You might also like
- Practical CS ProcessingDocument483 pagesPractical CS ProcessinganAMUstudent100% (2)
- How To Choose The Right Data VisualizationDocument27 pagesHow To Choose The Right Data VisualizationAli Bayesteh100% (2)
- GENUS Clock Gating Timing CheckDocument17 pagesGENUS Clock Gating Timing Checkwasimhassan100% (1)
- Electric Machinery and Transformers - I. L. Kosow PDFDocument413 pagesElectric Machinery and Transformers - I. L. Kosow PDFzcjswordNo ratings yet
- Principal Component Analysis: Term Paper For Data Mining & Data WarehousingDocument11 pagesPrincipal Component Analysis: Term Paper For Data Mining & Data Warehousinggirish90No ratings yet
- Coincent - Data Science With Python AssignmentDocument23 pagesCoincent - Data Science With Python AssignmentSai Nikhil Nellore100% (2)
- LWP ManualDocument14 pagesLWP ManualShabbir OsmaniNo ratings yet
- Predicting Sonar Rocks Against Mines With MLDocument7 pagesPredicting Sonar Rocks Against Mines With MLChandu sandyNo ratings yet
- Assignment 3Document8 pagesAssignment 3mohamedmariam490No ratings yet
- Package Ca': R Topics DocumentedDocument22 pagesPackage Ca': R Topics DocumentedJuanCarlosEspecializaciónNo ratings yet
- Assignment 2 With ProgramDocument8 pagesAssignment 2 With ProgramPalash SarowareNo ratings yet
- RBF, KNN, SVM, DTDocument9 pagesRBF, KNN, SVM, DTQurrat Ul AinNo ratings yet
- Pattern Recognition By: Artificial Neural Networking (Ann)Document19 pagesPattern Recognition By: Artificial Neural Networking (Ann)Nikhil MahajanNo ratings yet
- Principal Component AnalysisDocument23 pagesPrincipal Component AnalysisAmandeep SharmaNo ratings yet
- RnpregresskernelDocument24 pagesRnpregresskernelDaniel Redel SaavedraNo ratings yet
- Feature Selection For Nonlinear Kernel Support Vector MachinesDocument6 pagesFeature Selection For Nonlinear Kernel Support Vector MachinesSelly Anastassia Amellia KharisNo ratings yet
- Pca TutorialDocument11 pagesPca TutorialpreethihpNo ratings yet
- Machine LearningDocument56 pagesMachine LearningMani Vrs100% (3)
- On Input Selection With Reversible Jump Markov Chain Monte Carlo SamplingDocument10 pagesOn Input Selection With Reversible Jump Markov Chain Monte Carlo SamplingMutahira TahirNo ratings yet
- Algorithms For Concurrency Paper PDFDocument9 pagesAlgorithms For Concurrency Paper PDFranjith rNo ratings yet
- CSC649 Lecture 3 Unsupervised ML - KMeansClusteringDocument22 pagesCSC649 Lecture 3 Unsupervised ML - KMeansClusteringRyan anak GaybristiNo ratings yet
- 1.0 Modeling: 1.1 ClassificationDocument5 pages1.0 Modeling: 1.1 ClassificationBanujan KuhaneswaranNo ratings yet
- Machine Learning AlgorithmsDocument9 pagesMachine Learning AlgorithmsRaghupal Reddy GangulaNo ratings yet
- This Study Resource WasDocument4 pagesThis Study Resource WasJohn SolomonNo ratings yet
- Interview Preparing - ML DraftDocument12 pagesInterview Preparing - ML Draftالريس حمادةNo ratings yet
- CORRELATION AND COVARIANCE in RDocument24 pagesCORRELATION AND COVARIANCE in RRenukaNo ratings yet
- KMEANSDocument9 pagesKMEANSjohnzenbano120No ratings yet
- Int QnsDocument9 pagesInt QnsAnish RNo ratings yet
- Scale-Based Clustering The Radial Basis Function: NetworkDocument6 pagesScale-Based Clustering The Radial Basis Function: NetworkMahakGoindaniNo ratings yet
- Package Nnet': R Topics DocumentedDocument11 pagesPackage Nnet': R Topics DocumentedDiegoPedroNo ratings yet
- Algo PaperDocument5 pagesAlgo PaperUzmanNo ratings yet
- Package Sier': R Topics DocumentedDocument7 pagesPackage Sier': R Topics DocumentedChandrajeet ChavhanNo ratings yet
