You might also like
- Common ICD 10 CodesDocument2 pagesCommon ICD 10 CodesAhmadNo ratings yet
- By: Joe Jupin By: Joe Jupin Supervised By: Dr. Longin Jan Latecki Supervised By: Dr. Longin Jan LateckiDocument20 pagesBy: Joe Jupin By: Joe Jupin Supervised By: Dr. Longin Jan Latecki Supervised By: Dr. Longin Jan LateckichindhuzNo ratings yet
- Gynecology and Obstetrics MCQ ReviewDocument101 pagesGynecology and Obstetrics MCQ ReviewOwaisNo ratings yet
- Zapper Tabela Dr. Rife e Dra. HuldaDocument38 pagesZapper Tabela Dr. Rife e Dra. HuldaLuiz Felipe CarvalhoNo ratings yet
- Steganography: By: Joe Jupin Supervised By: Dr. Longin Jan LateckiDocument20 pagesSteganography: By: Joe Jupin Supervised By: Dr. Longin Jan LateckiRoopSainiNo ratings yet
- Variance Explained in Dimensions and AttributesDocument12 pagesVariance Explained in Dimensions and AttributesAnurag KhandelwalNo ratings yet
- Steganography: By: Joe Jupin Supervised By: Dr. Longin Jan LateckiDocument20 pagesSteganography: By: Joe Jupin Supervised By: Dr. Longin Jan LateckiShivam TrivediNo ratings yet
- MBTI Personality DetectionDocument3 pagesMBTI Personality DetectionAbu Shahid (B20CS003)No ratings yet
- CatBoost - An In-Depth Guide PythonDocument33 pagesCatBoost - An In-Depth Guide PythonRadha KilariNo ratings yet
- Multi Character RecognitionDocument19 pagesMulti Character RecognitionAnkit KumarNo ratings yet
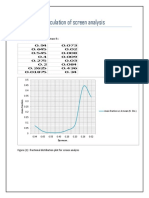
- Calculation of Screen Analysis: D Mean Average Particle Vs Mass Fr.Document3 pagesCalculation of Screen Analysis: D Mean Average Particle Vs Mass Fr.Anmar AhmedNo ratings yet
- Data MiningDocument27 pagesData MiningMohseen SayyedNo ratings yet
- McCombe Etal Supplementary Materials 2021Document6 pagesMcCombe Etal Supplementary Materials 2021dobbyNo ratings yet
- Predictive Modelling - Linear Discriminant Analysis - Mentor Version - Jupyter NotebookDocument25 pagesPredictive Modelling - Linear Discriminant Analysis - Mentor Version - Jupyter Notebooksambitmishra_gec100% (1)
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Hruby Ondrej Hw3Document18 pagesHruby Ondrej Hw3ondrah2No ratings yet
- Template FINDINGSDocument10 pagesTemplate FINDINGSKafeTEEN SabahNo ratings yet
- Ainul Mardiah 180342618063 Off G Biologi 2018 Jawaban No.3Document4 pagesAinul Mardiah 180342618063 Off G Biologi 2018 Jawaban No.3Rey JannahNo ratings yet
- Normal Distribution: Dr. Tarek TawfikDocument22 pagesNormal Distribution: Dr. Tarek TawfikSanjeev NawaniNo ratings yet
- Diffraction GratingDocument8 pagesDiffraction GratingClintDoesMusicNo ratings yet
- KNN, SVC, Decision Tree models for body weight classificationDocument3 pagesKNN, SVC, Decision Tree models for body weight classificationSpam KingNo ratings yet
- Lab 3. Linear Regression 230223Document7 pagesLab 3. Linear Regression 230223ruso100% (1)
- Id Sepallengthcm Sepalwidthcm Petallengthcm Petalwidthcm Species 0 1 2 3 4Document4 pagesId Sepallengthcm Sepalwidthcm Petallengthcm Petalwidthcm Species 0 1 2 3 4Sebastian CallesNo ratings yet
- Emran Assign2 1136Document10 pagesEmran Assign2 1136emarat hosenNo ratings yet
- Tambo de Mora - ReportDocument12 pagesTambo de Mora - ReportAlberto Chávez AngelesNo ratings yet
- Telecom Customer Churn Prediction Assessment-Pratik ZankeDocument19 pagesTelecom Customer Churn Prediction Assessment-Pratik Zankepratik zankeNo ratings yet
- Selection of A Probabilty Distribution Function For Construction Cost EstimationDocument4 pagesSelection of A Probabilty Distribution Function For Construction Cost EstimationEduardo MenaNo ratings yet
- Pengolahan Data Sektor Barang Baku - LOGDocument9 pagesPengolahan Data Sektor Barang Baku - LOGNikolai WenNo ratings yet
- 7.01 Feature SelectionDocument3 pages7.01 Feature Selectionjayant khanvilkarNo ratings yet
