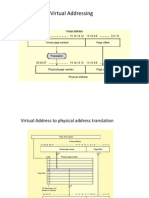
You might also like
- Memory Chapter4Document3 pagesMemory Chapter4zhuoyan xuNo ratings yet
- MEMORY SYSTEM OVERVIEWDocument68 pagesMEMORY SYSTEM OVERVIEWshiva100% (1)
- Summary of Computer MemoryDocument2 pagesSummary of Computer MemoryDrake William ParkerNo ratings yet
- Unit 6 Memory OrganizationDocument24 pagesUnit 6 Memory OrganizationAnurag GoelNo ratings yet
- Chapter 5-The Memory SystemDocument84 pagesChapter 5-The Memory SystemupparasureshNo ratings yet
- 3 s2.0 B0080431526004137 MainDocument12 pages3 s2.0 B0080431526004137 MainSanjay G RNo ratings yet
- Sram and Dram L4: Dram: Memory SubsystemDocument17 pagesSram and Dram L4: Dram: Memory SubsystemNeel RavalNo ratings yet
- Basic DRAM Operation and EvolutionDocument7 pagesBasic DRAM Operation and EvolutionKelvinNo ratings yet
- Design and Implementation of DDR SDRAM Controller Using VerilogDocument5 pagesDesign and Implementation of DDR SDRAM Controller Using VerilogIjsrnet EditorialNo ratings yet
- (New Paper On Sram) v39-15Document5 pages(New Paper On Sram) v39-15Pratap SaurabhNo ratings yet
- DRAM and MOS DRAM CellsDocument13 pagesDRAM and MOS DRAM CellsSiddharth PanditNo ratings yet
- Cache Perform AnseDocument6 pagesCache Perform AnseDado Fabrička GreškaNo ratings yet
- Design and Analysis of 4Kb Sram Array Cell For The Development of Sram ChipDocument8 pagesDesign and Analysis of 4Kb Sram Array Cell For The Development of Sram ChipRohit KumarNo ratings yet
- 3.1 Static Random Access Memory (SRAM)Document6 pages3.1 Static Random Access Memory (SRAM)VigneshInfotechNo ratings yet
- Cache PPTDocument20 pagesCache PPTshahida18No ratings yet
- Module 5 VLSI Design NotesDocument23 pagesModule 5 VLSI Design NotesUmme HanieNo ratings yet
- 1.1 Why There Is A Problem?Document18 pages1.1 Why There Is A Problem?Ragini VyasNo ratings yet
- Expt 8Document3 pagesExpt 8yuga.m.padhyeNo ratings yet
- CAO Assignment - Explanation of SRAM and DRAMDocument33 pagesCAO Assignment - Explanation of SRAM and DRAMJaskarman SinghNo ratings yet
- Memory Hierarchy Levels: Block (Aka Line) : Unit of Copying If Accessed Data Is Present in Upper LevelDocument16 pagesMemory Hierarchy Levels: Block (Aka Line) : Unit of Copying If Accessed Data Is Present in Upper LevelalexNo ratings yet
- BY: For:: Ahmad Khairi HalisDocument19 pagesBY: For:: Ahmad Khairi HalisKhairi B HalisNo ratings yet
- Synchronous Dynamic Random-Access MemoryDocument21 pagesSynchronous Dynamic Random-Access MemorychahoubNo ratings yet
- Computer Assignment 1Document6 pagesComputer Assignment 1Muhammad Hassnain AhmadNo ratings yet
- Dram KTMTDocument24 pagesDram KTMTNguyễn Khắc ThanhNo ratings yet
- Array SubsystemDocument29 pagesArray SubsystemMukesh MakwanaNo ratings yet
- E2805 B 43Document4 pagesE2805 B 43Verma JagdeepNo ratings yet
- Refreshing capacitors in DRAM memory cellsDocument8 pagesRefreshing capacitors in DRAM memory cellsTuan Anh NguyenNo ratings yet
- ASIC-System On Chip-VLSI Design - SRAM Cell Design PDFDocument8 pagesASIC-System On Chip-VLSI Design - SRAM Cell Design PDFGowtham SpNo ratings yet
- Computer OrganizationDocument32 pagesComputer Organizationy22cd125No ratings yet
