You might also like
- PowerFactory Applications for Power System AnalysisFrom EverandPowerFactory Applications for Power System AnalysisFrancisco M. Gonzalez-LongattNo ratings yet
- 1008 2297 PDFDocument39 pages1008 2297 PDFhafid jouiniNo ratings yet
- Dimensioning of NGN Main Components With Improved and Guaranteed Quality of ServiceDocument10 pagesDimensioning of NGN Main Components With Improved and Guaranteed Quality of ServiceNjiva DavidNo ratings yet
- Supervised Machine Learning Techniques in Cognitive Radio Networks During Cooperative Spectrum HandoversDocument12 pagesSupervised Machine Learning Techniques in Cognitive Radio Networks During Cooperative Spectrum Handovers游小德No ratings yet
- A New Diffusion Variable Spatial Regularized QRRLS AlgorithmDocument5 pagesA New Diffusion Variable Spatial Regularized QRRLS AlgorithmAkilesh MDNo ratings yet
- On The Performance of Switching Methods in Space Division Multiplexing Based Optical NetworksDocument7 pagesOn The Performance of Switching Methods in Space Division Multiplexing Based Optical NetworksCSIT iaesprimeNo ratings yet
- Lifetime Maximization For Amplify-and-Forward Cooperative NetworksDocument6 pagesLifetime Maximization For Amplify-and-Forward Cooperative NetworksGagandeep KaurNo ratings yet
- Identifying Quality of Experience (Qoe) in 3G/4G Radio Networks Based On Quality of Service (Qos) MetricsDocument9 pagesIdentifying Quality of Experience (Qoe) in 3G/4G Radio Networks Based On Quality of Service (Qos) Metricsleele wolfNo ratings yet
- SDN 2014Document9 pagesSDN 2014AGUNG TRI LAKSONONo ratings yet
- Collaborative Sphere Decoder For A MIMO Communication SystemDocument7 pagesCollaborative Sphere Decoder For A MIMO Communication SystemTiến Anh VũNo ratings yet
- Comparison Between GPON, XGPON, NGPON2 and UDWDM PONDocument11 pagesComparison Between GPON, XGPON, NGPON2 and UDWDM PONmartius89No ratings yet
- Subchannel and Power Allocation For OFDMA-based Mobile Cognitive Radio NetworksDocument6 pagesSubchannel and Power Allocation For OFDMA-based Mobile Cognitive Radio NetworksAnonymous uspYoqENo ratings yet
- 40 An Improved Adaptive Beam Forming Algorithm For 5G Interference-Coexistence CommunicationDocument5 pages40 An Improved Adaptive Beam Forming Algorithm For 5G Interference-Coexistence Communicationsaipuneeth thejaNo ratings yet
- Multi-Agent Reinforcement Learning For SpectrumDocument5 pagesMulti-Agent Reinforcement Learning For SpectrumeverlovingmansiNo ratings yet
- DRL Assisted Dynamic Reconfiguration of Multicast Session in Elastic Optical NetworksDocument4 pagesDRL Assisted Dynamic Reconfiguration of Multicast Session in Elastic Optical NetworksADJE JEAN MARCNo ratings yet
- Physical Layer Deep Learning of Encodings For The MIMO Fading ChannelDocument5 pagesPhysical Layer Deep Learning of Encodings For The MIMO Fading Channeljun zhaoNo ratings yet
- Welding ManualDocument9 pagesWelding ManualsivaNo ratings yet
- Weighted Subspace Fitting For Two-Dimension DOA Estimation in Massive MIMO SystemsDocument8 pagesWeighted Subspace Fitting For Two-Dimension DOA Estimation in Massive MIMO SystemsJavier MelendrezNo ratings yet
- Icns - 2011 - 3!10!10136 Caculation Probility Packet LossDocument5 pagesIcns - 2011 - 3!10!10136 Caculation Probility Packet LossshanmalayoteNo ratings yet
