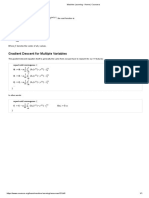
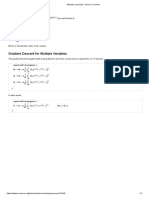
You might also like
- Lecture 8-ml On-Line LearningDocument48 pagesLecture 8-ml On-Line LearningJuan Javier GonzalezNo ratings yet
- Foundations of Machine Learning Lecture 6: Boosting and AdaBoostDocument42 pagesFoundations of Machine Learning Lecture 6: Boosting and AdaBoostAnonymous Wu14iV9dqNo ratings yet
- Assignment 1Document4 pagesAssignment 1PAPANo ratings yet
- HTMM NotesDocument3 pagesHTMM NotesDiane HuNo ratings yet
- MM Algorithm Guide for Optimization ProblemsDocument40 pagesMM Algorithm Guide for Optimization Problemssanka csaatNo ratings yet
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- Least Squares Problems: How To State and Solve Them, Then Evaluate Their SolutionsDocument63 pagesLeast Squares Problems: How To State and Solve Them, Then Evaluate Their SolutionsHông Hoa100% (1)
- A Simple Proof of AdaBoost AlgorithmDocument4 pagesA Simple Proof of AdaBoost AlgorithmXuqing WuNo ratings yet
- 7 PDFDocument1 page7 PDFLaith BounenniNo ratings yet
- 7 PDFDocument1 page7 PDFLaith BounenniNo ratings yet
- Contracts in MacroeconomicsDocument63 pagesContracts in Macroeconomics何旭波No ratings yet
- Robert E. Schapire: AT&T Labs, Shannon Laboratory 180 Park Avenue, Room A279, Florham Park, NJ 07932, USA SchapireDocument6 pagesRobert E. Schapire: AT&T Labs, Shannon Laboratory 180 Park Avenue, Room A279, Florham Park, NJ 07932, USA SchapireSaifuddin SidikiNo ratings yet
- NotesDocument8 pagesNotes박이삭No ratings yet
- Lagrange's Equations Degrees of FreedomDocument11 pagesLagrange's Equations Degrees of FreedomBilly BlattNo ratings yet
- Massachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 4: SolutionsDocument8 pagesMassachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 4: Solutionsjuanagallardo01No ratings yet
- Boosting: I I I IDocument5 pagesBoosting: I I I ISNo ratings yet
- The Schema Theorem and The Building Block Hypothesis: Natural ComputingDocument24 pagesThe Schema Theorem and The Building Block Hypothesis: Natural ComputingAbhishek ChattopadhyayNo ratings yet
- 1 Algorithm: For I 1 To N IfyDocument6 pages1 Algorithm: For I 1 To N IfyParias L. MukebaNo ratings yet
- Anthony Vaccaro MATH 264 Winter 2023 Assignment Assignment 6 Due 03/12/2023 at 11:59pm EDTDocument1 pageAnthony Vaccaro MATH 264 Winter 2023 Assignment Assignment 6 Due 03/12/2023 at 11:59pm EDTAnthony VaccaroNo ratings yet
- 8th Lecture Note - 1039837803 230515 094639Document10 pages8th Lecture Note - 1039837803 230515 094639Girie YumNo ratings yet
- Probabilistic Graphical Models CPSC 532c (Topics in AI) Stat 521a (Topics in Multivariate Analysis)Document35 pagesProbabilistic Graphical Models CPSC 532c (Topics in AI) Stat 521a (Topics in Multivariate Analysis)aofgubhNo ratings yet
- HW 4Document6 pagesHW 4juanagallardo01No ratings yet
- Week 9 - Classical Fluctuation Dissipation Theorem: I. Langevin EquationDocument4 pagesWeek 9 - Classical Fluctuation Dissipation Theorem: I. Langevin EquationAkshaya Kumar RathNo ratings yet
- CS229 Lecture on Supervised Learning and ClassificationDocument35 pagesCS229 Lecture on Supervised Learning and ClassificationAmr Abbas100% (1)
- Stability of Fractional Order SystemsDocument32 pagesStability of Fractional Order Systemscarlos9leoNo ratings yet
- Problem Set 8Document5 pagesProblem Set 8clouds lauNo ratings yet
- POPAdrian-Petru L2 PDFDocument8 pagesPOPAdrian-Petru L2 PDFTomescu MadalinNo ratings yet
- Stochastic Portfolio Theory - A Survey - SlidesDocument27 pagesStochastic Portfolio Theory - A Survey - SlidesTraderCat SolarisNo ratings yet
- Ode 45Document6 pagesOde 45Gustavo SalgeNo ratings yet
- UniversityDocument3 pagesUniversitySudo27No ratings yet
- MinimumjerkDocument11 pagesMinimumjerkSamir BachirNo ratings yet
