You might also like
- Advanced C Concepts and Programming: First EditionFrom EverandAdvanced C Concepts and Programming: First EditionRating: 3 out of 5 stars3/5 (1)
- Data ClearningDocument7 pagesData Clearninglequangtrung010389No ratings yet
- Pandas: Reference SheetDocument9 pagesPandas: Reference SheetdeveshagNo ratings yet
- Commands SQL, Python (BASICS)Document7 pagesCommands SQL, Python (BASICS)Kuldeep GangwarNo ratings yet
- PandasDocument5 pagesPandasSmart CrazyNo ratings yet
- Python Cheat Sheet Code AcademyDocument1 pagePython Cheat Sheet Code AcademyJaroslav Kostelník100% (1)
- Pandas Cheat Sheet PDFDocument1 pagePandas Cheat Sheet PDFmoraleseconomia50% (2)
- Real EstateDocument10 pagesReal EstateMuskaanNo ratings yet
- Pandas CommandsDocument3 pagesPandas Commandsvijayagajula1359No ratings yet
- Data Science Cheat Sheet: KEY ImportsDocument1 pageData Science Cheat Sheet: KEY ImportsMihai Dragomir100% (1)
- Practicum Data Analysis Takeaways Course1 Theme6 UsDocument2 pagesPracticum Data Analysis Takeaways Course1 Theme6 UsThai ChiNo ratings yet
- Pandas Cheat SheetDocument6 pagesPandas Cheat Sheetshan halder100% (2)
- Literacy Rate Analysis Coding and OutputDocument22 pagesLiteracy Rate Analysis Coding and OutputSuchitaNo ratings yet
- Practicle6 (Code)Document4 pagesPracticle6 (Code)Pallavi GaikwadNo ratings yet
- Imp DetailsDocument6 pagesImp DetailsJyotirmay SahuNo ratings yet
- C121 Exp2Document23 pagesC121 Exp2Devanshu MaheshwariNo ratings yet
- Pandas - PySpark Equivalents-1Document3 pagesPandas - PySpark Equivalents-1RufaiNo ratings yet
- Data Exploration PreparationDocument12 pagesData Exploration Preparationhamidsithole65No ratings yet
- Python Cheat Sheet: Pandas - Numpy - Sklearn Matplotlib - Seaborn BS4 - Selenium - ScrapyDocument9 pagesPython Cheat Sheet: Pandas - Numpy - Sklearn Matplotlib - Seaborn BS4 - Selenium - Scrapyrameshb87100% (3)
- Machine Learning Notes: 2. All The Commands For EdaDocument5 pagesMachine Learning Notes: 2. All The Commands For Edanaveen katta100% (1)
- C121 Exp1Document32 pagesC121 Exp1Devanshu MaheshwariNo ratings yet
- EDA Cheat Sheet - Exploratory Data AnalysisDocument2 pagesEDA Cheat Sheet - Exploratory Data AnalysisVanshika RastogiNo ratings yet
- Cheat Sheet: The Pandas Dataframe Object: Preliminaries Get Your Data Into A DataframeDocument10 pagesCheat Sheet: The Pandas Dataframe Object: Preliminaries Get Your Data Into A DataframeRaju Rimal100% (1)
- Form1: "Ingrese Nombre"Document1 pageForm1: "Ingrese Nombre"alejandrolsm1No ratings yet
- FakeNewsDetection StudentDocument7 pagesFakeNewsDetection StudentnehailaNo ratings yet
- Mercedes-Benz Greener Manufacturing AiDocument16 pagesMercedes-Benz Greener Manufacturing AiPuji0% (1)
- Learn Pandas Dataframe Object Cheat Sheet Part-8Document8 pagesLearn Pandas Dataframe Object Cheat Sheet Part-8Satyabrat DasNo ratings yet
- Data Cleaning & PreparationDocument2 pagesData Cleaning & PreparationNisha R SNo ratings yet
- Pandas DataFrame NotesDocument6 pagesPandas DataFrame NotesNhan Nguyen100% (1)
- Data Analysis W PandasDocument4 pagesData Analysis W Pandasx7jn4sxdn9No ratings yet
- Descriptive Statistics With Pandas: Data Handling Using Pandas - IIDocument37 pagesDescriptive Statistics With Pandas: Data Handling Using Pandas - IIB. Jennifer100% (1)
- Python Pandas Demo PDFDocument23 pagesPython Pandas Demo PDFRakshit Kukreja100% (2)
- Pandas Usefull CodeDocument2 pagesPandas Usefull Codeأحمد موريسNo ratings yet
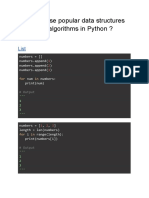
- How To Use Popular Data Structures and Algorithms in Python ?Document11 pagesHow To Use Popular Data Structures and Algorithms in Python ?Satish Singh100% (1)
