Professional Documents
Culture Documents
Flow 4.2 Training and Reference Manual.000
Uploaded by
dhirennaidooOriginal Description:
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Flow 4.2 Training and Reference Manual.000
Uploaded by
dhirennaidooCopyright:
Available Formats
Training and Reference Manual
Flow 4.2
Collect. Calculate. Visualize
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
4.2 Collect. Calculate. Visualize 2
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Information in this document is subject to change without notice. For the most up to date
documentation, please contact the Flow Software team at:
support@flow-software.com
Contents
“You can only manage what you can measure” ...................................................................................... 8
Data ..................................................................................................................................................... 8
Information ......................................................................................................................................... 8
Action .................................................................................................................................................. 8
Understanding data … Quickly! ............................................................................................................... 9
Understanding data … Accurately! ........................................................................................................ 11
What is Flow? ........................................................................................................................................ 14
What can I use Flow for? ....................................................................................................................... 15
Why should I use Flow? ......................................................................................................................... 15
What does Flow do? .............................................................................................................................. 16
Collect ............................................................................................................................................... 16
Calculate ............................................................................................................................................ 16
Visualize............................................................................................................................................. 16
Extracting value from time-based data ................................................................................................. 17
Time periods...................................................................................................................................... 18
Event periods .................................................................................................................................... 19
Flow Deployment Architecture ............................................................................................................. 20
Installed Components ....................................................................................................................... 20
Deployed Components ...................................................................................................................... 20
Lab 1: Installing Flow ............................................................................................................................. 21
Installation ......................................................................................................................................... 21
4.2 Collect. Calculate. Visualize 3
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Configuring Flow Bootstrap Service .................................................................................................. 23
Lab 2: Create a New Flow System ......................................................................................................... 25
Flow Config Orientation ........................................................................................................................ 27
Overall Layout ................................................................................................................................... 27
Lab 3: Prepare your Reporting Calendar ............................................................................................... 30
Shift Patterns ..................................................................................................................................... 32
Lab 4: Deploy your Flow System ............................................................................................................ 34
Lab 5: Create a Flow Model ................................................................................................................... 36
Model Locations ................................................................................................................................ 37
Lab 6: Connect to a Data Source ........................................................................................................... 38
Lab 7: Prepare your Default Measure settings ...................................................................................... 43
Lab 8: Create a new Measure ................................................................................................................ 44
Deploy the Measure .......................................................................................................................... 45
Measure Editor .................................................................................................................................. 46
Lab 9: Data Source Preview ................................................................................................................... 50
Understanding Measures ...................................................................................................................... 51
Measure Intervals.............................................................................................................................. 51
Measure Types .................................................................................................................................. 52
Aggregation Methods ............................................................................................................................ 54
Sum ................................................................................................................................................... 55
Average ............................................................................................................................................. 55
Minimum ........................................................................................................................................... 55
Maximum .......................................................................................................................................... 55
Range................................................................................................................................................. 55
First ................................................................................................................................................... 56
Last .................................................................................................................................................... 56
Delta .................................................................................................................................................. 56
Count ................................................................................................................................................. 56
Time in State ..................................................................................................................................... 56
Variance ............................................................................................................................................ 56
4.2 Collect. Calculate. Visualize 4
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Standard Deviation ............................................................................................................................ 56
Counter (Totalizers) ........................................................................................................................... 57
Custom Expression ............................................................................................................................ 58
Lab 10: Create a Manually Entered Measure ........................................................................................ 60
Lab 11: Scaling Factor ............................................................................................................................ 63
Lab 12: Create a Calculated Measure .................................................................................................... 64
Lab 13: Create a User Defined Function ................................................................................................ 68
Using a Function in a Calculated Measure ........................................................................................ 68
Lab 14: Create an Aggregated Measure ................................................................................................ 70
Lab 15: Create a Time-based Report ..................................................................................................... 73
Deploying a Report ............................................................................................................................ 78
Understanding Report Types ................................................................................................................. 79
Table .................................................................................................................................................. 79
Doughnut .......................................................................................................................................... 79
Gauge ................................................................................................................................................ 80
Scatter Plot ........................................................................................................................................ 80
Time Series ........................................................................................................................................ 81
Widget ............................................................................................................................................... 81
Lab 16: Create a simple Dashboard ....................................................................................................... 82
Open the Dashboard ......................................................................................................................... 84
Report and Dashboard Permissions ...................................................................................................... 86
Users and Groups .............................................................................................................................. 86
Assigning Groups to Folders .............................................................................................................. 86
Folder Permission Inheritance ........................................................................................................... 87
Lab 17: Create a Measure Limit ............................................................................................................. 88
Add the Limit to a Measure ............................................................................................................... 88
Add the Limit to a Report Measure ................................................................................................... 89
Lab 18: Create a Time Period Form for Data Entry ................................................................................ 91
View the Form and Edit Data............................................................................................................. 93
Form Permissions .............................................................................................................................. 98
4.2 Collect. Calculate. Visualize 5
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 19: Create an Event ........................................................................................................................ 99
Event Editor ..................................................................................................................................... 100
Lab 20: Create an Enumeration ........................................................................................................... 102
Lab 21: Add Attributes to an Event ..................................................................................................... 104
Lab 22: Create an Event-based Report ................................................................................................ 107
Lab 23: Create an Event Period Form .................................................................................................. 109
Lab 24: Associate an Event with a Measure ........................................................................................ 114
Lab 25: Monitoring System Progress ................................................................................................... 116
Lab 26: The “Packaging” Dashboard.................................................................................................... 119
Using the Flow Server .......................................................................................................................... 124
Messaging System ............................................................................................................................... 126
Message Trigger .............................................................................................................................. 126
Message Contents ........................................................................................................................... 126
Notification Services ........................................................................................................................ 126
Lab 27: Sending a Message ................................................................................................................. 127
Create a Message Channel .............................................................................................................. 127
Create a Message Definition ........................................................................................................... 130
Create an Email Notification Server ................................................................................................ 135
Deploying and Testing a Message ................................................................................................... 137
Using Message Content Placeholders ................................................................................................. 139
Notification Servers ............................................................................................................................. 144
Smtp Email ...................................................................................................................................... 144
Twilio ............................................................................................................................................... 145
Bulk SMS .......................................................................................................................................... 146
Flow Mobile ..................................................................................................................................... 147
Copying Events, Metrics and Measures............................................................................................... 148
Copying an Event ............................................................................................................................. 148
Copying a Metric ............................................................................................................................. 148
Using the Microsoft SQL Data Source.................................................................................................. 150
Measure Values ............................................................................................................................... 150
4.2 Collect. Calculate. Visualize 6
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Event Triggers .................................................................................................................................. 151
Event Attribute Segments ............................................................................................................... 152
Advanced Concepts ............................................................................................................................. 154
Filtering Detailed Data ..................................................................................................................... 154
Multiple Connections for a Measure ............................................................................................... 154
Relative Period Calculations ............................................................................................................ 155
Customizing the Flow Report Server ............................................................................................... 156
Understanding Flow System Modules ............................................................................................. 157
Flow Database Views ....................................................................................................................... 158
Integrating Flow information into other Systems............................................................................ 158
Flow Database Maintenance/Backups ............................................................................................ 158
Flow Directories .............................................................................................................................. 158
Customizing the Flow Simulator ...................................................................................................... 159
How do I get Flow? .............................................................................................................................. 161
Software Requirements ................................................................................................................... 161
Hardware Requirements ................................................................................................................. 161
Licensing .............................................................................................................................................. 163
4.2 Collect. Calculate. Visualize 7
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
“You can only manage what you can measure”
Unless you measure something, you will never know whether it is getting better or worse. You cannot
manage for improvement if you cannot see what you are trying to improve.
Data
The diagram below illustrates your production facility ①, which produces vast amounts of data ②
about your processes. This data, in some form or another, is stored in one or more data stores ③. In
many cases these data stores are simple databases, like Excel, but in other cases they are industrial data
Historians, SQL databases or even online data repositories.
Information
With the huge volumes of data that are collected in these data stores, it becomes important how we
“see and understand” this data. You may be thinking “Advanced Analytics” or “Statistical Processing”,
but these powerful tools are not always necessary. There is a simple and increasingly valuable option,
and that is effective data visualization ④. Applying basic data visualization best-practices provides a
quick and accurate understanding of the data ⑤. This understanding creates a “picture” of how the
production facility is performing – a “picture” that can be compared to your organization’s goals.
Action
A comparison of actual performance to organizational goals allows for better and more frequent
decision making ⑥, which affects the production facility. The quicker and more accurately information
can be gained from the data ④, the faster the cycle of informed and effective decision making can be
iterated, ultimately enabling the organization to achieve its goals.
4.2 Collect. Calculate. Visualize 8
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Understanding data … Quickly!
Here is an illustration of how data can be understood more quickly.
How many 3’s can you see in this string of numbers? How long does it take you to count them?
Going through all these numbers manually is not only error prone, but also time consuming.
Turn the page and try again …
4.2 Collect. Calculate. Visualize 9
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
How many 3’s can you see in this string of numbers? How long does it take you to count them?
The use of color helps us distinguish the 3’s from all the other numbers. Your brain’s visual cortex
“automatically” processes this data, making the task effortless and fast.
This example not only demonstrates how many 3’s there are, but also the distribution or pattern of 3’s
within the string of numbers, and that in itself provides additional information.
Using color to display information is a key data visualization best-practice.
4.2 Collect. Calculate. Visualize 10
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Understanding data … Accurately!
Here is an illustration of how data can be understood more accurately.
Everyone loves using Pie Charts, but which of the slices, A, B or C, is the biggest? How much bigger is it
than the others?
Your brain’s visual cortex is not so good at “seeing” angles. Turn the page and try again …
4.2 Collect. Calculate. Visualize 11
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Which bar, A, B or C, is the biggest? How much bigger is it than the others?
Encoding the data points in this way has allowed us to more accurately obtain the information we
need.
Using size, rather than angles, is another key data visualization best-practice.
4.2 Collect. Calculate. Visualize 12
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
“I want a system that I can install and configure myself to
get meaningful production information from my facility,
quickly and accurately, without the typical IT pain.”
4.2 Collect. Calculate. Visualize 13
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
What is Flow?
Flow is a flexible production reporting and operational analysis solution for industry. Flow provides a
self-service environment that enables the understanding and continuous monitoring of context
enriched decision support information. Using Flow, you can collect, transform and calculate
information from multiple data sources automatically.
Flow prepares information for presentation and integration. By employing data visualization best-
practice, Flow transforms your measured data into information that is understood quickly and
accurately, allowing frequent and effective decisions to be made.
Visualize and share information contained in your Flow System via web-based reports and dashboards
or by using other Reporting or Visual Analytics tools. Schedule the sending of information, reports and
dashboards via email and other notification services.
This introductory video will give you an idea of where you would be able to use Flow in your
organization.
http://support.flow-software.com/Introductory-Video
4.2 Collect. Calculate. Visualize 14
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
What can I use Flow for?
Flow is typically used as a Production, or Manufacturing, Performance Management System. It is
particularly useful in industrial applications because it understands industrial tag-based Historians. It is
able to connect to, and automatically collect, data from multiple data sources, making it an ideal system
for centralized reporting and data analysis.
Why should I use Flow?
If you are getting stuck in the IT funnel or have Excel spaghetti, then Flow may be a good solution for
your facility.
4.2 Collect. Calculate. Visualize 15
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
What does Flow do?
Collect
Flow automatically collects data from multiple data sources, aggregates it and stores it in a
structured format. Once configured, Flow will continuously collect data from these data sources.
The following data sources can be connected into your Flow System:
o Historian data sources (e.g. Wonderware Historian, etc.)
o OPCHDA compliant Historian data sources (e.g. Canary Labs Historian, OSIsoft PI Historian,
GE Proficy Historian, Siemens Process Historian, TopServer Historian, Citect Historian, etc.)
o Microsoft SQL Server databases (e.g. MES, LIMS, Weighbridge, Power Systems, etc.)
o HMI History files (e.g. Wonderware InTouch LGH files, etc.)
o Microsoft Excel files
o Text / CSV files
o Online data sources (Wonderware Online, Metering Online, Web API, etc.)
Flow allows you to “backfill” historical data from your data sources, thus allowing you to leverage
your existing systems and perform historical analysis and calculations on old data.
Data can also be entered manually into the Flow System and used in calculations.
Calculate
Information in Flow can be aggregated (rolled up) from smaller time periods (i.e. hours) to bigger
time periods (i.e. shifts / days / weeks / months)
Information in Flow can be used in calculations to create new information (i.e. KPIs, ratios,
efficiencies, etc.)
Information in Flow can be contextualized by production events (i.e. how much electricity was used
to make Grape juice compared to Apple juice during this month?)
Information in Flow can be validated and retrospectively edited with audit control and full version
history
Visualize
The Flow System is a single repository for all data collected (automatically or manually) and
calculated. This makes it a perfect source of information for Reporting and Integration into other
systems (e.g. MES, ERP, etc.)
The Flow System serves report information directly without the need for re-querying the underlying
data sources. This enhances the performance of the reporting and visualization layer, making for a
vastly improved user experience.
Flow makes use of a built-in web-based report and dashboard server.
Flow makes use of a built-in messaging system to schedule the sending of Flow information, reports
and dashboards via various Notification Services (e.g. Email, SMS, Flow Mobile).
Other Visualization or Business Intelligence tools can be used to create visual dashboards, reports
and provide self-service analyses (e.g. Tableau Software, Qlikview, Microsoft PowerBI, Dream
Report, Wonderware Intelligence, etc.)
4.2 Collect. Calculate. Visualize 16
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Extracting value from time-based data
Industrial Tag Historians store high resolution data, generally at sub-second resolution, and provide
detailed trends, like the kWh totalizer shown below. This detailed information is incredibly useful for
real time monitoring and troubleshooting process problems, but is not really useful for managing
Operational Performance.
Management teams demand more than just trends. They expect context rich information to be “lifted”
out of this detailed data. This involves summarizing the data into a form that is quickly and accurately
understood at a management level. The summarized information is not only demanded by
management teams, but is important to empower operators and team leaders to make their own
decisions.
To achieve this, they need a system that gives them decision support and insight. They want to know
things like:
Which machines are performing most efficiently?
What is different about the machines that perform well?
Do the machines run more efficiently when running specific products?
Are some shift teams able to achieve better efficiencies than others?
How often are the machines stopping? Do we know why?
Do we have unexpected electricity, or water, over usage scenarios?
Let’s see how Flow can help provide this decision support and insight.
4.2 Collect. Calculate. Visualize 17
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Time periods
Flow transforms this detailed data into context-rich information by aggregating it into time and event
periods. Let’s consider the Filler 1 Electricity (kWh) totalizer. Its data is logged every second, but we’re
only interested in the number of kWh consumed every hour. If we “overlay” hourly time periods onto
this detailed trend, we can easily summarize how many kWh were used in each hour.
For the hour starting 06:00 and ending 07:00, the kWh consumed can be calculated as:
14063.4 (07:00) – 14058.1 (06:00) = 5.3 kWh
By repeating this process, a simple summary report of the kWh used every hour can be produced as
follows:
The process of summarizing data in Flow is known as data retrieval and aggregation. In the kWh totalizer
example, the data is retrieved from a data source for each time period and then aggregated to provide
a single piece of information for that time period (i.e. a single value for the hour starting at 06:00).
Flow makes use of different aggregation methods, depending on the detailed source data and how you want the
summarized information to be presented. In the kWh totalizer example, Flow used a Counter aggregation
method. Other aggregation methods include Minimum, Maximum, Range, Average, Sum, First, Last, Delta, Count,
Variance, Standard Deviation and Time in State. These will be discussed in more detail on page 54.
4.2 Collect. Calculate. Visualize 18
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Event periods
Let’s take the Filler 1 Electricity (kWh) totalizer example a little further. For Filler 1, the Tag Historian is
storing data related to the Filler’s current product run. The detailed data relating to the Product is very
useful in terms of adding additional context to the information we “lift” out of the Tag Historian.
Flow understands the start and end of event periods. In this example, Flow starts an event when the
value of the Product changes from 0 to a positive number. Flow ends the event when the value of the
Product goes back to 0. Flow then “overlays” the event period onto the kWh detail and calculates how
many kWh were used during that production run:
14027.9 (00:51:43) – 14079.8 (09:49:14) = 51.9 kWh
By repeating this process and mapping the Product to a reportable description, a simple summary
report of the kWh used per production run, per product can be produced as follows:
4.2 Collect. Calculate. Visualize 19
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow Deployment Architecture
Before we get started, it is important to understand the various components that Flow consists of. Flow
is made up of installed components, deployed components and plug-in components.
Installed Components
Flow Bootstrap – communication between all Flow components and modules
Flow Config – configuration environment, create events, measures, calculations, monitor system
Deployed Components
Flow Platform – coordination between components in a Flow System
Flow Engine – automatic data source retrieval, calculation execution and limit evaluation
Flow Message Engine – automatic processing and scheduling of messages
Flow Report Server – Web-based Report and Dashboard Server
Flow Database – Microsoft SQL Server database to structure and store the Flow System’s data. A
Microsoft SQL Server installation is required in order to deploy a new Flow System.
The Flow System can be installed as a “stand-alone” system on a single machine, or it can be installed as a
distributed system across multiple machines. A distributed system should be used for large systems where engine
load balancing is required.
4.2 Collect. Calculate. Visualize 20
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 1: Installing Flow
For this lab, we are going to install Flow as a “stand-alone” system on a single machine.
Note: Please make sure you have already installed Microsoft SQL Server, preferably as the “default instance”.
To get started with Flow, everything you need is contained in a single Windows Installer file (.msi). The
name of the installer file is “Flow 4.0.x.x.msi”, where the 4.0.x.x is the build number. The build number
relates to a specific release, which can be confirmed at support.flow-support.com.
