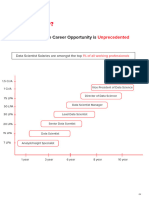
You might also like
- Google JAX Essentials: A quick practical learning of blazing-fast library for machine learning and deep learning projectsFrom EverandGoogle JAX Essentials: A quick practical learning of blazing-fast library for machine learning and deep learning projectsNo ratings yet
- Machine Learning with Python: A Comprehensive Guide with a Practical ExampleFrom EverandMachine Learning with Python: A Comprehensive Guide with a Practical ExampleNo ratings yet
- Brochure - UoA - CurriculumDocument13 pagesBrochure - UoA - CurriculumfgNo ratings yet
- Intellipaat's Data Science Architect Masters Course PDFDocument13 pagesIntellipaat's Data Science Architect Masters Course PDFankur.tomerNo ratings yet
- Data Analytics Full Time Bootcamp PDFDocument11 pagesData Analytics Full Time Bootcamp PDFAdrian Hurtado de Mendoza100% (1)
- Deep Learning SsuetDocument8 pagesDeep Learning SsuetSyed Raza Ur RehmanNo ratings yet
- Spark For Python Developers - Sample ChapterDocument32 pagesSpark For Python Developers - Sample ChapterPackt Publishing100% (6)
- Python Data Science CertificateDocument3 pagesPython Data Science CertificatechiahaoguangNo ratings yet
- Intellipaat's Data Science Architect Masters Course V1Document13 pagesIntellipaat's Data Science Architect Masters Course V1Gagana BNo ratings yet
- D P Lab ManualDocument54 pagesD P Lab Manualsanketwakde100No ratings yet
- Data Scientist Nanodegree Syllabus: Before You StartDocument5 pagesData Scientist Nanodegree Syllabus: Before You StartAditya the RetroNo ratings yet
- Data Analyst Nanodegree Program - SyllabusDocument7 pagesData Analyst Nanodegree Program - SyllabusShaikh Saad AlamNo ratings yet
- Packt - Hands On - Deep.learning - With.apache - Spark.2019Document363 pagesPackt - Hands On - Deep.learning - With.apache - Spark.2019yohoyonNo ratings yet
- My Linkedin ProfileDocument3 pagesMy Linkedin ProfileSai LikhithNo ratings yet
- Professional Program in Data Analytics: Outcome Driven, Practitioner DesignedDocument3 pagesProfessional Program in Data Analytics: Outcome Driven, Practitioner DesignedMANPREET SODHINo ratings yet
- Tentative Data Manipulation PythonDocument4 pagesTentative Data Manipulation Pythonimagtion pdrNo ratings yet
- Artificial Intelligence and Deep Learning: Certificate ProgramDocument12 pagesArtificial Intelligence and Deep Learning: Certificate ProgramDigvijay SolankiNo ratings yet
- Coding Dojo PH Course PacketDocument13 pagesCoding Dojo PH Course PacketFrancis FallorinNo ratings yet
- Learning Real-Time Processing With Spark Streaming - Sample ChapterDocument30 pagesLearning Real-Time Processing With Spark Streaming - Sample ChapterPackt PublishingNo ratings yet
- Data Analyst Nanodegree Syllabus with Python, R, SQL & TableauDocument7 pagesData Analyst Nanodegree Syllabus with Python, R, SQL & TableauReinaldy Maslim50% (2)
- INTELLIPAATDocument13 pagesINTELLIPAATSanad SawhneyNo ratings yet
- NumPy Essentials - Sample ChapterDocument16 pagesNumPy Essentials - Sample ChapterPackt Publishing50% (2)
- Productflyer - 978 1 4842 0964 6 PDFDocument1 pageProductflyer - 978 1 4842 0964 6 PDFduonghnNo ratings yet
