You might also like
- 28 Star Deities, 28 Constellati - Robert Ri'Chard, JRDocument32 pages28 Star Deities, 28 Constellati - Robert Ri'Chard, JRJai Sri HariNo ratings yet
- Extraterrestrial Aliens and Reptilian Gods in The Quran 7Document3 pagesExtraterrestrial Aliens and Reptilian Gods in The Quran 7Truman DhanishNo ratings yet
- Zohar Scanning Chart 2013-2014Document4 pagesZohar Scanning Chart 2013-2014water_melonNo ratings yet
- Who Is Dajjal?Document10 pagesWho Is Dajjal?zynal20038222No ratings yet
- Arthur E Waite - The Book of Ceremonial MagickDocument266 pagesArthur E Waite - The Book of Ceremonial MagickfenrissulfirNo ratings yet
- A Prayer For Spiritual Elevation and Protection by Ibn ArabiDocument23 pagesA Prayer For Spiritual Elevation and Protection by Ibn ArabiAbdal Dahr0% (1)
- Florida General Lines Agent Exam Questions and Answers 2023Document44 pagesFlorida General Lines Agent Exam Questions and Answers 2023Debs MaxNo ratings yet
- Prayer - in - Islam - Anwarul - IslamDocument23 pagesPrayer - in - Islam - Anwarul - Islambangla018No ratings yet
- Pouvoir Et Impuissance PDFDocument31 pagesPouvoir Et Impuissance PDFLidiane Soares RodriguesNo ratings yet
- Tutorial 1Document6 pagesTutorial 1sreekanthaNo ratings yet
- Wealthy Historical Figures 2008: The ListDocument54 pagesWealthy Historical Figures 2008: The Listpradeepg987No ratings yet
- Paper PDFDocument12 pagesPaper PDFKashilal IndraNo ratings yet
- Dantinne, EmileDocument11 pagesDantinne, EmilehighrangeNo ratings yet
- Gayat Al HakimDocument94 pagesGayat Al HakimIchwan NudinNo ratings yet
- AlSÙrat Al Kawthar1Document13 pagesAlSÙrat Al Kawthar1sahebjuNo ratings yet
- Calvo - Mystical Numerology - Chess HistoryDocument10 pagesCalvo - Mystical Numerology - Chess HistoryDavid BergeNo ratings yet
- 2019 Forum v89-1Document28 pages2019 Forum v89-1ShaneNo ratings yet
- Maimonide’s Division of the 248 Positive MitzvotDocument16 pagesMaimonide’s Division of the 248 Positive MitzvotAlma SlatkovicNo ratings yet
- Log JiDocument4 pagesLog JinopayantisalmaNo ratings yet
- ModalDocument19 pagesModalojangurenNo ratings yet
- Infrastructure Fault - ApzDocument13 pagesInfrastructure Fault - Apzyacine bouazniNo ratings yet
- Pioneer Deh 340, Deh 34, Deh 3400Document37 pagesPioneer Deh 340, Deh 34, Deh 3400Dan GuertinNo ratings yet
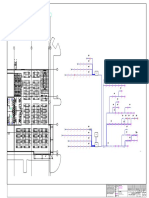
- FLSmidth Drawing Cable ScheduleDocument5 pagesFLSmidth Drawing Cable ScheduleRakesh Karan SinghNo ratings yet
- Circuit Identification Code Test (CIC Test) PresDocument15 pagesCircuit Identification Code Test (CIC Test) PresIslam Hasabo100% (1)
- U - DB - Common U - Psu: DB36 - Daughter Board Virtex4 DB36 Top LevelDocument26 pagesU - DB - Common U - Psu: DB36 - Daughter Board Virtex4 DB36 Top Leveljohn92691No ratings yet
- Materi Tema 4 Semester 1Document56 pagesMateri Tema 4 Semester 1ollindenyNo ratings yet
- Parts List-EOS 1DDocument38 pagesParts List-EOS 1Danlomol4671No ratings yet
- LogcatDocument16 pagesLogcatyongyut555919721No ratings yet
- Brocade FC SwitchDocument7 pagesBrocade FC SwitchMuthu KumarNo ratings yet
- PuttyDocument5 pagesPuttyvhan_meat2515No ratings yet
- logDocument50 pageslogmartinsodah76No ratings yet
- Philips 32pfl5605 LC9.3LDocument85 pagesPhilips 32pfl5605 LC9.3Ldivubi20040% (1)
- Philips 40pfl6606h 12 Chassis q552 2e La SM PDFDocument114 pagesPhilips 40pfl6606h 12 Chassis q552 2e La SM PDFTestrooteNo ratings yet