Installation
Run the Flow Installation Package:
Click “Next” …
Accept the terms of the License Agreement and click “Next” …
4.2 Collect. Calculate. Visualize 21
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
By default, all components will be selected for installation. Click “Next” …
Select the installation path and click “Next” to begin the installation.
Distributed Installation
In the “real world” you would install the separate components of Flow on different machines. For example:
The Bootstrap would be installed on servers where you want to deploy the Flow Platforms, Engines, Message
Engines and Servers.
The Config Tool would be installed on your developers’ (or even business users’) computers for configuring
measures, events and reports.
4.2 Collect. Calculate. Visualize 22
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Configuring Flow Bootstrap Service
This is an important step to remember when installing the Bootstrap component; the Bootstrap
component is a Windows Service that can be found in the Services application.
By default, the Flow Bootstrap Service is installed to Startup Automatically. Confirm this setting by
opening its Properties …
4.2 Collect. Calculate. Visualize 23
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Select the “Log On” tab and change the “Log on as:” option to a specific Account that has access to the
Microsoft SQL Database where the Flow Database will be deployed. This Account must have local
Administrator rights on the server where it is running. The local Administrator rights are required for
Flow to create Event Viewer log sources and start internal web service components.
Click “OK” and restart the Flow Bootstrap Service when prompted.
Some Data Sources that Flow will collect data from may require a special Account to allow access. An example of
this is Wonderware Historian. It is recommended that the Wonderware Network Account be used to run the Flow
Bootstrap Service.
4.2 Collect. Calculate. Visualize 24
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 2: Create a New Flow System
After installing Flow, you will find a shortcut to the Flow Config tool on your desktop. Run the Flow
Config tool.
When running Flow Config for the first time, you will be presented with the "Connect" dialog box. Use
this to create a new Flow System.
Follow these steps to create a new Flow System:
Name – This is a friendly name that you can use to describe your Flow System. Name this new Flow
System "The Juice Factory"
Server – This is the name (or IP address) of the Microsoft SQL Server where your new Flow System
will be created. If your SQL Server has a “named instance”, then use the full instance name. By
default, this is set to the name of the computer you are currently using.
Database – This is the name of the SQL Database where the data for your new Flow System will be
stored and organized. By default, the database will be named “Flow”. If you already have a
database named “Flow” on this SQL Server, you will need to give your new one a different name.
Username and Password – If you need to use SQL Authentication to create and access the SQL
Server, then specify the SQL login name and password, otherwise leave these fields blank to use
Integrated Security (i.e. your Windows logged on user account)
Click "Create" and Flow will confirm your settings as follows:
4.2 Collect. Calculate. Visualize 25
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
If necessary, change the “Time Zone” before creating your Flow System. The Time Zone of your system
cannot be changed once it has been created.
Click “Create” and Flow will deploy a new database to the Microsoft SQL Server and set it up for first-
time use. Once this has been completed, Flow will open your new system.
4.2 Collect. Calculate. Visualize 26
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow Config Orientation
Before we continue, it is worth spending some time understanding the layout of the Flow Configuration
environment.
Overall Layout
Flow Config has been designed to be a drag ‘n drop environment. The layout of various tree views
enables rapid configuration of new measures, events, reports and messages. We think you’ll love it.
Model View
This is the “Model” tab on the left. It represents the Physical Model of your production facility. Flow
allows this model to be completely flexible, however, it is advisable to follow a structure like S88 or S95
where possible. It is a good idea to define a naming standard early in your configuration process.
Notice the “Deployment” and “Users” tabs at the bottom of the Model view. The Deployment tab
shows a model of your Flow System. It consists of Platforms, Engines, Message Engines and Report
Servers. The Users tab shows the users and groups assigned to the Flow System.
4.2 Collect. Calculate. Visualize 27
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow “Zone”
This is a multi-purpose toolbar allowing dragging and dropping onto the various icons. You will use
these icons extensively while building your Flow Model.
Information Model
This is the “Reports” tab on the right. It represents an Information Model. Like the Model view, it is
completely flexible, however, it is advisable to model this view on the structure of your report
consumers (i.e. your audience).
Notice the other tabs at the bottom of the Information Model, namely, “Forms”, “Messages”,
“Toolbox”, “Context” and “Data Sources”. The Forms tab allows you to create data entry (or data
validation) forms. The Messages tab allows you to define and schedule the sending of information,
reports and dashboards via email and other notification services. The Toolbox tab allows the definition
of global system objects, like enumerations and functions. The Context tab allows you to define your
calendars and shift patterns, as well as model attributes. The Data Sources tab allows you to configure
data connections and view their namespaces.
4.2 Collect. Calculate. Visualize 28
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Defaults
Along the top of the Flow Config window is a “Defaults” toolbar. When you are creating many new
Measures and Events, you will use the Defaults to help streamline your development process.
Editor Space
In the center of the Flow Config window is a space where all the object editors will open up. All objects
(i.e. Measures, Events, Reports, Forms, Messages, Engines, etc.) have their own editors, which will open
up when the objects are double-clicked.
4.2 Collect. Calculate. Visualize 29
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 3: Prepare your Reporting Calendar
Now that you can find your way around Flow Config, let’s start configuring your system. One of the
first things to do is configure your reporting Calendar. Flow can use multiple Calendars, but for the
purposes of this lab, we will configure the default “Production” calendar.
Calendars and Shift Patterns tell Flow how to structure time-based data for reporting purposes. For
example, your reporting day may start at 06:00 in the morning or your reporting year may start in
March. The Flow calendars allow you to configure these things. When the Flow Engines run, they will
use the Calendars to create reporting “time periods”.
Select the “Context” tab under the Information Model view and double-click the “Production” calendar
in the “Calendars and Shifts” view …
In the calendar editor you will be able to set the following properties:
Description – used for reporting (can be left blank)
Management – by default Flow will manage a calendar’s “time period” creation automatically based
on the standard Gregorian calendar system, applying the applicable offsets where required. There
may be times where specific “time period” creation is required. In this case, you will need to use
4.2 Collect. Calculate. Visualize 30
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
the “Manage this calendar externally” option, and then manually create time periods in the Flow
database using the “CreateManualTimePeriod” stored procedure.
Year starts in – used to define the month in which the reporting year will start (e.g. financial year)
Week starts on – used to define the day on which the reporting week will start.
Day starts at – used to define the hour and minute at which the reporting day will start.
Hours split into – used to define the duration of “minutely” time periods. It is important to note
that “minutely” in Flow does not mean a single minute, but rather a sub-hourly period that has this
duration. The smallest “minutely” time period duration is 5 minutes. If this setting is set to 60
minutes, then Flow will not allow the creation of minutely measures.
The above Flow Calendar settings can only be modified when all Flow Engines are undeployed.
Click on the “Default Refresh Offset” bar …
The Refresh Offset for a measure is the “delay” or offset from the “Period End” to the time the retrieval
of a measure will be performed by the Flow Engines. Each calendar has a set of default refresh offsets
that will be used when a calendar is first linked to a measure.
Click on the “Purge Age” bar …
Flow has the ability to automatically remove old data. This ensures a well maintained system. For
example, if we set the minutely time period’s Purge Age to 90, the Engines will automatically remove
4.2 Collect. Calculate. Visualize 31
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
minutely measures’ data that are older than 90 days. By default the Purge Age for each “Time Period”
type is set to 0 days, which implies that purging is disabled.
Purging is recommended for large systems that have accumulated a few years of data. If purging is not configured,
your Flow System may perform slowly.
Shift Patterns
Expand the “Production” calendar. By default, your new Flow System’s “Production” calendar has a
pre-configured Shift Pattern. Shift Patterns in Flow are defined by a Date and Time from which the Shift
Pattern is valid. Additional Shift Patterns can be added to the calendar, as long as they have a different
Date and Time. This mechanism provides the ability to change Shift Patterns over time.
Double-click the “2010-01-01 06:00” Shift Pattern to open its editor …
Notice that this default Shift Pattern has a 3 x 8 hour shift scheme, repeating each day of the week. The
start of the week is defined by the Shift Pattern’s parent Calendar. The start of the day is defined by
the Shift Pattern’s parent Calendar.
By definition, a Shift Pattern has a duration of one week (i.e. 7 “Production” days). Flow will repeat the
pattern from the Date and Time definition every week, up until a new Shift Pattern definition is found.
4.2 Collect. Calculate. Visualize 32
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
If you needed to start a new 2 x 12 hour shift scheme, starting on Sunday 1st November 2016, you would
create a new Shift Pattern named “2016-11-01 06:00” under the “Production” Calendar. You would
then open the Shift Pattern and shuffle the individual shifts around as required. If you needed to
rename or add a new “Shift” type, you will find the Shifts defined in the “Toolbox” tab, under “Shifts”.
You can drag these “Shifts” onto the Shift Pattern canvas to create and manage your shift patterns.
4.2 Collect. Calculate. Visualize 33
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 4: Deploy your Flow System
Once you have configured your reporting calendar (or calendars), you need to configure your
Deployment model. We are using a simple “stand-alone” architecture, but the deployment model
needs to be planned carefully for a distributed architecture.
Select the “Deployment” view tab at the bottom of the Model View …
By default, your Flow deployment model will have a single Platform
containing an Engine, a Message Engine and a Flow Report Server.
Right-click on the Platform and click “Deploy”. Deployment will only
work if the Flow Bootstrap Service is running on that computer. If
you see an error message when deploying, it is likely that that the
Flow Bootstrap Service is not running on that computer. Make sure
that you have installed and configured the Flow Bootstrap Service
(page 23) on that computer.
If you are still having communication errors, confirm that port 4501 on that
computer has not been blocked by the firewall.
Once you have a running Platform (i.e. no white disk), you can right-
click on the Engine, and click “Deploy”.
The white disk will immediately turn red, but should disappear when
Flow has confirmed that the Engine is running. Give it a few seconds
to start the Engine.
If the red disk on the Engine does not disappear, it is likely that the
Flow Bootstrap Service has not been configured correctly. Please
review the Flow Bootstrap Service configuration on page 23.
4.2 Collect. Calculate. Visualize 34
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
To assist with any troubleshooting, Flow maintains an error and warning log in the Windows Event
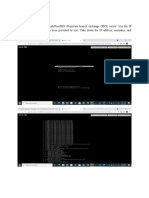
Viewer on the computer where the Flow Bootstrap Service is running. Open the Windows Event Viewer
…
You will find a log called “Flow” under the “Applications and Services Logs”. If you see any Errors in the
Flow log, select it to view the error message. This message will be useful for you or your Flow support
contact to troubleshoot any problems with your Flow System.
The “Flow” log is created on any computer running the Flow Bootstrap Service.
To complete the deployment of your Flow System, right-click on the “Message Engine” and “Flow
Report Server”, and click “Deploy”. A fully deployed Flow System will have no red or white disks
displayed in the deployment view.
By default the “Flow Report Server” uses port 80. If the computer running the “Flow Report Server” has another
web server running on it, make sure the default Ports do not clash (e.g. Internet Information Server, SQL Server
Reporting Services, etc.) If necessary, change the “Flow Report Server” Port setting to 8000. You can access the
“Flow Report Server” settings by double-clicking it. See section on page 156.
4.2 Collect. Calculate. Visualize 35
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 5: Create a Flow Model
Now that you have a deployed Flow System, let’s start building a Model of your production facility.
Select the “Model” view tab. Flow created a new default root folder called “The Juice Factory” (the
name you gave your Flow System when creating it on page 25).
Right-click on one of the folders …
The menu allows a number of options:
New Folder – create a new folder to group objects in your model
New Event – create a new event definition
New Metric – create a new metric to be measured
Rename – rename any object in your model
Move Up – reorder folders to provide a procedurally accurate representation of your facility
Move Down – reorder folders
Refresh – refresh the model
You can also use the Flow Zone toolbar to drag new objects onto your model
Let’s assume you have a good understanding of your Juice Factory layout. Create the following folder
structure to represent the Juice Factory facility:
4.2 Collect. Calculate. Visualize 36
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Model Locations
Flow provides the ability to set a “location” at each level in your Model View. A “location” is defined in
the Toolbox. Let’s create a location that can be used in your Model. Select the “Toolbox” tab, right-
click on the “Locations” item and create a new location. Use a location appropriate to your Model:
Double-click the location to open its editor:
These location properties are optional.
Now that you have defined a location, let’s allocate it to the root folder in your Model View. Double-
click “The Juice Factory” folder to open its editor and then set its location:
All folders in the Model View, including child folders, can have their location set. If a child folder is not
explicitly set, it will inherit the location of its parent folder by default.
Where Flow is used to provide information to a higher level visualization tools (e.g. Tableau, Qlikview, etc.), these
location properties are exposed in the Flow SQL database views (see section “Flow Database Views” on page 158).
4.2 Collect. Calculate. Visualize 37
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 6: Connect to a Data Source
Before you can start retrieving data into your Flow model, you will need to connect your Flow System
to one or more data sources.
Select the “Data Sources” tab at the bottom of the Information Model on the right hand side …
The “Data Sources” panel is split into two sections.
Data Sources
At the top, the Flow System’s available Data Source types are listed.
By default, a new Flow System will have the following Data Source
types available:
Microsoft SQL
OPC HDA (connects to most Industrial Historians)
Simulator
Wonderware Historian (external toolkit installation required)
Wonderware Online
The Simulator is used for demonstration and training purposes.
Namespace
Once a Data Source connection has been added to the Flow System,
selecting it will populate its “Namespace”. The “Namespace” is
provided by the Data Source (e.g. Wonderware Historian provides a
folder tree containing all the tags configured).
The “Namespace” also provides a place where you can create your own folders and items. You can use
this functionality to create “shortcuts” to your favorite tags, or “templates” that would simplify the
creation of new measures (e.g. SQL query template when using the Microsoft SQL Data Source).
Connect to the Simulator
For this lab, let’s create a connection to the Simulator Data Source. Right-click on the Simulator Data
Source type and click “New”. Give the new Simulator connection the name “Historian”, and click “Save”
4.2 Collect. Calculate. Visualize 38
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Select the new “Historian” connection in the Data Source view. Notice how the Namespace displays
the folders and tags available in the “Historian”. Think of the Namespace as a “window” directly into
the configuration of the “Historian”. If the Historian supports engineering units, they will be displayed
as part of the tag item. If the Historian supports tag descriptions, they will be displayed as tooltips when
you hover over the items.
4.2 Collect. Calculate. Visualize 39
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Create a custom “Namespace”
Note that it is not necessary to create a custom namespace if your
Data Source provides one already. However, you may want to use
the custom namespace functionality to create a “shortcuts”,
“links” or reusable “templates” within your Data Source.
For this lab, let’s create a single custom namespace item so that
you know how to do it when you need to.
Right-click in the whitespace below the Data Source’s namespace
and select “New Folder”.
Name the folder “My Favorites” …
Now create a new custom item. Right-click on “My Favorites”
and select “New Analog”.
Name the new item “Water Mains Totalizer”. We are going
to configure this custom item as a “shortcut” or “link” to one
of the existing Historian tags.
4.2 Collect. Calculate. Visualize 40
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Right-click on the “Water Mains Totalizer” and select “Edit” (or
press F2) to open the custom item’s editor:
Update the properties of the new item as per your requirements. In this example you can set the Tag
property to “020-FQ-001.PV” (an easy way to do this is to drag the “Tag” property of the actual 020-
FQ-001.PV item onto the Tag textbox). Change the Aggregation property to “Counter”.
4.2 Collect. Calculate. Visualize 41
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now can use this custom item just like you would have used any standard Data Source items. You will
see how to do this in the following labs.
Flow supports multiple connections. This means you can connect many Data Sources to your Flow System. You
may have a number of SQL Databases and Historians all connected to your Flow System.
When you have a large system, you can see where items from each Data Source are being used by clicking “Detail”
to open a Data Source dependency view:
4.2 Collect. Calculate. Visualize 42
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 7: Prepare your Default Measure settings
Before you create a measure that retrieves data from the “Historian”, let’s setup a few Default Measure
settings.
Browse through the Historian’s Namespace until you find tags
relating to the Juice Factory’s Boiler. Hover over these tags to see a
brief description of what they represent. Using the description and
the engineering units, you should get a good idea of what these tags
are.
Let’s focus on the Temperature tag, 010-TT-001.PV, measured in ˚C.
The value of this tag is most likely being stored in the Historian at
high-resolution, possibly every second.
To report on this temperature, you want to create a Flow measure
that stores the average temperature every hour. You want to report
the average temperature to 1 decimal place (i.e. 98.2 ˚C). You also
know that your Historian has a few months of data already stored,
so let’s go back and retrieve the average temperature for every hour
as far back as we can.
Given that you know a few of the settings required to report on the Boiler Temperature, it is useful to
pre-select the Measure defaults as described on page 29.
Select the following:
Default Time Base – set this to Hourly since we want an hourly summary of the temperature.
Default Format – set this to 0.0 (to give us 1 decimal place).
Default Unit of Measure (UOM) – ignore this for now because the Historian supports engineering
units.
Default Backfill Date – set this to the beginning of last month (notice the hour starts at 06:00 based
on our calendar definition).
4.2 Collect. Calculate. Visualize 43
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 8: Create a new Measure
You are going to create a measure for the Boiler Temperature under the “Steam” folder in your Flow
Model. But before we can create the measure, we first need to create a Metric inside the “Steam”
folder.
Drag the Metric icon from the Flow Zone onto the “Steam” folder …
By default the new Metric will take on the name of its parent folder.
Locate the 010-TT-001.PV Boiler Temperature tag from the Historian, drag it across to the Model View
and drop it onto the “Steam” folder.
4.2 Collect. Calculate. Visualize 44
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Notice what has happened …
When you dropped the tag onto the metric, Flow created a measure
for you. Notice how the icon describes a few of the measure’s
properties:
You should see the white disk appear on the measure and recursively up the model tree. Like in the
deployment view, this white disk indicates that there are undeployed objects in that branch.
Deploy the Measure
The measure has been created, but it is not “Deployed” (i.e. it is not running). To get it to run, you need
to “Deploy” it. Right-click on it and select “Deploy”.