- Probability and StatisticsDocument26 pagesProbability and StatisticsAshok Thiruvengadam100% (1)
- Continuous & Discrete SystemsDocument14 pagesContinuous & Discrete Systemsopenid_ZufDFRTuNo ratings yet
- CQF January 2016 M5S8 Workings AnnotatedDocument7 pagesCQF January 2016 M5S8 Workings AnnotatedClaptrapjackNo ratings yet
- Agricultural Land Use in KeralaDocument5 pagesAgricultural Land Use in KeralaavsanthoshNo ratings yet
- slides1Document73 pagesslides1emilyNo ratings yet
- Solutions To Selected Exercises From Chapter 9 Bain & Engelhardt - Second EditionDocument13 pagesSolutions To Selected Exercises From Chapter 9 Bain & Engelhardt - Second EditionMezika WahyuniNo ratings yet
- MA2002 Tutorial7Document3 pagesMA2002 Tutorial7yu hanyueNo ratings yet
- Note 4: EECS 189 Introduction To Machine Learning Fall 2020 1 MLE and MAP For Regression (Part I)Document6 pagesNote 4: EECS 189 Introduction To Machine Learning Fall 2020 1 MLE and MAP For Regression (Part I)Rohan DebNo ratings yet
- The Fourier Transform ExplainedDocument14 pagesThe Fourier Transform ExplainedHoney PhsNo ratings yet
- 220 Logistic RegressionDocument5 pages220 Logistic Regressionmihir thakkar100% (1)
- Machine Learning Foundations: Learning to Answer Yes/NoDocument37 pagesMachine Learning Foundations: Learning to Answer Yes/NoDonald BennettNo ratings yet
- Assignment 4Document1 pageAssignment 4Muhammad AftabNo ratings yet
- Signals & Systems 2018-19Document3 pagesSignals & Systems 2018-19YuvRaj SinghNo ratings yet
- NumericalIntegration PDFDocument17 pagesNumericalIntegration PDFAshok Kumar KNo ratings yet
- ErodicityDocument2 pagesErodicityAshish AwasthiNo ratings yet
- Fundamentals of Statistics (18.6501x)Document20 pagesFundamentals of Statistics (18.6501x)Sourabh SinghNo ratings yet
- Random Processes, Correlation, and Power Spectral DensityDocument32 pagesRandom Processes, Correlation, and Power Spectral Densitysha3107No ratings yet
- DB Quiz-2007Document4 pagesDB Quiz-2007harlequin007No ratings yet
- Vibration Analysis - Experimental Modal Analysis Guide-2Document84 pagesVibration Analysis - Experimental Modal Analysis Guide-2Yusuf Ihtiyaroğlu100% (1)
- PDF (8) Panel Q-A PDFDocument9 pagesPDF (8) Panel Q-A PDFFatemeh IglinskyNo ratings yet
- 3 - Trigonometric SubstitutionDocument4 pages3 - Trigonometric Substitutionfmmora88No ratings yet
- Feast2015 Kuznetsov PDFDocument27 pagesFeast2015 Kuznetsov PDFindoexchangeNo ratings yet
- Machine Learning Coursera Quiz 2Document6 pagesMachine Learning Coursera Quiz 2Noha El-sheweikh100% (1)
- Asymptotic VarianceDocument6 pagesAsymptotic VarianceSiyaBNo ratings yet
- 9b9756b6f73bfd0c558e4ea9a933650d_MIT8_324F10_Lecture11Document5 pages9b9756b6f73bfd0c558e4ea9a933650d_MIT8_324F10_Lecture11Ayham ziadNo ratings yet
- BVP: Finite Differences or Method of Lines: Lecture #36: TA-Led Final ReviewDocument6 pagesBVP: Finite Differences or Method of Lines: Lecture #36: TA-Led Final ReviewEhsanMojtahediNo ratings yet
- Advanced Statistical InferenceDocument7 pagesAdvanced Statistical InferencePere Barber LlorénsNo ratings yet
- 41 DeepLearningDocument4 pages41 DeepLearningCaballero Alférez Roy TorresNo ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- Adaboost With Totally Corrective Updates For Fast Face DetectionDocument6 pagesAdaboost With Totally Corrective Updates For Fast Face DetectionNguyen Quoc TrieuNo ratings yet
- Data Mining Lab QuestionsDocument47 pagesData Mining Lab QuestionsSneha Pinky100% (1)
- Fitness Action Recognition Based On MediapipeDocument8 pagesFitness Action Recognition Based On MediapipeBouhafs AbdelkaderNo ratings yet
- CAD Phase5 PDFDocument53 pagesCAD Phase5 PDFpvh15022003No ratings yet