- Tracking The Progress of The Lanczos Algorithm For Large Symmetric EigenproblemsDocument21 pagesTracking The Progress of The Lanczos Algorithm For Large Symmetric Eigenproblemsjuan carlos molano toroNo ratings yet
- Comparison of Density-Based Clustering Algorithms: Mariam RehmanDocument5 pagesComparison of Density-Based Clustering Algorithms: Mariam RehmansuserNo ratings yet
- Principal Component AnalysisDocument9 pagesPrincipal Component AnalysisGeethakshaya100% (1)
- KNN HMMDocument51 pagesKNN HMMRohitNo ratings yet
- tmp655C TMPDocument1 pagetmp655C TMPFrontiersNo ratings yet
- Package Soma': R Topics DocumentedDocument7 pagesPackage Soma': R Topics DocumentedRotsi JussicaNo ratings yet
- Q. 1) What Is Class Condition Density? (3 Marks) AnsDocument12 pagesQ. 1) What Is Class Condition Density? (3 Marks) AnsMrunal BhilareNo ratings yet
- Module - 5 Lecture Notes - 5: Remote Sensing-Digital Image Processing Information Extraction Principal Component AnalysisDocument10 pagesModule - 5 Lecture Notes - 5: Remote Sensing-Digital Image Processing Information Extraction Principal Component Analysisgoel2001No ratings yet
- Adhikary e Murty - 2012 - Feature Selection For Unsupervised LearningDocument8 pagesAdhikary e Murty - 2012 - Feature Selection For Unsupervised LearningEdilson Guedes de AlmeidaNo ratings yet
- Support Vector Machines: The Interface To Libsvm in Package E1071 by David Meyer FH Technikum Wien, AustriaDocument8 pagesSupport Vector Machines: The Interface To Libsvm in Package E1071 by David Meyer FH Technikum Wien, AustriaDoom Head 47No ratings yet
- Package Fasthica': R Topics DocumentedDocument8 pagesPackage Fasthica': R Topics DocumentedCliqueLearn E-LearningNo ratings yet
- Linear Programming With MATLABDocument51 pagesLinear Programming With MATLABTangerine DianeNo ratings yet
- Wavelet Kernel Atik 04Document5 pagesWavelet Kernel Atik 04Raiyan AshrafNo ratings yet
- MapDocument5 pagesMapMarc AsenjoNo ratings yet
- Ranking of Closeness Centrality For Large-Scale Social NetworksDocument10 pagesRanking of Closeness Centrality For Large-Scale Social NetworksArdiansyah SNo ratings yet
- Bookkeeping Functions: RandomDocument16 pagesBookkeeping Functions: Randomlibin_paul_2No ratings yet
- SVM in R (David Meyer)Document8 pagesSVM in R (David Meyer)alexa_sherpyNo ratings yet
- Major Classes of Neural NetworksDocument21 pagesMajor Classes of Neural Networksbhaskar rao mNo ratings yet
- Package Mvtnorm': R Topics DocumentedDocument17 pagesPackage Mvtnorm': R Topics DocumentedMuhammad Gabdika BayubuanaNo ratings yet
- Agglomerative Mean-Shift ClusteringDocument7 pagesAgglomerative Mean-Shift ClusteringkarthikNo ratings yet
- Fast Reciprocal Nearest Neighbors ClusteringDocument5 pagesFast Reciprocal Nearest Neighbors ClusteringVaziel IvansNo ratings yet
- SvmdocDocument8 pagesSvmdocEZ112No ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- Data Hiding and Retrieval Using Permutation Index MethodDocument6 pagesData Hiding and Retrieval Using Permutation Index MethodWalid El-ShafaiNo ratings yet
- Eem520l3 2023Document25 pagesEem520l3 2023Berkan TezcanNo ratings yet
- A Statistical Theory of Chord Under Churn: AbstractDocument6 pagesA Statistical Theory of Chord Under Churn: AbstractNghĩa ZerNo ratings yet
- Package Nleqslv': R Topics DocumentedDocument19 pagesPackage Nleqslv': R Topics Documentedrezza ruzuqiNo ratings yet
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- Animate Ggplots With Gganimate::: Cheat SheetDocument2 pagesAnimate Ggplots With Gganimate::: Cheat SheetJosé AnguloNo ratings yet
- SDFF SDF SDFDFDocument1 pageSDFF SDF SDFDFjorge musajaNo ratings yet