The Engine you deployed earlier will now start processing this measure. The Engine will go and collect
summary information from the Historian for every hour back to the Backfill date and time, catch up to
“now”, and then continue to process every hour from now on.
If you select the “Deployment” view tab, you will notice the new Metric is allocated to the Engine for
processing. If more than one engine was configured in a distributed architecture, you could deploy
your metric to any of those engines.
4.2 Collect. Calculate. Visualize 45
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Measure Editor
Let’s have a look at what is happening behind the scenes. Double-click on the new measure to open its
Editor …
General Properties
The top section of the Measure Editor displays a few general properties for the Measure:
Description – Measure description (in this case, the description was pulled through from the
Historian tag’s description)
Format – report format used to display the summary values (in this case, 1 decimal place)
Unit – unit of measure (in this case, the unit of measure was pulled through from the Historian tag’s
engineering unit. This is why we didn’t need to set the Default Unit of Measure.)
Backfill – the date and time used by the Engine to go back in history and retrieve the summary
information from the Historian
Context
4.2 Collect. Calculate. Visualize 46
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
By default, the Context section will show a chart of the summarized information relating to the
measure. In this case, the chart is displaying the last 12 hours of average Boiler Temperature in ˚C for
each hour. The vertical cursor line represents the following states:
Green - the measure is running. The cursor represents the last successful processing time.
Red - the measure is running, but has been "Backfilled". The cursor will turn Green as soon as the
Engine accepts the Backfill date.
Black - the measure is not running (i.e. it has been undeployed).
The same information can be displayed in a grid. Select the Grid tab …
Notice the information provided in the grid:
Period Start – the start of the time period (in this case the start of the reporting hour).
Period End – the end of the time period.
Value – the formatted summary value retrieved from the Historian.
Quality – the OPC Quality of the data used to produce the summary value (192 = Good, 0 = Bad)
Duration – the duration of the time period in milliseconds.
Preferred – indicates whether this version of the value for the time period is used for reporting.
Version – the version of the value for this time period.
Captured – date and time when the value was actually retrieved / calculated / edited.
User – indicates if and who made changes to the measure value via the Flow Server.
Select the Properties tab …
4.2 Collect. Calculate. Visualize 47
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
The “Context” section contains configuration relating to what context the measure’s values are
summarized against. In this case, you will notice the “Production” calendar has already been added to
this measure’s context. Being an hourly measure, the Engine will process it against the “Production”
calendar’s definition for hourly time periods. In this case, the “Production” calendar’s hourly time
periods are standard hours (e.g. 06:00 to 07:00), but you could have set the calendar up for hours to
start at 15 minutes past the hour (e.g. 06:15 to 07:15).
Notice that a default “Refresh Offset” of 60 seconds has been configured for this calendar context. This
means that Flow will only attempt to get the current hour’s summary information from the Historian
60 seconds after the hour is completed. More than one “Refresh Offset” can be configured if required.
Processing
Expand the “Processing” section. Flow allows you to project a measure into the future by a number of
intervals. By default, a measure will be set to process “now” (i.e. 0 periods into the future). By setting
the “Projected” property of a measure to a positive integer value will set the measure to process into
the future. Notice that the chart in the “Context” section will show the “future” periods in the green
shaded area.
Projected measures are useful for information relating to plans or predictive calculations. For this lab,
leave the “Projected” value as 0 periods.
Retrieval
Expand the “Retrieval” section. Notice that this section contains information about the tag you dragged
across from the Historian Namespace.
4.2 Collect. Calculate. Visualize 48
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Tag – the “Historian” tag for which summary data is retrieved (this was populated during the drag
n’ drop action, but can be edited if required, another tag can also be dragged over this textbox).
Aggregation – this determines how the detailed data (i.e. high-resolution data) should be
summarized into an hourly value for reporting purposes. By default, Flow uses the average
aggregation method.
Scaling Factor – this is a factor that the resultant summarized value is multiplied by in the case
where scaling is required (e.g. simple unit of measure scaling).
Filter Tag – when retrieving data from the Historian, Flow can use the value of another tag (or the
same tag) to filter out unwanted detailed data. This is discussed in detail in a section on page 154.
Dependents
This section displays any other objects in your Flow System that depend on this measure. Examples
include:
Other measures that may use this measure in calculations or aggregations
Reports
Forms
Change Log
This section displays a change log for this specific measure, from creation to deployment. Any changes
that are made to the measure’s configuration will be logged here.
To confirm the Change Log functionality, rename the “Steam” measure in the Model View to “Steam
Temperature”. Refresh the Change Log and notice the new log relating to the rename action.
4.2 Collect. Calculate. Visualize 49
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 9: Data Source Preview
Now that you have created and deployed your first measure, let’s go back to the Data Source tag and
compare the detailed values to the measure’s summarized values for each hour.
Select the “Data Sources” tab at the bottom of the Information Model and double-click the “010-TT-
001.PV” Boiler Temperature item …
The “Data Source Preview” is a useful view of the detailed data. After opening the “010-TT-001.PV”
tag, play with “Zoom In”, “Zoom Out”. Double-click to zoom in. Notice the right-click context menu
options for each chart: “Pin to Zero”, and each item: “Format”, “Style”, “Width”, “Move” and
“Remove”.
The “Data Source Preview” window has two chart sections, top and bottom. By default the top section
is used, however, additional tags, measures and events can be added to these two sections.
Drag the “Steam Temperature (˚C)” measure from the Model View onto the bottom section. By default,
the “Pin to Zero” setting is unlocked. Notice how the time axis is always kept in synchronization
between the top and the bottom sections. This is useful for alignment and troubleshooting.
Remove the “Steam Temperature (˚C)” item from the bottom section and add it to the top section. You
should now see the overlap of the summarized measure values, changing every hour, overlaid on the
detailed value. Zoom out to about 8 weeks of data. You should notice that the legend for the detailed
values adds the word “Sampled”.
Be aware of “Sampled” because the chart only shows a subset of the detailed data, evenly spaced over
the period. This means that some important points may not be shown. As soon
as you zoom in enough, and the word “Sampled” disappears, you will know you
have all the data points displayed. Note that the grid view will always show all
data points.
4.2 Collect. Calculate. Visualize 50
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Understanding Measures
As you have seen from the previous labs, a Measure can summarize data from a data source and store
the resultant information in your Flow System. In the previous labs, you created a Measure that
summarized data every hour. This means that for every hour (described by your calendar’s definition),
a summary value was created and stored in the Flow System for that Measure. However, Flow handles
more than just hourly time periods. Let’s see …
Measure Intervals
The following Measure intervals can be configured in Flow (notice the associated icons):
Minutely
Hourly
Shiftly
Daily
Weekly
Monthly
Quarterly
Yearly
Each Measure created in your Flow System will be associated with one of these intervals. Once created,
a Measure’s interval cannot be modified. If you create an hourly measure for the average Boiler
Temperature, but you also require the daily Boiler Temperature average, you will need to create a new
daily measure.
It is important to note that “Minutely” in Flow does not imply a single minute time period, but rather a
sub-hourly period that is defined by your calendars. The available “Minutely” durations are:
5 minutes
10 minutes
15 minutes
20 minutes
30 minutes
The reason Flow has these “Minutely” time periods is to accommodate the aggregation (roll up) of data to an
“Hourly” time period.
4.2 Collect. Calculate. Visualize 51
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Measure Types
In the previous labs, you created a Measure that retrieved detailed data from a data source (i.e.
Historian) and summarized it into a single value stored in the Flow System. This Measure Type is known
as “Retrieved”. However, Flow allows the configuration of other Measure Types as well, let’s discuss …
The following Measure types can be configured in Flow:
Retrieved (from a data source)
Manually Entered (by a person)
Aggregated (rolled up from other Flow Measures)
Calculated (from other Flow Measures)
Retrieved Measures
Retrieved Measures are used to collect data from the data sources you have connected to your Flow
System. These measures are responsible for collecting, summarizing and storing data from the “outside
world” in your Flow System.
Most Flow Data Source types represent tag-based time series data. For this reason, Flow has defined
a number of aggregation methods to standardize how detailed data is summarized into Flow. A detailed
description of how these aggregation methods function is provided on page 54.
Note that Flow does not replicate the detailed data from your data sources in the Flow System. It will only store
the summarized information in the Flow System.
Manually Entered Measures
It is not always possible to retrieve information automatically from a data source. Some information is
just not available in a data source. For this reason, Manually Entered Measures are used to allow
insertion of information into your Flow System by people.
Examples of where you would use a Manually Entered Measure include:
Instrument data that isn’t available in your control systems and historians
Calculation factors that you will want to change over time
Aggregated Measure
Aggregated Measures are used to perform roll up calculations of other measures in your Flow System.
For example, you have already created a measure that summarizes the Boiler Temperature from your
Historian every hour. You can configure a new Aggregated Measure to calculate the daily average of
these hourly values. This means that the new daily measure does not have to re-query the detailed
data from the Historian to provide the daily summary values, it rather uses the information Flow has
4.2 Collect. Calculate. Visualize 52
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
already collected from the Historian for the hourly values. Furthermore, if any of the hourly values
need to be edited via the Flow Server, Flow will automatically re-calculate the daily Aggregated
Measure, thus maintaining the integrity of the information stored in your Flow System.
By using Aggregated Measures, you not only reduce the retrieval load on your data sources, but also increase the
performance of your Flow System.
Calculated Measures
Calculated Measures are used to configure your own calculations based on one or more measures in
your Flow System. This is an extremely powerful feature which allows you to generate additional
information, just like you would be able to do in Excel. For example, if you had an hourly measure for
production counts, and an hourly measure for electricity used, you could create an hourly calculated
measure for the ratio of electricity used per unit of production.
In addition to allowing the configuration of calculations, Flow has a built-in library of common functions,
similar to what you would find in Excel. You can even create your own User Defined Functions to
standardize and simplify your calculation expressions.
Flow allows you to use Calculated Measures inside other Calculated Measures, making nested calculations
possible.
4.2 Collect. Calculate. Visualize 53
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Aggregation Methods
When retrieving detailed data from tag based time series data sources (i.e. Historians), Flow makes use
of a number of aggregation methods to standardize how this data is summarized and stored in the Flow
System. In a previous lab, you created a measure that calculated the average value of the Boiler
Temperature for each hour. The aggregation method you used was “Average”, but there are a few
others you should know about. Let’s discuss each of these aggregation methods in detail.
Let’s use a standard set of detailed data, and then apply each of the aggregation methods to the same
data set. Here is our data set …
Point Timestamp Raw Value
1 05:55:03 1.6
2 06:03:23 2.3
3 06:07:30 2.5
4 06:10:22 3
5 06:15:52 2.1
6 06:20:40 1.9
7 06:25:13 2.5
8 06:29:44 2.3
9 06:35:14 1.6
10 06:41:14 1.8
11 06:46:03 2.3
12 06:52:35 2.9
13 06:55:26 2.2
14 07:05:40 1.4
Which, graphically, looks like this if we plot the points. The shaded area is the time period we are
interested in for our summary information.
4.2 Collect. Calculate. Visualize 54
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow uses a “Stair Step” interpolation between each point, like this …
Because the first point in our data set is outside of our summary time period, Flow uses it as a
“boundary” value with a timestamp of exactly 06:00:00.
The Wonderware Historian Data Source type does allow the option to use a different Interpolation between
points, however, Flow will default to using “Stair Step”.
Sum
When using the “Sum” aggregation method, Flow will calculate the sum of points 2 to 13. It will exclude
the “boundary” value, since point 1 before the “boundary”, would have been used in the previous time
period’s calculation.
Average
When using the “Average” aggregation method, Flow calculates a time weighted average. The
“boundary” value is included in the calculation.
Minimum
When using the “Minimum” aggregation method, Flow determines the minimum value of all the points
within the time period, including the “boundary” value.
Maximum
When using the “Maximum” aggregation method, Flow determines the maximum value of all the points
within the time period, including the “boundary” value.
Range
When using the “Range” aggregation method, Flow determines the maximum and the minimum values
of all the points within the time period, including the “boundary” value, and then returns the difference
between the maximum and the minimum.
4.2 Collect. Calculate. Visualize 55
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
First
When using the “First” aggregation method, Flow will return the “boundary” value.
Last
When using the “Last” aggregation method, Flow will return the value of the last point before the end
of the time period. If a point falls exactly on the end of the time period (i.e. 07:00:00), it will be excluded
from the evaluation.
Delta
When using the “Delta” aggregation method, Flow will sum the difference between each consecutive
point, including the “boundary” point.
Count
When using the “Count” aggregation method, Flow will return the number of points within the time
period, excluding the “boundary” point.
Time in State
When configuring Flow to return a “Time in State” summary, you will need to specify the “State” setting
and condition. Flow will return the total duration (in milliseconds) that the “Stair Step” interpolation
evaluates to the specified “State” setting and condition. For example, in the above scenario, if the
“State” setting is specified as “=” 1.6, Flow will sum the duration between the “boundary” point and
point 2, and the duration between point 9 and point 10.
Variance
When using the “Variance” aggregation method, Flow will calculate the statistical population variance
for all the data points within the time period, including the “boundary” point.
Standard Deviation
When using the “Standard Deviation” aggregation method, Flow will calculate the statistical population
standard deviation for all the data points within the time period, including the “boundary” point.
4.2 Collect. Calculate. Visualize 56
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Counter (Totalizers)
The “Counter” aggregation method is applicable to totalizers only. For this aggregation type, let’s look
at a different set of data:
Point Timestamp Raw Value
1 05:55:03 1
2 06:03:23 1.7
3 06:07:30 1.9
4 06:10:22 2
5 06:15:52 2.3
6 06:20:40 2.5
7 06:25:13 2.8
8 06:29:44 3.2
9 06:35:14 0
10 06:41:14 0.2
11 06:46:03 0.4
12 06:52:35 1
13 06:55:26 1.4
14 07:05:40 2.3
When we plot this “totalizer’s” points, and then apply the “Stair Step” interpolation, we get the
following result. Notice the totalizer’s reset point.
4.2 Collect. Calculate. Visualize 57
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow will sum the difference between each consecutive point, including the “boundary” value, until it
detects a negative change. If the negative change is greater than the “Deadband” setting, Flow
interprets this as a totalizer reset, and then continues summing the difference between following
consecutive points.
The Flow “Counter” aggregation method will handle multiple totalizer resets in any single time period. Null values
returned by the Data Source will be ignored in the “Counter” aggregation algorithm.
Counter Rollover
A totalizer is often configured in the instrument or in its controller to always reset at a specific value.
This specific value is known as the “Rollover” value.
Due to the nature of slight delays in data historization, it is possible that the raw data will not include a
point at exactly the rollover value, but rather a value slightly before, and slightly lower than the rollover
value.
For example, if this totalizer reset at exactly 3.5, Flow would “miss” 0.3 counts (3.5 rollover – 3.2 point 8).
Fortunately, Flow allows the configuration of a “Rollover” setting. When calculating the “Counter”
aggregation for a time period, Flow will use this “Rollover” setting to include the “missed” counts.
Custom Expression
Some Data Source types provide the ability to configure a “Custom Expression”, rather than using one
of the standard aggregation methods. Custom expressions allow for the querying of more than one tag
from the data source.
4.2 Collect. Calculate. Visualize 58
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
The results of the query are transposed into a “data” object that returns a set of columns containing
the tag values and qualities. The custom expression uses Microsoft.NET’s C# syntax. A single “Result”
object must be returned by the custom expression.
The custom expression must be validated before being saved.
Custom expressions can be used for custom calculations (e.g. integrate one tag by another), lookups
(e.g. convert the returned values based on a lookup table), etc.
4.2 Collect. Calculate. Visualize 59
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 10: Create a Manually Entered Measure
You are going to create a measure for the expected output of the Boiler. The Boiler has been designed
to produce 14.5 metric tons per hour.
Drag the “Hourly” icon from the Flow Zone onto the
“Steam” metric.
Rename the new Manually Entered measure to “Steam
Production Rating”. Notice the icon indicates the Measure
Type (i.e. manual).
General Properties
Double-click the new measure and edit the general properties as follows:
4.2 Collect. Calculate. Visualize 60
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Retrieval Properties
Expand the “Retrieval” section. Notice that the “Retrieval” section is different for a Manually Entered
Measure compared to a Retrieved Measure. A Manually Entered Measure is configured to have a
“Default Value”. Just like an hourly Retrieved Measure, Flow will generate an hourly time period for an
hourly Manually Entered Measure. The value for each of these time periods depends on the “Default
Value” setting.
Let’s discuss the “Default Value”: options
Set to previous value – Flow will set a new time period’s value to the value of the measure’s previous
time period. An “Initial Value” setting tells Flow what the first time period’s value will be set to.
This option is useful for calculation factors you may want to change over time, but not too
frequently.
Set to 0 – Flow will set a new time period’s value to 0.
Set to null – Flow will set a new time period’s value to a null (empty) value. This option is useful
when creating a measure for an instrument or value that needs to be inserted manually by a person
every time period (e.g. daily electricity reading from an external meter).
Set to measure value – Flow will set a new time period’s value to the value of another Flow measure
at the same point in time. This option is useful when you need to, for example, set an hourly
measure’s value to that of a weekly measure.
For your new “Steam Production Rating (tons/hr)” measure, set the “Default Value” setting to “Set to
previous value” and the “Initial Value” setting to 14.5 as follows:
4.2 Collect. Calculate. Visualize 61
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Deploy the new measure and confirm that it is running and producing a value of 14.5 tons/hr every
hour:
4.2 Collect. Calculate. Visualize 62
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 11: Scaling Factor
Now that you have a measure specifying the Boiler’s design rating, you are going to create a Retrieved
Measure for the Boiler’s actual production.
Locate the 010-FT-001.PV Boiler Steam Output tag from the Historian, drag it across to the Model View,
and drop it onto the “Steam” folder. Rename the new Retrieved Measure to “Steam Production”.
