You might also like
- Filipino Construction TermsDocument6 pagesFilipino Construction TermsAdrian Perez75% (4)
- A Survey of Parallel Programming Models and Tools in The Multi and Many-Core EraDocument18 pagesA Survey of Parallel Programming Models and Tools in The Multi and Many-Core Eraramon91No ratings yet
- AIR Conditioner: Owner'S ManualDocument52 pagesAIR Conditioner: Owner'S Manualashley diazNo ratings yet
- The Landscape of Parallel Computing Research: A View From BerkeleyDocument56 pagesThe Landscape of Parallel Computing Research: A View From BerkeleyDima LitvinovNo ratings yet
- High Performance Computing in Power System Applications.: September 1996Document24 pagesHigh Performance Computing in Power System Applications.: September 1996Ahmed adelNo ratings yet
- Laszewski IEEECloud2012 Id 4803Document8 pagesLaszewski IEEECloud2012 Id 4803Thiago SenaNo ratings yet
- An Approach of RDD Optimization in Big Data AnalytDocument9 pagesAn Approach of RDD Optimization in Big Data Analytmary maryNo ratings yet
- New Challenges of Parallel Job Scheduling: Springer-Verlag Berlin Heidelberg 2008Document23 pagesNew Challenges of Parallel Job Scheduling: Springer-Verlag Berlin Heidelberg 2008ssfofoNo ratings yet
- Grid2005 NBCR SoaDocument8 pagesGrid2005 NBCR Soaxico107No ratings yet
- High Performance Computing Student Projects PDFDocument17 pagesHigh Performance Computing Student Projects PDFSaurabh KadamNo ratings yet
- Research Paper On Green Cloud ComputingDocument5 pagesResearch Paper On Green Cloud Computingjsxmwytlg100% (1)
- PHD Thesis On System DynamicsDocument9 pagesPHD Thesis On System Dynamicsoabfziiig100% (2)
- New Advances in High Performance Computing and Simulation: Parallel and Distributed Systems, Algorithms, and ApplicationsDocument7 pagesNew Advances in High Performance Computing and Simulation: Parallel and Distributed Systems, Algorithms, and ApplicationspattysuarezNo ratings yet
- FALCON: A MATLAB Interactive Restructuring Compiler.: January 1995Document23 pagesFALCON: A MATLAB Interactive Restructuring Compiler.: January 1995Anchuri LokeshNo ratings yet
- 1 s2.0 S1877050915032664 MainDocument10 pages1 s2.0 S1877050915032664 MainNhat NguyenNo ratings yet
- Senger Et Al-2016-Concurrency and Computation Practice and ExperienceDocument4 pagesSenger Et Al-2016-Concurrency and Computation Practice and ExperienceMahalingam RamaswamyNo ratings yet
- Green Computing Research Papers 2014Document6 pagesGreen Computing Research Papers 2014qhujvirhf100% (1)
- Berkeley ViewDocument54 pagesBerkeley Viewshams43No ratings yet
- Optimized Cloud Resource Management and Scheduling: Theories and PracticesFrom EverandOptimized Cloud Resource Management and Scheduling: Theories and PracticesNo ratings yet
- Thesis Energy EfficiencyDocument8 pagesThesis Energy Efficiencyynwtcpwff100% (2)
- Thesis HvaDocument8 pagesThesis HvaIWillPayYouToWriteMyPaperUK100% (2)
- Green Computing Research Papers PDFDocument4 pagesGreen Computing Research Papers PDFxwrcmecnd100% (1)
- Ophidia: Toward Big Data Analytics For EscienceDocument10 pagesOphidia: Toward Big Data Analytics For EsciencehidrobhNo ratings yet
- Editorial: Complexity Problems Handled by Big Data TechnologyDocument8 pagesEditorial: Complexity Problems Handled by Big Data TechnologyPepe MNo ratings yet
- Epfl Thesis DefenseDocument4 pagesEpfl Thesis Defensegbx272pg100% (2)
- Parallel ProcessingDocument5 pagesParallel ProcessingMustafa Al-NaimiNo ratings yet
- Cai NatDocument25 pagesCai Natquang long TrinhNo ratings yet