- J HKJDocument3 pagesJ HKJjorge musajaNo ratings yet
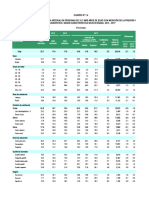
- Cuadro #1.4 Perú: Prevalencia de Hipertensión Arterial en Personas de 15 Y Más Años de Edad Con Medición de La Presión Arterial Alta Y Diagnóstico, Según Característica Seleccionada, 2014 - 2017Document4 pagesCuadro #1.4 Perú: Prevalencia de Hipertensión Arterial en Personas de 15 Y Más Años de Edad Con Medición de La Presión Arterial Alta Y Diagnóstico, Según Característica Seleccionada, 2014 - 2017jorge musajaNo ratings yet
- Loan Agreement: Acceleration ClauseDocument2 pagesLoan Agreement: Acceleration ClauseSomething SuspiciousNo ratings yet
- 10 Problem For The Topic 9 & 10 Hicao GroupDocument4 pages10 Problem For The Topic 9 & 10 Hicao GroupArvin ArmojallasNo ratings yet
- Gel Electrophoresis Worksheet Teacher AnswersDocument3 pagesGel Electrophoresis Worksheet Teacher AnswersChris FalokunNo ratings yet
- Pointers in CDocument25 pagesPointers in CSainiNishrithNo ratings yet
- Modal Verbs of Ability and PossibilityDocument12 pagesModal Verbs of Ability and PossibilitymslolinrNo ratings yet
- A Control Method For Power-Assist Devices Using A BLDC Motor For Manual WheelchairsDocument7 pagesA Control Method For Power-Assist Devices Using A BLDC Motor For Manual WheelchairsAhmed ShoeebNo ratings yet
- Epidemiological Triad of HIV/AIDS: AgentDocument8 pagesEpidemiological Triad of HIV/AIDS: AgentRakib HossainNo ratings yet
- Review Systems of Linear Equations All MethodsDocument4 pagesReview Systems of Linear Equations All Methodsapi-265647260No ratings yet
- FCC O Cials Denounce Lawmakers' Attempts To Censor NewsroomsDocument52 pagesFCC O Cials Denounce Lawmakers' Attempts To Censor NewsroomsKeithStewartNo ratings yet
- Engineering Mathematics Questions and AnswersDocument9 pagesEngineering Mathematics Questions and AnswersZaky Muzaffar100% (1)
- Introduction To Object Oriented Database: Unit-IDocument67 pagesIntroduction To Object Oriented Database: Unit-Ipreetham rNo ratings yet
- Preliminary Voters ListDocument86 pagesPreliminary Voters Listمحمد منيب عبادNo ratings yet
- Assignment Group OSHADocument10 pagesAssignment Group OSHAariffikriismailNo ratings yet
- SmoothWall Express 2.0 Quick-Start GuideDocument6 pagesSmoothWall Express 2.0 Quick-Start Guideinfobits100% (1)
- Sample Engagement LetterDocument5 pagesSample Engagement Letterprincess_camarilloNo ratings yet
- STS Reviewer FinalsDocument33 pagesSTS Reviewer FinalsLeiNo ratings yet
- Appendicitis Case StudyDocument6 pagesAppendicitis Case StudyKimxi Chiu LimNo ratings yet
- SLHT Grade 7 CSS Week 5 Without Answer KeyDocument6 pagesSLHT Grade 7 CSS Week 5 Without Answer KeyprinceyahweNo ratings yet
- Damask: by ChenoneDocument17 pagesDamask: by ChenoneYasir IjazNo ratings yet
- Trend Trading StocksDocument64 pagesTrend Trading Stockssasi717100% (1)
- Pe8 Mod5Document16 pagesPe8 Mod5Cryzel MuniNo ratings yet
- Clepsydra - PesquisaDocument2 pagesClepsydra - PesquisaJose Maria SantosNo ratings yet
- Kobelco CK1100G Spec BookDocument38 pagesKobelco CK1100G Spec BookEjeantengNo ratings yet
- MetLife CaseDocument4 pagesMetLife Casekatee3847No ratings yet
- Loch ChildrenDocument4 pagesLoch ChildrenLauro De Jesus FernandesNo ratings yet
- Hybrid Neural-Network - Genetic Algorithm Technique For Aircraft Engine Performance Diagnostics Developed and DemonstratedDocument4 pagesHybrid Neural-Network - Genetic Algorithm Technique For Aircraft Engine Performance Diagnostics Developed and Demonstratedmohamad theibechNo ratings yet
- Cinnamon RollDocument1 pageCinnamon RollMaria Manoa GantalaNo ratings yet