Double-click the new measure …
Notice the unit of measure has been set to kg/s since this is the engineering unit of the 010-FT-001.PV
tag in the Historian. You need to compare the Boiler’s design rating in tons/hr to the Boiler’s actual
output. To do this you are going to convert the actual output from kg/s to tons/hr, and you are going
to use the “Scaling Factor” to achieve this.
The “Scaling Factor” is a multiplier applied to the summary value retrieved from the data source. The
multiplied summary value is then stored in the Flow System.
Configure the following:
Unit – tons/hr
Scaling Factor – 3.6
Deploy the new measure. Confirm that it is retrieving and scaling a summary value from the Historian.
4.2 Collect. Calculate. Visualize 63
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 12: Create a Calculated Measure
Now that you have a measure for the Boiler’s actual production (tons/hr) and a measure specifying the
Boiler’s design rating (tons/hr), you can do the necessary comparison to determine how well your Boiler
is performing.
However, Flow allows you to create calculations based on other measures within your Flow System.
You are now going to create a Calculated Measure that indicates the Efficiency (%) of the Boiler against
its design rating.
Let’s first set your default measure Format and Unit of Measure (UOM) on the “Defaults” toolbar …
Drag the “Steam Production (tons/hr)” measure onto the Flow Zone Calculator icon …
Flow will create and configure a new Calculated Measure. Rename it to “Steam Production Efficiency”.
You will notice the red disk displayed on the new measure’s icon. This indicates that it has a problem.
Hover your cursor over the measure to see a message, “Calculation has not been validated”. This is
4.2 Collect. Calculate. Visualize 64
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
normal after creating a new Calculated Measure. You need to open the measure’s editor and expand
the “Retrieval” section …
For a Calculated Measure, the “Retrieval” tab displays two sections:
Dependents – the calculation dependents are displayed on the left. Calculations in Flow are defined
by a Date and Time from which the calculation is valid. Additional calculations can be added to the
dependency tree, as long as they have a different Date and Time. This mechanism provides the
ability to change calculations over time, but not lose the ability to backfill a measure to a time when
a different calculation was used.
Expression – the expression on the right is the actual calculation, which is defined using
Microsoft.NET’s C# syntax. Flow simplifies the “writing” of the expression by supporting double-
click and drag ‘n drop into the expression.
You will see the “Steam Production (tons/hr)” measure has already been added to the dependency
tree. Drag the “Steam Production Rating (tons/hr)” measure from the Model View onto the Date and
Time in the dependency tree.
4.2 Collect. Calculate. Visualize 65
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now edit the expression as follows to calculate the Efficiency of the Boiler as a percentage. After placing
your cursor in the expression, you can double-click the measure in the dependency tree to place the
relevant text into the expression at your cursor position. Alternatively, you can drag the measure from
the dependency tree into the expression.
Once you are happy with your calculation’s expression, click the “tick” button to validate the expression.
If there are no problems with your expression, Flow will save it and you will notice the red disk
disappears.
Deploy the calculated measure and confirm that it is generating a percentage for the Boiler’s Efficiency.
4.2 Collect. Calculate. Visualize 66
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Notice that the calculation expression makes use of the “.Value” property of a measure. The “Insert” button
allows you to use other properties of a measure (i.e. “.Quality”, “.Duration” in milliseconds, “.PeriodStart” and
“.PeriodEnd”)
Calculation “Date and Time”
You will notice in the calculation dependency tree that a calculation’s dependents and expression is defined by a
date and time. This represents the date and time from which this calculation is valid.
This functionality allows for calculations to change over time (i.e. water reticulation calculation changes because
of a new meter installation), but still maintain data integrity during a measure “backfill”.
4.2 Collect. Calculate. Visualize 67
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 13: Create a User Defined Function
Select the “Toolbox” tab at the bottom of the Information Model. Expand the “Functions” folder. Flow
includes a number of built-in functions similar to what you would find in Excel. These functions can be
used in the expressions of calculated measures.
In addition to the built-in functions, Flow allows you to create your own User Defined Functions. Right-
click on “User Defined” and click “New”, “Function”. Name the new function “Efficiency”. Double-click
on it to open its editor …
The function “Definition” is a standard Microsoft.NET C# static method. Don’t be scared of it, just type
it out as shown above.
Click the “tick” button to validate the “Definition”. If there are any problems, Flow will provide an error
message to explain what you have done wrong.
Using a Function in a Calculated Measure
Now that you have created your own User Defined Function for calculating Efficiency, let’s go back to
the Calculated Measure you created for “Steam Production Efficiency (%)” and edit its calculation
expression to rather use your new function.
4.2 Collect. Calculate. Visualize 68
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Open the “Steam Production Efficiency (%)” measure and expand the “Retrieval” section. Undeploy
the measure. Delete the expression. Drag the “Efficiency” function from the “Toolbox” into the
expression editor.
Select the text “double Actual” and double-click the “Steam Production (tons/hr)”. Flow will replace
the selected text with the measure’s name and value property. Do the same for the “double Rating”
and validate your new expression.
Redeploy your Calculated Measure.
4.2 Collect. Calculate. Visualize 69
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 14: Create an Aggregated Measure
At this stage you have 4 measures configured and deployed in your Flow System. However, these
measures only collect or calculate summary information for every hour. What if you wanted to
summarize and report information for daily time periods?
As discussed on page 52, Aggregated Measures are used to perform roll up calculations of other
measures in your Flow System. Let’s use an Aggregated Measure to roll up the hourly summary
information into daily information.
Drag the “Steam Production Rating (tons/hr)” measure from the
Model View onto the “Daily” icon of the Flow Zone.
Flow will create a new daily “Steam Production Rating (tons/hr)”
measure. Notice the icon indicates the Interval (i.e. daily) and
the Measure Type (i.e. aggregated Δ).
General Properties
Double-click the new measure and notice the general properties have been copied from the hourly
“Steam Production Rating (tons/hr)” measure. Because this is a daily measure, change the “Unit” to
“tons/day” as follows:
4.2 Collect. Calculate. Visualize 70
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Retrieval Properties
Expand the “Retrieval” section. Notice that the “Retrieval” section is different for an Aggregated
Measure.
Measure – this is the measure Flow will roll up (i.e. aggregate) to create new summary information.
To change this measure, drag another measure from the Model View onto this setting.
Aggregation – this is the aggregation method Flow will use to calculate the roll up. Flow will default
to “Sum”, but available aggregation methods include “Average”, “Minimum”, “Maximum”,
“Range”, “First”, “Last” and “Counter”.
Interval – this is the “boundary” interval Flow will use to calculate the roll up summary information.
This property can be changed when cumulative roll up calculation are required (e.g. “Week to
Date”, or “Month to Date”, etc.)
Scaling Factor - this is a multiplier applied to the result of the aggregation. This is useful when you
need to present an aggregated value in a different Unit of Measure (e.g. the hourly measure can
be kWh, but the monthly aggregated value should be in MWh).
Deploy the new measure and confirm that it is running and producing a value of 348.0 tons every day:
4.2 Collect. Calculate. Visualize 71
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now create daily Aggregated Measures for “Steam Production (tons/day)” and “Steam Temperature
(˚C)”. For the daily “Steam Temperature (˚C)”, make sure you change the “Aggregation” property to
“Average”, not “Sum”. It would not make sense to sum the hourly average temperature summaries!
4.2 Collect. Calculate. Visualize 72
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 15: Create a Time-based Report
Now that you have a few deployed measures in your Model, all automatically collecting and
summarizing data from your Historian, let’s see how we can “see” this summarized information.
Select the “Reports” tab. This is where you are going to create an “Information” model that represents
the audience (or consumers) of your Flow System’s information. The Boiler information you have
configured in your Flow System would typically be useful for the Engineering or Utilities Managers.
Create a new folder in the “Reports” tab for “Engineering”. Now create a new “Hourly Report” in this
folder (you can do this by dragging the “Hourly” icon from the Flow Zone, or by right-clicking on the
folder) …
Double-click the new report definition to open its editor …
General Properties
The top section of the Report Editor displays a few general properties:
Title – this is the report title. By default Flow uses a “placeholder” for the name of the report. This
can be edited to a fixed title or a combination of the placeholders and fixed text.
Description – report description.
4.2 Collect. Calculate. Visualize 73
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Report Type – various types of reports can be configured. Depending on which type is selected,
different report definitions need to be provided. See the Understanding Report Types section on
page 79 for more explanation on the various report types.
Period
The “Period” section of the report definition provides information about the default period that a report
will display:
Calendar – which calendar should be used to present the information
Default Period – either “Start of Period” or “Moving Window”, then specify a number of intervals
and finally the interval type.
Definition
This section is used to define what needs to be presented in the report. A Flow report is made up of
one or more Report Sections. A Report Section contains one or more measures. Let’s build the report
definition:
Right-click in the “Definition” section and click “New Section” (or drag a folder from the Flow Zone).
Name the new section “Boiler”. Now drag the “Steam” metric from the Model View and drop it onto
the “Boiler” section …
Flow adds the hourly measures from the metric to the “Boiler” section. Individual measures can also
be dragged to a Report Section.
4.2 Collect. Calculate. Visualize 74
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Opening a Report
Right-click on your report in the “Information” model, and select “Tasks\Open” to view the report in
your default web browser.
Your report definition should appear as follows in the Chrome browser:
Notice how the structure of the visualization matches the structure of the report definition (i.e. Sections
and Measures).
Let’s change a few properties in the report definition. Open the “Engineering Hourly Report” definition
again.
Change the “Default Period” to “Moving Window” of 1 “Day”.
In the “Boiler” section, delete the “Steam Production Rating (tons/hr)” measure (right-click and
“Delete”). Flow will remove the measure from the report definition, but not from the Model View.
4.2 Collect. Calculate. Visualize 75
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
In the “Boiler” section, move the “Steam Temperature (˚C)” measure to the bottom of the section
(right-click and “Move Down”).
Notice the differences when you refresh your visualization. The table has more data because it is
defaulting to a “moving window” of 24 hours. The order of the measures in the “Boiler” section has
been updated …
Click on the measure “Steam Production” to open a graphical “quick view” of the data. Notice how a
chart of the data is presented as an overlay. You can configure a “Line” (default) or “Bar” chart by
setting the “Chart” property of the measure in the report definition.
Click on an individual cell to drilldown to its Details, insert Comments and view any other version
information relating to that value. In this example, the inputs to the efficiency calculation are provided
for clarity. Further drilldown is possible by clicking on the cells in the Detail.
4.2 Collect. Calculate. Visualize 76
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
4.2 Collect. Calculate. Visualize 77
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Deploying a Report
If you are using the default “Flow Report Server”, this step is done automatically for you. However, if
you are using one of the Report Server plugins (e.g. SQL Server Reporting Services), you will need to
manually deploy your reports to the respective report server. Select the “Deployment” view tab at the
bottom of the Model View and expand your report server component …
The report server contains a number of “visualization” templates. Drag your report definition onto a
compatible template …
Right-click on the “deployed” report, click “Tasks”, “Open” …
Flow will open a visualization of your table report definition in your default web browser.
4.2 Collect. Calculate. Visualize 78
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Understanding Report Types
Flow provides a number of report types, for both Time-based reports and Event-based reports. Time-
based report types will be discussed here.
Table
Use this report type to provide detail. This is similar to a spreadsheet view of your data.
Additional functionality available in a Table report includes:
Chart “Quick View” – clicking the name of a measure in the report will open a Chart overlay
Cell “Drilldown” – clicking an individual cell will open a Drilldown overlay providing details of
that measure value (calculation inputs, comments and versions)
Doughnut
Use this report type to indicate the proportion of an attribute (e.g. Product) that makes up the whole:
This Doughnut chart has been made up of one Section containing two Measures. You can add more
Sections to create additional rows, or more measures to create additional columns.
4.2 Collect. Calculate. Visualize 79
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Gauge
Use this report type to provide a visual of key performance indicators (KPIs). When configuring each
measure in the Gauge report type, set the minimum and maximum values. The start of each gauge is
at the top of the circle. Limit display can be configured.
This Gauge chart has been made up of two Sections containing two Measures each, hence the two by
two grid.
Scatter Plot
Use this report type to correlate one measure against another. Configure measures on the X and Y
axes. Optionally, use a third measure for the size of the bubble plotted.
4.2 Collect. Calculate. Visualize 80
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Time Series
Use this report type to display measure values on time series charts. Line, bar and stacked bar charts
can be configured.
Additional functionality available in a Time Series chart includes:
Item “Drilldown” – clicking an individual point or bar will open a Drilldown overlay providing
details of that measure value (calculation inputs, comments and versions)
Widget
Use this report type to display a single value for a set of measures’ last values. This is useful for
displaying key performance indicators on auto-updating dashboards.
4.2 Collect. Calculate. Visualize 81
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 16: Create a simple Dashboard
Now that you have your first report defined and deployed, let’s create a dashboard and add this report
as a panel on the dashboard.
A Flow Dashboard is a great way to pull multiple views of your information together, into a single place
that can be monitored at a glance.
In the “Reports” tab, right-click on the “Engineering” folder and click “New\Dashboard”. Flow will
create a new “Engineering Dashboard”. Open its editor …
General Properties
The top section of the dashboard editor displays a few general properties:
Title – this is the dashboard title. By default Flow uses a “placeholder” for the name of the
dashboard. This can be edited to a fixed title or a combination of the placeholder and fixed text.
Description – dashboard description.
Panels
The “Panels” section is a grid canvas which is always 12 blocks wide. By default, Flow displays 6 blocks
of height, but the height can be increased by dragging a panel to a larger size.
4.2 Collect. Calculate. Visualize 82
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Drag the “Engineering Hourly Report” onto the dashboard canvas …
Dropping the “Engineering Hourly Report” onto the top left block of the canvas, Flow automatically
expands the new panel to all the available canvas space below and to the right of where you dropped
it. The panel’s “handles” can be used to resize it as required. In the labs that follow, you will need to
resize these panels to be able to fit other panels onto the dashboard.
4.2 Collect. Calculate. Visualize 83
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Panel Properties
Each panel on the dashboard has the following properties:
Panel Title - this is the panel’s title. By default, Flow uses a “placeholder” for the name of the report
in this panel. This can be edited to a fixed title or a combination of the placeholder and fixed text.
Panel Link – this is the URL for a “Web Page Panel” (see “Web Page Panel” below).
Refresh – this is the period on which the panel will automatically refresh itself. Flow defaults this
property to 300 seconds (5 minutes).
Web Page Panel
If you right-click on the dashboard canvas, you can add a “Web Page Panel” by clicking “New”, “Web
Page Panel”. A “Web Page Panel” will display the contents of any URL configured in the “Panel Link”
property.
Open the Dashboard
Similarly to the Report, right-click and select “Tasks”, “Open” …
4.2 Collect. Calculate. Visualize 84
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
This simple dashboard demonstrates the canvas and panel functionality. Notice how a panel has a “title
bar” at the top. The “title bar” can be removed by setting the panel’s “Title” property to blank (empty).
4.2 Collect. Calculate. Visualize 85
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Report and Dashboard Permissions
Where required, reports and dashboards can be allocated user permissions. These permissions are
controlled using user groups.
Users and Groups
On the Model View, select the “Users” tab. This view allows you to add users and groups to your Flow
System.
By default all new users belong the “Everyone” group. Any users
who sign in to the Flow Report Server will be added to the
“Everyone” group.
Add a User
Flow makes use of your Active Directory users for permissions. To
add a new user, right-click on a group and select “New User”,
“Windows User”. Use the “Select Users” dialog box to find one or
more users registered on your domain to add to your Flow System.
Flow makes use of “Message Recipient” users for the Flow
Messaging System. These users are not used for permissions on
Reports and Forms. See Messaging System on page 126.
Add a Group
To add a new group, right-click and select “New Group”. Edit the
name of the group.
Link Users to Groups
Users can be linked to groups by dragging them from the
“Everyone” group onto the destination group. Alternatively, right-click on the destination group and
select “New User”. Users can belong to more than one group.
Assigning Groups to Folders
Once you have created groups and assigned users to them, these groups can be assigned to Folders in
the “Information” view. Double-click on a folder in the “Reports” tab to open its editor:
4.2 Collect. Calculate. Visualize 86
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
By default, every folder has “Allow” access assigned to the “Everyone” group. Assign “Allow” access to
other groups by dragging them into the “Allow” section of the folder editor. Note that as soon as a
group other than “Everyone” is added to the folder, the “Everyone” group is removed:
When groups are assigned to folders, the reports and dashboards belonging to those folders will only
be accessible to users that belong to the assigned groups.
Folder Permission Inheritance
Folders inherit “Allow” access groups from their parent folders in the “Information” view. A child folder
can be assigned additional groups that do not belong to their parent folders (e.g. Utilities is a child
folder to the Engineering folder):
4.2 Collect. Calculate. Visualize 87
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 17: Create a Measure Limit
Now that you have a simple report and dashboard, let’s use some visualization best-practice (page 9)
and indicate an “out of limit” value using color.
Flow allows you to set up one or more limit definitions. These limits can be used for various functions
(i.e. targets not achieved, data validation checking, bonus target achieved, etc.)
In the Flow “Toolbox”, under “Limits”, right-click on “Simple” and select “New”, “Limit”. Name the new
limit “Site Target”.
Open the new limit’s editor …
You will notice the only thing that can be edited on the limit is the “High”, “Low” and “Target” colors
that will be used in the reports.
Add the Limit to a Measure
Open the “Steam Temperature (˚C)” measure from the Model View. Now that the “Site Target” limit
has been defined, you will notice a new section called “Limits” in the measure editor. Expand this
“Limits” section, right-click and select “Add Limit”, “Site Target”. Alternatively, you can drag the “Site
Target” limit into the measure’s “Limits” definition.
Right-click the “Site Target” and click “Add Instance” …
4.2 Collect. Calculate. Visualize 88
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
The instance of a Limit is defined as a Date and Time from which the Limit is valid. Additional instances
of this Limit can be added, as long as they have a different Date and Time. This mechanism provides
the ability to change Limits over time, but not lose the ability to backfill a measure to a time when a
different Limit was used.