- Genetic Programming Evolves Data Matching ConfigurationsDocument62 pagesGenetic Programming Evolves Data Matching ConfigurationsElwin HuamanNo ratings yet
- DL7.2Document11 pagesDL7.2Sandesh PokhrelNo ratings yet
- IRE Deliverable 2Document4 pagesIRE Deliverable 2Vaibhav NautiyalNo ratings yet
- Genetic Programming Evolves Data Matching Configurations in Under 60 GenerationsDocument20 pagesGenetic Programming Evolves Data Matching Configurations in Under 60 GenerationsElwin HuamanNo ratings yet
- Informe Tarea 3Document10 pagesInforme Tarea 3Miguel angel BarreroNo ratings yet
- Understanding Raster Data Models and Storage FormatsDocument29 pagesUnderstanding Raster Data Models and Storage FormatslahiyaNo ratings yet
- Practical - 5 - 52Document4 pagesPractical - 5 - 52Royal EmpireNo ratings yet
- Rajat Kapoor Assignment No. 5 8102Document7 pagesRajat Kapoor Assignment No. 5 8102kapoorrajat859500No ratings yet
- Sample OD1 OD2 OD3 Average CorrectedDocument2 pagesSample OD1 OD2 OD3 Average CorrectedLadyamayuNo ratings yet
- Overdispersion in R and JAGS: Recognizing and fixing overdispersion in statistical modelsDocument16 pagesOverdispersion in R and JAGS: Recognizing and fixing overdispersion in statistical modelsAna ScaletNo ratings yet
- Diabetic Prediction Using LogicalRegressionDocument9 pagesDiabetic Prediction Using LogicalRegressionYagnesh VyasNo ratings yet
- 1811067Document8 pages1811067Naser MahmudNo ratings yet
- BI and Data Mining Key ConceptsDocument44 pagesBI and Data Mining Key ConceptsAjit chowdaryNo ratings yet
- Model Num - Diagnostic Functdent Sex Baseage Nursbeds / Noscale Dist Negbin Offset Log - Period - Yr Type3Document2 pagesModel Num - Diagnostic Functdent Sex Baseage Nursbeds / Noscale Dist Negbin Offset Log - Period - Yr Type3Dani ShaNo ratings yet
- Regression AnalysisDocument3 pagesRegression AnalysisJeffery GulNo ratings yet
- Multiple Transformer Mining For Vizwiz Image CaptionDocument2 pagesMultiple Transformer Mining For Vizwiz Image Captionsonali kambleNo ratings yet
- Comparison of Two Independent Samples: Method: Welch Two Sample T-Test Factor: Gen (Femenin vs. Masculin)Document1 pageComparison of Two Independent Samples: Method: Welch Two Sample T-Test Factor: Gen (Femenin vs. Masculin)Iuliana MovileanuNo ratings yet
- Dimensionality Reduction of MNIST ImagesDocument5 pagesDimensionality Reduction of MNIST ImageschelseaNo ratings yet
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocument18 pages26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNo ratings yet
- Histopathologic Cancer Detection Using CNNDocument5 pagesHistopathologic Cancer Detection Using CNNAbu Shahid (B20CS003)No ratings yet
- 2.1 Speech Quality AssessmentDocument15 pages2.1 Speech Quality Assessmentdi diNo ratings yet
- Linear Ordinal Perceptions AnalysisDocument3 pagesLinear Ordinal Perceptions AnalysisFRANNY FRANGKY WAGANIANo ratings yet
- RAJIV RANJAN - 19!02!2023 - Predictive Modelling Project Report - FinalDocument34 pagesRAJIV RANJAN - 19!02!2023 - Predictive Modelling Project Report - FinalRajiv Ranjan100% (1)
- Logistic Regression Models for Diabetes ClassificationDocument10 pagesLogistic Regression Models for Diabetes ClassificationC TNo ratings yet
- Logistic Regression Models for Diabetes ClassificationDocument10 pagesLogistic Regression Models for Diabetes ClassificationC TNo ratings yet
- Script Tabela3 MultimorbidadeDocument16 pagesScript Tabela3 MultimorbidadeCristina CamargoNo ratings yet
- PM10 Air Quality Data AnalysisDocument9 pagesPM10 Air Quality Data AnalysisSanju VisuNo ratings yet
- Modeling and Simulation (Tcs-506) Assignment 2Document2 pagesModeling and Simulation (Tcs-506) Assignment 2Anurag BairagiNo ratings yet
