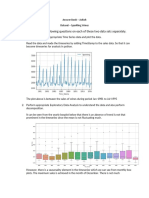
You might also like
- Vijaya MLDocument26 pagesVijaya MLVijayalakshmi Palaniappan83% (6)
- Analyze Wine Sales and Forecast Future TrendsDocument70 pagesAnalyze Wine Sales and Forecast Future TrendsAnushi100% (4)
- EXTENDED PROJECT-Shoe - SalesDocument28 pagesEXTENDED PROJECT-Shoe - Salesrhea100% (5)
- Time Series Analysis - Univariate and Multivariate Methods by William Wei PDFDocument634 pagesTime Series Analysis - Univariate and Multivariate Methods by William Wei PDFAnuj Sachdev100% (3)
- Problem StatementDocument17 pagesProblem Statementgowtham100% (1)
- Practical Time Series Analysis Master Time Series Data Processing Visualization and Modeling Using PythonDocument238 pagesPractical Time Series Analysis Master Time Series Data Processing Visualization and Modeling Using PythonDavidReyes100% (11)
- Time Series Forecasting Project ReportDocument62 pagesTime Series Forecasting Project Reportpradeep100% (3)
- Time Series ForecastingDocument1 pageTime Series ForecastingAshu0% (1)
- Course Project Report: Indian Institute of Technology, KanpurDocument15 pagesCourse Project Report: Indian Institute of Technology, KanpurPrithvi SinghNo ratings yet
- The Role of Visual AnalysisDocument13 pagesThe Role of Visual AnalysisAngie Marcela Marulanda Meneses100% (2)
- Data Dictionary and Time Series AnalysisDocument8 pagesData Dictionary and Time Series AnalysisWildShyamNo ratings yet
- Tsf Project Faizanalisayyed 26012024Document72 pagesTsf Project Faizanalisayyed 26012024Faizan AliNo ratings yet
- TSF Sparkling MeenakarthikaDocument26 pagesTSF Sparkling Meenakarthikameena13121993No ratings yet
- Business Report TSF - Rose DataSetDocument52 pagesBusiness Report TSF - Rose DataSetCharit Sharma100% (1)
- DABM Lab Manual Syllabuswise PDFDocument111 pagesDABM Lab Manual Syllabuswise PDFqwertyuiop100% (1)
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz KhanNo ratings yet
- Rev Insurance Business ReportDocument4 pagesRev Insurance Business ReportPratigya pathakNo ratings yet
- Time Series Forecasting Project ReportDocument39 pagesTime Series Forecasting Project ReportAbhishek AbhiNo ratings yet
- Coding Project HairDocument8 pagesCoding Project HairHaritika ChhatwalNo ratings yet
- Forecasting Methods For Managers: TUTORIAL 4 - Optimisation and Out of Sample FittingDocument1 pageForecasting Methods For Managers: TUTORIAL 4 - Optimisation and Out of Sample FittingyourhunkieNo ratings yet
- Economic and Financial Modelling with EViews: A Guide for Students and ProfessionalsFrom EverandEconomic and Financial Modelling with EViews: A Guide for Students and ProfessionalsNo ratings yet
- Time Series Forecasting of Rose Wine SalesDocument69 pagesTime Series Forecasting of Rose Wine SalesPriyanka PatilNo ratings yet
- PriyankaSharma TSF SparklingDocument36 pagesPriyankaSharma TSF SparklingPriyanka SharmaNo ratings yet
- Dsce Dabm Lab ExcerciseDocument109 pagesDsce Dabm Lab ExcerciseAkhil TacoNo ratings yet
- Answer Book - Rose WinesDocument11 pagesAnswer Book - Rose WinesAshish AgrawalNo ratings yet
- MA ReinickeDocument50 pagesMA Reinickejalajsingh1987No ratings yet
- Time Series: Book 2Document45 pagesTime Series: Book 2squirrelalexisNo ratings yet
- Project +Sweta+Kumari+ +FRA+Milestone+2 July+2021Document18 pagesProject +Sweta+Kumari+ +FRA+Milestone+2 July+2021sweta kumari100% (1)
- Bitmap vs B-tree Index: When to Use EachDocument29 pagesBitmap vs B-tree Index: When to Use EachDeepak ChaudhryNo ratings yet