- Comparative Analysis of Machine Learning Techniques For Indian Liver Disease PatientsDocument5 pagesComparative Analysis of Machine Learning Techniques For Indian Liver Disease PatientsM. Talha NadeemNo ratings yet
- The Opencv User Guide: Release 2.4.9.0Document23 pagesThe Opencv User Guide: Release 2.4.9.0osilatorNo ratings yet
- Ensemble Boosting and Bagging Based MachineLearning Models For Groundwater Potential PredictionDocument15 pagesEnsemble Boosting and Bagging Based MachineLearning Models For Groundwater Potential PredictionAmir MosaviNo ratings yet
- Catboost ET ComparaisonDocument20 pagesCatboost ET ComparaisonBENSALEM Mohamed AbderrahmaneNo ratings yet
- Experiment 1 Aim:: Introduction To ML Lab With Tools (Hands On WEKA On Data Set (Iris - Arff) ) - (A) Start WekaDocument55 pagesExperiment 1 Aim:: Introduction To ML Lab With Tools (Hands On WEKA On Data Set (Iris - Arff) ) - (A) Start WekaJayesh bansalNo ratings yet
- AdaBoost Classifier in Python (Article) - DataCampDocument9 pagesAdaBoost Classifier in Python (Article) - DataCampenghoss77100% (1)
- AdaBoost M1Document16 pagesAdaBoost M1Dmitriy BoikoNo ratings yet
- CHAPTER 4 DiabetesDocument6 pagesCHAPTER 4 DiabetesSRPC ECENo ratings yet
- Machine Learning Predicts Vancouver Crime RatesDocument7 pagesMachine Learning Predicts Vancouver Crime RatesMeghanath Reddy ChavvaNo ratings yet
- Embewc PPTDocument31 pagesEmbewc PPTAbhishek AryanNo ratings yet
- Numerical Computing With Python (En)Document676 pagesNumerical Computing With Python (En)tsalmy100% (1)
- Trees, Boosting, and Random ForestDocument14 pagesTrees, Boosting, and Random ForestKevin SongNo ratings yet
- Face Recognition SampleDocument9 pagesFace Recognition SamplealbinjamestpraNo ratings yet
- THE APPLIED DATA SCIENCE WORKSHOP Urinary Biomarkers Based Pancreatic Cancer Classification and Prediction (Vivian Siahaan Rismon Hasiholan Sianipar) (Z-Library)Document491 pagesTHE APPLIED DATA SCIENCE WORKSHOP Urinary Biomarkers Based Pancreatic Cancer Classification and Prediction (Vivian Siahaan Rismon Hasiholan Sianipar) (Z-Library)16061977No ratings yet
- Ramsri Face Detection and TrackingDocument32 pagesRamsri Face Detection and TrackingAkbarSabNo ratings yet
- ENVI Extensions in IDL: C.1 InstallationDocument17 pagesENVI Extensions in IDL: C.1 InstallationOsman EjameNo ratings yet
- Analysis of Wear Debris Through ClassificationDocument13 pagesAnalysis of Wear Debris Through ClassificationBHOOPALA KRISHNAN MOTHILALNo ratings yet
- High Protection Voice Identification Based Bank Locker Security System With Live Image AuthenticationDocument6 pagesHigh Protection Voice Identification Based Bank Locker Security System With Live Image AuthenticationSona SonuuNo ratings yet
- Machine Learning Fundamentals Chapter 9 Ensemble Learning Bagging BoostingDocument19 pagesMachine Learning Fundamentals Chapter 9 Ensemble Learning Bagging BoostingJuan ZarateNo ratings yet
- Machine Learning - Intro to ML LabDocument68 pagesMachine Learning - Intro to ML LabvishalNo ratings yet
- IE506 ChallengequestionDocument2 pagesIE506 ChallengequestionNitish GoelNo ratings yet
- Scene Text Detection Using Machine Learning ClassifiersDocument5 pagesScene Text Detection Using Machine Learning ClassifiersijsretNo ratings yet
- Gradient Boosting: Presentation Edited byDocument38 pagesGradient Boosting: Presentation Edited bySvastits100% (1)
- Face Identification Using Haar Cascade ClassifierDocument6 pagesFace Identification Using Haar Cascade ClassifierHamzaNo ratings yet
- Campus Placement Analyzer: Using Supervised Machine Learning AlgorithmsDocument5 pagesCampus Placement Analyzer: Using Supervised Machine Learning AlgorithmsATSNo ratings yet
- A Survey On Transfer Learning: Sinno Jialin Pan and Qiang Yang, Fellow, IEEEDocument15 pagesA Survey On Transfer Learning: Sinno Jialin Pan and Qiang Yang, Fellow, IEEEazertytyty000No ratings yet