- CHEGR 2650: Computer Methods in Chemical EngineeringDocument27 pagesCHEGR 2650: Computer Methods in Chemical EngineeringNebojsa MihajlovicNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document9 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1Rajat SolankiNo ratings yet
- RIVERA ECE11 Laboratory Exercise 3Document3 pagesRIVERA ECE11 Laboratory Exercise 3Ehron RiveraNo ratings yet
- Correlation and regression analysis of variablesDocument2 pagesCorrelation and regression analysis of variablesHassanRazaNo ratings yet
- Utilization of Super Pixel Based Microarray Image SegmentationDocument5 pagesUtilization of Super Pixel Based Microarray Image SegmentationEditor IJTSRDNo ratings yet
- Neural Network PC Tools: A Practical GuideFrom EverandNeural Network PC Tools: A Practical GuideRating: 1 out of 5 stars1/5 (2)
- VascularDocument40 pagesVascularOmar MohammedNo ratings yet
- Adult PSG Guidelines 2014Document49 pagesAdult PSG Guidelines 2014mohanNo ratings yet
- ACCRE Test Parameters 2022Document3 pagesACCRE Test Parameters 2022jishnu.m89No ratings yet
- MahamTahir PDFDocument6 pagesMahamTahir PDFAdeel AizadNo ratings yet
- ResearchDocument3 pagesResearchAhtisham NadeemNo ratings yet
- Mapeh Q4 Week 1Document24 pagesMapeh Q4 Week 1Aira MalinaoNo ratings yet
- Effect of Constraint Induced Movement Therapy Versus Motor Relearning Programme To Enhance Upper Limb Motor Function in Stroke Patients: A Quasi Experimental StudyDocument7 pagesEffect of Constraint Induced Movement Therapy Versus Motor Relearning Programme To Enhance Upper Limb Motor Function in Stroke Patients: A Quasi Experimental StudyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Medicine GBS: Guillain Barre SyndromeDocument4 pagesMedicine GBS: Guillain Barre SyndromedinakarNo ratings yet
- Ringworm in CatsDocument4 pagesRingworm in CatsZain AsifNo ratings yet
- HalluDocument180 pagesHalluNajib ZulkifliNo ratings yet
- Commentary "Incidence of Total Thyroidectomy and Lobectomy"Document2 pagesCommentary "Incidence of Total Thyroidectomy and Lobectomy"Cristina RamirezNo ratings yet
- 2011 - Kim, Kim, Beriwal - Contouring Inguinal and Femoral Nodes How Much Margin Is Needed Around The VesselsDocument1 page2011 - Kim, Kim, Beriwal - Contouring Inguinal and Femoral Nodes How Much Margin Is Needed Around The VesselsPoljarLijanNo ratings yet
- Saving Lives Averting CostsDocument79 pagesSaving Lives Averting CostsMedCR1987No ratings yet
- Topic 2Document2 pagesTopic 2Joshua PanganNo ratings yet
- Pharm 02 A11Document4 pagesPharm 02 A11DonkeyManNo ratings yet
- Service: Medicine Attending Physician: Dr. Santos Date/Time 06/10/21 1400Document4 pagesService: Medicine Attending Physician: Dr. Santos Date/Time 06/10/21 1400Andrea Kyla Dela PazNo ratings yet
- Bronchiectasis - A Clinical ReviewDocument13 pagesBronchiectasis - A Clinical Reviewrudy sanabriaNo ratings yet
- CT BrainDocument230 pagesCT BrainpraveenbhavniNo ratings yet
- Gi BleedingDocument22 pagesGi BleedingAndreea GociuNo ratings yet
- Breast Imaging Mammography 1 and AnatomyDocument74 pagesBreast Imaging Mammography 1 and AnatomyabafzNo ratings yet
- Pcos Case StudyDocument33 pagesPcos Case StudyAli AkbarNo ratings yet
- Dyspepsia in Children IFFGDDocument2 pagesDyspepsia in Children IFFGDNorman Alexander TampubolonNo ratings yet
- Concept of Intentional Injuries and Its TypesDocument6 pagesConcept of Intentional Injuries and Its TypesDomenique Aldrin RestauroNo ratings yet
- ABM Chapter 2 Group 7 Research Part 1Document11 pagesABM Chapter 2 Group 7 Research Part 1Micah PabillarNo ratings yet
- Eeg NcsDocument5 pagesEeg NcsFathy ShaabanNo ratings yet
- Bloodborne Pathogens English QuizDocument6 pagesBloodborne Pathogens English QuizAslan MuborakshoevNo ratings yet
- Electrotherapy PresentationDocument24 pagesElectrotherapy PresentationHamza DibNo ratings yet