- SAS Econometrics and Time Series Analysis 2 For JMP: Second EditionDocument120 pagesSAS Econometrics and Time Series Analysis 2 For JMP: Second EditionAnifaNo ratings yet
- Chapter 12 Part 2_Arima Model Estimation_2023Document15 pagesChapter 12 Part 2_Arima Model Estimation_2023chau.nguyenminh2003No ratings yet
- Capstone Proect Notes 2Document16 pagesCapstone Proect Notes 2Deva Dass100% (2)
- AN3896Document24 pagesAN3896tanatosth100% (1)
- A Time Series Analysis of 252 Successive Days of The Russell Index. 1 Introduction and SummaryDocument15 pagesA Time Series Analysis of 252 Successive Days of The Russell Index. 1 Introduction and SummarypostscriptNo ratings yet
- Excel Forecasting FundamentalsDocument7 pagesExcel Forecasting Fundamentalsnauli10No ratings yet
- The BigChaos Solution to Winning the Netflix Grand PrizeDocument52 pagesThe BigChaos Solution to Winning the Netflix Grand Prizehectorcflores1No ratings yet
- Data Mining Project DSBA PCA Report FinalDocument21 pagesData Mining Project DSBA PCA Report Finalindraneel120No ratings yet
- James P Stevens - Intermediate Statistics - A Modern Approach-Routledge Academic (2007)Document474 pagesJames P Stevens - Intermediate Statistics - A Modern Approach-Routledge Academic (2007)xavierNo ratings yet
- Answer Book - Sparkling WinesDocument10 pagesAnswer Book - Sparkling WinesAshish AgrawalNo ratings yet
- SQL Server 2005 - CoursewareDocument108 pagesSQL Server 2005 - Coursewaremalai642No ratings yet
- OmegaDocument34 pagesOmegaAbdulla AlshehhiNo ratings yet
- Predictive Modelling: Linear Regression Analysis for Sales PredictionDocument35 pagesPredictive Modelling: Linear Regression Analysis for Sales PredictionGirish Chadha100% (3)
- Download Singular Spectrum Analysis Using R Hossein Hassani all chapterDocument64 pagesDownload Singular Spectrum Analysis Using R Hossein Hassani all chapterkaren.homan394100% (4)
- Project Time Series ForecastingDocument53 pagesProject Time Series Forecastingharish kumar100% (1)
- Ebook PDF Business Analytics A Management Approach PDFDocument35 pagesEbook PDF Business Analytics A Management Approach PDFshirley.gallo357100% (32)
- Creating and Examining Databases in SPSSDocument11 pagesCreating and Examining Databases in SPSSMark PeterNo ratings yet
- Stat 401B Final Exam F16-KeyDocument13 pagesStat 401B Final Exam F16-KeyjuanEs2374pNo ratings yet
- Machine Learning Project: Sneha Sharma PGPDSBA Mar'21 Group 2Document36 pagesMachine Learning Project: Sneha Sharma PGPDSBA Mar'21 Group 2preeti100% (2)
- Stat 401B Final Exam F16Document13 pagesStat 401B Final Exam F16juanEs2374pNo ratings yet
- Advanced Topics in SPCDocument10 pagesAdvanced Topics in SPCAngélica Ramos LopezNo ratings yet
- CS3361 Set2Document6 pagesCS3361 Set2hodit.itNo ratings yet
- Artificial Neural Network Applications for Software Reliability PredictionFrom EverandArtificial Neural Network Applications for Software Reliability PredictionNo ratings yet
- Lecture Notes WI3411TU Financial Time Series - 2021Document107 pagesLecture Notes WI3411TU Financial Time Series - 2021AlexandraNo ratings yet
- Profit Driven Business Analytics: A Practitioner's Guide to Transforming Big Data into Added ValueFrom EverandProfit Driven Business Analytics: A Practitioner's Guide to Transforming Big Data into Added ValueNo ratings yet
- Page 006Document1 pagePage 006francis earlNo ratings yet
- LDA KNN LogisticDocument29 pagesLDA KNN Logisticshruti gujar100% (1)
- Benchmarking MLDocument9 pagesBenchmarking MLYentl HendrickxNo ratings yet