- Big Data Analytics With Spark: A Practitioner's Guide To Using Spark For Large Scale Data AnalysisDocument1 pageBig Data Analytics With Spark: A Practitioner's Guide To Using Spark For Large Scale Data AnalysisShailendra chaudharyNo ratings yet
- Mongodb Homework 3.1 PythonDocument6 pagesMongodb Homework 3.1 Pythonafmtkadub100% (1)
- Data Scientist Nanodegree SyllabusDocument16 pagesData Scientist Nanodegree SyllabuslavanyaNo ratings yet
- Downloadable: Cheat Sheets For AI, Neural Networks, Machine Learning, Deep Learning & Data Science PDFDocument34 pagesDownloadable: Cheat Sheets For AI, Neural Networks, Machine Learning, Deep Learning & Data Science PDFfekoy61900No ratings yet
- ML - AI RoadmapDocument14 pagesML - AI Roadmapsanot31159No ratings yet
- Python Data Handling - A Deeper Dive - Live TrainingDocument4 pagesPython Data Handling - A Deeper Dive - Live Trainingsapabapjava2012No ratings yet
- Python Machine Learning: Machine Learning and Deep Learning With Python, Scikit-Learn, and TensorFlow 2, 3rd Edition - PythonDocument6 pagesPython Machine Learning: Machine Learning and Deep Learning With Python, Scikit-Learn, and TensorFlow 2, 3rd Edition - Pythonjodubalu0% (1)
- Fabric Data Science 1 150Document150 pagesFabric Data Science 1 150pascalburumeNo ratings yet
- Programming For Data Science Syllabus: Before You StartDocument5 pagesProgramming For Data Science Syllabus: Before You StartAbhimanyu BhatNo ratings yet
- Machine Learning With Spark - Sample ChapterDocument36 pagesMachine Learning With Spark - Sample ChapterPackt Publishing100% (1)
- Fabric Data ScienceDocument652 pagesFabric Data SciencepascalburumeNo ratings yet
- Data RoadmapDocument9 pagesData Roadmapadit369yaNo ratings yet
- Data Science Immersive Syllabus: CourseDocument4 pagesData Science Immersive Syllabus: Coursedel_espacioNo ratings yet
- Introduction To Programming Nanodegree Syllabus: Before You StartDocument6 pagesIntroduction To Programming Nanodegree Syllabus: Before You StartSatyam AnandNo ratings yet
- PYTHON FOR ANALYTICS: GAIN HANDS-ON SKILLS FOR BUSINESS APPLICATIONSDocument13 pagesPYTHON FOR ANALYTICS: GAIN HANDS-ON SKILLS FOR BUSINESS APPLICATIONSBiz InvestNo ratings yet
- Scientific Computing With Scala - Sample ChapterDocument33 pagesScientific Computing With Scala - Sample ChapterPackt PublishingNo ratings yet
- Professional Program in Data Science and Machine Learning: - ML EngineerDocument4 pagesProfessional Program in Data Science and Machine Learning: - ML EngineerMANPREET SODHINo ratings yet
- Udacity Enterprise Syllabus Data Streaming nd029Document12 pagesUdacity Enterprise Syllabus Data Streaming nd029Amir MarmulNo ratings yet
- 0901ec221090 RishavmudgalDocument11 pages0901ec221090 RishavmudgalSuryanshNo ratings yet
- Packt - Hands On - Big.data - Analytics.with - Pyspark.2019Document253 pagesPackt - Hands On - Big.data - Analytics.with - Pyspark.2019yohoyonNo ratings yet
- Lab ManualDocument100 pagesLab Manualaleesakhan28No ratings yet
- A Whirlwind Tour of PythonDocument88 pagesA Whirlwind Tour of PythonRadhesyam YarramsettyNo ratings yet
