You might also like
- How Not to Make a Decision: Gymnastics for the Brain: Gymnastics for the BrainFrom EverandHow Not to Make a Decision: Gymnastics for the Brain: Gymnastics for the BrainNo ratings yet
- Decision Making in Dental Implantology: Atlas of Surgical and Restorative ApproachesFrom EverandDecision Making in Dental Implantology: Atlas of Surgical and Restorative ApproachesNo ratings yet
- Report Math FADocument5 pagesReport Math FAkamosiik26No ratings yet
- Biostatistic Love FinalssssDocument12 pagesBiostatistic Love FinalssssLove Mie MoreNo ratings yet
- Biostatistic LoveDocument9 pagesBiostatistic LoveLove Mie MoreNo ratings yet
- Stats Abilong Assignment No. 3 PDFDocument10 pagesStats Abilong Assignment No. 3 PDFElmarNo ratings yet
- Sampling Lesson 10: Sampling Without Replacement: The Binomial and Hypergeometric Probability ModelsDocument10 pagesSampling Lesson 10: Sampling Without Replacement: The Binomial and Hypergeometric Probability ModelsIsabella MondragonNo ratings yet
- The Randomized Block DesignDocument32 pagesThe Randomized Block DesignSaras AgrawalNo ratings yet
- Anscombes Quartet eDocument3 pagesAnscombes Quartet eSweta Jain SewakNo ratings yet
- RP ch06Document121 pagesRP ch06alallaqNo ratings yet
- Group 1 Addmaths SbaDocument25 pagesGroup 1 Addmaths SbaAidan FernandesNo ratings yet
- D10 - Meta AnalysisDocument7 pagesD10 - Meta AnalysisxbsdNo ratings yet
- Ex Day1Document9 pagesEx Day1retokoller44No ratings yet
- S&RM Session Plan CasesDocument21 pagesS&RM Session Plan CasesHimanshu Rajesh PatnekarNo ratings yet
- Lecture1 Jan27 2023Document44 pagesLecture1 Jan27 2023Rabbur AhmedNo ratings yet
- Lab 1 BioDocument14 pagesLab 1 BioRyan HughesNo ratings yet
- Argument For The Dynamic Warm Up - Kansas JayhawksDocument4 pagesArgument For The Dynamic Warm Up - Kansas JayhawksPatrick AdewaleNo ratings yet
- Latihan Ujian Korelasi SPSSDocument2 pagesLatihan Ujian Korelasi SPSSFadzli AhmadNo ratings yet
- BS ExamDocument7 pagesBS ExamJakeNo ratings yet
- Business Data + Graphs and TablesDocument19 pagesBusiness Data + Graphs and TablesLUCRECIA TULIAONo ratings yet
- Correlated Samples T-Test ExerciseDocument2 pagesCorrelated Samples T-Test ExerciseNazia SyedNo ratings yet
- Bio101d IaDocument7 pagesBio101d IaTvisha PatelNo ratings yet
- Stat-304 Lecture 2Document14 pagesStat-304 Lecture 2ahmed.iqbal2907No ratings yet
- Project 3 - Bouncing Energy - Lab ReportDocument5 pagesProject 3 - Bouncing Energy - Lab ReportKOBE2401No ratings yet
- Suggested Solutions: Exercise 1: Introductory Statistics, Period 1Document2 pagesSuggested Solutions: Exercise 1: Introductory Statistics, Period 1Alejandro RamirezNo ratings yet
- Department of Statistics: COURSE STATS 330/762Document3 pagesDepartment of Statistics: COURSE STATS 330/762PETERNo ratings yet
- Center of Pressure PracDocument5 pagesCenter of Pressure Pracfire benderNo ratings yet
- Department of Statistics: COURSE STATS 330/762Document8 pagesDepartment of Statistics: COURSE STATS 330/762PETERNo ratings yet
- AP Biology Lab Ten: Physiology of The Circulatory SystemDocument8 pagesAP Biology Lab Ten: Physiology of The Circulatory SystemCoolAsianDude75% (4)
- Effect of Isometric Strength Training On Mechanical, Electrical, and Metabolic Aspects of Muscle FunctionDocument11 pagesEffect of Isometric Strength Training On Mechanical, Electrical, and Metabolic Aspects of Muscle FunctionLuuca DeusNo ratings yet