- SRAM Circuit Design and Operation: Prepared By: Mr. B. H. NagparaDocument49 pagesSRAM Circuit Design and Operation: Prepared By: Mr. B. H. NagparaBharatNo ratings yet
- How RAM Works 28 by NafeesDocument10 pagesHow RAM Works 28 by NafeesnafeesNo ratings yet
- Types of RAM - DRAM vs SRAMDocument6 pagesTypes of RAM - DRAM vs SRAM93headbangerNo ratings yet
- Chapter 4 Memory ElementDocument87 pagesChapter 4 Memory ElementWann FarieraNo ratings yet
- How RAM WorksDocument9 pagesHow RAM WorksPablo Miguel FelsteadNo ratings yet
- Unit 3Document24 pagesUnit 3Sunil KumarNo ratings yet
- Sram Low Power DecoderDocument7 pagesSram Low Power DecoderKedhar MallaNo ratings yet
- The Memory System PDFDocument38 pagesThe Memory System PDFMeenu RadhakrishnanNo ratings yet
- Rambus Memory SystemDocument3 pagesRambus Memory Systemapi-3850195No ratings yet
- Understanding the Basics of DDR4 SDRAMDocument12 pagesUnderstanding the Basics of DDR4 SDRAMAnh Viet NguyenNo ratings yet
- A Novel Three Transistor Sram Cell Design and AnalysisDocument9 pagesA Novel Three Transistor Sram Cell Design and AnalysisVijay UrkudeNo ratings yet
- Application Note: Introduction To Synchronous DRAMDocument15 pagesApplication Note: Introduction To Synchronous DRAMnilesh.vlsiNo ratings yet
- Design Simulation and Analysis of 5T-Sram Cell Using Different FoundriesDocument6 pagesDesign Simulation and Analysis of 5T-Sram Cell Using Different FoundriesPreeti SinghNo ratings yet
- Computer Hardware Image GalleryDocument7 pagesComputer Hardware Image Gallerymathur1995No ratings yet
- Dynamic Random-Access Memory PDFDocument17 pagesDynamic Random-Access Memory PDFBintang Kejora100% (1)
- COA Module4Document35 pagesCOA Module4puse1223No ratings yet
- Manage Enhancing Energy G.sakanaDocument10 pagesManage Enhancing Energy G.sakanaBESTJournalsNo ratings yet
- CAO AssignmentDocument44 pagesCAO AssignmentAbhishek Dixit40% (5)
- Lec 29 PDFDocument9 pagesLec 29 PDFPrashant SinghNo ratings yet
- SRAM and DRAMDocument2 pagesSRAM and DRAMBiju AngaleesNo ratings yet
- VAMSI Kumar SRAMfinalDocument28 pagesVAMSI Kumar SRAMfinalraghuippiliNo ratings yet
- Semiconductor Memories: VLSI Design (18EC72)Document11 pagesSemiconductor Memories: VLSI Design (18EC72)PraveenNo ratings yet
- 6TSRAM Cell ReportDocument15 pages6TSRAM Cell ReportpalakNo ratings yet
- 8T Paper WTCM FinalDocument11 pages8T Paper WTCM Finaldeberjeet ushamNo ratings yet
- Efficient STT-RAM Last-Level-Cache Architecture To Replace DRAM CacheDocument10 pagesEfficient STT-RAM Last-Level-Cache Architecture To Replace DRAM CacheKARAN KARHALENo ratings yet
- Bipolar SramDocument33 pagesBipolar SramRavinder VijayranNo ratings yet
- High Speed Memory Design Techniques An4010 12Document6 pagesHigh Speed Memory Design Techniques An4010 12Luis Daniel BinsakNo ratings yet
- IISc eDRAM Ravi 2014 PDFDocument75 pagesIISc eDRAM Ravi 2014 PDFVenkateswararao MusalaNo ratings yet
- (P) Delay Analysis and Design Exploration For 3D SRAMDocument4 pages(P) Delay Analysis and Design Exploration For 3D SRAMRein ZhangNo ratings yet
- High-Performance D/A-Converters: Application to Digital TransceiversFrom EverandHigh-Performance D/A-Converters: Application to Digital TransceiversNo ratings yet