- Deep Learning For Computer Vision - Rajalingappa ShanmugamaniDocument427 pagesDeep Learning For Computer Vision - Rajalingappa ShanmugamaniTin Kuculo93% (14)
- Post Graduate Program In: Artificial Intelligence & Machine LearningDocument19 pagesPost Graduate Program In: Artificial Intelligence & Machine LearningTarun BaggaNo ratings yet
- Pyhton Libraries To LearnDocument2 pagesPyhton Libraries To LearnShlok MittalNo ratings yet
- Data Science - Full-TimeDocument35 pagesData Science - Full-TimeJuan SalinasNo ratings yet
- Learning Spark Preview EdDocument18 pagesLearning Spark Preview Edlinux87sNo ratings yet
- Data Science Course SyllabusDocument37 pagesData Science Course SyllabusFabulousMaxxNo ratings yet
- Spark 101Document25 pagesSpark 101Daniel OrtizNo ratings yet
- UntitledDocument248 pagesUntitledAliah Gie ZabalaNo ratings yet
- Data Science - Full-Time PDFDocument34 pagesData Science - Full-Time PDFGab UANo ratings yet
- Brochure MIT XPRO - Professional Certificate in Data Engineering - V44Document15 pagesBrochure MIT XPRO - Professional Certificate in Data Engineering - V44Henry JaimesNo ratings yet
- Practical 1to10Document32 pagesPractical 1to10hetprajapati2004217No ratings yet
- Python for Analytics: Master Data SkillsDocument14 pagesPython for Analytics: Master Data SkillsmartinNo ratings yet
- Apache Spark Graph Processing - Sample ChapterDocument22 pagesApache Spark Graph Processing - Sample ChapterPackt PublishingNo ratings yet
- Metis Bootcamp Curriculum 2020Document19 pagesMetis Bootcamp Curriculum 2020Haidar ANo ratings yet
- Specialised Programme On Big Data and Machine Learning - 8 WeeksDocument6 pagesSpecialised Programme On Big Data and Machine Learning - 8 Weekscop camarasNo ratings yet
- Nikmods Mig 29 PDF Plan Tiled 9pmkiuDocument18 pagesNikmods Mig 29 PDF Plan Tiled 9pmkiusfazistNo ratings yet
- KPK 10th Maths ch06 KM PDFDocument16 pagesKPK 10th Maths ch06 KM PDFmehreen arshad100% (1)
- Logistics and Warehousing Course OutlineDocument4 pagesLogistics and Warehousing Course OutlineManny Daniel AbuanNo ratings yet
- Win A RewardDocument1 pageWin A RewardsfazistNo ratings yet
- Science Fair Planning GuideDocument2 pagesScience Fair Planning GuideFranky KamagiNo ratings yet
- Negative Numbers: Extending Number LinesDocument10 pagesNegative Numbers: Extending Number LinessfazistNo ratings yet
- Learn Android App Development Without CodingDocument2 pagesLearn Android App Development Without CodingsfazistNo ratings yet
- 1.1 Real Numbers: (As Opposed To Fake Numbers?)Document17 pages1.1 Real Numbers: (As Opposed To Fake Numbers?)Nela AkmaliaNo ratings yet
- 1.1 Real Numbers: (As Opposed To Fake Numbers?)Document17 pages1.1 Real Numbers: (As Opposed To Fake Numbers?)Nela AkmaliaNo ratings yet
- Skip ListsDocument23 pagesSkip ListssfazistNo ratings yet
- XML in Android: Basics of User InterfaceDocument9 pagesXML in Android: Basics of User InterfacesfazistNo ratings yet
- Unix Cook BookDocument23 pagesUnix Cook Bookapi-3730515100% (1)
- CosmosCR Whitepaper V1.2Document50 pagesCosmosCR Whitepaper V1.2sfazistNo ratings yet
- CosmosCR Whitepaper V1.2Document50 pagesCosmosCR Whitepaper V1.2sfazistNo ratings yet
- Speech ActDocument14 pagesSpeech ActA. TENRY LAWANGEN ASPAT COLLE100% (2)