- Heart Attack Risk Assessment ModelDocument13 pagesHeart Attack Risk Assessment ModelmbowejNo ratings yet
- Statistics Formative Task 5.Document3 pagesStatistics Formative Task 5.Arcebuche Figueroa FarahNo ratings yet
- MulticollinearityDocument28 pagesMulticollinearityMike Vergara PatronaNo ratings yet
- Pulse Rate LabDocument2 pagesPulse Rate LabGemini JuneboiNo ratings yet
- Rancang Bangun Sistem Pengolahan Citra Digital Untuk Menentukan Berat Badan IdealDocument8 pagesRancang Bangun Sistem Pengolahan Citra Digital Untuk Menentukan Berat Badan IdealKelvin TryantoNo ratings yet
- Introduction To Machine LearningDocument48 pagesIntroduction To Machine LearningKylleNo ratings yet
- Statistics & Probability Theory: Course Instructor: DR. MASOOD ANWARDocument67 pagesStatistics & Probability Theory: Course Instructor: DR. MASOOD ANWARManal RizwanNo ratings yet
- Pulse Rate - RevDocument10 pagesPulse Rate - RevNikkiJenalynReyNo ratings yet
- Lesson 1Document3 pagesLesson 1Carlo YambaoNo ratings yet
- Kumpulan Latihan Praktik Microsoft Excel: A B C A+B-C 3A-2B 5C - (A:B) Akar (A+C) A +CDocument5 pagesKumpulan Latihan Praktik Microsoft Excel: A B C A+B-C 3A-2B 5C - (A:B) Akar (A+C) A +CThia SallsabillaNo ratings yet
- Combined Science Coursework 2021Document22 pagesCombined Science Coursework 2021Archita RoutNo ratings yet
- Name: Abdul Rehman Grade: 8: 125 X 130 130 X 135 135 X 140 140 X 145 145 X 150 150 X 155 155 X 160 160 X 165 165 X 170Document5 pagesName: Abdul Rehman Grade: 8: 125 X 130 130 X 135 135 X 140 140 X 145 145 X 150 150 X 155 155 X 160 160 X 165 165 X 170shaikh shahrukhNo ratings yet
- Enriquez Physio Ex2-Act 6Document11 pagesEnriquez Physio Ex2-Act 6Vergel Jigs EnriquezNo ratings yet
- Bio IA TemplateDocument4 pagesBio IA Templateeidmclsk100% (2)
- Bio2 Module 2 - Non-Parametric MethodsDocument14 pagesBio2 Module 2 - Non-Parametric Methodstamirat hailuNo ratings yet
- Muller IllusionDocument6 pagesMuller IllusionAkanksha SridharNo ratings yet
- Preap Homeostasis Lab Student PageDocument5 pagesPreap Homeostasis Lab Student Pageapi-2521467860% (1)
- P7 - Lab 5 Muscular Strength and Endurance: ObjectiveDocument10 pagesP7 - Lab 5 Muscular Strength and Endurance: ObjectiveSarn Yung-HonNo ratings yet
- Biology ReportDocument8 pagesBiology Reportfarah fouadNo ratings yet
- Pex 02 06Document11 pagesPex 02 06metamongNo ratings yet
- 3 - Frequency DistributionDocument28 pages3 - Frequency DistributionShammah Sagunday100% (1)
- Assignment Ch#6-1-1Document6 pagesAssignment Ch#6-1-1Riaz Ahmad100% (1)
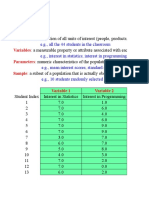
- Population: Variables: Parameters: SampleDocument15 pagesPopulation: Variables: Parameters: SampleAbdu AbdoulayeNo ratings yet
- Topic 12: Split-Plot Design and Its Relatives: PLS205 Winter 2015Document3 pagesTopic 12: Split-Plot Design and Its Relatives: PLS205 Winter 2015Anonymous gUySMcpSqNo ratings yet
- Learn StatisticsDocument8 pagesLearn StatisticsAditya MessiNo ratings yet
- Statistics: Leonida M. Falculan, RPM, LPT, MaedDocument40 pagesStatistics: Leonida M. Falculan, RPM, LPT, MaedKen SorianoNo ratings yet
- Training Course 4 Statistics and ProbabilityDocument33 pagesTraining Course 4 Statistics and ProbabilityRichardoBrandonNo ratings yet