The instance of the Limit in the Measure is where you will define your Target, High and Low values for
this specific Measure. Flow will evaluate each value retrieved or calculated for the Measure against the
High and Low values. If the High and/or Low values are exceeded, an “exception” will be generated.
The Target value is used for reporting only.
For this “Steam Temperature (˚C)” measure, set the Target to 94.5, set the Low to 94.5, and set the
High to 101.0. If Flow detects any values below 94.5 (i.e. the Low setting) or any values above 101.0
(i.e. the High setting), an exception will be generated.
A High or Low setting can be left blank to exclude it from being evaluated.
Right-click the Limit instance and select “Backfill”. Flow will start evaluating existing summary values
for this measure.
Add the Limit to a Report Measure
In the background, Flow flags a measure’s values when they exceed a limit. In order to “see” these
exceptions, you will need to configure the measure on a report to “show” this Limit’s exceptions. Open
the “Engineering Hourly Report”, expand the “Boiler” section and select the “Steam Temperature (˚C)”
measure. Update its “Limit” property to “Site Target” …
4.2 Collect. Calculate. Visualize 89
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now open your “Engineering Dashboard” from the “Deployment” View …
Notice the High and Low colors coming through on the report. Notice the Target displayed as well.
Linking another Measure to a Limit Value
When configuring limit values for a Measure, Flow allows you to “link” another Measure’s values to the
High, Low and Target properties. For example, you could drag a Measure from the Model onto the
High property:
In this example, the value retrieved for “Steam Temperature (˚C)” for a specific time period will be
evaluated against the value of the manual measure “Steam Temperature High (˚C)” for that same time
period.
4.2 Collect. Calculate. Visualize 90
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
“Linked” limits are useful in the following scenarios:
Frequently changing limits – rather than changing a Measure’s limit configuration frequently, rather
create a manual Measure to “store” the limit value. Link the manual Measure to the limit, and then
create a Form where users can update the manual Measure as and when required. See the Lab on
forms for data entry on page 92.
Cumulative Targets – when tracking progress during a time period (e.g. every hour during the
production day), create a cumulative target Measure to use as a linked limit against a cumulative
production Measure. In this example, the straight line is the cumulative target during the day. At
11:00, there was excessive use of water, thus sending the cumulative water usage over the limit,
but the team ended the day within their daily usage target.
4.2 Collect. Calculate. Visualize 91
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 18: Create a Time Period Form for Data Entry
It is not always possible to retrieve information automatically from a data source. Some information is
just not available in a data source. For this reason, Flow can be used to define data entry forms for the
manual capture of information into your Flow System by people. There are two types of data entry
forms, Time Period forms and Event Period forms. This lab will focus on Time Period forms.
Examples of where you would use a Flow Form to manually enter information include:
Instrument data that isn’t available in your control systems and historians
Calculation factors that you will want to change over time
Flow Forms can also be used to validate and modify retrieved data. This is important in any reporting
system, since there will always be times where systems fail and hence provide incorrect data. For
example, you may be collecting summary information for a Mixing Tank Level by retrieving data from a
level transmitter tag in your Historian (e.g. 101-LT-001.PV). What happens if that level transmitter is
removed from service for maintenance or re-calibration? During the time that it is out of service, the
Retrieved Measure in Flow would have no data to summarize. However, an estimated value could be
inserted by a person, with a comment if required.
Let’s create a Time Period Form for your Boiler. Select the “Forms” tab at the bottom of the
“Information Model” view. Similarly to the “Reports” tab, you can create a structured model to
organize your forms.
Create a new folder in the “Forms” tab for “Engineering”. Now create a new “Time Period Form” in this
folder by right-clicking on the folder …
Double-click the new form definition to open its editor …
4.2 Collect. Calculate. Visualize 92
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Definition
A Flow Form consists of one or more “tabs” (similar to “sheets” in an Excel workbook). A tab then
contains one or more measures. Let’s build the form definition:
Right-click in the “Tabs” section and click “New Tab” (or drag a folder from the Flow Zone). Name the
new tab “Boiler”. Now drag the “Steam” metric from the Model View and drop it onto the “Boiler” tab.
Flow adds all the measures from the metric to the “Boiler” tab. Individual measures can also be dragged
to a Form tab.
View the Form and Edit Data
Now that you have defined a Flow Form, open the “Flow Server” in a supported browser (i.e. Chrome,
Edge, Safari, etc.). Before you have signed in, you will only see the Dashboards and Reports accessible
to everyone. You will need to sign in before you can see any Forms.
4.2 Collect. Calculate. Visualize 93
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Authentication
Click the “Sign In” button to authenticate with the Flow Server:
After signing in you should now see the Flow Forms:
4.2 Collect. Calculate. Visualize 94
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now click on the “Engineering Form” in Forms section of the menu.
Flow Form Orientation
A Flow Form provides the familiarity of a spreadsheet. Notice how the structure of the form follows
the structure of the form definition you created earlier.
Even though your “Boiler” tab configuration included hourly and daily measures, Flow will only display
the measures as per the “Interval Selector”.
4.2 Collect. Calculate. Visualize 95
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Entering Data
After selecting a cell, you can start typing a value to insert or update data. Select one of the hourly
“Steam Production Rating” cells and edit its value to 14.8 (press enter to accept the new value).
Data Quality Indicator
Where measure values have a bad quality, you will notice a red disk in the cell. This provides a visual
indicator of suspect or bad quality data.
If you have bad quality data, but you’re actually satisfied with the value, you can “Accept” the value and
Flow will set its quality to good. Double-click on the cell to display its details, select the “Version” tab
and hover over the version with the bad quality.
Notice the “Accept” tick button. Clicking this button will create a new version of value, but with a good
quality. Notice the new version is set to the “Preferred” version. This instructs Flow to use this value
for any calculations and for display on reports and dashboards. The date and time of the version change
is also recorded against the user that made the change.
4.2 Collect. Calculate. Visualize 96
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Dependent Measures
Select the “Steam Production Efficiency” measure. Notice that the selection border is black, not green.
This means that this cell cannot be edited. The reason for this is that it is a calculated measure, which
depends on the values of other measures in the Flow System.
In this case, the efficiency measure is calculated from the “Steam Production Rating” and the actual
“Steam Production”. Edit the “Steam Production” value to 14.8, wait a few seconds for the Flow Engine
to recalculate the efficiency and click the “Refresh” button. Notice how the calculated measure has
been updated correctly.
4.2 Collect. Calculate. Visualize 97
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Entering Comments
Double-click on the cell you edited and enter a comment explaining why you needed to change that
value.
Press enter to save the comment:
Flow allows more than one comment to be entered for each measure value. Notice in the form, any
cells that have one or more comments will display a gray disk.
Form Permissions
Similarly to the group based permissions applied to Reports and Dashboards (see page 86), the same
group based permissions apply to Form folders.
4.2 Collect. Calculate. Visualize 98
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 19: Create an Event
Up until now, you have used Flow to retrieve, calculate and report on time period summary information.
As described on page 19, Flow also understands event periods, allowing the association of additional
contextual information overlaid onto the summary information.
Locate the “FL001.State” (Filler 1 State) tag in your Historian. Double-click on it to open the Data Source
Preview …
Zoom out to show about 15 hours of detailed data. Notice the Filler 1 cycles through a pattern of states.
The states are:
0 = Idle
10 = Setup
20 = Running
30 = CIP
Flow can be used to automatically detect the start and end of event periods. Let’s define an event that
starts when the Filler state changes to 10 (“Setup”) and ends when the Filler state changes to 30 (“CIP”).
4.2 Collect. Calculate. Visualize 99
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Drag the Event icon from the Flow Zone onto the “Filler 1” folder …
By default the new metric will take on the name of its parent folder.
Rename this event to “Filler 1 Run”.
Event Editor
Double-click on the new event to open its Editor …
General Properties
The top section of the Event Editor displays a few general properties for the Event:
Description – Event description.
Refresh Offset – this is the number of seconds before “now” that Flow will start querying the
Historian data. Flow defaults this property to 0 seconds.
Backfill – the date and time used by the Engine to go back in history and retrieve the event period
information from the Historian.
Triggers
The event triggers define how Flow determines the start of an event and the end of an event. Locate
the “FL001.State” tag in the Historian and drag it into the “Triggers” section …
Flow creates a “Start Trigger”. Notice Flow has created a link to the “FL001.State” tag and setup the
default “Trigger” condition properties. Let’s discuss these trigger properties:
4.2 Collect. Calculate. Visualize 100
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Tag – this is the tag Flow will monitor in the data sources and evaluate against the “Trigger”
condition properties.
Trigger – this defines the type of condition Flow will use to detect the trigger event.
Condition – this tells Flow how to evaluate the tag’s value against the “Condition Value”.
Condition Value – this is the value Flow evaluates the tag’s value against to determine whether an
event is triggered.
For the “Start Trigger”, set the trigger “Condition Value” to 10. Flow will use this to start a new event
period when it detects the tag’s value is equal to 10 (“Setup” state).
Now drag the “FL001.State” tag onto the “Triggers” section again …
Flow creates an “End Trigger”. Set this trigger’s “Condition Value” to 30 (“CIP” state).
Deploy the Event and open the “Triggers” diagnostic chart window. Refresh the diagnostic chart and
confirm that event periods have been detected and created by Flow.
Note: If you create an Event with no triggers, you will need to create a “Event Period” form to manually insert
event periods.
4.2 Collect. Calculate. Visualize 101
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 20: Create an Enumeration
Before you configure your new Event any further, let’s discuss Flow Enumerations. An Enumeration is
a set of ordinals that map integer values to string values. Think of Enumerations as “Lookups”. For
example, in your Historian, you have an integer tag called “FL001.Product”. Locate this tag and open
it …
Zoom out to view a day or two of detailed data. You will notice the “FL001.Product” tag value changes
between 0 and 4. 0 represents an “Idle” state for the Filler, but 1 to 4 represent the various products
or brands that your Juice Factory produces:
1 = Apple
2 = Grape
3 = Orange
4 = Raspberry
Let’s create a Flow Enumeration for the Filler Product. Select the “Toolbox” tab, right-click on
“Enumerations” and click “New”, “Enumeration”. Name your new Enumeration “Filler Product”, and
open its editor …
4.2 Collect. Calculate. Visualize 102
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
In the “Ordinals” section, right-click and select “New”. Flow will create a new ordinal for the integer
value 1. Let’s discuss the Ordinal’s properties:
Ordinal – this is the integer value that Flow associates with the ordinal’s string “Value”.
Value – this is the string value that is mapped by Flow for the ordinal.
Color – this is the color associated with the ordinal. The color will be used for reporting purposes.
The color is defined as a hexadecimal color code (see www.color-hex.com for color palettes).
Description – this is the ordinal’s description.
Set Ordinal 1’s “Value” to “Apple”.
Now add 3 more ordinals for “Grape”, “Orange” and “Raspberry”.
We are going to use this Enumeration to create an Event Attribute in the next lab.
4.2 Collect. Calculate. Visualize 103
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 21: Add Attributes to an Event
Event Attributes are additional pieces of information that can be associated with each event period
created manually or generated by Flow. These additional pieces of information, when associated with
event periods and overlaid onto time periods, provide context rich information that support decision
making and provide insight.
An Attribute can either be “Retrieved” from a data source, or “Manually Entered” by a person on an
Event Period form.
Let’s add context to the “Filler 1 Run” Event you created earlier. Open the “Filler 1 Run” Event and
expand the “Attributes” section. Undeploy your Event so that you can make configuration changes to
it. Right-click in the “Attributes” section and select “New”, “Attribute”, “Retrieved”. Name your new
Attribute “Product”:
Locate the “FL001.Product” tag in your Historian and drag it onto the “Product” Attribute.
4.2 Collect. Calculate. Visualize 104
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow creates a new attribute “Segment” named “FL001.Product” …
For the properties of this segment, change the “Enumeration” property to “Filler Product”.
Segments
A “Retrieved” Event Attribute can be made up of one or more Segments concatenated together. The
following Segment types are available:
Retrieved – the value of the segment is retrieved from a Data Source. If the retrieved value is an
integer, the segment can be linked to an Enumeration to map the integer values to string values.
Constant – this is a constant string that can be added as part of an Attribute. This is useful for
generating Attributes for Batch Numbers.
Period Start – this segment uses the start date and time of the event period. Use the “Format”
property to change the way you want the date and time to be displayed.
Period End – this segment uses the end date and time of the event period. Use the “Format”
property to change the way you want the date and time to be displayed.
Period Index – this segment uses a unique Index that Flow assigns to each event period created (see
section below).
Index
Every event period created by Flow for an Event will generate a unique Index identifier. This Index auto-
increments every event period. Expand the “Index” section of the “Filler 1 Run” Event …
There are a few properties that can be defined for an Event’s Index:
Initial Value – this is the initial value that will be used the first time the Event is deployed (or, the
first value that will be used of an Index “Reset”).
Reset using – this specifies the Calendar to be used when applying a “Reset” rule to the Index.
Leaving this blank will ensure the Index will never reset.
Reset interval – this specifies how often the Index will reset using the above Calendar.
4.2 Collect. Calculate. Visualize 105
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Use Attributes to generate additional Context
By making use of the Attribute Segments, you can actually generate information without the need to
access your data sources. For example, your Historian does not provide any data relating to the Work
Order being run by your Filler. Let’s create a “Work Order” Attribute for your “Filler 1 Run” event.
Create a new “Retrieved” Attribute called “Work Order”, and add the following Segments to it:
Constant “FL001”
Period Start formatted to “yyyy” (i.e. only the year)
Period Index formatted to “0000” (i.e. always 4 digits)
Deploy your “Filler 1 Run” event again, open the diagnostic grid on the Attributes and confirm the
attribute values coming through for each event period:
Notice how the “Product” attribute has been mapped to a string value for the product.
Notice how the “Work Order” attribute has been made up of:
“FL001” + Period Start (yyyy) + Period Index (0000) = “FL00120150141”
4.2 Collect. Calculate. Visualize 106
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 22: Create an Event-based Report
Now that you have a deployed an event in your Model, automatically collecting event periods and
summarizing data from your Historian, let’s create an Event Report to “see” this information.
Select the “Reports” tab. Create a new folder in the “Reports” tab for “Packaging”. Now create a new
“Event Report” in this folder (you can do this by dragging the “Event” icon from the Flow Zone, or by
right-clicking on the folder) …
Double-click the new report definition to open its editor. Set the “Default Period” to start at the
beginning of the Production week. Create a new Section called “Filler 1” in the Definition. Drag your
“Filler 1 Run” Event onto the “Filler 1” Section …
4.2 Collect. Calculate. Visualize 107
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Right-click on the report, click “Tasks”, “Open”. Flow will open a visualization of your event report:
Notice how the structure of the visualization matches the structure of the report definition (i.e.
Sections, Events and Event Attributes).
Let’s change a few properties in the report definition. Open the “Packaging Event Report” definition
again.
In the “Filler 1” Section, select the “Filler 1 Run” event and set its “Description” property to “Work
Order”. Set the “Identifier” to “Work Order”.
In the “Filler 1” Section, right-click the “Work Order” Attribute and click “Delete”. This will remove
it as a column in the event report.
Notice the differences when you refresh your visualization. The Index column has been replaced by the
“Work Order” column as an identifier, and the “Work Order” attribute column has been removed.
4.2 Collect. Calculate. Visualize 108
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 23: Create an Event Period Form
In a previous lab, we created a Time Period form for the manual entry of data. This lab will focus on
the creation of Event Period forms which can be used to edit or even insert event periods and
associated context into Flow.
Let’s create an Event Period Form for your Filler. Select the “Forms” tab at the bottom of the
“Information Model” view. Create a new folder in the “Forms” tab for “Packaging”. Now create a new
“Event Period Form” in this folder by right-clicking on the folder …
Double-click the new form definition to open its editor …
Definition
Right-click in the “Tabs” section and click “New Tab” (or drag a folder from the Flow Zone). Name the
new tab “Filler 1”. Now drag the “Filler 1 Run” event from the Model View and drop it onto the “Filler
1” tab.
4.2 Collect. Calculate. Visualize 109
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
View the Event Form
Open the “Flow Server” again, make sure you have signed in and select the “Packaging Event Form”:
Notice the structure of the Event form. The event Index, Start and End is always displayed on the left.
Any attributes that you have added to the form definition will appear on the right (in the order you
have specified).
Editing Event Attribute Data
Let’s focus on the event with Index 146. Let’s assume that for that Period, the Filler actually produced
“Grape” flavor, not “Apple”. Select the cell and edit the value to “Grape”:
4.2 Collect. Calculate. Visualize 110
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Editing Event Period Data
To edit the Index, Start or End of a specific event period, double-click on the Index to open an editor
form:
Using this form you can modify the Index, Start or End of the event period. After clicking commit, the
Flow Engine will start processing the changes. Other linked information within the Flow System will
also need to be updated. Wait a few seconds and click the “Refresh” button.
Removing Event Periods
To remove an event period, hover over the period and click the “Delete” button (x). A message will
popup requesting confirmation that you want to remove this event period. Click okay, wait a few
seconds for the Flow Engine to process the required changes and then click the “Refresh” button.
4.2 Collect. Calculate. Visualize 111
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
After refreshing, you will notice that the original period with Index 146 has been replaced with the
details of the period that was 147.
Inserting an Event Period
To insert an event period above an existing event period, hover over the period and click the “Insert”
button (+). Provide the details required to create the new event period. Notice the Period Start and
End are defaulted to “fill” the space between the existing event periods.
After committing your new event period details, wait a few seconds for the Flow Engine to process the
required changes and click the “Refresh” button. Notice that the Flow Engine has processed the
Attribute information for the inserted event. We can edit these values if required.