- Trimble MS750 - DatasheetDocument2 pagesTrimble MS750 - DatasheetHaffiz Yasin100% (1)
- Concours at The Paris Conservatory. The Pieces Were Written by Former Students of TheDocument52 pagesConcours at The Paris Conservatory. The Pieces Were Written by Former Students of ThePau MIÑANANo ratings yet
- Everything You Wanted To Know About OpensslDocument10 pagesEverything You Wanted To Know About OpensslnakhomNo ratings yet
- Adverbs of FrequencyDocument6 pagesAdverbs of FrequencyJoana PereiraNo ratings yet
- Jyotish - Marc Boney - Babel's Tower - The Astrology of PolyglotsDocument42 pagesJyotish - Marc Boney - Babel's Tower - The Astrology of PolyglotsRajesh S VNo ratings yet
- Linguistics Midterm TopicsDocument5 pagesLinguistics Midterm TopicsMadeline LeeahNo ratings yet
- AND Conditional: Zero First WorksheetDocument2 pagesAND Conditional: Zero First Worksheetгалина сосницькаNo ratings yet
- Types of Sentences Accdng To FunctionDocument8 pagesTypes of Sentences Accdng To FunctionMelanie C. lealNo ratings yet
- First Quarter Performance Task in EsP 4Document9 pagesFirst Quarter Performance Task in EsP 4Malhea VegeniaNo ratings yet
- Models of CommunicationDocument7 pagesModels of CommunicationKristine Mae Musa AñonuevoNo ratings yet
- Slot Deposit 10k Gbosky 6Document1 pageSlot Deposit 10k Gbosky 6naeng naengNo ratings yet
- Vdoc - Pub Classics of Semiotics 176 200Document25 pagesVdoc - Pub Classics of Semiotics 176 200limberthNo ratings yet
- Acting II SyllabusDocument2 pagesActing II SyllabusEthanFelizzari100% (1)
- InemDocument8 pagesInemKimberly Anne AlbarilloNo ratings yet
- Exploring SE For Android - Sample ChapterDocument19 pagesExploring SE For Android - Sample ChapterPackt PublishingNo ratings yet
- Gupta Et Al. (1989)Document23 pagesGupta Et Al. (1989)Prabath PzNo ratings yet
- Excel Grade 5 LessPlans Mod 3Document24 pagesExcel Grade 5 LessPlans Mod 3Narine HovhannisyanNo ratings yet
- How To Ace Your IELTS Writing TestDocument19 pagesHow To Ace Your IELTS Writing TestAnindia AuliaNo ratings yet
- Our PoemDocument6 pagesOur Poemapi-213540529No ratings yet
- Test 4to ADocument1 pageTest 4to AFlor De AnserisNo ratings yet
- Certified Data Scientist Brochure Datamites India V6.5Document22 pagesCertified Data Scientist Brochure Datamites India V6.5AmarNo ratings yet
- Ic 05Document11 pagesIc 05Luvie Jhun GahiNo ratings yet
- ESP Course and Syllabus Design Paper PDFDocument23 pagesESP Course and Syllabus Design Paper PDFputri novaNo ratings yet
- Fall 2020 TimetableDocument142 pagesFall 2020 TimetablemariamsaeedNo ratings yet
- Courtesy, Ceremonial, and Contest Speeches GuideDocument10 pagesCourtesy, Ceremonial, and Contest Speeches GuideSteps RolsNo ratings yet
- WEEK#3 Del Pilar, Jarule Matthew S. KOM - Pan2Document4 pagesWEEK#3 Del Pilar, Jarule Matthew S. KOM - Pan2deymgoods100% (2)
- MLII Modbus Mapping Manual FV 4-33-05Document118 pagesMLII Modbus Mapping Manual FV 4-33-05Sergio SosaNo ratings yet
- English Paper 1Document8 pagesEnglish Paper 1Marie Meeky MbeweNo ratings yet
- B I I B (BIIB) : Curriculum - Vitae DisciplineDocument4 pagesB I I B (BIIB) : Curriculum - Vitae DisciplinechinmayshastryNo ratings yet