- Measurement of Length - Screw Gauge (Physics) Question BankFrom EverandMeasurement of Length - Screw Gauge (Physics) Question BankNo ratings yet
- GRADE 6 BASELINE TEST QP-2024-25Document4 pagesGRADE 6 BASELINE TEST QP-2024-25shamshadNo ratings yet
- CBSE Class 6 Science - Separation of SubstancesDocument5 pagesCBSE Class 6 Science - Separation of SubstancesshamshadNo ratings yet
- Remedial Worksheet Nervouys SystemDocument1 pageRemedial Worksheet Nervouys SystemshamshadNo ratings yet
- Revision Test I Grade 8 PhysicsDocument4 pagesRevision Test I Grade 8 PhysicsshamshadNo ratings yet
- Grade 8 Class TestDocument2 pagesGrade 8 Class TestshamshadNo ratings yet
- Tax Invoice: CPP281123014909230 Credit CardDocument1 pageTax Invoice: CPP281123014909230 Credit CardshamshadNo ratings yet
- Cells Introduction TNDocument14 pagesCells Introduction TNshamshadNo ratings yet
- Revision Test Grade 6Document4 pagesRevision Test Grade 6shamshadNo ratings yet
- Post Assessmnt ElectricittyDocument3 pagesPost Assessmnt ElectricittyshamshadNo ratings yet
- CT2 QP - Grade 6 Answer KeyDocument3 pagesCT2 QP - Grade 6 Answer KeyshamshadNo ratings yet
- Grade 5 - Rev Worksheet 1 (23-24) Answer KeyDocument5 pagesGrade 5 - Rev Worksheet 1 (23-24) Answer KeyshamshadNo ratings yet
- Matter Grade 6Document22 pagesMatter Grade 6shamshadNo ratings yet
- Abu Dhabi Indian SchoolDocument1 pageAbu Dhabi Indian SchoolshamshadNo ratings yet
- Food and Health-Week 2Document8 pagesFood and Health-Week 2shamshadNo ratings yet
- Force and Laws of Motion - NotesDocument7 pagesForce and Laws of Motion - Notesshamshad100% (1)
- Notes - Fun With Magnets-2023-24Document5 pagesNotes - Fun With Magnets-2023-24shamshadNo ratings yet
- Air and Water Class 5 0 2020 25 07 083521Document1 pageAir and Water Class 5 0 2020 25 07 083521shamshad100% (1)
- New Text DocumentDocument3 pagesNew Text DocumentshamshadNo ratings yet
- The Moon Class 5 Worksheets 0 2021 18 05 060016Document1 pageThe Moon Class 5 Worksheets 0 2021 18 05 060016shamshad0% (1)
- 7AM Student ListDocument1 page7AM Student ListshamshadNo ratings yet
- Atomic Structure Key WordsDocument2 pagesAtomic Structure Key WordsshamshadNo ratings yet
- Assignment Grade 7Document1 pageAssignment Grade 7shamshadNo ratings yet
- Worksheet 3 Microorganisms Frien Dand FoeDocument3 pagesWorksheet 3 Microorganisms Frien Dand FoeshamshadNo ratings yet
- REMEDIAL - Grade 5Document2 pagesREMEDIAL - Grade 5shamshad0% (1)
- Worksheet Answers Grade 7Document2 pagesWorksheet Answers Grade 7shamshadNo ratings yet
- WORKSHEET 2 Living World Grade 11Document1 pageWORKSHEET 2 Living World Grade 11shamshadNo ratings yet
- CBSE Class 7 Science - Transportation in Plants and AnimalsDocument2 pagesCBSE Class 7 Science - Transportation in Plants and Animalsshamshad100% (1)
- Worksheet For DA - 2Document4 pagesWorksheet For DA - 2shamshadNo ratings yet
- CBSE Class 7 Science - Transport and ExcretionDocument1 pageCBSE Class 7 Science - Transport and ExcretionshamshadNo ratings yet
- WORKSHEET Forest Our LifelineDocument5 pagesWORKSHEET Forest Our LifelineshamshadNo ratings yet
- NBP Planner - NEET-2022Document21 pagesNBP Planner - NEET-2022Mruthyun120% (1)