4.2 Collect. Calculate. Visualize 112
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Note: If you do not see an “Insert” button, this means that there is no space available to insert a new
period. You would need to first edit the existing periods to create space for a new period to be inserted.
Adding an Event Period
To add an event period, click the “Create” button (+) at the bottom of the form. Enter the event details,
commit and wait a few seconds for the Flow Engine to process the required changes, then click the
“Refresh” button.
4.2 Collect. Calculate. Visualize 113
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 24: Associate an Event with a Measure
Let’s go back to your “Packaging Event Report”, wouldn’t it be useful if you could add additional
columns to your report?
Let’s see how we can do this with new measures. Set your Measure Defaults to “Hourly” with a format
of “0” (i.e. no decimal places).
In the Model View, create a new Metric in the “Filler 1” folder. Flow will name your new Metric “Filler
1”. Locate the “FL001.BottleCount” tag in your Historian, drag it across to the “Filler 1” Metric and
rename it to “Filler 1 Good Production”. Set its retrieval aggregation method to “Counter” (because it
is a counter tag).
Before you deploy your new measure, expand the “Context” section, and drag the “Filler 1 Run” Event
into it ...
4.2 Collect. Calculate. Visualize 114
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now deploy the new measure.
Let’s discuss what you have just done. By adding the “Filler 1 Run” Event into the “Context” of the new
measure, you have told Flow to “overlay” the time period information from the measure and the event
period information from the event. Flow effectively “slices” the overlaid time and event period
information, allowing you to present it from different perspectives (or dimensions).
Let’s add this measure to the Event Report you created earlier. Open the “Packaging Event Report”,
expand the “Filler 1” Section and drag this new “Filler 1 Good Production (bottles)” measure onto the
“Filler 1 Run” event. Set its “Description” property to “Good Bottles” …
Refresh your “Packaging Event Report” and notice the additional column of information …
4.2 Collect. Calculate. Visualize 115
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 25: Monitoring System Progress
In this lab, you are going to complete the configuration of the “Filler 1” Metric. All measures are going
to be hourly and associated with the “Filler 1 Run” Event.
Build the following measures:
Retrieved
Add a Retrieved Measure called “Filler 1 Bad Production (bottles)” using tag “FL001.BottleCount.Reject”
and the “Counter” aggregation method. Add the “Filler 1 Run” Event to its context.
Manually Entered
Add a Manually Entered Measure called “Filler 1 Rating (bottles)” for the design specification of the
Filler. Add the “Filler 1 Run” Event to its context. Expand the “Retrieval” section set the properties as
follows:
Because an Event is associated with this Measure, Flow needs to know how the “Initial Value” property
is used. The overlay of event periods onto time periods literally slices the time period into pieces. Flow
wants to know whether each slice’s value is assigned to the initial value, or whether the whole time
period’s value is assigned to the initial value, in which case the slices’ values will be assigned a
proportional split of the time period’s value. For the “Filler 1 Rating (bottles)” measure, use “Split initial
value of time slices”.
Calculated
Add a Calculated Measure for “Filler 1 Total Production (bottles)” which is the sum of “Filler 1 Good
Production (bottles)” and “Filler 1 Bad Production (bottles)”.
Add a Calculated Measure for “Filler 1 Efficiency (%)” which is the ratio of “Filler 1 Total Production
(bottles)” to “Filler 1 Rating (bottles)”. You can use the User Defined Function for “Efficiency” created
earlier.
Add a Calculated Measure for “Filler 1 Quality (%)” which is the ratio of “Filler 1 Good Production
(bottles)” to “Filler 1 Total Production (bottles)”. You can use the User Defined Function for “Efficiency”
created earlier.
4.2 Collect. Calculate. Visualize 116
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Aggregated
Add an Aggregated Measure for “Filler 1 Good Production DTD (bottles)”. This is an hourly measure
which will sum the “Filler 1 Good Production (bottles)” measure every hour, but “reset” every day. This
will result in a DTD (“Day to Date”) calculation. Drag the “Filler 1 Good Production (bottles)” measure
from the Model View onto the “hourly” Flow Zone icon, not the “daily” icon. Set the Retrieval
properties as follows:
Just before you deploy all your new measures, open the Flow Monitor from the “VIEW”, “Monitor”
main menu item. Notice the top section for Measure processing is empty. This indicates that the Flow
System is up to date.
Now right-click on the “Filler 1” Metric and select “Deploy” …
Deploying the metric will deploy all of its measures. Notice the Flow Monitor has a number of hourly
measures’ time periods to process. Hover your cursor over the bars to see what each one represents.
4.2 Collect. Calculate. Visualize 117
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
You should notice the bars starting to drop (including a rough rate calculation). When there are no bars
remaining in the Measures section, Flow is up to date again.
4.2 Collect. Calculate. Visualize 118
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 26: The “Packaging” Dashboard
Now that your Flow System has a few more measures, associated with events, let’s build a dashboard
that presents this information to the Packaging Line 1 Manager.
Open the “Packaging Event Report” you created earlier. Expand the “Filler 1 Run” event and add the
“Filler 1 Efficiency (%)” and “Filler 1 Quality (%)” measures to it …
Create a new “Packaging Dashboard” in the “Packaging” report folder. Open it and add the “Packaging
Event Report” to the canvas. Resize the panel to 9 x 3 blocks.
4.2 Collect. Calculate. Visualize 119
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now open the dashboard …
Your Packaging Line 1 Manager is particularly interested in the hourly good production, the “Day to
Date” good production and the quality. Create a new hourly “widget” report for these three measures
and add it to the dashboard. Name it “Filler 1 Widget”, open it and change the Report Type to “Widget”.
4.2 Collect. Calculate. Visualize 120
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Now set the widget’s definition as follows:
Now add the widget report to the “Packaging Dashboard” canvas …
4.2 Collect. Calculate. Visualize 121
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Refresh your dashboard view to see the layout of the widget report. Notice the “rows” as per the
widget definition. Adding more measures to each “row” provides the flexibility to create a grid of
widgets.
We have space on our dashboard for one more report. Let’s create a time-based report for “Filler 1”
that shows our production and efficiency for each hour, for each product. Create a new hourly report
in the “Packaging” report folder. Open it and create the following report definition …
Notice the “DTD” measure has been placed in the “Cumulative Aggregations” Day placeholder for the
“Good Production” report measure. This will add a column at the end of the report to display the “DTD”
value.
Notice the “Context” property of each report measure. Even though you are creating an hourly (time-
based) report, because these measures are associated with an event, you can “slice” the report by the
Event Attribute context.
Add this report to your “Packaging Dashboard”.
4.2 Collect. Calculate. Visualize 122
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Refresh your dashboard view to see the final result:
4.2 Collect. Calculate. Visualize 123
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Using the Flow Server
When opening the Flow Server in a browser, you are presented with the following:
Notice the following:
Index Page – click this link to open the Index / Menu for the Flow System. The Index displays the
Dashboards and Reports in alphabetical order.
o Hide Index – click here to close the Index / Menu
o Refresh Index – click here to refresh the Index / Menu contents
4.2 Collect. Calculate. Visualize 124
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
o Favorite – if you are signed in, click here to favorite a report or dashboard. After refreshing,
all favorites are moved to the top of the menu
o Show Usage – click here to display a chart indicating the frequency of use
o Show More – if you are not signed in, the menu will only show the top few items. Click
“Show more” to display all items.
Pop Out – when hovering your mouse over a dashboard panel, notice the “pop out” button. Click
the “pop out” button to open the panel in a separate browser tab.
Sign In – signing in allows you to view dashboards, reports and forms that you have access to. It
also allows you to set/remove your favorite dashboards, report and forms. Click here to sign in
using your Windows user account:
4.2 Collect. Calculate. Visualize 125
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Messaging System
The Flow Messaging System extends the reach of Flow information by pushing configured messages,
reports and dashboards to external Notification Services like Email, SMS (Short Message Service) or
Flow Mobile, either on a schedule or when an event occurs.
This functionality can be used to notify groups of people of certain events, or send them certain
information periodically. Using the SMS or Flow Mobile Notification Servers to deliver messages
augments the social nature of our smart device lifestyle. Keep your operations managers “in the loop”
without them having to constantly monitor reports and dashboards.
Flow Messages are defined by the following:
Message Channel
Message Channels are used to group messages by production area, department or even project. The
Channels are also responsible for defining who receives messages. A user can be “subscribed” to a
Message Channel if they are given access.
Message Trigger
This defines when a message will be compiled and sent. A trigger can be one of the following types:
Time Period Trigger – this defines a scheduled trigger based on a Calendar period (i.e. daily)
Event Period Trigger – this defines an event trigger based on an Event definition (i.e. end of
batch)
Limit Exceeded – this defines a limit trigger based on a measure’s limit being exceeded (i.e.
temperature too high)
Message Contents
This defines what a message will contain (e.g. measure values, measure limits, event periods, report
screenshots, dashboard screenshots, etc.).
Notification Services
This defines how a message will be sent (i.e. the external delivery mechanism):
SMTP Email
SMS (via web services)
Flow Mobile (iOS App)
A message can be sent to more than one Notification Service.
4.2 Collect. Calculate. Visualize 126
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Lab 27: Sending a Message
In this lab, you are going to create a new Flow message that is sent via email on a periodic schedule.
Select the “Messages” tab at the bottom of the “Information Model” view.
Notification Services
Notification Services are the mechanisms available to send
messages. These will be discussed in more detail in the following
sections.
Messages
The message definition section is made up of “Message Channels”
that contain one or more “Messages”. By default, Flow creates a
“System” Channel that contains an “Engine Status” Message.
Create a Message Channel
A Message Channel provides the following functionality:
Message organization similar to folders
Group level channel access
User level channel subscription
Right-click in the message definition section to create a new “Channel”. Name it “Packaging”.
4.2 Collect. Calculate. Visualize 127
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Double-click the “Packaging” Channel to open its editor. The “Allow” section of the editor defines which
user groups have access to receive messages defined in this channel. By default, the “Everyone” group
has access to the channel. However, just because a group is given access to the channel, does not mean
the users in that group are “Subscribed” to the channel.
The “Subscribed Users” section of the editor defines which users are subscribed to receive messages
defined in the channel.
Select the “Users” tab at the bottom of the Model View, and drag the “Packaging” group into the
“Allow” section. Notice the available users that can now subscribe to the channel. Both “Windows
Users” and “Message Recipient” users can subscribe to Message Channels.
4.2 Collect. Calculate. Visualize 128
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Users can be subscribed to a channel in one of the following ways:
Drag an individual user from the “Allow” section to the “Subscribed Users” section.
Drag a whole group from the “Allow” section to the “Subscribed Users” section. Note that this will
subscribe all the users currently defined in that group, but will not automatically link users that are
added to the group at later stage.
From the Flow Server, a signed in user can view the Channels they have access to via their “Profile”.
Clicking the available channels in the “Subscriptions” sections allows the user to toggle which
channels they want to subscribe to.
4.2 Collect. Calculate. Visualize 129
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Create a Message Definition
Now that you have a Message Channel to define group access and user subscription, let’s create a
Message that publishes to that Channel.
Right-click the “Packaging” Channel and create a new Message. Name it “Packaging Daily Scorecard”.
Double-click the “Packaging Daily Scorecard” Message to open its editor.
General Properties
The top section of the editor displays the general properties for the Message:
Description – message description.
Purge Age – this is the number of days that an instance of a message will be stored in the Flow
System. After this time, the message will be removed. Note that this property cannot be edited.
4.2 Collect. Calculate. Visualize 130
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Message Trigger
The message trigger determines when a message needs to be compiled and sent. For this lab, lets
create a message that is sent on a daily schedule. You will create a new “Time Period Trigger” in one of
the following ways:
Right-click in the Message Triggers section to create a new “Time Period Trigger”.
Drag the Daily icon from the Flow Zone into the Message Triggers section.
The “Time Period Trigger” has the following properties:
When – either the start or the end of the period, in this case “Daily” (i.e. at the end of the day)
Calendar – this specifies which calendar the time period is derived from. If the calendar’s day starts
and ends at 06:00, then this will be the time period used for “the end of the day” trigger evaluation.
Refresh offset – this is a number of seconds after “the end of the day” that Flow will attempt to
compile the message contents. A default value of 300 seconds (i.e. 5 minutes) is set. If you find
that some information is not being provided in the compiled messages, you may need to increase
this Refresh Offset.
Delay sending – this is the number of seconds after “the end of the day” that Flow will send the
message. If the delay is set to the same value as the Refresh Offset, then Flow will send the message
as soon as it is compiled. If “the end of the day” is 06:00, you may want to set the delay to 1800
seconds (i.e. 30 minutes) to send the message at 06:30.
Message Contents
Now that we have determined when the “Packaging Daily Scorecard” will be triggered, let’s define what
the message should contain. Expand the “Message Contents” section:
4.2 Collect. Calculate. Visualize 131
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
You will notice that by default, Flow creates some initial message content. The message content is
defined by one or more Sections, and each section can contain one or more Segments. Think of sections
as a grouping of your message content.
In a message, one section can be defined as the message subject. This is displayed as the bold section.
Within each section, one segment can be defined as that section’s heading. This is displayed as the
bold segment.
Looking at the default content Flow has created, the section “Packaging Daily Scorecard” is set to be
the subject (i.e. bold). The single segment within the section is the text “Packaging Daily Scorecard”.
This is the text that will be used by Flow as the subject of the message.
For clarity, let’s rename the subject section to “Subject”:
Create two new sections, one named “Summary” and the other name “Dashboard”:
On the “Summary” section, create a new “Constant” segment:
4.2 Collect. Calculate. Visualize 132
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Notice that the new segment is set to represent the heading (i.e. bold) of the “Summary” section. The
segment text is also set to “Summary”, as derived from the section name. Edit this segment text to
“Packaging Daily Summary”.
Create a new “Measure Value” segment. Drag the “Filler 1 Total Production” measure from the Model
View across to the new segment’s “Measure” textbox:
The segment text is made up of static text and placeholders. Right-click in the segment text section to
add one or more available placeholders. For this lab, use the simple example:
4.2 Collect. Calculate. Visualize 133
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
This will add the following placeholders:
[Measure]: [Value("0.00")] [UOM]
When Flow evaluates this segment, the placeholders will be replaced by actual names, values or text
strings, e.g.
Filler 1 Total Production: 24607 bottles
You can change the segment text as required. See the section on page 139 for a description of the
available placeholders you can add for each Segment type.
To finish our message contents, let’s add the “Packaging Dashboard” to the “Dashboard” section. Select
the “Reports” tab at the bottom of the Information Model, find the “Packaging Dashboard” you created
earlier, and drag it onto the “Dashboard” section:
For the “Dashboard” segment, set the following properties:
Segment Text – this can be left blank (default). If any text or placeholder is included here, Flow will
use it as a hypertext link to open the dashboard via a default browser.
Attachment – by default this is set to “Image”, at “Screen HD 1080” size. Flow will render the
dashboard to an image and include it with the message contents. A 5 second timeout is provided
to create the dashboard rendering, but this value can be increased where required.
4.2 Collect. Calculate. Visualize 134
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Notification Services
Now that we have defined when and what needs to be sent in our message, let’s define how Flow will
send the message to the Message Channel’s subscribers.
Flow makes use of Notification Service plug-ins to send messages. Think of a Notification Service as a
mechanism to deliver a message to an “external” system (e.g. an email system). For this lab, you will
configure an Email Notification Service to deliver your message.
Expand the “Notification Services” section:
A message definition must have at least one Notification Server assigned to it. Before we can assign an
Notification Server to this message, we will need to configure one.
Create an Email Notification Server
Right-click the “Smtp Email” Notification Service type in the Information Model and select “New”:
4.2 Collect. Calculate. Visualize 135
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
“Smtp” stands for Simple Mail Transfer Protocol. Smtp is the
internet standard for electronic mail submission.
The “Smtp Email” Notification Service requires the following properties to be set:
Name – set this to a name that describes the email system.
Server – set this to the Smtp server name. This would typically be an internal email server host
name. “smtp.office365.com” is the server address for Microsoft Office 365.
Port – this is the port used by the Smtp protocol. Contact your System Administrator for details
relating to your internal email server.
Enable SSL – specify whether Smtp server uses SSL (Secure Sockets Layer) to encrypt the
submission.
Timeout – the amount of time in milliseconds after which a send will fail.
Username – email account that will be used to send the email messages. If your email server allows
anonymous sending, then leave this property blank.
Password – password of the above account
Sender Display Name – the sender’s name that will be displayed to the email recipients. Some email
servers will ignore this property and use the “Username” email properties.
Domain Mask – a mask that will only allow messages to be sent to users that have an email address
that uses this domain. This property can be a comma separated list of domains. At least one
domain mask must be specified.
Click “Save” and then drag your “Internal Email” Notification Server into the message definition:
4.2 Collect. Calculate. Visualize 136
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Some Notification Servers will require additional properties to be set (e.g. email priority).
Note: A message can be delivered to more than one Notification Server.
Deploying and Testing a Message
Now that you have configured your message definition, you will need to deploy it. Either click the
“Deploy” button at the top of the message editor, or right-click the message and “Deploy”:
Once deployed, the Flow Message Engine will automatically manage the scheduling, compiling and
sending of messages.
In order to facilitate the testing of your message definition and Notification Services, you can manually
trigger a message by right-clicking in the triggers section of a message and selecting “Trigger now”:
Note: Use the Event Viewer on the platform where the Message Engine is deployed to monitor for any message
processing errors. See the section on page 34 for troubleshooting information.
4.2 Collect. Calculate. Visualize 137
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Received Email Message
Once the Flow Message Engine has compiled and sent the test message, you should notice an email in
your inbox. This email was opened using Microsoft Outlook. Notice how the email layout matches the
message content definition.
Note: When the Message Engine is ready to send a message, it will pass the message and recipient information
to the configured Notification Services. If the Notification Service is unavailable at this time, the Message Engine
will not attempt to send the message again.