- Ijcns20110200008 58644332Document6 pagesIjcns20110200008 58644332Simranjit SinghNo ratings yet
- An LSTM Framework For Modeling NetworkDocument6 pagesAn LSTM Framework For Modeling NetworkSuvarna PatilNo ratings yet
- Geomulticast: Architectures and Protocols For Mobile Ad Hoc Wireless NetworksDocument14 pagesGeomulticast: Architectures and Protocols For Mobile Ad Hoc Wireless NetworksDharanya PandiyanNo ratings yet
- 3068 Structure Aware Transformer PoDocument19 pages3068 Structure Aware Transformer PoAdeeba AliNo ratings yet
- An Approach To Analysis of Heterogeneous Networks' EfficiencyDocument5 pagesAn Approach To Analysis of Heterogeneous Networks' EfficiencyJasmin MusovicNo ratings yet
- Ordinal Optimisation Approach For Locating and Sizing of Distributed GenerationDocument11 pagesOrdinal Optimisation Approach For Locating and Sizing of Distributed GenerationAhmed WestministerNo ratings yet
- Spatial Stochastic Models and Metrics For The Structure of Base Stations in Cellular NetworksDocument13 pagesSpatial Stochastic Models and Metrics For The Structure of Base Stations in Cellular NetworksEstefenn Ollan EstebanNo ratings yet
- Fmadm System For Manet EnvironmentDocument13 pagesFmadm System For Manet EnvironmentijansjournalNo ratings yet
- Simplified Diffusion Schrödinger BridgeDocument28 pagesSimplified Diffusion Schrödinger BridgelarrylynnmailNo ratings yet
- Vehicle Delay-Tolerant Network Routing Algorithm Based On Multi-Period Bayesian NetworkDocument8 pagesVehicle Delay-Tolerant Network Routing Algorithm Based On Multi-Period Bayesian NetworkTelockNo ratings yet
- On Simultaneous Wireless Information and Power Transfer For Receive Spatial ModulationDocument8 pagesOn Simultaneous Wireless Information and Power Transfer For Receive Spatial ModulationgaraceNo ratings yet
- A Hybrid Time Divisioning Scheme For Power Allocation in DMT-based DSL SystemsDocument3 pagesA Hybrid Time Divisioning Scheme For Power Allocation in DMT-based DSL SystemsHarishchandra DubeyNo ratings yet
- Differential Evolution (De) Algorithm To Optimize Berkeley - Mac Protocol For Wireless Sensor Network (WSN)Document6 pagesDifferential Evolution (De) Algorithm To Optimize Berkeley - Mac Protocol For Wireless Sensor Network (WSN)wissemNo ratings yet
- Differential Evolution (De) Algorithm To Optimize Berkeley - Mac Protocol For Wireless Sensor Network (WSN)Document6 pagesDifferential Evolution (De) Algorithm To Optimize Berkeley - Mac Protocol For Wireless Sensor Network (WSN)wissemNo ratings yet
- System Model FormulationDocument10 pagesSystem Model FormulationlucyNo ratings yet
- Ijcnc 050313Document13 pagesIjcnc 050313AIRCC - IJCNCNo ratings yet
- SpectralTemporalOCDMACodefor2dGPON JEASDocument14 pagesSpectralTemporalOCDMACodefor2dGPON JEASDayanna Karoline Manosalvas AyalaNo ratings yet
- An Investigative Model For Wimax Networks With Multiple Traffic SummaryDocument14 pagesAn Investigative Model For Wimax Networks With Multiple Traffic SummarySalman ZahidNo ratings yet
- Artes: α (s, t) = st eDocument14 pagesArtes: α (s, t) = st eWilliam Ramos PaucarNo ratings yet
- Planning Aspects of WCDMA Mobile Radio Network DeploymentDocument8 pagesPlanning Aspects of WCDMA Mobile Radio Network DeploymentW.D.P.C PereraNo ratings yet