- Control Philosophy Empower Indus Palaza SampleDocument46 pagesControl Philosophy Empower Indus Palaza Samplesony thomasNo ratings yet
- CB 960 Offline Online RMADocument5 pagesCB 960 Offline Online RMAPayal PriyaNo ratings yet
- Log Cat 1671227386454Document6,399 pagesLog Cat 1671227386454fajarjr1204No ratings yet
- Service Manual: MODEL: MACRO830/1400/2400Document38 pagesService Manual: MODEL: MACRO830/1400/2400Osmar ContreirasNo ratings yet
- DCT700 ph0Document14 pagesDCT700 ph0waltech2005100% (1)
- Consola 5Document8 pagesConsola 5Ana ReyesNo ratings yet
- 9800t16 Labelling SambalpurDocument4 pages9800t16 Labelling SambalpurChinmaya malikNo ratings yet
- 2024-02-26 11-57-24Document14 pages2024-02-26 11-57-24edmundo13ysNo ratings yet
- 5 KVA UPS Docs (HI-REL) PDFDocument53 pages5 KVA UPS Docs (HI-REL) PDFMohan Kulkarni75% (4)
- Ellipse 1250 180 Static.f04Document31 pagesEllipse 1250 180 Static.f04GRNAYAKNo ratings yet
- 40PFL6606D 78Document179 pages40PFL6606D 78Tvsena Imagem E SomNo ratings yet
- Or Logo Here Your Name: V V V MW MW MW CoffeeDocument3 pagesOr Logo Here Your Name: V V V MW MW MW CoffeeRadu JuneNo ratings yet
- Expect Trum LerunoumDocument730 pagesExpect Trum Lerunoumcanvabulan09No ratings yet
- Report on node and interface alarmsDocument5 pagesReport on node and interface alarmsVinod saw serrh tree for QR is a PetwalNo ratings yet
- Operations ReportDocument18 pagesOperations ReportHumberto Cadori FilhoNo ratings yet
- Annexure 4-Set Files & PSLDocument252 pagesAnnexure 4-Set Files & PSLirfuNo ratings yet
- Data CostaDocument93 pagesData CostafabiesteNo ratings yet
- Log Cat 1707735259015Document513 pagesLog Cat 1707735259015ridholanang32No ratings yet
- PHILIPS Chassis QV14.1E LA PDFDocument301 pagesPHILIPS Chassis QV14.1E LA PDFboroda241082% (11)
- ASUS ZC554KL - A - RF Trouble Shooting Guide - 170524Document18 pagesASUS ZC554KL - A - RF Trouble Shooting Guide - 170524Vinicius TeixeiraNo ratings yet
- Product DFGDDocument137 pagesProduct DFGDTanuj GhimireNo ratings yet
- Print Out V2 S2Document23 pagesPrint Out V2 S2Sergio Andres Muñoz CorleoneNo ratings yet
- The Signature Display (12-19-2019 4 - 09 - 07 PM)Document31 pagesThe Signature Display (12-19-2019 4 - 09 - 07 PM)darwin paulo dela cruzNo ratings yet
- ABB - Control ACS100 CAB Datasheet PDFDocument22 pagesABB - Control ACS100 CAB Datasheet PDFmetanoia88No ratings yet
- Digital Signal Processing Using the ARM Cortex M4From EverandDigital Signal Processing Using the ARM Cortex M4Rating: 1 out of 5 stars1/5 (1)
- All-Digital Frequency Synthesizer in Deep-Submicron CMOSFrom EverandAll-Digital Frequency Synthesizer in Deep-Submicron CMOSNo ratings yet
- Radio Shack TRS-80 Expansion Interface: Operator's Manual Catalog Numbers: 26-1140, 26-1141, 26-1142From EverandRadio Shack TRS-80 Expansion Interface: Operator's Manual Catalog Numbers: 26-1140, 26-1141, 26-1142No ratings yet
- The Next Questions Will Depend On Your Answer(s) in Question Number 4: 6. The Next Questions Will Depend On Your Answer(s) in Question Number 4: 6Document1 pageThe Next Questions Will Depend On Your Answer(s) in Question Number 4: 6. The Next Questions Will Depend On Your Answer(s) in Question Number 4: 6cgranzore8833% (3)
- A Review Paper On Rice Quality Analysis Using Image Processing TechniqueDocument5 pagesA Review Paper On Rice Quality Analysis Using Image Processing TechniqueIJRASETPublicationsNo ratings yet