- PYTHON PANDAS Cheat SheetDocument2 pagesPYTHON PANDAS Cheat SheetIndri Dayanah AyulaniNo ratings yet
- Pandas Library Problems For ParcticeDocument13 pagesPandas Library Problems For ParcticeMAXI 32No ratings yet
- Python Cheat Sheet For Data AnalysisDocument2 pagesPython Cheat Sheet For Data AnalysisAbdullah aminNo ratings yet
- DatavischeatsheetDocument2 pagesDatavischeatsheetrcg97.hdNo ratings yet
- AL NotesDocument61 pagesAL NotesShikha JayaswalNo ratings yet
- ML 1-10Document53 pagesML 1-1022128008No ratings yet
- Assignment 1 - LP1Document14 pagesAssignment 1 - LP1bbad070105No ratings yet
- Cognitive Class - Answers Data Analysis With PythonDocument6 pagesCognitive Class - Answers Data Analysis With PythonSloan Ian AriffNo ratings yet
- Rec 11Document49 pagesRec 11Tamer SultanyNo ratings yet
- PW2 DataCleaningDocument6 pagesPW2 DataCleaninghhaline9No ratings yet
- Document PyDocument8 pagesDocument PyUdaya sankari sankariNo ratings yet
- CSC KV CHN - Stack With WorksheetDocument10 pagesCSC KV CHN - Stack With WorksheetThenmozhi GovindarajNo ratings yet
- Multiple - Linear - Regression - AirBNB - Student - File0.2 - New (1) .Ipynb - ColaboratoryDocument8 pagesMultiple - Linear - Regression - AirBNB - Student - File0.2 - New (1) .Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Data Wrangling PDFDocument14 pagesData Wrangling PDFEdgar GuerreroNo ratings yet
- Important Pandas Operations 1697910759Document6 pagesImportant Pandas Operations 1697910759qhksfqnqsrNo ratings yet
- Python QuizDocument220 pagesPython QuizRanvitha GNo ratings yet
- Untitled2.ipynb - ColaboratoryDocument2 pagesUntitled2.ipynb - ColaboratoryrvvnbraoNo ratings yet
- Prac 303Document19 pagesPrac 303VIGHNESH RAJEEVANNo ratings yet
- String (Pandas) - Removing $ After Int Sales ( Revenue') Sales ( Revenue') .STR - Strip ( $') #Convert String To IntDocument12 pagesString (Pandas) - Removing $ After Int Sales ( Revenue') Sales ( Revenue') .STR - Strip ( $') #Convert String To IntMAHMUDA AKTER KEYANo ratings yet
- MAU Practica4Document16 pagesMAU Practica4Paul Pinto JNo ratings yet
- Pandas: ImportDocument13 pagesPandas: Importhello100% (1)
- HIV Regression Source CodeDocument26 pagesHIV Regression Source CodeVăn ThịnhNo ratings yet
- Mathematics: Quarter 1 - Module 7 Polynomial EquationDocument10 pagesMathematics: Quarter 1 - Module 7 Polynomial EquationLimar Anasco EscasoNo ratings yet
- S.No. Name of The Agency Contact Details: M/s M.P. PrintersDocument3 pagesS.No. Name of The Agency Contact Details: M/s M.P. PrintersVIKKAS AGARWALNo ratings yet
- Report ProjectDocument8 pagesReport ProjectNadeemNo ratings yet
- The Greatest Inventions in The Past 1000 YearsDocument2 pagesThe Greatest Inventions in The Past 1000 YearsRosario CabarrubiasNo ratings yet
- Information and Communication TechnologyDocument18 pagesInformation and Communication TechnologyAvantee SinghNo ratings yet
- مختبر ابلايد 1Document6 pagesمختبر ابلايد 1عبد الرحمن أبوخاطر, أبو رزقNo ratings yet
- Navfac Far East Waterfrnt Sec Sept 2019 ADocument37 pagesNavfac Far East Waterfrnt Sec Sept 2019 AMICHAEL JOHN TolonghariNo ratings yet
- Juan Dela Cruz: UP Mindanao Security Personnel ProfileDocument4 pagesJuan Dela Cruz: UP Mindanao Security Personnel ProfileinvictuslorenzoNo ratings yet
- Implementing Client Virtualization and Cloud ComputingDocument33 pagesImplementing Client Virtualization and Cloud ComputingEthan BooisNo ratings yet
- Leanna Balinado - Puzzle DesignDocument13 pagesLeanna Balinado - Puzzle Designapi-529497466No ratings yet