4.2 Collect. Calculate. Visualize 138
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Using Message Content Placeholders
Depending on the Segment type used when defining message contents, various placeholders are
available for use. When creating a new Segment, you can always right-click in the “Segment Text” or
“Segment Link” section and use the “Example” text. This will give you an idea of how to use the segment
type.
Constant
A “Constant” segment type has no placeholders, only free text.
Measure Value
The following placeholders are available for a “Measure Value” segment type:
Measure
o [Measure] – measure’s name
o [Description] – measure’s description
o [UOM] – measure’s unit of measure
Value
o [Value("0.00")] – measure’s value for most recent period (if value is null, then use 0.00)
o [Quality] – measure’s quality for most recent period
o [Version] – measure’s version for most recent period
Limit
o [Limit] – limit’s name
o [Target] – limit’s target
o [High] – limit’s high setting
o [Low] – limit’s low setting
o [Exceeded("Ouch!", "What happened?")] – if limit has been exceeded, then Flow will
randomly select one of the text parameters (more text parameters can be used in a comma
separated list)
o [Achieved("Well done team!", "Good Work!", "Keep it up!")] – if limit has been achieved,
then Flow will randomly select one of the text parameters
Period
o [PeriodStart("HH:mm")] – period’s start date formatted as per parameter
o [PeriodEnd("HH:mm")] – period’s end date formatted as per parameter
o [Duration] – period’s duration
Condition
o [Positive("Great improvement!", "Keep it up!")] – if value is positive, then Flow will
randomly select one of the text parameters (more text parameters can be used in a comma
separated list)
o [Negative("What happened?", "Ouch!")] – if value is negative, then Flow will randomly
select one of the text parameters
4.2 Collect. Calculate. Visualize 139
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Relative – similar to above, but with an additional parameter that specifies a previous period index
o [Value(-1, "0.00")]
o [Quality(-1)]
o [Version(-1)]
o [Target(-1)]
o [High(-1)]
o [Low(-1)]
o [PeriodStart(-1, "HH:mm")]
o [PeriodEnd(-1, "HH:mm")]
o [Duration(-1)]
Measure Attribute Value
A “Measure Attribute Value” segment can be used when a measure is sliced by additional Event context.
The following placeholders are available for a “Measure Attribute Value” segment type:
Measure
o [Measure] – measure’s name
o [Description] – measure’s description
o [UOM] – measure’s unit of measure
Attribute
o [Attribute] – attribute’s name (e.g. Product)
o [AttributeValue] – attribute value’s name (e.g. Orange, Apple)
Value
o [Value("0.00")] – measure’s value for most recent period (if value is null, then use 0.00)
o [Duration] – period’s duration relating to this attribute value
o [Quality] – measure’s quality for most recent period
o [Version] – measure’s version for most recent period
Period
o [PeriodStart("HH:mm")] – period’s start date formatted as per parameter
o [PeriodEnd("HH:mm")] – period’s end date formatted as per parameter
Relative – similar to above, but with an additional parameter that specifies a previous period index
o [Value(-1, "0.00")]
o [Quality(-1)]
o [Version(-1)]
o [PeriodStart(-1, "HH:mm")]
o [PeriodEnd(-1, "HH:mm")]
o [Duration(-1)]
4.2 Collect. Calculate. Visualize 140
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Event Period
An “Event Period” segment can be used when a message is triggered by an Event Period. The following
placeholders are available for a “Event Period” segment type:
Event
o [Event] – event’s name
Period
o [PeriodStart("HH:mm")] – period’s start date formatted as per parameter
o [PeriodEnd("HH:mm")] – period’s end date formatted as per parameter
o [Duration] – period’s duration
o [Index("0000")] – period’s index formatted as per parameter
Relative – similar to above, but with an additional parameter that specifies a previous period index
o [PeriodStart(-1, "HH:mm")]
o [PeriodEnd(-1, "HH:mm")]
o [Duration(-1)]
o [Index(-1, "0000")]
Event Period Attribute
An “Event Period Attribute” segment can be used when a message is triggered by an Event Period. The
following placeholders are available for a “Event Period Attribute” segment type:
Event
o [Event] – event’s name
Attribute
o [Attribute] – attribute’s name (e.g. Product)
o [AttributeValue] – attribute value’s name (e.g. Orange, Apple)
Period
o [PeriodStart("HH:mm")] – period’s start date formatted as per parameter
o [PeriodEnd("HH:mm")] – period’s end date formatted as per parameter
o [Duration] – period’s duration
o [Index("0000")] – period’s index formatted as per parameter
Relative – similar to above, but with an additional parameter that specifies a previous period index
o [PeriodStart(-1, "HH:mm")]
o [PeriodEnd(-1, "HH:mm")]
o [Duration(-1)]
o [Index(-1, "0000")]
4.2 Collect. Calculate. Visualize 141
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Event Period Value
An “Event Period Value” segment can be used when a message is triggered by an Event Period. The
following placeholders are available for a “Event Period Value” segment type:
Event
o [Event] – event’s name
Measure
o [Measure] – measure’s name
o [Description] – measure’s description
o [UOM] – measure’s unit of measure
Value
o [Value("0.00")] – measure’s value for most recent period (if value is null, then use 0.00)
o [Quality] – measure’s quality for most recent period
o [Version] – measure’s version for most recent period
Attribute
o [Attribute] – attribute’s name (e.g. Product)
o [AttributeValue] – attribute value’s name (e.g. Orange, Apple)
Period
o [PeriodStart("HH:mm")] – period’s start date formatted as per parameter
o [PeriodEnd("HH:mm")] – period’s end date formatted as per parameter
o [Duration] – period’s duration
o [Index("0000")] – period’s index formatted as per parameter
Condition
o [Positive("Great improvement!", "Keep it up!")] – if value is positive, then Flow will
randomly select one of the text parameters (more text parameters can be used in a comma
separated list)
o [Negative("What happened?", "Ouch!")] – if value is negative, then Flow will randomly
select one of the text parameters
Relative – similar to above, but with an additional parameter that specifies a previous period index
o [PeriodStart(-1, "HH:mm")]
o [PeriodEnd(-1, "HH:mm")]
o [Duration(-1)]
o [Index(-1, "0000")]
Report Link
The following placeholders are available for a “Report Link” segment type:
Report
o [Report] – report’s name
4.2 Collect. Calculate. Visualize 142
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
o [Link] – report’s hypertext link
Dashboard Link
The following placeholders are available for a “Dashboard Link” segment type:
Dashboard
o [Dashboard] – dashboard’s name
o [Link] – dashboard’s hypertext link
4.2 Collect. Calculate. Visualize 143
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Notification Servers
Flow makes use of Notification Service plug-ins to send messages. Think of a Notification Service as a
mechanism to deliver a message to an “external” system (e.g. an email system). The Notification
Services available to deliver your messages include:
Smtp Email
Smtp (Simple Mail Transfer Protocol) is the internet standard for electronic mail submission.
For further details on configuring the “Smtp Email” Notification Service, see the section on page 135.
4.2 Collect. Calculate. Visualize 144
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Twilio
Twilio is a web service that provides bulk messaging. The “Twilio” Notification Service makes use of the
SMS (Short Message System) Twilio API. The “Twilio” Notification Service does not support Flow
message segments that use attachments (i.e. report or dashboard images).
For you to use the “Twilio” Notification Service, you will need to create your own Twilio account at
https://www.twilio.com. For testing purposes, Twilio offers a limited number of free SMS messages,
thereafter, you will need to pay for the Twilio service.
Note: In order to send messages from your Twilio account, you will need to create a “sender” Twilio number. This
number can be bought from Twilio based on the country of use. In addition to this, each recipient’s number must
be verified in Twilio as a “Verified Called ID” using the recipient’s name and number.
When creating a new “Twilio” Notification Service in Flow, you will need to provide the following details:
Name – set this to a name that describes the Twilio system.
Account SID – set this to the 34 character Twilio account ID.
Auth Token – set this to the authentication token provided by Twilio for your account ID.
Sender – set this to the “sender” number you bought from Twilio.
4.2 Collect. Calculate. Visualize 145
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Bulk SMS
BulkSMS is a web service that provides bulk SMS messaging. The “BulkSms” Notification Service does
not support Flow message segments that use attachments (i.e. report or dashboard images).
For you to use the “BulkSms” Notification Service, you will need to create your own BulkSMS account
at https://www1.bulksms.com/register. For testing purposes, BulkSMS offers a limited number of free
SMS message credits, thereafter, you will need to pay for SMS bundles based on usage.
When creating a new “BulkSms” Notification Service in Flow, you will need to provide the following
details:
Name – set this to a name that describes the BulkSMS system.
Username – set this to your BulkSMS Username.
Password – set this to your BulkSMS Password.
4.2 Collect. Calculate. Visualize 146
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow Mobile
Flow Mobile is an app that runs on iOS. Flow Mobile is a collaborative messaging app that allows
channel subscribers to interact with each other and receive messages from Flow Systems via “Flowbot”.
When creating a new “Flow Mobile” Notification Service in Flow, you will need to provide the following
details:
Name – set this to a name that describes the Flow Mobile system.
Domain Mask – Flow Mobile authorizes users via their email address. This mask will only allow
messages to be sent to users that have an email address that uses this domain. This property can
be a comma separated list of domains. At least one domain mask must be specified.
Note: The Flow Mobile app is currently available for iOS only. Please search “Flow Software” in the Apple App
Store.
4.2 Collect. Calculate. Visualize 147
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Copying Events, Metrics and Measures
Flow allows you to copy and paste events, metrics and measures. This is expected functionality,
however, it is worth discussing a few concepts regarding how Flow handles the paste operation. If you
understand how this works, Flow can be used very effectively to speed up the configuration of large
systems.
Copying an Event
When pasting an event into a folder, Flow will use the source and destination folders in a “search and
replace” manner. Copy “Filler 1 Run” and paste it into the “Filler 2” folder. Flow uses the source folder
(i.e. “Filler 1”) and replaces it in the name of the new event with the destination folder (i.e. “Filler 2”).
It is recommended that you standardize on a naming convention for folders and events so that this
paste functionality can be used to your benefit.
Open the new “Filler 2 Run” Event, set the “Tag” properties to the correct references for triggers and
attribute segments and then deploy …
Copying a Metric
Similar to an Event, when copying a metric into a folder, Flow will use the source and destination folders
in a “search and replace” manner. Copy the “Filler 1” metric and paste it into the “Filler 2” folder. Flow
uses the source folder (i.e. “Filler 1”) and replaces it in the name of the new metric (and all the metric’s
measures) with the destination folder (i.e. “Filler 2”).
4.2 Collect. Calculate. Visualize 148
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
After pasting the new metric, you will need to edit the retrieval properties of any Retrieved Measures,
as well as validate the calculations in any Calculated Measures.
4.2 Collect. Calculate. Visualize 149
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Using the Microsoft SQL Data Source
Flow is very good at understanding the way Tag Historians store their data. This makes configuring
Events and Measures really easy. However, when you connect Flow to a Microsoft SQL Data Source,
Flow will not "understand" the structure of your data, making it a little tricky to configure.
Here are a few guidelines and an example to get you started. In this example, we have a single
"Quantity" value recorded every hour for a specific "Work Order" and corresponding "Product". It is
possible that more than one record could be inserted for a single hour during a "Work Order" change
over. These records are stored in a SQL table called "ProdData". We will be creating an Hourly measure.
Measure Values
When retrieving data for a Measure's value, your SQL script must return a single record for the time
period being queried, e.g.
select sum(Quantity) from ProdData
But this would sum all the records in the table. We need to give Flow a bit more information about the
time periods to query. At any point in time, Flow knows what time period it is busy processing for our
measure. We can use Flow [Placeholders] to augment this SQL query:
select sum(Quantity) from ProdData
where Start >= [PeriodStart]
and End <= [PeriodEnd]
Flow will now sum the records for the hour that is being processed.
4.2 Collect. Calculate. Visualize 150
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
For this example, we may want to filter our SQL query for the "Filler 3" Machine only.
select sum(Quantity) from ProdData
where Start >= [PeriodStart]
and End <= [PeriodEnd]
and Machine = 'Filler 3'
One last thing ... because this query makes use of a SQL aggregation method (i.e. "sum"), it would return
a NULL value if there were no records for a specific hour. Flow will handle the NULL values, but it may
be more elegant for the SQL query to return 0 rather than NULL:
select isnull(sum(Quantity), 0) from ProdData
where Start >= [PeriodStart]
and End <= [PeriodEnd]
and Machine = 'Filler 3'
Event Triggers
When retrieving data for an Event's triggers, your SQL script must return zero or more "Timestamps",
e.g.
select Start from ProdData
But this would return the "Start" value for all the records in the table. We need to give Flow a bit more
information about the time span to query. Like the measure value's query, we can use Flow
[Placeholders] to augment this query:
select Start from ProdData
where Start >= [PeriodStart]
and End <= [PeriodEnd]
and Machine = 'Filler 3'
Flow will now return all the "Starts" found during the last period being processed.
For the example data above, this would result in a new Event Period being created every hour at least.
What we actually want is a new Event Period every time the "Work Order" changes. Let's change our
SQL query to a "group by" on the "Work Order" column and select the minimum "Start":
select min(Start) from ProdData
where Machine = 'Filler 3'
group by WorkOrder
having min(Start) >= [PeriodStart]
4.2 Collect. Calculate. Visualize 151
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
and min(Start) <= [PeriodEnd]
Flow will create a new Event Period every time the Work Order changes.
If you require an End Trigger, use the following SQL query:
select max(End) from ProdData
where Machine = 'Filler 3'
group by WorkOrder
having max(End) >= [PeriodStart]
and max(End) <= [PeriodEnd]
Event Attribute Segments
When retrieving data for an Event Attribute's Segment (i.e. context), your SQL script must return a
single value. Flow will convert this value into a string, or, if your segment is linked to an enumeration,
it will perform the ordinal lookup and return the resultant string.
Like the measure value and event trigger queries, we can use a Flow [Placeholder] to retrieve an Event
Attribute Segment's value:
select Product
from ProdData
where Machine = 'Filler 3'
and Start = [TimeStamp]
Flow defaults the [TimeStamp] placeholder to 0 seconds after the Event Period has started. This can
be changed by modifying the attribute segment's "Retrieve Point".
For the example data above, let's create a "Work Order" Attribute and a "Product" Attribute:
select WorkOrder
from ProdData
where Machine = 'Filler 3'
and Start = [TimeStamp]
select Product
from ProdData
where Machine = 'Filler 3'
and Start = [TimeStamp]
4.2 Collect. Calculate. Visualize 152
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
In this example, the Measure Values, Event Triggers and Event Attribute Segment values all came from
the same SQL table. Something to consider is that each of these Flow retrievals could come from
different data sources.
4.2 Collect. Calculate. Visualize 153
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Advanced Concepts
This section describes a few concepts that are not typically used every day. However, it is important to
understand that Flow can be used to achieve these things.
Filtering Detailed Data
For Retrieved Measures, some Flow Data Source types support the use of “Filter Tags”. Flow uses a
filter tag and condition to filter out some of the detailed data when calculating a summary value for the
measure.
Filter Tag – this is the tag Flow will use to compare against the filter condition to determine whether
the detailed data should be used in the calculation or not.
Filter Comparator – this is the comparator part of the filter condition.
Filter Value – this is the value part of the filter condition.
Filter Default – this is used by Flow if all the detailed data is filtered out of a time period. Flow will
use this default value for the measure value for that time period.
Multiple Connections for a Measure
For Retrieved Measures, Flow allows more than one Data Source connection to be added to its
“Retrieval” properties.
In this example the measure has a connection to the “Historian” and to the “Planning System”. The
“Historian” connection uses a specific tag to retrieve an average value. The “Planning System”
connection may use a SQL query to collect a value from a validated data source.
4.2 Collect. Calculate. Visualize 154
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
But when would you use this? Open the “Context” section of a Retrieved Measure and select the
“Properties” tab …
Where more than one connection has been linked to a Retrieved Measure, the Refresh Offset
properties can be associated with a specific connection.
Let’s discuss a scenario where this would be useful. Let’s assume a manually validated number in the
“Planning System” Data Source is only available at 09h00 every day (maybe it needs to be checked by
a person first). However, the morning shift handover meeting happens at 06h00. You would like to
provide an “initial” value from your “Historian” tag for the 06h00 meeting, and then when the “Planning
System” data is available at 09h00, get that value for your measure. To do this, you would set the “60”
second Refresh Offset to use the “Historian”, and create another Refresh Offset of “10800” seconds (3
hours) which uses the “Planning System”. If the value from the “Planning System” at 09h00 is different
from the value retrieved from the “Historian” at 06h00, Flow will create a new version of the measure’s
value and set it to “Preferred”, hence making it the value used in reports.
Relative Period Calculations
For Calculated Measures, Flow allows calculations to be configured based on a measure’s previous
period’s value, or even a previous range of values.
Relative Period
When selecting a dependent measure in a measure calculation, select the “Properties” tab. Set the
“Dependent” property to “Previous period” and the “Relative End” to -1.
Flow will now use the previous period of this measure in your calculation expression.
4.2 Collect. Calculate. Visualize 155
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Relative Range
Set the “Dependent” property to “Previous range”, “Relative Start” to -30 and the “Relative End” to 0.
Flow will now use an array of values in your calculation expression. You will need to use this array in a
Built-In or User Defined Function.
This Relative Range calculation is useful for “moving window” calculations (e.g. moving average, moving
sum, etc.)
Customizing the Flow Report Server
You will most likely want to change the “look and feel” of the Flow Report Server. Here are a few
properties you may want to change:
4.2 Collect. Calculate. Visualize 156
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Logo – add your company logo file. Flow will use it in the header of the reports and dashboards.
Color 3 – this is the color Flow uses for the dashboard panel title bars. The default color is the Flow
green, but it is recommended that this be changed to one of your company’s accent colors.
Port – this is the port used by the Flow Report Server. Port 80 is the default http value.