- Deep Reinforcement Learning Based Computation Offloading and Resource Allocation For MECDocument6 pagesDeep Reinforcement Learning Based Computation Offloading and Resource Allocation For MECNguyen Khac ChienNo ratings yet
- Research Article: Impact of Dynamic Path Loss Models in An Urban Obstacle Aware Ad Hoc Network EnvironmentDocument9 pagesResearch Article: Impact of Dynamic Path Loss Models in An Urban Obstacle Aware Ad Hoc Network EnvironmentkashifNo ratings yet
- (TC) (Jin21) (C1) Efficient - PHY - Layer - Abstraction - For - Fast - Simulations - in - Complex - System - EnvironmentsDocument12 pages(TC) (Jin21) (C1) Efficient - PHY - Layer - Abstraction - For - Fast - Simulations - in - Complex - System - EnvironmentsAlberto GuzmanNo ratings yet
- A Novel Technique For Multi User Multiple Access Spatial Modulation Using Adaptive Coding and ModulationDocument9 pagesA Novel Technique For Multi User Multiple Access Spatial Modulation Using Adaptive Coding and ModulationEditor IJTSRDNo ratings yet
- Evolutionary Game Theory-Based QoS Routing Algorithm For Wireless Mesh Networks (WMNS)Document4 pagesEvolutionary Game Theory-Based QoS Routing Algorithm For Wireless Mesh Networks (WMNS)Paranthaman GNo ratings yet
- 3 Delay-Optimal Traffic Engineering Through Multi-Agent Reinforcement LearningDocument8 pages3 Delay-Optimal Traffic Engineering Through Multi-Agent Reinforcement LearningBlanca HillNo ratings yet
- Spectral and Network Deployment Efficiency Analysis in A K-Tier NetworkDocument5 pagesSpectral and Network Deployment Efficiency Analysis in A K-Tier NetworkJasmin MusovicNo ratings yet
- Performance Analysis of Decode-and-Forward Cooperative Diversity Using Differential EGC Over Nakagami-M Fading ChannelsDocument6 pagesPerformance Analysis of Decode-and-Forward Cooperative Diversity Using Differential EGC Over Nakagami-M Fading ChannelsballmerNo ratings yet
- Cooperative FSO Systems Performance Analysis and Optimal Power AllocationDocument8 pagesCooperative FSO Systems Performance Analysis and Optimal Power AllocationAiman ThoriqNo ratings yet
- 01 - Seonghoon JinDocument9 pages01 - Seonghoon JinAbhishek ThakurNo ratings yet
- Throughput Optimization inDocument14 pagesThroughput Optimization inSHIVANISANDYNo ratings yet
- QoT Estimation ForUnestablishedLightpathsUsingML Tornatore OFC 17'Document3 pagesQoT Estimation ForUnestablishedLightpathsUsingML Tornatore OFC 17'Ruben Rumipamba ZambranoNo ratings yet
- Merayo 2016Document12 pagesMerayo 2016Mario Quinto JuñoNo ratings yet
- Capacity and Delay Analysis of Next-Generation Passive Optical Networks (Ng-Pons) - Extended VersionDocument45 pagesCapacity and Delay Analysis of Next-Generation Passive Optical Networks (Ng-Pons) - Extended VersionHakim ZentaniNo ratings yet
- Machine Learning Approach For Computing Optical Properties of A Photonic Crystal FiberDocument12 pagesMachine Learning Approach For Computing Optical Properties of A Photonic Crystal FiberfaisalbanNo ratings yet
- Short Term Load Forecasting Using Gaussian Process ModelsDocument12 pagesShort Term Load Forecasting Using Gaussian Process ModelsDedin DiyantoNo ratings yet
- Electrical Engineering and Computer Science DepartmentDocument27 pagesElectrical Engineering and Computer Science Departmenteecs.northwestern.eduNo ratings yet