- Applied Multivariate Statistics For The Social Sciences: University of CincinnatiDocument708 pagesApplied Multivariate Statistics For The Social Sciences: University of CincinnatiNeuronas PsicambNo ratings yet
- Fift PresentationDocument23 pagesFift PresentationMichael AdonuNo ratings yet
- The Relative Performance of VAR and VECM Model: Xzhang@business - Queensu.caDocument4 pagesThe Relative Performance of VAR and VECM Model: Xzhang@business - Queensu.caAlissa BarnesNo ratings yet
- List of Programs in R 2 SemDocument48 pagesList of Programs in R 2 Semsamarth agarwalNo ratings yet
- Student Handouts Choosing Chart TypesDocument129 pagesStudent Handouts Choosing Chart TypesARCHANA RNo ratings yet
- CodeDocument9 pagesCodeARCHANA RNo ratings yet
- Accelerator Program in Artificial Intelligence and Machine LearningDocument19 pagesAccelerator Program in Artificial Intelligence and Machine LearningARCHANA RNo ratings yet
- Titanic 3Document74 pagesTitanic 3Ifan AzizNo ratings yet
- Tableau+2020 2+relationshipsDocument2 pagesTableau+2020 2+relationshipsARCHANA RNo ratings yet
- Suresh-Rose Time Series Forecasting Project ReportDocument75 pagesSuresh-Rose Time Series Forecasting Project ReportARCHANA RNo ratings yet
- ViredDocument4 pagesViredARCHANA RNo ratings yet
- Suresh-Sparkling Time Series Forecasting Project ReportDocument73 pagesSuresh-Sparkling Time Series Forecasting Project ReportARCHANA RNo ratings yet
- Choosing A Good ChartDocument1 pageChoosing A Good ChartARCHANA RNo ratings yet
- Plan The Week - Storytelling With Data-1Document5 pagesPlan The Week - Storytelling With Data-1ARCHANA RNo ratings yet
- Saraswathy Sridhar 3Document3 pagesSaraswathy Sridhar 3ARCHANA RNo ratings yet
- DSML Brochure 2023 Latest FebDocument18 pagesDSML Brochure 2023 Latest FebARCHANA RNo ratings yet
- How To Install Tableau PublicDocument3 pagesHow To Install Tableau PublicARCHANA RNo ratings yet
- Data Fallacies To AvoidDocument1 pageData Fallacies To Avoidcodestudent405No ratings yet
- Data Visualisation Using TableauDocument12 pagesData Visualisation Using TableauARCHANA RNo ratings yet
- Statistics and Machine LearningDocument51 pagesStatistics and Machine LearningARCHANA RNo ratings yet
- Descriptive Statistics 2Document40 pagesDescriptive Statistics 2ARCHANA RNo ratings yet
- Statistics Interview QuestionsDocument5 pagesStatistics Interview QuestionsARCHANA R100% (1)
- Import & Clean Energy Consumption DataDocument25 pagesImport & Clean Energy Consumption DataARCHANA RNo ratings yet
- Wine DSDocument14 pagesWine DSARCHANA RNo ratings yet
- Machine: LearningDocument15 pagesMachine: LearningARCHANA RNo ratings yet
- Feature EngineeringDocument23 pagesFeature EngineeringARCHANA RNo ratings yet
- MACHINE LEARNING AND STATISTICS TEAM MEMBERDocument42 pagesMACHINE LEARNING AND STATISTICS TEAM MEMBERARCHANA RNo ratings yet
- Statistics Materials: Data Science: Week 9Document22 pagesStatistics Materials: Data Science: Week 9ARCHANA RNo ratings yet
- Machine Learning: by Team 2Document41 pagesMachine Learning: by Team 2ARCHANA RNo ratings yet
- Deposit Subscription: Eda Mini ProjectDocument41 pagesDeposit Subscription: Eda Mini ProjectARCHANA RNo ratings yet
- Titanic DS CallengeDocument24 pagesTitanic DS CallengeARCHANA RNo ratings yet
- Statistical Data Analysis VisualizationDocument16 pagesStatistical Data Analysis VisualizationARCHANA RNo ratings yet
- Empirical Trade CourseDocument3 pagesEmpirical Trade CoursesaloniNo ratings yet
- A Pervasive Sensing Approach To Automatic Assessment of Trunk Coordination Using Mobile DevicesDocument18 pagesA Pervasive Sensing Approach To Automatic Assessment of Trunk Coordination Using Mobile DevicesZilu LiangNo ratings yet