- A 256 KB 65 NM 8T Subthreshold SRAM Employing Sense-Amplifier RedundancyDocument9 pagesA 256 KB 65 NM 8T Subthreshold SRAM Employing Sense-Amplifier RedundancyVishva BNo ratings yet
- Review For Final Examination: ECE 4420 - Spring 2004Document3 pagesReview For Final Examination: ECE 4420 - Spring 2004Pay RentNo ratings yet
- I. 8-Bit Microprocessors Architecture, Instruction Set and Their ProgrammingDocument4 pagesI. 8-Bit Microprocessors Architecture, Instruction Set and Their ProgrammingSaorabh KumarNo ratings yet
- TTLDocument5 pagesTTLChaitanya Varma D100% (1)
- Mini PC Overview TableDocument8 pagesMini PC Overview TableRamiNo ratings yet
- Computer Architecture: BranchingDocument37 pagesComputer Architecture: Branchinginfamous0218No ratings yet
- Altium持续助力Tasking Tricore AURIX技术的嵌入式系统开发解决方案Document31 pagesAltium持续助力Tasking Tricore AURIX技术的嵌入式系统开发解决方案MohamedHassanNo ratings yet
- MP & MC Chap1Document33 pagesMP & MC Chap1Chandler BingNo ratings yet
- R20 MPMC Unit IiiDocument25 pagesR20 MPMC Unit IiiMaddineni TejaNo ratings yet
- General Purpose Programmable Peripheral DevicesDocument33 pagesGeneral Purpose Programmable Peripheral DevicesSudarshanBhardwajNo ratings yet
- Integrated CircuitDocument21 pagesIntegrated CircuitKennedy OliveiraNo ratings yet
- Pipe LiningDocument29 pagesPipe LiningAnkitShingalaNo ratings yet
- A 45 NM Stacked CMOS Image Sensor Process TechnoloDocument13 pagesA 45 NM Stacked CMOS Image Sensor Process TechnolowalkrogNo ratings yet
- Module 5 - Pentium Processors - FinalDocument43 pagesModule 5 - Pentium Processors - FinalKEVINNo ratings yet
- Tutorial Session On MicrocontrollerDocument17 pagesTutorial Session On MicrocontrollerZohaibNo ratings yet
- Advanced Computer Architecture Performance AnalysisDocument9 pagesAdvanced Computer Architecture Performance AnalysisSherril VincentNo ratings yet
- Chapter - 2 - Jump, Loop and Call InstructionsDocument27 pagesChapter - 2 - Jump, Loop and Call InstructionsJoe HxNo ratings yet
- Notes NewDocument14 pagesNotes NewPriya SirsatNo ratings yet
- EE6008 MBSDDocument34 pagesEE6008 MBSDHans John D'cruzNo ratings yet
- Basic Structure and Functional Units of ComputersDocument46 pagesBasic Structure and Functional Units of ComputersTameem AhmedNo ratings yet
- Addressing ModeDocument3 pagesAddressing ModeAnjanaNo ratings yet
- DP Sound IDT 15000 DriversDocument515 pagesDP Sound IDT 15000 DriversMohammed Tahver Farooqi QuadriNo ratings yet
- 8255 Ppi ExamplesDocument10 pages8255 Ppi Examplesvenky258100% (1)
- Faculty of EngineeringDocument2 pagesFaculty of EngineeringMohamed AlfarashNo ratings yet
- 8086 Microprocesser InstructionsDocument22 pages8086 Microprocesser InstructionsSaddam HussainNo ratings yet
- Intel Case AnalysisDocument3 pagesIntel Case AnalysisRhea RejithNo ratings yet
- Q.paper MPMC 2022-23 L6 L32Document155 pagesQ.paper MPMC 2022-23 L6 L32Soumya Ranjan PandaNo ratings yet
- CSS 548 Joshua LoDocument13 pagesCSS 548 Joshua LoUtsav SinghalNo ratings yet
- Module IIIDocument64 pagesModule IIISorab KhoslaNo ratings yet
- HC11 OpcodesDocument1 pageHC11 OpcodesmembernameNo ratings yet