- Zhang 2023 DistributedDocument5 pagesZhang 2023 DistributedCédric RichardNo ratings yet
- Nuo Huang Improved Synchronization Scheme For TheDocument6 pagesNuo Huang Improved Synchronization Scheme For Thewildbeast007755No ratings yet
- Rayleigh Fading Channel Via Deep Learning DoneDocument12 pagesRayleigh Fading Channel Via Deep Learning DonenubnajninNo ratings yet
- Computers and Mathematics With ApplicationsDocument10 pagesComputers and Mathematics With Applicationsalireza khoshnoodNo ratings yet
- Bioresource Technology: Oscar Pardo-Planas, Hasan K. Atiyeh, John R. Phillips, Clint P. Aichele, Sayeed MohammadDocument8 pagesBioresource Technology: Oscar Pardo-Planas, Hasan K. Atiyeh, John R. Phillips, Clint P. Aichele, Sayeed Mohammadmohsen ranjbarNo ratings yet
- Shell & Tube Heat Exchangers: First Name LAST NAME - Speaker's Job TitleDocument71 pagesShell & Tube Heat Exchangers: First Name LAST NAME - Speaker's Job TitledivakarNo ratings yet
- 100 Notes 2 XPDocument53 pages100 Notes 2 XPJIGSNo ratings yet
- AARTI STEEL Six Month TrainingDocument21 pagesAARTI STEEL Six Month TrainingNeelabh GothwalNo ratings yet
- BS 7941-1-2006Document20 pagesBS 7941-1-2006Willy AryansahNo ratings yet
- Practica 3Document4 pagesPractica 3Fernxndo BxsxntesNo ratings yet
- Opener Gurus Exam, Juy 2021 - Form 3Document14 pagesOpener Gurus Exam, Juy 2021 - Form 3munimercy12No ratings yet
- 19-104 ResearchPaperDocument6 pages19-104 ResearchPaperGimhani KavishikaNo ratings yet
- Class Notes On Gravitation (Physics 152) : Galileo Analyzes A Cannonball TrajectoryDocument4 pagesClass Notes On Gravitation (Physics 152) : Galileo Analyzes A Cannonball TrajectorythestudierNo ratings yet
- Chapter 8 - SynchronousDocument12 pagesChapter 8 - SynchronousLin ChongNo ratings yet
- Lab 8 - Sampling Techniques 1Document43 pagesLab 8 - Sampling Techniques 1rushikumarNo ratings yet
- Manuale PJ6KPS-CA Rev 1.4 EngDocument89 pagesManuale PJ6KPS-CA Rev 1.4 EngTerver Fred KumadenNo ratings yet
- 8085 Microprocessor Programs: Microprocessor & Microcontroller Lab ManualDocument16 pages8085 Microprocessor Programs: Microprocessor & Microcontroller Lab ManualLIFE of PSNo ratings yet
- Deep Learning (R20A6610)Document46 pagesDeep Learning (R20A6610)barakNo ratings yet
- Door SheetDocument9 pagesDoor SheetAnilkumarNo ratings yet
- 3 - Intermetallic Compounds of Ni and Ga As Catalysts For The Synthesis of MethanolDocument12 pages3 - Intermetallic Compounds of Ni and Ga As Catalysts For The Synthesis of Methanoltunganh1110No ratings yet
- Elimination of LowerDocument8 pagesElimination of LowervalentinmullerNo ratings yet
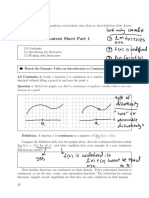
- 3 Module 2 Content Sheet Part 1: Math 180 Worksheets W3Document8 pages3 Module 2 Content Sheet Part 1: Math 180 Worksheets W3Deep PrajapatiNo ratings yet
- SM2059 (Apr-67)Document310 pagesSM2059 (Apr-67)EdU RECTIFICANo ratings yet
- Indian Abacus Starters Tutor Training Manual - 1st Level - FreeDocument10 pagesIndian Abacus Starters Tutor Training Manual - 1st Level - FreeIndian Abacus83% (36)
- BMT Lab Manual - NewDocument109 pagesBMT Lab Manual - NewAravind B Patil100% (1)
- Harmonic EspritDocument9 pagesHarmonic EspritNizar TayemNo ratings yet