- Biology Pollination Lab Spring 09 - FinalDocument9 pagesBiology Pollination Lab Spring 09 - FinalRafal WhittingtonNo ratings yet
- CBSE Class 10 Science Solution PDF 2019 Set 6Document9 pagesCBSE Class 10 Science Solution PDF 2019 Set 6Khushboo SinghNo ratings yet
- Yam Bean. Pachyrhizus DC.: January 1996Document144 pagesYam Bean. Pachyrhizus DC.: January 1996haveanicedayNo ratings yet
- Block PrintingDocument28 pagesBlock PrintingRhea SharmaNo ratings yet
- Plant SpellsDocument43 pagesPlant Spellsrawr100% (1)
- Bee Pollination Services and The Enhancement of Fruit Yield Associated WithDocument9 pagesBee Pollination Services and The Enhancement of Fruit Yield Associated WithRissa WidayantiNo ratings yet
- Problem of UnfruitfulnessDocument6 pagesProblem of UnfruitfulnessRockyNo ratings yet
- Reproductive Ecology of Cleome Gynandra and Cleome Viscosa (Capparaceae)Document15 pagesReproductive Ecology of Cleome Gynandra and Cleome Viscosa (Capparaceae)noahNo ratings yet
- Plants Question NATDocument2 pagesPlants Question NATRachelle Melegrito Bernabe100% (1)
- Whole Plant Reconstructions in Fossil Angiosperm 2008Document11 pagesWhole Plant Reconstructions in Fossil Angiosperm 2008Evaldo PapeNo ratings yet
- Study Material 12TH Biology 2023-24Document90 pagesStudy Material 12TH Biology 2023-24Ayush Sharma100% (1)
- LESSON PLAN Grade 1Document10 pagesLESSON PLAN Grade 1Nyca PacisNo ratings yet
- Fig Growing in The SouthDocument28 pagesFig Growing in The SouthHector Quezada100% (1)
- Semestral Assessment (1) : Raffles Girls' Primary SchoolDocument43 pagesSemestral Assessment (1) : Raffles Girls' Primary SchoolJun Yi HoNo ratings yet
- CLASS - 7th SCIENCE, CHAPTER 8 (REPRODUCTION IN PLANTSDocument1 pageCLASS - 7th SCIENCE, CHAPTER 8 (REPRODUCTION IN PLANTSexperimentoboyNo ratings yet
- Plant ReproductionDocument5 pagesPlant ReproductionFaizan ElahiNo ratings yet
- Resource Assessment of Seabuckthorn - Hippophae LDocument27 pagesResource Assessment of Seabuckthorn - Hippophae Lkhilendragurung100% (1)
- 17 Test BankDocument672 pages17 Test BankHazim Amini0% (2)
- Plant Spacing TomatoDocument6 pagesPlant Spacing TomatoHailayNo ratings yet
- Review of The Related Literature: Definition and Nature of Some Home ChemicalsDocument11 pagesReview of The Related Literature: Definition and Nature of Some Home ChemicalsErlyn Grace RedobladoNo ratings yet
- Marginpar CatalogueDocument20 pagesMarginpar CatalogueEmmanuel SabuniNo ratings yet
- A Mathematical Model of The Interactions Between Pollinators and PDFDocument85 pagesA Mathematical Model of The Interactions Between Pollinators and PDFAgni Guntur SugitoNo ratings yet
- Icones Plantarum V5-6Document382 pagesIcones Plantarum V5-6Daniel ReyesNo ratings yet
- En - 0122 8706 Ccta 20 01 00149Document10 pagesEn - 0122 8706 Ccta 20 01 00149mrcariNo ratings yet
- V. Raghavan (Auth.) - Developmental Biology of Flowering Plants-Springer-Verlag New York (2000)Document363 pagesV. Raghavan (Auth.) - Developmental Biology of Flowering Plants-Springer-Verlag New York (2000)tandifNo ratings yet
- Bee Keeping-KVK MorenaDocument6 pagesBee Keeping-KVK MorenaAsh1Scribd100% (1)
- How Plants SurviveDocument34 pagesHow Plants SurviveAlyzza Joy Albay100% (2)
- Detailed Lesson PlanDocument6 pagesDetailed Lesson PlanDencie CabarlesNo ratings yet
- Convey 1996Document8 pagesConvey 1996Moises Tinte100% (1)