- Recurrent Neural Networks: Anahita Zarei, PH.DDocument37 pagesRecurrent Neural Networks: Anahita Zarei, PH.DNickNo ratings yet
- The Role of Computers in The Development of Odia LanguageDocument5 pagesThe Role of Computers in The Development of Odia LanguageIJRASETPublicationsNo ratings yet
- Valliammai Engineering College: SRM Nagar, Kattankulathur - 603 203Document9 pagesValliammai Engineering College: SRM Nagar, Kattankulathur - 603 203nandiniNo ratings yet
- Practical 5 - Text Processing PDFDocument2 pagesPractical 5 - Text Processing PDFDarian ChettyNo ratings yet
- Mini Project Doc 2Document25 pagesMini Project Doc 2Likhil GoudNo ratings yet
- Revised Inauguration FunctionDocument2 pagesRevised Inauguration FunctionUsha KrishnaNo ratings yet
- Repair The Great Conduit - Hob Walkthrough - NeoseekerDocument7 pagesRepair The Great Conduit - Hob Walkthrough - NeoseekerEnla Mira TetengoNo ratings yet
- Sil4s en Silence FullDocument23 pagesSil4s en Silence FullAshish PawarNo ratings yet
- Section 1 PDFDocument2 pagesSection 1 PDFRobert FergustoNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological UniversityVijay DharajiyaNo ratings yet
- Final Thesis On 3phase Fault AnalysisDocument73 pagesFinal Thesis On 3phase Fault Analysisabel tibebuNo ratings yet
- 6.4 WorksheetDocument6 pages6.4 Worksheetmohanad sayedNo ratings yet
- Rab Foodcourt Alt 1Document176 pagesRab Foodcourt Alt 1citaNo ratings yet
- B.tech (EEE 2011), Fresher ResumeDocument3 pagesB.tech (EEE 2011), Fresher ResumeMadhar Sha68% (28)
- Danfoss Modbus2Document4 pagesDanfoss Modbus2erick paredesNo ratings yet
- Disomat Opus: System ManualDocument36 pagesDisomat Opus: System Manualrajban cementNo ratings yet
- GPOA (PR Consultant)Document7 pagesGPOA (PR Consultant)Jeydrew TVNo ratings yet
- Manual Warp PyxisDocument13 pagesManual Warp PyxisPablo RuizNo ratings yet
- Electric Substation Practices PDFDocument11 pagesElectric Substation Practices PDFShelke PankajNo ratings yet
- Tge463 Pnqx778yaDocument96 pagesTge463 Pnqx778yaCharles LeeNo ratings yet
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Four Battlegrounds: Power in the Age of Artificial IntelligenceFrom EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceRating: 5 out of 5 stars5/5 (5)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)From EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Rating: 5 out of 5 stars5/5 (5)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionFrom EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionRating: 5 out of 5 stars5/5 (2)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryFrom EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNo ratings yet
- A Brief History of Artificial Intelligence: What It Is, Where We Are, and Where We Are GoingFrom EverandA Brief History of Artificial Intelligence: What It Is, Where We Are, and Where We Are GoingRating: 4.5 out of 5 stars4.5/5 (3)
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerFrom EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerRating: 4 out of 5 stars4/5 (4)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsFrom EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNo ratings yet
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesFrom EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesNo ratings yet
- System Design Interview: 300 Questions And Answers: Prepare And PassFrom EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNo ratings yet
- Architects of Intelligence: The truth about AI from the people building itFrom EverandArchitects of Intelligence: The truth about AI from the people building itRating: 4.5 out of 5 stars4.5/5 (21)