- jPOS EEDocument67 pagesjPOS EEanand tmNo ratings yet
- Turbine Control SystemDocument8 pagesTurbine Control SystemZakariya50% (2)
- Coding For Kids How To Programming Code Games For Kids Supe...Document25 pagesCoding For Kids How To Programming Code Games For Kids Supe...Wez My Meds?No ratings yet
- Haqaik Ul Wasaiq - 1of2 - MasoomeenDocument444 pagesHaqaik Ul Wasaiq - 1of2 - MasoomeennasimNo ratings yet
- XT1C 160 TMD 25-450 4p F F: General InformationDocument3 pagesXT1C 160 TMD 25-450 4p F F: General InformationHenrics MayoresNo ratings yet
- 3d Printing CEDocument11 pages3d Printing CEShivam SamaiyaNo ratings yet
- Calculating Index Values and PerformanceDocument5 pagesCalculating Index Values and Performancemuneebmateen01No ratings yet
- DO RequestDocument3 pagesDO RequestAhmed IsmailNo ratings yet
- Scaling Up: How a Few Companies Make It...and Why the Rest Don't, Rockefeller Habits 2.0From EverandScaling Up: How a Few Companies Make It...and Why the Rest Don't, Rockefeller Habits 2.0Rating: 5 out of 5 stars5/5 (1)
- Powerful Phrases for Dealing with Difficult People: Over 325 Ready-to-Use Words and Phrases for Working with Challenging PersonalitiesFrom EverandPowerful Phrases for Dealing with Difficult People: Over 325 Ready-to-Use Words and Phrases for Working with Challenging PersonalitiesRating: 4 out of 5 stars4/5 (14)
- The 5 Languages of Appreciation in the Workplace: Empowering Organizations by Encouraging PeopleFrom EverandThe 5 Languages of Appreciation in the Workplace: Empowering Organizations by Encouraging PeopleRating: 4.5 out of 5 stars4.5/5 (46)
- The Five Dysfunctions of a Team SummaryFrom EverandThe Five Dysfunctions of a Team SummaryRating: 4.5 out of 5 stars4.5/5 (58)
- The Power of People Skills: How to Eliminate 90% of Your HR Problems and Dramatically Increase Team and Company Morale and PerformanceFrom EverandThe Power of People Skills: How to Eliminate 90% of Your HR Problems and Dramatically Increase Team and Company Morale and PerformanceRating: 5 out of 5 stars5/5 (22)
- The Way of the Shepherd: Seven Secrets to Managing Productive PeopleFrom EverandThe Way of the Shepherd: Seven Secrets to Managing Productive PeopleRating: 5 out of 5 stars5/5 (112)
- 12 Habits Of Valuable Employees: Your Roadmap to an Amazing CareerFrom Everand12 Habits Of Valuable Employees: Your Roadmap to an Amazing CareerNo ratings yet
- Hire With Your Head: Using Performance-Based Hiring to Build Outstanding Diverse TeamsFrom EverandHire With Your Head: Using Performance-Based Hiring to Build Outstanding Diverse TeamsRating: 4.5 out of 5 stars4.5/5 (5)
- The Fearless Organization: Creating Psychological Safety in the Workplace for Learning, Innovation, and GrowthFrom EverandThe Fearless Organization: Creating Psychological Safety in the Workplace for Learning, Innovation, and GrowthRating: 4.5 out of 5 stars4.5/5 (101)
- Getting Along: How to Work with Anyone (Even Difficult People)From EverandGetting Along: How to Work with Anyone (Even Difficult People)Rating: 4.5 out of 5 stars4.5/5 (18)
- Organizational Behaviour: People, Process, Work and Human Resource ManagementFrom EverandOrganizational Behaviour: People, Process, Work and Human Resource ManagementNo ratings yet