- February 22, 2010Document53 pagesFebruary 22, 2010tt_aljobory3911No ratings yet
- Research Papers On Database Management System PDFDocument5 pagesResearch Papers On Database Management System PDFvbbcvwplgNo ratings yet
- Green Cloud Computing Research PapersDocument4 pagesGreen Cloud Computing Research Papersgw0a869x100% (1)
- Research Papers On Energy Efficiency in Cloud ComputingDocument7 pagesResearch Papers On Energy Efficiency in Cloud ComputingklbndecndNo ratings yet
- Author Carson You PBP 5Document9 pagesAuthor Carson You PBP 5api-642869165No ratings yet
- A Low-Cost Energy-Efficient Raspberry Pi Cluster For Data Mining AlgorithmsDocument13 pagesA Low-Cost Energy-Efficient Raspberry Pi Cluster For Data Mining Algorithmsnico la roccaNo ratings yet
- Research Paper Green ComputingDocument5 pagesResearch Paper Green Computingrsbptyplg100% (1)
- Electronics Thesis PDFDocument4 pagesElectronics Thesis PDFCarrie Tran100% (2)
- MSC Thesis Software EngineeringDocument4 pagesMSC Thesis Software Engineeringsprxzfugg100% (1)
- Performance, Security, and EnergyDocument9 pagesPerformance, Security, and EnergyPradum KumarNo ratings yet
- Paper SLEDocument12 pagesPaper SLEJoão BernardoNo ratings yet
- MIT Sloan School of Management Final Report For S-Lab Project With Facebook, Inc. Introduction & ObjectiveDocument21 pagesMIT Sloan School of Management Final Report For S-Lab Project With Facebook, Inc. Introduction & ObjectiveScree BeedownNo ratings yet
- The Landscape of Parallel Computing ResearchDocument56 pagesThe Landscape of Parallel Computing ResearchFeharaNo ratings yet
- Ieee Research Paper On Green ComputingDocument5 pagesIeee Research Paper On Green Computingfypikovekef2100% (3)
- Nextflow in Bioinformatics Executors Performance - 2023 - Future Generation CoDocument12 pagesNextflow in Bioinformatics Executors Performance - 2023 - Future Generation CoRuchira SahaNo ratings yet
- Research Paper Computer Architecture PDFDocument8 pagesResearch Paper Computer Architecture PDFcammtpw6100% (1)
- Abstract of ThesisDocument17 pagesAbstract of ThesisGiorgis GeorgakoudisNo ratings yet
- Computação ParalelaDocument18 pagesComputação ParalelaGuilherme AlminhanaNo ratings yet
- M.SC Dissertation FormatDocument5 pagesM.SC Dissertation FormatWriteMySociologyPaperAlbuquerque100% (1)
- 36 Comparative Analysis of EnergyDocument3 pages36 Comparative Analysis of EnergyBaranishankarNo ratings yet
- 2008 01 ConfigDocument2 pages2008 01 ConfigDamodar TeluNo ratings yet
- Mobile Cloud Computing Literature ReviewDocument6 pagesMobile Cloud Computing Literature Reviewc5jbmre7100% (1)
- Energy Efficiency Across Programming Languages: How Do Energy, Time, and Memory Relate?Document12 pagesEnergy Efficiency Across Programming Languages: How Do Energy, Time, and Memory Relate?Fredy MasandikaNo ratings yet
- Term Paper About Computer ArchitectureDocument6 pagesTerm Paper About Computer Architectureaflsmceoc100% (1)
- Advances in Data Warehousing and OLAP in The Big Data EraDocument2 pagesAdvances in Data Warehousing and OLAP in The Big Data EraM. Nishom, S.KomNo ratings yet
- 1.6 Final Thoughts: 1 Parallel Programming Models 49Document5 pages1.6 Final Thoughts: 1 Parallel Programming Models 49latinwolfNo ratings yet
- Literature Review On Cloud ComputingDocument7 pagesLiterature Review On Cloud Computingqtbghsbnd100% (1)
- Sample Literature Review Cloud ComputingDocument10 pagesSample Literature Review Cloud Computingc5h4drzj100% (1)