Understanding Flow System Modules
Many of the components of Flow, as described in the Flow Deployment Architecture section on page
20 are Flow “Modules”. Open “SYSTEM”, “Modules” from the main menu …
Your Flow System can be extended by adding new modules to it. Some of the components can be
updated by importing the latest releases. Use the “Import” menu to add or update these modules.
Why is this important to you? If Flow Software releases a new Data Source type in the future, you
would be able to add that new module here and be able to use the new Data Source without needing
to reinstall your Flow System.
4.2 Collect. Calculate. Visualize 157
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Flow Database Views
If you are familiar with other visual analytics tools you would like to use on top of the Flow database
(e.g. SSRS, Dream Report, WW Intelligence, Tableau, Qlikview, etc.), Flow exposes a number of views in
the Flow database that may be useful:
vMeasure – measure definition.
vMeasureValue – all measure values.
vMeasureValueException – all measure value exceptions.
vReportGroupMeasure – time-based report definition.
vEventPeriod – all event periods created.
vEventPeriodValue – all measure values associated with event periods.
vEventPeriodAttributeValue – all attribute values collected for the event periods.
vReportGroupEventScheme – event-based report definition.
Integrating Flow information into other Systems
Flow Software can provide additional services relating to the integration of Flow information into other
systems. For example, it may be useful for you to integrate your Flow information into your ERP system
(i.e. actual production values). Please contact your Flow Distributor or Flow Support if you need to
discuss the options available to you.
Flow Database Maintenance/Backups
The Flow System handles the standard periodic database maintenance (i.e. index re-building, etc.).
However, Flow does not manage any database backup procedures. The Flow database should be
backed up on a periodic basis as part of your disaster recovery policies.
Flow Directories
The Flow System uses a number of standard Operating System directories. In general, these directories
do not need to be accessed, but for information purposes, they are listed below:
Bootstrap
“ProgramData\Flow Software\Flow\Bootstrap” – this folder contains the necessary runtime files
required for a deployed Flow Platform.
Config
“ProgramData\Flow Software\Flow\Config” – this folder contains the templates and packages
required to create a new Flow System.
“Users\{username}\AppData\Roaming\Flow Software\Flow\Config” – this folder contains a
configuration file that stores the “shortcut” information displayed in the “Connect” dialog box.
4.2 Collect. Calculate. Visualize 158
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Customizing the Flow Simulator
The Flow Simulator is provided as-is. It is a tool used for training and demonstration purposes only.
Limited support can be provided if you want to customize the simulator.
The Flow Simulator is configured using an XML file. You will find this file in your “C:\ProgramData\Flow
Software\Flow\Config\Simulator” folder. You can modify this file little by little until you are comfortable
with how it works.
The following is a section of the default Simulator.xml file.
4.2 Collect. Calculate. Visualize 159
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Once you have built your “Simulator.xml” file, you can add it to your Simulator connection by editing
its “Definition” property and clicking “Save”…
4.2 Collect. Calculate. Visualize 160
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
How do I get Flow?
Flow is available for download at http://support.flow-software.com. You will always find the latest
version and release notes here.
After installing Flow, each Flow System you create will automatically generate a Demonstration License.
This license will allow you to run 100 measures, 5 events and unlimited reports for 30 days.
Software Requirements
Operating Systems
Windows 10 64-bit
Windows Server 2012 64-bit
Operating System Pre-Requisite
.Net 4.5
3rd Party Software
Microsoft SQL Server Express for Flow Starter
Microsoft SQL Server Standard for Flow Small and Medium
Microsoft SQL Server Enterprise for Flow Large, XL, 2XL and 3XL
Hardware Requirements
There are many deployment architecture options available for Flow. Flow has been designed for a
distributed and modular architecture, but can be installed and deployed on a single server.
Flow Config
Minimum of an Intel Pentium 4
16 GB minimum memory
5 GB minimum free disk space
32-bit color depth recommended
1920 by 1080 screen resolution recommended
Flow Platforms, Engines, Message Engines and Report Servers
Minimum of an Intel Pentium 4
4 Cores, 2.0 GHz minimum CPU
32 GB minimum memory
4.2 Collect. Calculate. Visualize 161
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
SQL Database Server Hardware
The Flow data store is a relational Microsoft SQL database. For a Flow System consisting of 10 000
measures, the database can accumulate around 60 million records per year, depending on the
granularity of measure configuration.
Appropriate hardware sizing must be performed to meet expected Flow retrieval and reporting
performance. As a minimum, the following is recommended:
Minimum of an Intel Pentium 4
4 Cores, 2.0 GHz minimum CPU
32 GB minimum memory
100 GB minimum free disk space
4.2 Collect. Calculate. Visualize 162
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
Licensing
Flow is currently available in the following sizes:
Flow Starter 100 measures 5 events 2 messages
Flow Small 1000 measures 50 events 10 messages
Flow Medium 5000 measures 100 events 20 messages
Flow Large 10000 measures 150 events 40 messages
Flow XL 15000 measure 200 events 60 messages
Flow 2XL 20000 measure 250 events 80 messages
Flow 3XL 25000 measure 300 events 100 messages
A rough guide for sizing your Flow System, is to use 10% of your Historian tag count as a starting point.
4.2 Collect. Calculate. Visualize 163
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
Flow 4.2
“I have a system that I can install and configure myself to
get meaningful production information from my facility,
quickly and accurately, without the typical IT pain.”
Please join the online Flow Community. Ask questions, make suggestions, become a known expert.
4.2 Collect. Calculate. Visualize 164
+27 11 595 8455 PO Box 10759, Fourways East 2055 www.flow-software.com
You might also like
- Data SecurityDocument8 pagesData SecurityBanjo GiraoNo ratings yet
- Oracle Grants AccountingDocument618 pagesOracle Grants Accountingmudassar_aziz1980No ratings yet
- PT120 CT120 Database Schema Essentials: Training ManualDocument163 pagesPT120 CT120 Database Schema Essentials: Training ManualAbraham Castro PardoNo ratings yet
- Gme - Osp PDFDocument148 pagesGme - Osp PDFseenuyarasiNo ratings yet
- Oracle PayrollDocument322 pagesOracle PayrollSathish KumarNo ratings yet
- Isupplier User ManualDocument29 pagesIsupplier User ManualMarwan AladarbehNo ratings yet
- Microsoft Windows Server 2008 R2 Administrator's Reference: The Administrator's Essential ReferenceFrom EverandMicrosoft Windows Server 2008 R2 Administrator's Reference: The Administrator's Essential ReferenceRating: 4.5 out of 5 stars4.5/5 (3)
- Workforce Central Timekeeper 5 User ManualDocument326 pagesWorkforce Central Timekeeper 5 User ManualjdurmickNo ratings yet
- CAT Parts Kpi Application TrainingDocument166 pagesCAT Parts Kpi Application Trainingenjoythedocs100% (1)
- Using Receivables Credit To CashDocument598 pagesUsing Receivables Credit To CashKumar MNo ratings yet
- API Best PracticesDocument43 pagesAPI Best Practicesxspid100% (1)
- SAP BW Performance TuningDocument63 pagesSAP BW Performance TuningRaj Reddy KNo ratings yet
- Auditing FT Historian SE Server PDFDocument26 pagesAuditing FT Historian SE Server PDFGonzaloMauricioNo ratings yet
- Lime Datavan Manual Update 092213Document122 pagesLime Datavan Manual Update 092213Peter SnellNo ratings yet
- Cisco CCNA/CCENT Exam 640-802, 640-822, 640-816 Preparation KitFrom EverandCisco CCNA/CCENT Exam 640-802, 640-822, 640-816 Preparation KitRating: 2.5 out of 5 stars2.5/5 (8)
- Paulina Mahajan: Dallas TX, 75052Document3 pagesPaulina Mahajan: Dallas TX, 75052Kritika ShuklaNo ratings yet
- Chapter 1,2,3 (Shanne)Document15 pagesChapter 1,2,3 (Shanne)vanrudolph94% (48)
- OGW Hosted Payment Integration Guide v2.7.0.0Document121 pagesOGW Hosted Payment Integration Guide v2.7.0.0mitchauhan22No ratings yet
- Financial Business Intelligence: Trends, Technology, Software Selection, and ImplementationFrom EverandFinancial Business Intelligence: Trends, Technology, Software Selection, and ImplementationNo ratings yet
- 115 FininsDocument190 pages115 FininsOlgalicia SGNo ratings yet
- Oracle® Mobile Supply Chain Applications: User's Guide Release 11iDocument284 pagesOracle® Mobile Supply Chain Applications: User's Guide Release 11iAvinash RoutrayNo ratings yet
- Lime Instruments. Datavan With LimeFrac Software User GuideDocument92 pagesLime Instruments. Datavan With LimeFrac Software User GuideAnasNo ratings yet
- 115 ArtaxwDocument118 pages115 ArtaxwOlgalicia SGNo ratings yet
- Oracle® Real-Time Decisions: Platform Developer's Guide Release 3.2Document326 pagesOracle® Real-Time Decisions: Platform Developer's Guide Release 3.2Papas FoodsNo ratings yet
- Oracle Process ManufacturingDocument122 pagesOracle Process ManufacturingSayed Jafar SadiqNo ratings yet
- Administering Global Payroll InterfaceDocument58 pagesAdministering Global Payroll InterfacePro HRDNo ratings yet
- Jde 920 Advanced Stock ValuationDocument60 pagesJde 920 Advanced Stock ValuationAlmir GoncalvesNo ratings yet
- Oracle OPM InventoryDocument378 pagesOracle OPM InventoryAnudeep KNo ratings yet
- GPON OLT User Manual Configuration Guide (CDATA)Document35 pagesGPON OLT User Manual Configuration Guide (CDATA)Rabeeagwad GwadNo ratings yet
- Payroll ProcessingDocument744 pagesPayroll ProcessingPankaj SharmaNo ratings yet
- OLI Flowsheer V10 User Guide PDFDocument206 pagesOLI Flowsheer V10 User Guide PDFeujualNo ratings yet
- GL Implementaton PDFDocument292 pagesGL Implementaton PDFnehaNo ratings yet
- Oracle Fixed Assets User GuideDocument700 pagesOracle Fixed Assets User GuideJohn MacNo ratings yet
- Vertex IntegrationDocument108 pagesVertex Integrationsubhashram1No ratings yet
- EPON OLTFD1204S User Manual Quick ConfigurationDocument57 pagesEPON OLTFD1204S User Manual Quick ConfigurationEveraldo BarretoNo ratings yet
- Global ERP Adapter Guide - Credit Transfer - GlobalVersion - Baseline - V2Document104 pagesGlobal ERP Adapter Guide - Credit Transfer - GlobalVersion - Baseline - V2tammna.87No ratings yet
- Time and Attendance Store Guide V7.0Document49 pagesTime and Attendance Store Guide V7.0Anezwa MpetaNo ratings yet
- Forms 6i: Deploying Forms Applications To The Web With Oracle Forms ServerDocument244 pagesForms 6i: Deploying Forms Applications To The Web With Oracle Forms ServerAvinash100% (6)
- Tally - Erp 9 Release NotesDocument137 pagesTally - Erp 9 Release NotessumeshtrNo ratings yet
- ApexCen 2019 IugDocument113 pagesApexCen 2019 IugAnuradha KannanNo ratings yet
- 115 MvstatugDocument202 pages115 Mvstatugkuttush1No ratings yet
- 122 Payuk User GuideDocument376 pages122 Payuk User GuideCynthia GweksNo ratings yet
- Oracle® Internet Expenses: Implementation and Administration Guide Release 11iDocument294 pagesOracle® Internet Expenses: Implementation and Administration Guide Release 11iSyam Sundar SureNo ratings yet
- E17968 Concepts GuideDocument34 pagesE17968 Concepts GuideSahatma SiallaganNo ratings yet
- ReeftDocument109 pagesReeftmicorreNo ratings yet
- Oracle® Shop Floor Management: User's Guide Release 11iDocument146 pagesOracle® Shop Floor Management: User's Guide Release 11iHanbon HoNo ratings yet
- LDAP Manager E25092Document88 pagesLDAP Manager E25092rlufthansaNo ratings yet
- 115 FinfinDocument142 pages115 FinfinOlgalicia SGNo ratings yet
- Eadstart Racle Esigner: User GuideDocument307 pagesEadstart Racle Esigner: User GuideraedadobeNo ratings yet
- Application Server Single Sign-OnDocument168 pagesApplication Server Single Sign-OnneelaprasadNo ratings yet
- PCCharge DevKit590 ManualDocument551 pagesPCCharge DevKit590 ManualEddy SulbaranNo ratings yet
- Qot 115 IgDocument204 pagesQot 115 IgOlgalicia SGNo ratings yet
- Oracle9i Forms Developer and Forms ServicesDocument84 pagesOracle9i Forms Developer and Forms Servicesﺍﻟﻄﺎﺋﺮ ﺍﻟﺤﺰﻳﻦNo ratings yet
- 121payinug PDFDocument268 pages121payinug PDFkrishnaNo ratings yet
- Oracle® Human Resources Management Systems: Payroll Processing Management Guide (Canada) Release 12.1Document500 pagesOracle® Human Resources Management Systems: Payroll Processing Management Guide (Canada) Release 12.11 2No ratings yet
- Payroll Oracle - HRMS PDFDocument212 pagesPayroll Oracle - HRMS PDFYusuf MasharNo ratings yet
- 115 CsfigDocument196 pages115 CsfigOlgalicia SGNo ratings yet
- Command-Line Interface (CLI) Guide: Database Security and ComplianceDocument47 pagesCommand-Line Interface (CLI) Guide: Database Security and Compliancenobbyneptunegroup.jpNo ratings yet
- Payroll - UserManualDocument17 pagesPayroll - UserManualRazvan Dan PapoeNo ratings yet
- Database ModelDocument476 pagesDatabase ModelDavid KoiralaNo ratings yet
- Approved TALQ Specification Version 2.5.1Document64 pagesApproved TALQ Specification Version 2.5.1tensseiosbonitosNo ratings yet
- Purchasing Power Parities and the Real Size of World EconomiesFrom EverandPurchasing Power Parities and the Real Size of World EconomiesNo ratings yet
- Rad & RudDocument4 pagesRad & Ruduser AINo ratings yet
- Cloud EnablementDocument107 pagesCloud EnablementmaggigNo ratings yet
- Bca 6th Semester Project Reported On Spotify Music AppDocument27 pagesBca 6th Semester Project Reported On Spotify Music Appthestudyplace05No ratings yet
- Accenture 10 Ways COVID 19 Impacting PaymentsDocument30 pagesAccenture 10 Ways COVID 19 Impacting PaymentsShweta TomarNo ratings yet
- CPI Certification (CPI - CPI - 13) Related details/tips/Questions/Useful LinksDocument3 pagesCPI Certification (CPI - CPI - 13) Related details/tips/Questions/Useful LinksKumar Saurav0% (1)
- Shivam Kumar Ramchandra SarojDocument77 pagesShivam Kumar Ramchandra SarojAshwathi SumitraNo ratings yet
- Mansi Mca21 Project ReportDocument13 pagesMansi Mca21 Project ReportrajibmukherjeekNo ratings yet
- What Are Enterprise Application Integration (EAI) and Enterprise Information Integration (EII) Technologies?Document5 pagesWhat Are Enterprise Application Integration (EAI) and Enterprise Information Integration (EII) Technologies?Rajisha ThapaNo ratings yet
- L J - X Series Simulation-Software: User's ManualDocument78 pagesL J - X Series Simulation-Software: User's ManualjanomirNo ratings yet
- Zta Nist SP 1800 35b Preliminary Draft 3Document264 pagesZta Nist SP 1800 35b Preliminary Draft 3Roxana ArancibiaNo ratings yet
- VoipDocument4 pagesVoipVinod MalikNo ratings yet
- Mca-III Enterprise Resource PlanningDocument166 pagesMca-III Enterprise Resource Planningveere_arunNo ratings yet
- Common Schemes For Grade 8 and 9: Ministry of General Education Kitwe DistrictDocument12 pagesCommon Schemes For Grade 8 and 9: Ministry of General Education Kitwe DistrictTahpehs Phiri0% (1)
- Students' Assessment of The Online Enrollment System of Nueva EcijaDocument7 pagesStudents' Assessment of The Online Enrollment System of Nueva EcijaJenifer Languido CalautitNo ratings yet
- The Life Cycle Technical ProjectDocument16 pagesThe Life Cycle Technical ProjectSharifah BaitieNo ratings yet
- BCOM304 Management Information System Unit-4: Multimedia Approach To Information ProcessingDocument10 pagesBCOM304 Management Information System Unit-4: Multimedia Approach To Information ProcessingvivekkumarsNo ratings yet
- Team 6Document47 pagesTeam 6arifyusofNo ratings yet
- GX Cons Tech Effectively Deploy Sap Hana Modern LandscapesDocument1 pageGX Cons Tech Effectively Deploy Sap Hana Modern LandscapesCharles SantosNo ratings yet
- TIBCO Business Works - Process Design Guide - Nov 2002Document180 pagesTIBCO Business Works - Process Design Guide - Nov 2002NaveenNo ratings yet
- IA MagazineDocument78 pagesIA MagazinebibemergalNo ratings yet
- BUS 5116 Final Group Activity 0009F Task DistributionDocument2 pagesBUS 5116 Final Group Activity 0009F Task DistributionazgorNo ratings yet
- Whitepaper Led Compliance 1058 Comply 5991 9419en Us AgilentDocument10 pagesWhitepaper Led Compliance 1058 Comply 5991 9419en Us AgilentSalvador Petanas EstebanNo ratings yet
- Melroy Dsouza PromoDocDocument11 pagesMelroy Dsouza PromoDocyugant shahNo ratings yet
- 2018081396Document35 pages2018081396Akash JainNo ratings yet
- Ic Script v2Document4 pagesIc Script v2Garvit sachdevaNo ratings yet
- Due Care & Diligence ConceptsDocument2 pagesDue Care & Diligence ConceptsalokNo ratings yet