- The Fearless Organization: Creating Psychological Safety in the Workplace for Learning, Innovation, and GrowthFrom EverandThe Fearless Organization: Creating Psychological Safety in the Workplace for Learning, Innovation, and GrowthRating: 4 out of 5 stars4/5 (12)
- Inspiring Accountability in the Workplace: Unlocking the brain's secrets to employee engagement, accountability, and resultsFrom EverandInspiring Accountability in the Workplace: Unlocking the brain's secrets to employee engagement, accountability, and resultsRating: 4.5 out of 5 stars4.5/5 (2)
- Profit Works: Unravel the Complexity of Incentive Plans to Increase Employee Productivity, Cultivate an Engaged Workforce, and Maximize Your Company's PotentialFrom EverandProfit Works: Unravel the Complexity of Incentive Plans to Increase Employee Productivity, Cultivate an Engaged Workforce, and Maximize Your Company's PotentialRating: 5 out of 5 stars5/5 (1)
- Coaching and Mentoring: Practical Techniques for Developing Learning and PerformanceFrom EverandCoaching and Mentoring: Practical Techniques for Developing Learning and PerformanceRating: 3.5 out of 5 stars3.5/5 (4)
- Irresistible: The Seven Secrets of the World's Most Enduring, Employee-Focused OrganizationsFrom EverandIrresistible: The Seven Secrets of the World's Most Enduring, Employee-Focused OrganizationsRating: 5 out of 5 stars5/5 (3)
- Summary: Who Moved My Cheese?: An A-Mazing Way to Deal with Change in Your Work and in Your Life by Spencer Johnson M.D. and Kenneth Blanchard: Key Takeaways, Summary & AnalysisFrom EverandSummary: Who Moved My Cheese?: An A-Mazing Way to Deal with Change in Your Work and in Your Life by Spencer Johnson M.D. and Kenneth Blanchard: Key Takeaways, Summary & AnalysisRating: 3.5 out of 5 stars3.5/5 (3)
- Goal Setting: How to Create an Action Plan and Achieve Your GoalsFrom EverandGoal Setting: How to Create an Action Plan and Achieve Your GoalsRating: 4.5 out of 5 stars4.5/5 (9)
- Mastering the Instructional Design Process: A Systematic ApproachFrom EverandMastering the Instructional Design Process: A Systematic ApproachNo ratings yet
- Strength-Based Leadership Coaching in Organizations: An Evidence-Based Guide to Positive Leadership DevelopmentFrom EverandStrength-Based Leadership Coaching in Organizations: An Evidence-Based Guide to Positive Leadership DevelopmentRating: 4 out of 5 stars4/5 (1)
- Developing Coaching Skills: A Concise IntroductionFrom EverandDeveloping Coaching Skills: A Concise IntroductionRating: 4.5 out of 5 stars4.5/5 (5)
- The Manager's Path: A Guide for Tech Leaders Navigating Growth and ChangeFrom EverandThe Manager's Path: A Guide for Tech Leaders Navigating Growth and ChangeRating: 4.5 out of 5 stars4.5/5 (99)
- Management For Beginners: The Ultimate Guide for First Time ManagersFrom EverandManagement For Beginners: The Ultimate Guide for First Time ManagersNo ratings yet
- 50 Top Tools for Coaching, 3rd Edition: A Complete Toolkit for Developing and Empowering PeopleFrom Everand50 Top Tools for Coaching, 3rd Edition: A Complete Toolkit for Developing and Empowering PeopleRating: 4.5 out of 5 stars4.5/5 (4)
- The Art of Active Listening: How People at Work Feel Heard, Valued, and UnderstoodFrom EverandThe Art of Active Listening: How People at Work Feel Heard, Valued, and UnderstoodRating: 4.5 out of 5 stars4.5/5 (4)