- Project 2 Factor Hair Revised Case StudyDocument25 pagesProject 2 Factor Hair Revised Case StudyrishitNo ratings yet
- Characteristics That Distinguish Quantitative and Qualitative ResearchDocument32 pagesCharacteristics That Distinguish Quantitative and Qualitative Researchgerald martosNo ratings yet
- VDA Volume Product Safety and Conformity - February 2018 PDFDocument35 pagesVDA Volume Product Safety and Conformity - February 2018 PDFPatryk RączyNo ratings yet
- Learning Book 11 FebDocument322 pagesLearning Book 11 FebTushar AgarwalNo ratings yet
- BPD Surveillance22Document56 pagesBPD Surveillance22Adam ThompsonNo ratings yet
- Senior High School: Rizal ST., Guimbal, IloiloDocument4 pagesSenior High School: Rizal ST., Guimbal, IloiloLeah LabelleNo ratings yet
- How To Calculate The Mean, Mode and Median LA 2016Document22 pagesHow To Calculate The Mean, Mode and Median LA 2016Sudhiksha SurmughiNo ratings yet
- Homework 1 Regression Analysis of Height, Weight, and Exam ScoresDocument2 pagesHomework 1 Regression Analysis of Height, Weight, and Exam ScoresgleniaNo ratings yet
- Impact of Celebrity Endorsement on Consumer Buying BehaviorDocument12 pagesImpact of Celebrity Endorsement on Consumer Buying BehaviorNishant PandeyNo ratings yet
- ContinueDocument2 pagesContinueranjeet patilNo ratings yet
- Talent and Recruiting Consultant Resume LeBlanc 2019Document4 pagesTalent and Recruiting Consultant Resume LeBlanc 2019Christina LeBlancNo ratings yet
- Demand Forecasting-Quantitative MethodsDocument47 pagesDemand Forecasting-Quantitative MethodsRamteja SpuranNo ratings yet
- Biostatistics 201 Mock Exam FinalDocument12 pagesBiostatistics 201 Mock Exam FinalJordan SantosNo ratings yet
- Best Practice Recommendations For Using Structural Equation Modelling in Psychological ResearchDocument16 pagesBest Practice Recommendations For Using Structural Equation Modelling in Psychological ResearchPriyashree RoyNo ratings yet
- Week 7 Statistics - TaggedDocument72 pagesWeek 7 Statistics - TaggedNabielaNo ratings yet
- Chap 001 COMPLETE BUSINESS STATISTICSDocument79 pagesChap 001 COMPLETE BUSINESS STATISTICSShekhar Saurabh Biswal75% (4)
- What Are Non Parametric Methods!Document19 pagesWhat Are Non Parametric Methods!Omkar BansodeNo ratings yet
- Business Analytics in Performance ManagementDocument18 pagesBusiness Analytics in Performance Managementsambit kumarNo ratings yet
- Employee Motivation and Job Performance of Selected Construction Companies in Rivers StateDocument8 pagesEmployee Motivation and Job Performance of Selected Construction Companies in Rivers StateIJEMR JournalNo ratings yet
- Ie Electives Final Exam - RampulaDocument2 pagesIe Electives Final Exam - RampulaRampula mary janeNo ratings yet
- Overhead Variance Analysis PDFDocument2 pagesOverhead Variance Analysis PDFKim100% (1)
- FMEA for CNC Machines in Valve IndustryDocument92 pagesFMEA for CNC Machines in Valve IndustrybhaskarjalanNo ratings yet
- 17mba 025Document42 pages17mba 025Er Aks PatelNo ratings yet
- Heizer Om11 Irm Ch04Document18 pagesHeizer Om11 Irm Ch04DHRUV SONAGARANo ratings yet
- User Manual On Correlation Analysis Using JamoviDocument7 pagesUser Manual On Correlation Analysis Using JamoviStephanie Camille ChuaNo ratings yet
- Evaluation of The Materials Damage in Gas TurbineDocument9 pagesEvaluation of The Materials Damage in Gas TurbineThanapaet RittirutNo ratings yet
- 1852 PDFDocument10 pages1852 PDFAnonymous uBpC2WO5lNo ratings yet