- A Systematic Approach To Composing and Optimizing Application WorkflowsDocument9 pagesA Systematic Approach To Composing and Optimizing Application WorkflowsLeo Kwee WahNo ratings yet
- Ijcnc 52018 FinalDocument13 pagesIjcnc 52018 Finalabutalib fadlallahNo ratings yet
- Parallel Computer Architecture A Hardware / Software ApproachDocument877 pagesParallel Computer Architecture A Hardware / Software ApproachTarek Jabre100% (1)
- 1 s2.0 S0167739X15003362 MainDocument18 pages1 s2.0 S0167739X15003362 MaingmgaargiNo ratings yet
- PowerFactory Applications for Power System AnalysisFrom EverandPowerFactory Applications for Power System AnalysisFrancisco M. Gonzalez-LongattNo ratings yet
- Project ReportDocument14 pagesProject ReportNoah100% (7)
- MSDS DowthermDocument4 pagesMSDS DowthermfebriantabbyNo ratings yet
- Armadio Presentation-2019Document45 pagesArmadio Presentation-2019Subhash Singh TomarNo ratings yet
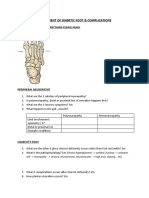
- Assessment of Diabetic FootDocument7 pagesAssessment of Diabetic FootChathiya Banu KrishenanNo ratings yet
- Statics: Vector Mechanics For EngineersDocument39 pagesStatics: Vector Mechanics For EngineersVijay KumarNo ratings yet
- 1 s2.0 S1110016815000563 Main PDFDocument13 pages1 s2.0 S1110016815000563 Main PDFvale1299No ratings yet
- TM 10-3930-669-34 Forklift Truck 6K Drexel MDL R60SL-DC Part 1Document294 pagesTM 10-3930-669-34 Forklift Truck 6K Drexel MDL R60SL-DC Part 1AdvocateNo ratings yet
- Manuscript FsDocument76 pagesManuscript FsRalph HumpaNo ratings yet
- Pharmalytica Exhibitor List 2023Document3 pagesPharmalytica Exhibitor List 2023Suchita PoojaryNo ratings yet
- Eco Exercise 3answer Ans 1Document8 pagesEco Exercise 3answer Ans 1Glory PrintingNo ratings yet
- Arts Class: Lesson 01Document24 pagesArts Class: Lesson 01Lianne BryNo ratings yet
- Ecological Quality RatioDocument24 pagesEcological Quality RatiofoocheehungNo ratings yet
- Kinder DLL Week 8Document15 pagesKinder DLL Week 8Jainab Pula SaiyadiNo ratings yet
- Region 1 - Concreting Works Materials Prices - PHILCON PRICESDocument9 pagesRegion 1 - Concreting Works Materials Prices - PHILCON PRICESMark Gregory RimandoNo ratings yet
- Las Tech Drafting 3Q WKDocument13 pagesLas Tech Drafting 3Q WKClemenda TuscanoNo ratings yet
- Bchem 455 - Module 3Document42 pagesBchem 455 - Module 3WilliamNo ratings yet
- 500 TransDocument5 pages500 TransRodney WellsNo ratings yet
- Worksheet - 143760187HS-II, TUTORIAL ON CH-5Document14 pagesWorksheet - 143760187HS-II, TUTORIAL ON CH-5A MusaverNo ratings yet
- SMC VM Eu PDFDocument66 pagesSMC VM Eu PDFjoguvNo ratings yet
- FebvreDocument449 pagesFebvreIan Pereira AlvesNo ratings yet
- Minimalist KWL Graphic OrganizerDocument2 pagesMinimalist KWL Graphic OrganizerIrish Nicole AlanoNo ratings yet
- Tabla9 1Document1 pageTabla9 1everquinNo ratings yet
- Tabla de Avances de AcesoriosDocument3 pagesTabla de Avances de AcesoriosPedro Diaz UzcateguiNo ratings yet
- Goa Daman & Diu Factory Rules PDFDocument141 pagesGoa Daman & Diu Factory Rules PDFmrudang1972100% (1)
- Course Code:TEX3021 Course Title: Wet Processing Technology-IIDocument20 pagesCourse Code:TEX3021 Course Title: Wet Processing Technology-IINakib Ibna BasharNo ratings yet
- Principles Involved in Baking 1Document97 pagesPrinciples Involved in Baking 1Milky BoyNo ratings yet
- Concrete Super Structure ReportDocument43 pagesConcrete Super Structure ReportLivian TeddyNo ratings yet
- Hashimoto's Thyroiditis: Veena RedkarDocument10 pagesHashimoto's Thyroiditis: Veena RedkarSan RedkarNo ratings yet