- 21eb7 0 PDFDocument1 page21eb7 0 PDFdediranduNo ratings yet
- Logging Levels in Log4j - Tutorialspoint ExamplesDocument3 pagesLogging Levels in Log4j - Tutorialspoint ExamplesJai PannuNo ratings yet
- I Am Sharing 'ASSIGNMENT MAT099 - E08G5 - WRTTEN REPORT' With YouDocument23 pagesI Am Sharing 'ASSIGNMENT MAT099 - E08G5 - WRTTEN REPORT' With YouaqilNo ratings yet
- Murder Conviction UpheldDocument9 pagesMurder Conviction UpheldBobNo ratings yet
- Adoption: Legal DefinitionDocument8 pagesAdoption: Legal Definitionsharon victoria mendezNo ratings yet
- Capstone Presentation 2020Document12 pagesCapstone Presentation 2020api-539629427No ratings yet
- Unit 5 - Lesson 1 - Understanding Hypothesis TestingDocument31 pagesUnit 5 - Lesson 1 - Understanding Hypothesis TestingJasper A. SANTIAGONo ratings yet
- Imeko WC 2012 TC21 O10Document5 pagesImeko WC 2012 TC21 O10mcastillogzNo ratings yet
- Probability Concepts and Random Variable - SMTA1402: Unit - IDocument105 pagesProbability Concepts and Random Variable - SMTA1402: Unit - IVigneshwar SNo ratings yet
- Flygt 4660 EnglishDocument2 pagesFlygt 4660 EnglishVictor Manuel Lachira YarlequeNo ratings yet
- Presentation - On SVAMITVADocument18 pagesPresentation - On SVAMITVAPraveen PrajapatiNo ratings yet
- 286129Document23 pages286129Cristian WalkerNo ratings yet
- YLE - Top Tips and Common MistakesDocument15 pagesYLE - Top Tips and Common Mistakeskuvan alievNo ratings yet
- Ps1 GeneralDocument2 pagesPs1 Generalkulin123456No ratings yet
- Banking and Fintech in 2022Document45 pagesBanking and Fintech in 2022Shahbaz talpurNo ratings yet
- Instruction Manual: Shimadzu Analytical BalanceDocument169 pagesInstruction Manual: Shimadzu Analytical BalanceChanthar SoeNo ratings yet
- Android Activity Lifecycle OverviewDocument8 pagesAndroid Activity Lifecycle OverviewMario FedericiNo ratings yet
- Learn From Customers to Improve Products and ServicesDocument8 pagesLearn From Customers to Improve Products and ServicesQuan Hoang AnhNo ratings yet
- New Technique for Producing 3D Fabrics Using Conventional LoomDocument1 pageNew Technique for Producing 3D Fabrics Using Conventional LoomSujit GulhaneNo ratings yet
- How To Make Lampblack - AllDocument6 pagesHow To Make Lampblack - AllclaudjiuNo ratings yet
- Dental Cements: Dr. Hamida KhatunDocument39 pagesDental Cements: Dr. Hamida Khatunsakib samiNo ratings yet
- GARAM ModelDocument40 pagesGARAM ModelprasunmathurNo ratings yet
- Sales Target Planning ToolkitDocument7 pagesSales Target Planning ToolkitCarmenLarisaNo ratings yet
- Muhammad Farrukh QAMAR - Assessment 2 Student Practical Demonstration of Tasks AURAMA006 V2Document19 pagesMuhammad Farrukh QAMAR - Assessment 2 Student Practical Demonstration of Tasks AURAMA006 V2Rana Muhammad Ashfaq Khan0% (1)
- Introduction To Engineering Economy: Title of The LessonDocument16 pagesIntroduction To Engineering Economy: Title of The LessonsdanharoldNo ratings yet
- Impact of Sugarcane Molasses in Concrete As Time Retarding and Water Reducing AdmixtureDocument131 pagesImpact of Sugarcane Molasses in Concrete As Time Retarding and Water Reducing AdmixtureMohamed MoralesNo ratings yet
- Balanced Scorecard ThesisDocument59 pagesBalanced Scorecard Thesisapi-3825626100% (5)
- AWS Architecture Icons Deck For Light BG 20190729 LegacyDocument111 pagesAWS Architecture Icons Deck For Light BG 20190729 LegacyHenson ChinNo ratings yet