,063 pages(Ogunnaike) Random Phenomenaquantummechanician100% (2)
- Independent Sample T Test 1Document3 pagesIndependent Sample T Test 1Teach StoryNo ratings yet
- How To Use SPSSDocument134 pagesHow To Use SPSSdhimba100% (6)
- Stat5000 HW 1-2Document3 pagesStat5000 HW 1-2vinay kumarNo ratings yet
- Multivariate Parametric Methods: Steven J ZeilDocument36 pagesMultivariate Parametric Methods: Steven J Zeilscribd8198No ratings yet
- Assignment Instructor: P. Sri Harikrishna Course Code & Title: MBG 112: Business StatisticsDocument5 pagesAssignment Instructor: P. Sri Harikrishna Course Code & Title: MBG 112: Business StatisticsAakash murarkaNo ratings yet
- Weight and HeightDocument3 pagesWeight and HeightShinji IkariNo ratings yet
- Factors Influencing The Growth of Hair Salon Enterprises in Kenya: A Surveyof Hair Salon Enterprises in Kisii TownDocument15 pagesFactors Influencing The Growth of Hair Salon Enterprises in Kenya: A Surveyof Hair Salon Enterprises in Kisii TownInternational Organization of Scientific Research (IOSR)No ratings yet
- Metric Tolerance Chart PDFDocument6 pagesMetric Tolerance Chart PDFSwapnilSawantNo ratings yet
- The Stat 43 AssignmentDocument3 pagesThe Stat 43 Assignmentbajaman1234No ratings yet